ElasticSearch+Logstash+Filebeat+Kibana集群日志管理分析平台搭建
一、ELK搜索引擎原理介绍
在使用搜索引擎是你可能会觉得很简单方便,只需要在搜索栏输入想要的关键字就能显示出想要的结果。但在这简单的操作背后是搜索引擎复杂的逻辑和许多组件协同工作的结果。
搜索引擎的组件一般可分为两大类:索引组件和搜索组件。在搜索之前搜索引擎必须把可搜索的所有数据做整合处理并构建索引(倒排索引),将所有数据构建成能被搜索的格式并存储起来,这就成为索引组件;能根据用户搜索并能从索引组件构建的索引中查询出用户想要的结果的组件称为搜索组件。
ElasticSearch就属于搜索组件的一种,并且它是一个分布式搜索服务器,在搭建ElasticSearch集群时最好有三台以上的服务器,因为它的数据都是分片存储的。Lucene是Apache提供的开源项目,是一个完全用Java编写的搜索引擎库。ElasticSearch使用Lucene作为内部的搜索索引构建库,使ElasticSearch集成了搜索引擎的两大核心组件。虽然用这两个组件可以完成索引构建并进行搜索操作,但成为完善的搜索引擎是不够的。
对于集群日志分析平台来说,还需要对大量应用服务的日志数据进行采集,并按需要的格式进行划分、存储、分析,这就要用到Logstash和Filebeat组件。
Filebeat是一个非常轻量化的日志采集组件,Filebeat 内置的多种模块(auditd、Apache、NGINX、System 和 MySQL)可实现对常见日志格式的一键收集、解析和可视化。而Logstash是一个开源的服务器端数据处理管道,它可以同时从多个源中提取数据,对其进行转换,然后输出到指定位置。
在解决上面一系列问题后,搜索引擎还需要提供一个友善的用户界面来展示给用户,使用户能够进行傻瓜式的搜索操作,并且还能将搜索结果通过各种直观的方式展示在用户面前。这是就要用到Kibana组件。Kibana可以让ElasticSearch数据极为丰富的展现出来。
上面提到的组件除了Lucene库意外其他的都属于Elastic Stack家族的产品,在普遍的企业中都是采用这些组件构建成集群来分析处理大量的日志数据的。更多组件可访问Elastic官网站点。
二、ELK日志分析集群搭建
1.基本架构
在本文示例中,以下面的结构来进行演示,图1:
