洗礼灵魂,修炼python(66)--爬虫篇—BeauitifulSoup进阶之“我让你忘记那个负心汉,有我就够了”
说明一下,这个标题可能有点突兀,结合上一篇一起看就行
前面已经对BeautifulSoup有了了解了,相信你基本已经学会怎么获取网页数据了,那么BeautifulSoup这么吊,还有没有其他的功能呢?当然是有的
前面说的Tag对象都还记得吧?像这样BeautifulSoup.title,得到的就是Tag对象,它其实还有一些属性:
1.contents:将tag的子节点以列表的方式输出
还是前面的例子:
# -*- coding:utf-8 -*-
import bs4
html='''
<html>
<head>
<title>这是第二节课</title>
<meta charset='utf-8'> <!--meta是单标签-->
<meta name='keywords' content='hello world,oh yeah'>
</head>
<!--<body bgcolor='green'>-->
<body link='red' vinlk='green' alink='blue'>
<h1>这是一个标题</h1>
<!--超链接必须加上http://不然无法跳转-->
<a href='http://www.baidu.com'>百度</a>
<a href='http://www.163.com'>网易</a>
<a href='http://www.qq.com'>腾讯</a>
<a href='http://www.sina.com'>新浪</a>
</body>
</html>
'''
test=bs4.BeautifulSoup(html,'html.parser')
print test.title
print test.title.contents
结果:
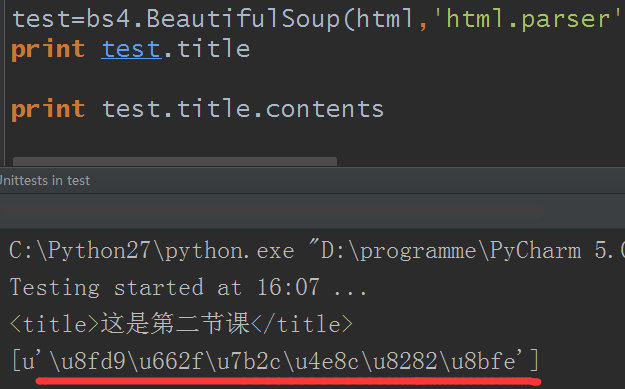
字符型是utf-8,而我用的是python2,前面编码问题已经说过了,略过
既然是列表对吧,那么它就可以使用列表的方法了:
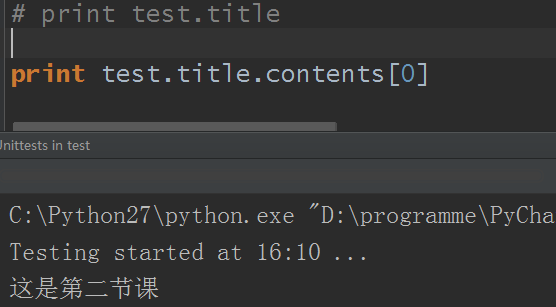
2.children:返回一个列表迭代器
既然是迭代器,那么就可以迭代出来了:
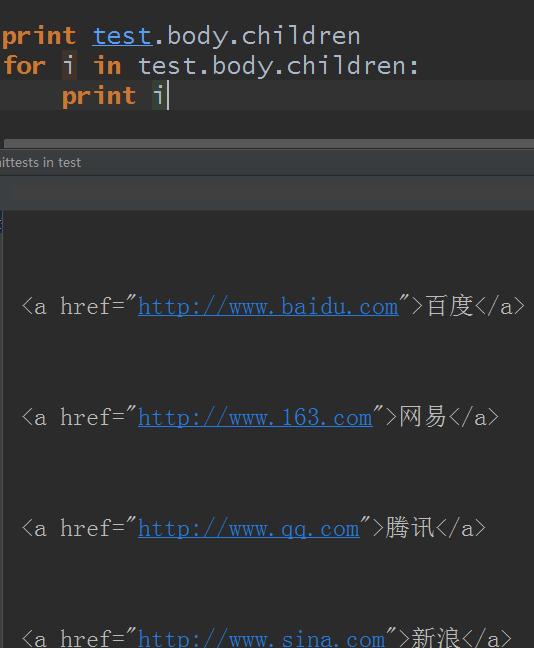
其实BeautifulSoup对象也有类似tag对象的children的属性:
3.descendants:类似tag对象的children的属性,不过返回的是一个生成器对象
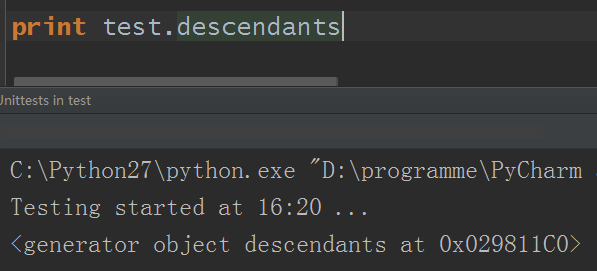
同样的,使用for循环也可以迭代出来,这里直接略过。
上面的contents和children是什么属性呢?官方文档里有个称呼叫Tag对象的直接子节点。而descendants是BeautifulSoup的子孙节点。
4.什么是节点呢?