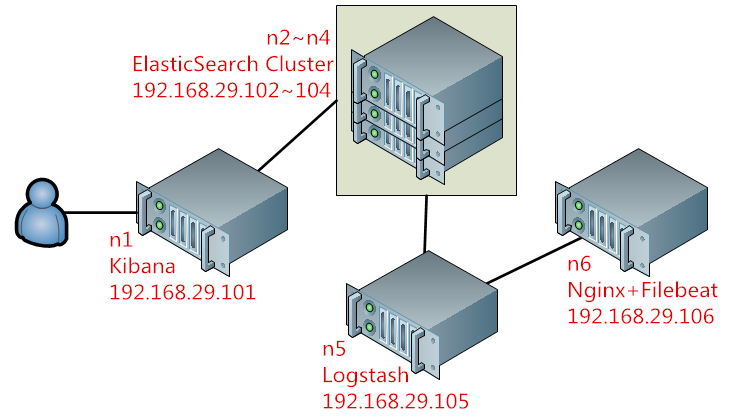
在上图所示的架构的工作逻辑:Kibana将ElasticSearch集群提供的搜索内容进行可视化处理,并用多种方式展现给用户;ElasticSearch集群和其集成的Lucene用来完成对所有采集到的数据进行分析构建索引并提供搜索;而数据的来源则是通过Logstash和FileBeat采集自Nginx日志,Logstash将来自FileBeat的数据过滤并输出给ElasticSearch集群。
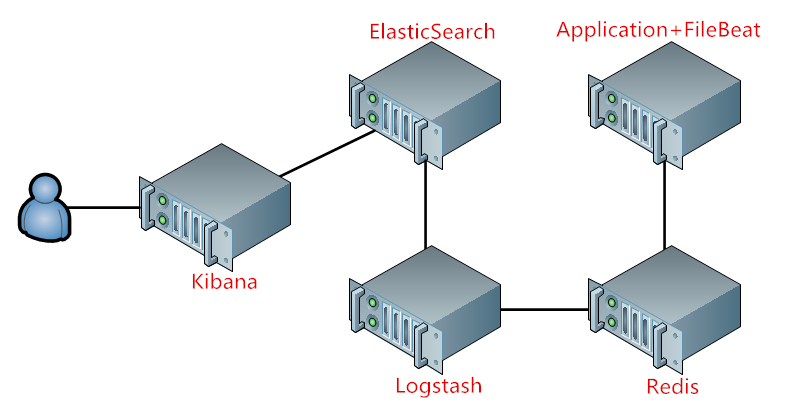
在集群达到一定规模后,大量的后端应用通过FileBeat采集到数据输出到Logstash会使Logstash Server称为性能瓶颈,因为Logstash是用Java程序开发的,很消耗内存,当数据处理量大后性能会大打折扣;所以可以在Logstash和FileBeat之间增加Redis,Redis专门用来做队列数据库,将在FieBeat中采集的数据平缓的输出到Logstash。如图2:
2.搭建ElasticSearch集群
Linux版本:CentOS7.2
ElasticSearch:5.5.1
下面先用图1的架构示例来构建集群,完成后再引入Redis来进行演示,当集群没有达到很庞大规模时引入Redis不会对集群性能有实质性的提升。
由于ElasticSearch是用Java开发的,运行时依赖JDK环境,ElasticSearch集群所有节点上都需要装上JDK。在n2~n4节点上安装ElasticSearch和JDK:
yum install -y java-1.8.-openjdk java-1.8.-openjdk-devel
在官网下载ElasticSearch,我这里安装的是ElasticSearch5.5.1版本,在官网下载rpm包直接安装:
rpm -ivh elasticsearch-5.5..rpm
ElasticSearch5的程序环境:
/etc/elasticsearch/elasticsearch.yml #主程序配置文件
/etc/elasticsearch/jvm.options #java配置文件
/etc/elasticsearch/log4j2.properties #日志配置文件
主配合文件配置段:
Cluster #集群配置段,需要设置ElasticSearch集群名称
Node #各节点配置段,要设置当前主机的主机名
Paths #各类路径配置段
Memory #内存配置段
Network #网络配置段
Discovery #
Gateway
Various
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
#
#cluster.name: my-application
cluster.name: myels #集群名称,ElasticSearch是基于集群名和主机名来识别集群成员的
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
#
#node.name: node-
node.name: n2 #本节点名
# Add custom attributes to the node:
#
#node.attr.rack: r1
#
# ----------------------------------- Paths ------------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):
#
#path.data: /path/to/data
path.data: /els/data #查询索引数据存放路径
# Path to log files:
path.data: /els/logs #日志路径
#path.logs: /path/to/logs
#
# ----------------------------------- Memory -----------------------------------
#
# Lock the memory on startup:
#
#bootstrap.memory_lock: true #是否开启时就划用所有内存
#
# Make sure that the heap size is set to about half the memory available
# on the system and that the owner of the process is allowed to use this
# limit.
#
# Elasticsearch performs poorly when the system is swapping the memory.
#
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#
#network.host: 192.168.0.1
network.host: 192.168.29.102 #监听地址,默认是本地
# Set a custom port for HTTP:
#
#http.port: #监听端口
#
# For more information, consult the network module documentation.
#
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when new node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
#
discovery.zen.ping.unicast.hosts: ["n2", "n3", "n4"] #为了安全起见,尽量将ElasticSearch节点的解析名配置进来(画圈圈)
#
# Prevent the "split brain" by configuring the majority of nodes (total number of master-eligible nodes / + ):
#
discovery.zen.minimum_master_nodes: #脑裂预防选项
#
# For more information, consult the zen discovery module documentation.
#
# ---------------------------------- Gateway -----------------------------------
#
# Block initial recovery after a full cluster restart until N nodes are started:
#
#gateway.recover_after_nodes:
#
# For more information, consult the gateway module documentation.
#
# ---------------------------------- Various -----------------------------------
#
# Require explicit names when deleting indices:
#
#action.destructive_requires_name: true
ElasticSearch主配置
创建数据和日志目录并修改目录权限并启动ElasticSearch:
mkdir -pv /els/{data,logs}
chown -R elasticsearch.elasticsearch /els/
systemctl start elasticsearch
启动时发生了错误:
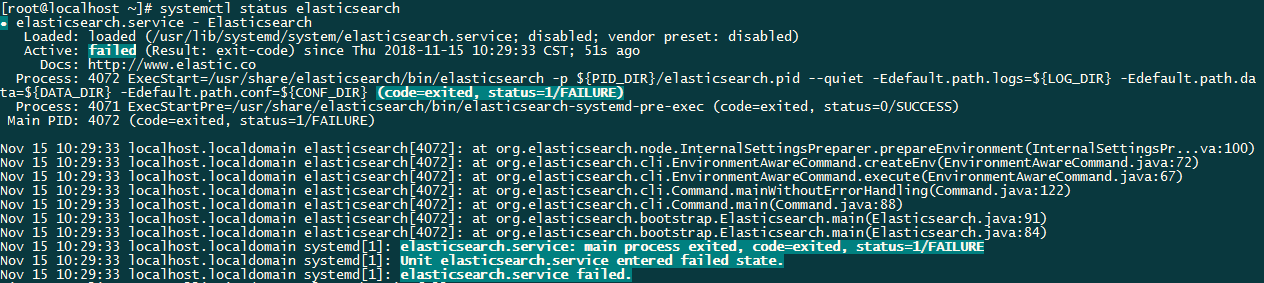
查看 /var/log/messages 发现一条警告信息:
elasticsearch: OpenJDK -Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
这是因为JVM中的 ParallelGCThreads 参数未设置正确导致的,我修改了虚拟机的线程数后又出现了新的报错:
elasticsearch: Exception in thread "main" ElasticsearchParseException[duplicate settings key [path.data] found at line number [], column number [], previous value [/els/data], current value [/els/logs]]
这个的大致意思就是路径冲突了,后来发现在主配置文件中我将 path.logs: /els/logs 写成了 path.data: /els/logs ,导致路径冲突。
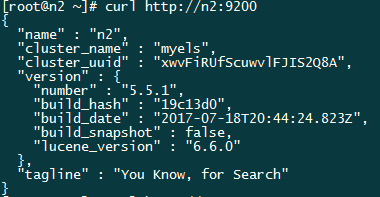
启动完成后可以看到9200和9300端口被监听:

至此ElasticSearch集群就已经工作起来了。
2.安装Kibana
在n1上安装Kibana:
rpm -ivh kibana-5.5.-x86_64.rpm
修改Kibana配置文件:
vim /etc/kibana/kibana.yml
# Kibana is served by a back end server. This setting specifies the port to use.
#server.port:
server.port: #监听端口
# Specifies the address to which the Kibana server will bind. IP addresses and host names are both valid values.
# The default is 'localhost', which usually means remote machines will not be able to connect.
# To allow connections from remote users, set this parameter to a non-loopback address.
#server.host: "localhost"
server.host: "192.168.29.101" #监听地址
# Enables you to specify a path to mount Kibana at if you are running behind a proxy. This only affects
# the URLs generated by Kibana, your proxy is expected to remove the basePath value before forwarding requests
# to Kibana. This setting cannot end in a slash.
#server.basePath: "" # The maximum payload size in bytes for incoming server requests.