结合我个人的理解:这里牵扯到一个知识点,树形结构知道吗?就是只某样事物类似树枝一样,由树干延伸到树枝,树枝再延伸到小树枝……这样不断的蔓延伸展,这种就是树形结构,而每一个过渡点就叫做节点。那么这里的html文档就好比一棵树,然后利用BeautifulSoup模块生成了BeautifulSoup对象,BeautifulSoup对象下面每一个属性就是一个节点,属性下面又有一个子节点,然后descendants其实就是BeautifulSoup对象的直接子节点,而contents和children就是由BeautifulSoup对象结合html标签生成的Tag对象的直接子节点(有点递归的意思,你可以结合理解)
既然有节点,结合上一篇说的,我们可以在Tag对象下使用string子节点属性获得html代码内的字符串内容,那么这样的内容就叫节点内容
我相信,你在自己动手练习时,一定遇到这种情况:
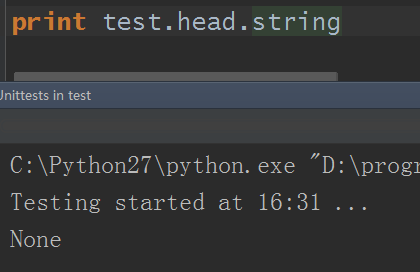
怎么是None呢?html里不是有数据title标签和meta标签等的吗?对吧?那么这为何是空呢?这里就是string属性的一个特性而来。
string属性特性:
官方文档是这么说的:
如果tag只有一个NavigableString类型(忘记什么是NavigableString类型回去看上一篇博文)子节点,那么这个tag可以使用string属性得到子节点。如果一个tag仅有一个子节点,那么这个tag也可以使用string属性,输出结果与当前唯一子节点的string属性结果相同。
换句话就是:
- 如果一个标签里面没有子标签了,那么 string属性就会返回标签里面的内容。如果标签里面只有唯一的一个子标签了,那么string属性也会返回最里面的内容