#server.maxPayloadBytes: # The Kibana server's name. This is used for display purposes.
#server.name: "your-hostname"
server.name: "n1" #主机名
# The URL of the Elasticsearch instance to use for all your queries.
#elasticsearch.url: "http://n2:9200"
elasticsearch.url: "http://n2:9200" #ElasticSearch地址
# When this setting's value is true Kibana uses the hostname specified in the server.host
# setting. When the value of this setting is false, Kibana uses the hostname of the host
# that connects to this Kibana instance.
#elasticsearch.preserveHost: true # Kibana uses an index in Elasticsearch to store saved searches, visualizations and
# dashboards. Kibana creates a new index if the index doesn't already exist.
#kibana.index: ".kibana" # The default application to load.
#kibana.defaultAppId: "discover" # If your Elasticsearch is protected with basic authentication, these settings provide
# the username and password that the Kibana server uses to perform maintenance on the Kibana
# index at startup. Your Kibana users still need to authenticate with Elasticsearch, which
# is proxied through the Kibana server.
#elasticsearch.username: "user" #可以设置登录认证用户和密码
#elasticsearch.password: "pass" # Enables SSL and paths to the PEM-format SSL certificate and SSL key files, respectively.
# These settings enable SSL for outgoing requests from the Kibana server to the browser.
#server.ssl.enabled: false
#server.ssl.certificate: /path/to/your/server.crt
#server.ssl.key: /path/to/your/server.key # Optional settings that provide the paths to the PEM-format SSL certificate and key files.
# These files validate that your Elasticsearch backend uses the same key files.
#elasticsearch.ssl.certificate: /path/to/your/client.crt
#elasticsearch.ssl.key: /path/to/your/client.key # Optional setting that enables you to specify a path to the PEM file for the certificate
# authority for your Elasticsearch instance.
#elasticsearch.ssl.certificateAuthorities: [ "/path/to/your/CA.pem" ] # To disregard the validity of SSL certificates, change this setting's value to 'none'.
#elasticsearch.ssl.verificationMode: full # Time in milliseconds to wait for Elasticsearch to respond to pings. Defaults to the value of
# the elasticsearch.requestTimeout setting.
#elasticsearch.pingTimeout: # Time in milliseconds to wait for responses from the back end or Elasticsearch. This value
# must be a positive integer.
#elasticsearch.requestTimeout: # List of Kibana client-side headers to send to Elasticsearch. To send *no* client-side
# headers, set this value to [] (an empty list).
#elasticsearch.requestHeadersWhitelist: [ authorization ] # Header names and values that are sent to Elasticsearch. Any custom headers cannot be overwritten
# by client-side headers, regardless of the elasticsearch.requestHeadersWhitelist configuration.
#elasticsearch.customHeaders: {} # Time in milliseconds for Elasticsearch to wait for responses from shards. Set to to disable.
#elasticsearch.shardTimeout: # Time in milliseconds to wait for Elasticsearch at Kibana startup before retrying.
#elasticsearch.startupTimeout: # Specifies the path where Kibana creates the process ID file.
#pid.file: /var/run/kibana.pid # Enables you specify a file where Kibana stores log output.
#logging.dest: stdout # Set the value of this setting to true to suppress all logging output.
#logging.silent: false # Set the value of this setting to true to suppress all logging output other than error messages.
#logging.quiet: false # Set the value of this setting to true to log all events, including system usage information
# and all requests.
#logging.verbose: false # Set the interval in milliseconds to sample system and process performance
# metrics. Minimum is 100ms. Defaults to .
#ops.interval: # The default locale. This locale can be used in certain circumstances to substitute any missing
# translations.
#i18n.defaultLocale: "en"
浏览器访问http://192.168.29.101:5601,显示如下,说明Kibana已经安装成功:

3.在n6上安装Nginx和Filebeat
前面已经将ElasticSearch搜索引擎最重要的部分搭建完成了,可以进行搜索和构建索引了。下面来部署数据采集的部分。我这里用Nginx来做演示,用Filebeat将Nginx的日志搜集并输出给ElasticSearch并构建索引提供搜索。
在n6节点安装Nginx和Filebeat:
rpm -ivh filebeat-5.5.-x86_64.rpm
yum install -y nginx
配置Filebeat并启动:
vim /etc/filebeat/filebeat.yml
#=========================== Filebeat prospectors ============================= filebeat.prospectors: # Each - is a prospector. Most options can be set at the prospector level, so
# you can use different prospectors for various configurations.
# Below are the prospector specific configurations. - input_type: log # Paths that should be crawled and fetched. Glob based paths.
paths:
#- /var/log/*.log
- /var/log/nginx/access.log #指定要采集的日志文件路径
#- c:\programdata\elasticsearch\logs\* # Exclude lines. A list of regular expressions to match. It drops the lines that are
# matching any regular expression from the list.
#exclude_lines: ["^DBG"] # Include lines. A list of regular expressions to match. It exports the lines that are
# matching any regular expression from the list.
#include_lines: ["^ERR", "^WARN"] # Exclude files. A list of regular expressions to match. Filebeat drops the files that
# are matching any regular expression from the list. By default, no files are dropped.
#exclude_files: [".gz$"] # Optional additional fields. These field can be freely picked
# to add additional information to the crawled log files for filtering
#fields:
# level: debug
# review: 1 ### Multiline options # Mutiline can be used for log messages spanning multiple lines. This is common
# for Java Stack Traces or C-Line Continuation #multiline.pattern: ^\[ # Defines if the pattern set under pattern should be negated or not. Default is false.
#multiline.negate: false #multiline.match: after #================================ General ===================================== # The name of the shipper that publishes the network data. It can be used to group
# all the transactions sent by a single shipper in the web interface.
#name: # The tags of the shipper are included in their own field with each
# transaction published.
#tags: ["service-X", "web-tier"] # Optional fields that you can specify to add additional information to the
# output.
#fields:
# env: staging #================================ Outputs ===================================== # Configure what outputs to use when sending the data collected by the beat.
# Multiple outputs may be used. #-------------------------- Elasticsearch output ------------------------------
output.elasticsearch:
# Array of hosts to connect to.
hosts: ["n2:9200"] #数据输出到ElasticSearch,填写集群其中的一个即可 # Optional protocol and basic auth credentials.
#protocol: "https"
#username: "elastic"
#password: "changeme" #----------------------------- Logstash output --------------------------------
#output.logstash:
# The Logstash hosts
#hosts: ["localhost:5044"] # Optional SSL. By default is off.
# List of root certificates for HTTPS server verifications
#ssl.certificate_authorities: ["/etc/pki/root/ca.pem"] # Certificate for SSL client authentication
#ssl.certificate: "/etc/pki/client/cert.pem" # Client Certificate Key
#ssl.key: "/etc/pki/client/cert.key" #================================ Logging ===================================== # Sets log level. The default log level is info.
# Available log levels are: critical, error, warning, info, debug
#logging.level: debug # At debug level, you can selectively enable logging only for some components.