- 如果tag包含了多个子节点(子标签),tag就无法确定string属性应该调用哪个子节点的内容而返回None
那有朋友说,我就想返回多个内容怎么办?使用strings属性和stripped_strings属性
5.strings:获取多个内容,返回一个生成器对象:
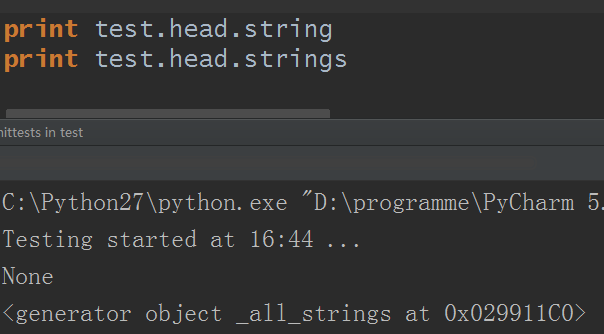
遍历就直接略过了,你使用工程函数list转为列表或者用for迭代或者转为字符串或者使用函数repr输出都随便你了
6.stripped_strings :(看单词意思估计你都能猜到干嘛的了)同strings返回一个生成器对象,不过生成器对象内的元素已自动去除多余空白内容:
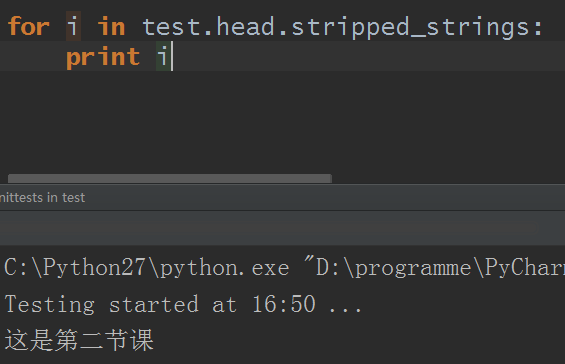
因为只返回字符串内容,而我那个html源码例子里属于head标签的只有这一句字符串内容,所以结果如上。
那么既然有子节点,自然还有父节点,前后节点,兄弟节点等等的。
7.父节点:parent属性,即就是当前节点的父级节点
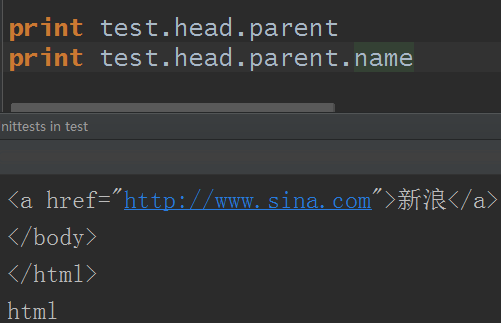
使用parent属性会打印父级节点所有内容,使用parent.name属性则显示父级节点的名字
当然你会想,还有和父级节点同级的节点
8.全部父级节点:parents属性
同parents,略过
9.兄弟节点:和当前节点同一级别的节点
- next_sibling属性获取该节点的下一个兄弟节点
- previous_sibling属性获取当前节点的上一个兄弟节点,如果节点不存在,则返回 None
实际文档中的tag的 .next_sibling 和 .previous_sibling 属性通常是字符串或空白,因为空白或者换行也可以被视作一个节点,所以得到的结果可能是空白或者换行。