# To enable all selectors use ["*"]. Examples of other selectors are "beat",
# "publish", "service".
#logging.selectors: ["*"]
systemctl start filebeat
在浏览器上访问n6节点,使Nginx生成日志文件,触发Filebeat将数据输出给ElasticSearch,然后访问n1节点的Kibana,配置索引模式构建索引。在Nginx被访问后会自动生成:
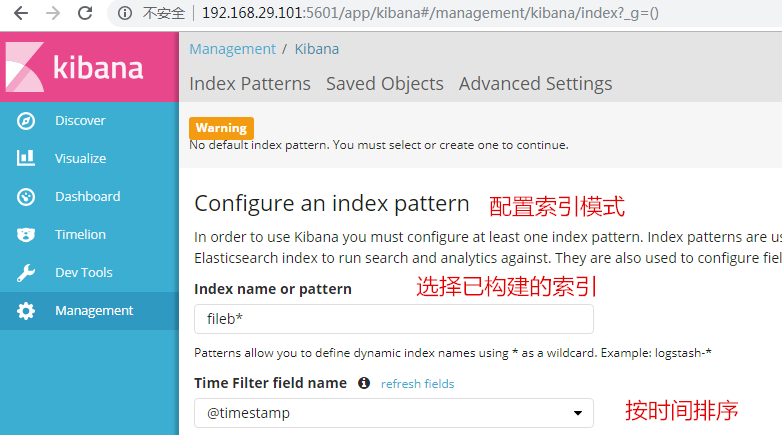
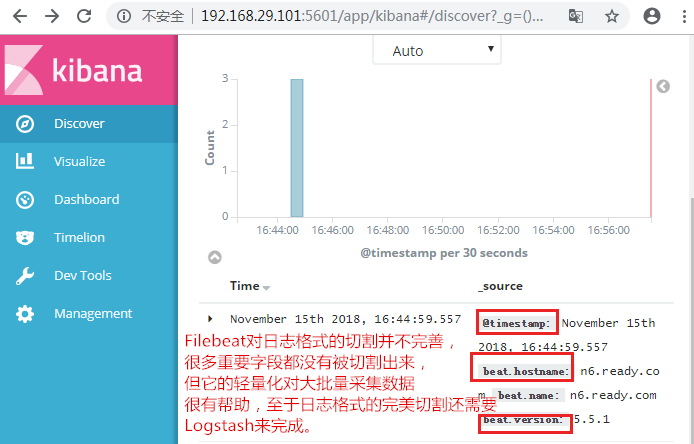
4.安装并配置Logstash
在n5节点上安装Logstash,Logstash的运行依赖JDK环境,所以也需要安装JDK:
yum install -y java-1.8.-openjdk java-1.8.-openjdk-devel
rpm -ivh logstash-5.5..rpm
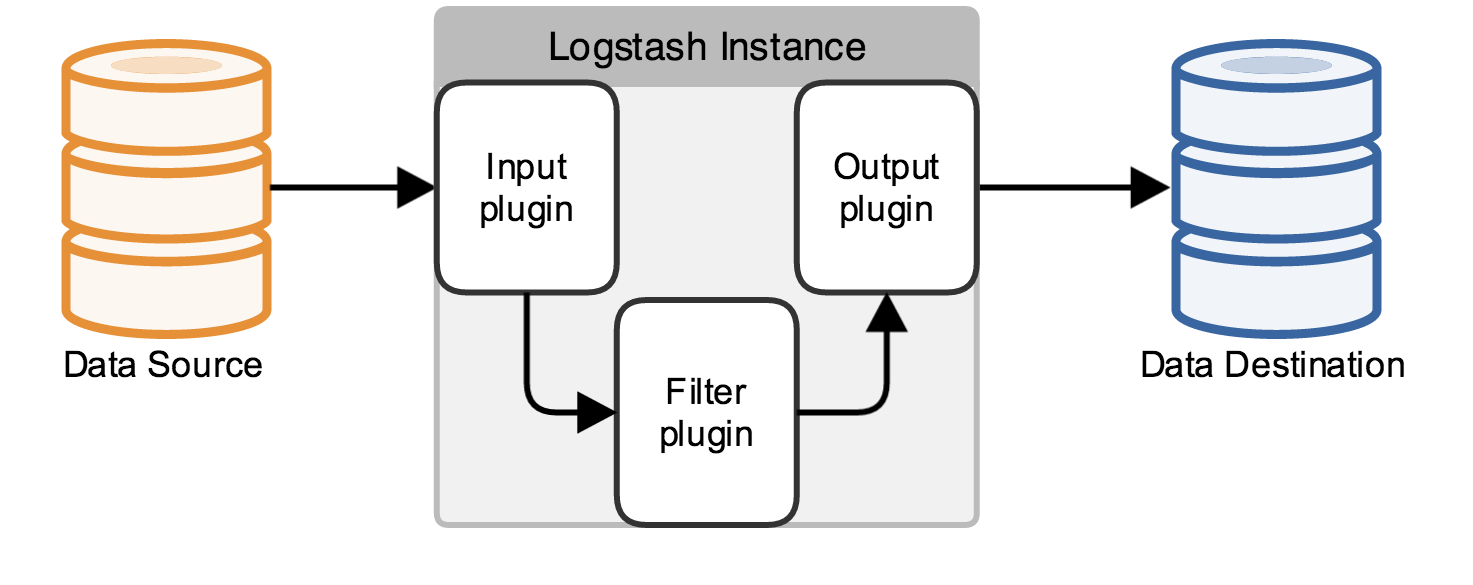
Logstash的组件结构分为输入组件(Input plugin)、输出组件(Output plugin)、过滤组件(Filter plugin),图示:
测试Logstash是否能正常运行时,为避免与root发生权限冲突,需要切换至logstash用户尝试启动Logstash:
su - logstash -s /bin/bash
主配置文件为: /etc/logstash/logstash.yml ,基本上不需要做修改,但要修改n6节点上的Filebeat配置文件,将Filebeat的输出从ElasticSearch修改成向Logstash输出:
#----------------------------- Logstash output --------------------------------
output.logstash:
# The Logstash hosts
#hosts: ["localhost:5044"]
hosts: ["n5:5044"]
在n5节点上编写Logstash过滤模块:
input { #定义数据输入来源,这里定义的是从Filebeat输入
beats {
host => '0.0.0.0' #监听地址
port =>
}
}
filter { #过滤模块,将输入的数据按某种定义的格式做处理切割
grok { #由grok模块来过滤
match => {
"message" => "%{IPORHOST:clientip}" #切割源message的格式
}
}
}
output { #将过滤后的数据输出到ElasticSearch
elasticsearch {
hosts => ["n2:9200","n2:9200","n2:9200"]
index => "logstash-nginxlog-%{+YYYY.MM.dd}"
}
}
在Kibana上重新查找便能看出已经将 clientip 切割出来了,这种的切割功能用Filebeat是没办法实现的:

ElasticSearch+Logstash+Filebeat+Kibana集群日志管理分析平台搭建的更多相关文章
- Kubernetes 集群日志管理 Elasticsearch + fluentd(二十)
目录 一.安装部署 Kubernetes 开发了一个 Elasticsearch 附加组件来实现集群的日志管理.这是一个 Elasticsearch.Fluentd 和 Kibana 的组合.Elas ...
- Kubernetes 集群日志管理 - 每天5分钟玩转 Docker 容器技术(180)
Kubernetes 开发了一个 Elasticsearch 附加组件来实现集群的日志管理.这是一个 Elasticsearch.Fluentd 和 Kibana 的组合.Elasticsearch ...
- elasticsearch+logstash+redis+kibana 实时分析nginx日志
1. 部署环境 2. 架构拓扑 3. nginx安装 安装在192.168.176.128服务器上 这里安装就简单粗暴了直接yum安装nginx [root@manager ~]# yum -y in ...
- Kubernetes 集群日志管理
Kubernetes 开发了一个 Elasticsearch 附加组件来实现集群的日志管理.这是一个 Elasticsearch.Fluentd 和 Kibana 的组合.Elasticsearch ...
- Kubernetes 集群日志管理【转】
Kubernetes 开发了一个 Elasticsearch 附加组件来实现集群的日志管理.这是一个 Elasticsearch.Fluentd 和 Kibana 的组合.Elasticsearch ...
- ELKF-分布式日志收集分析平台搭建 最小化 配置过程 - 查看收集日志(windows10下搭建)
前言 Elasticsearch是与名为Logstash的数据收集和日志解析引擎以及名为Kibana的分析和可视化平台一起开发的.这三个产品被设计成一个集成解决方案,称为“Elastic Stack” ...
- filebeat收集日志传输到Redis集群,logstash从Redis集群中拉取数据
前提:已配置好Redis集群,并设置的有统一的访问密码 架构是filebeat-->redis集群-->logstash->elasticsearch,需要修改filebeat的输出 ...
- centos7搭建ELK Cluster集群日志分析平台(一):Elasticsearch
应用场景: ELK实际上是三个工具的集合,ElasticSearch + Logstash + Kibana,这三个工具组合形成了一套实用.易用的监控架构, 很多公司利用它来搭建可视化的海量日志分析平 ...
- 使用ELK(Elasticsearch + Logstash + Kibana) 搭建日志集中分析平台实践--转载
原文地址:https://wsgzao.github.io/post/elk/ 另外可以参考:https://www.digitalocean.com/community/tutorials/how- ...
随机推荐
- C++ STL next_permutation(快速排列组合)
排列组合必备!! https://blog.csdn.net/bengshakalakaka/article/details/78515480
- ADO.NET学习笔记(1)
ADO.Net是.Net框架中为数据库的访问而封装的一个库.通过这个库我们可以简单便捷的访问数据库,并对数据库进行一些增删改查的操作,目前ADO.Net支持四种主流的数据库,分别是SQL.OLE DB ...
- tomcat设置错误页面
今日学习笔记: 当我们访问tomcat的一个不存在的页面,返回错误信息如下: 这样的界面直接暴露给用户并不友好,有时候还不安全,因此一般需要修改默认的错误页. vim /$TOMCAT_HOME/co ...
- C++的IO处理中的头文件以及类理解(2)<sstream>头文件
C++的IO处理中的头文件以及类理解(2)<sstream>头文件 头文件<sstream>中定义的类型都继承iostream头文件中定义的类型.除了继承得来的操作,sstre ...
- C#轻量级通通讯组件StriveEngine —— C/S通信开源demo(2) —— 使用二进制协议 (附源码)
前段时间,有几个研究ESFramework通信框架的朋友对我说,ESFramework有点庞大,对于他们目前的项目来说有点“杀鸡用牛刀”的意思,因为他们的项目不需要文件传送.不需要P2P.不存在好友关 ...
- gitlab导入现在git项目
确保管理员所在机器的ssh 公钥已经保存在gitlab网站上. 这样管理员可以在自己的机器上和gitlab系统交互. 现在在管理员自己的机器上,进入项目目录(项目目录拷贝自git server,目录后 ...
- Jquery中attr()与prop()的区别
在jQuery中,attr()函数和prop()函数都用于设置或获取指定的属性,它们的参数和用法也几乎完全相同.但是,这两个函数的用处却并不相同.下面我们来详细介绍这两个函数之间的区别. 1.操作对象 ...
- 第84节:Java中的网络编程(中)
第84节:Java中的网络编程(中) 实现客户端和服务端的通信: 客户端需要的操作,创建socket,明确地址和端口,进行键盘录入,获取需要的数据,然后将录入的数据发送给服务端,为socket输出流, ...
- 微信小程序提交审核并发布详细流程
微信小程序提交审核并发布详细流程 审核在1小时到N天不等 官方7天,一般3天内 提交审核?如何发布?审核过程中注意事项? 服务器: 域名只支持 https (request.uploadFile.do ...
- Python爬虫-萌妹子图片
最近发现一个可以看图的地方,一张张翻有点累,毕竟只有一只手(难道鼠标还能两只手翻?).能不能下到电脑上看呢,毕竟不用等网速,还可以预览多张,总之很方便,想怎么就怎么,是吧? 刚好这几天在学python ...