可以利用next_sibling.next_sibling获得下一个兄弟节点:
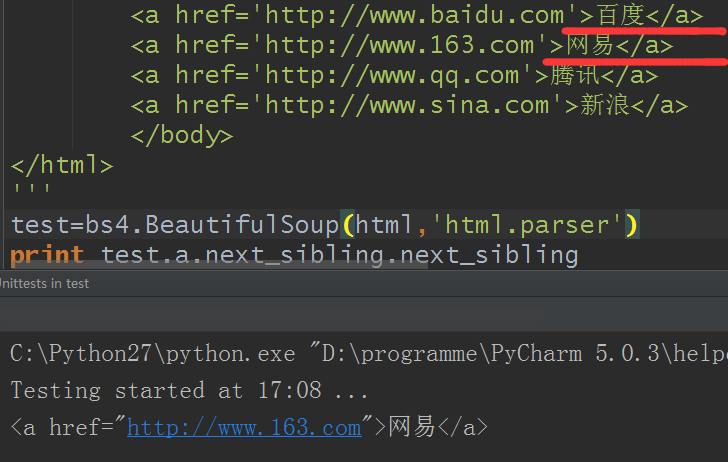
当然上一个兄弟节点也同样,略过
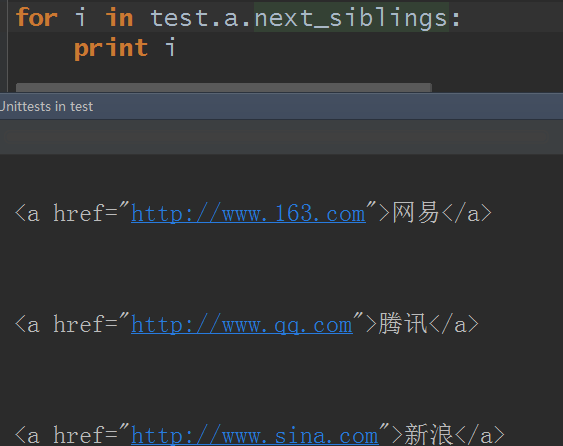
10.全部兄弟节点:获得当前节点的兄弟节点并返回一个生成器,使用属性next_siblings和previous_siblings
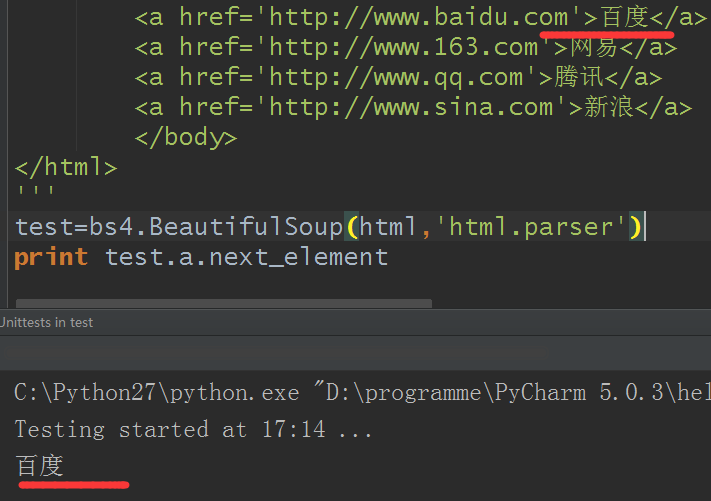
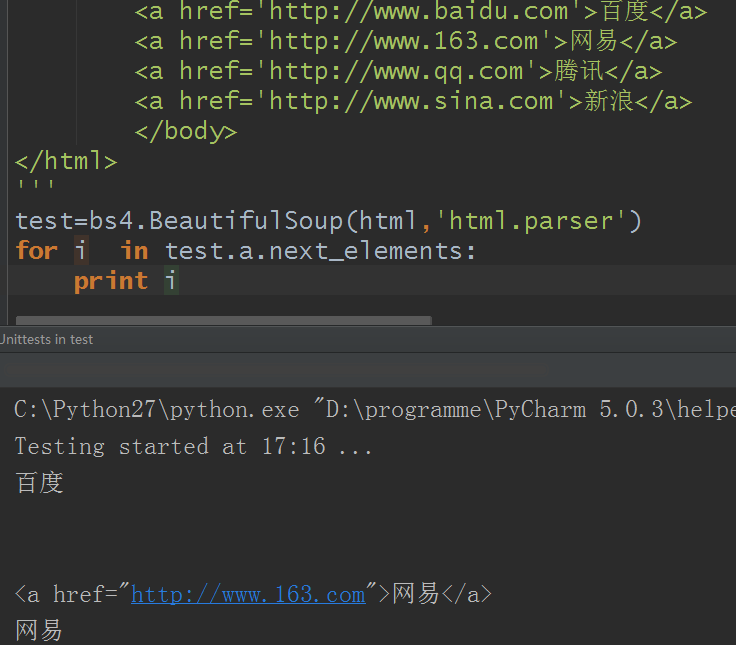
11.前后节点:与 next_sibling和previous_sibling不同,它并不是针对于兄弟节点,而是在所有节点,不分层次,谁在前就是前节点,谁在后就是后节点。使用next_element和previous_element
12.所有前后节点:向前或向后访问文档节点内容,返回一个生成器。使用next_elements和previous_elements 属性
既然BeautifulSoup这么强大,那么也可以搜索文档内容吧?是的
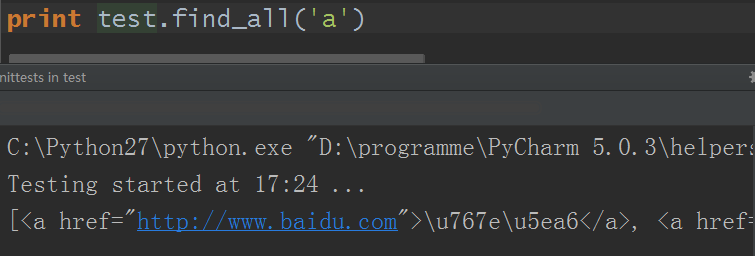
13. find_all( name , attrs , recursive , text , **kwargs ):搜索当前tag的所有tag子节点,以列表形式返回符合条件的所有tag对象,name参数即待搜索的html标签名
name参数:
1)name参数可以是一个字符串对象,即html标签
2)name参数可以是一个正则表达式,BeautifulSoup对象会默认使用正则表达式的match()方法匹配
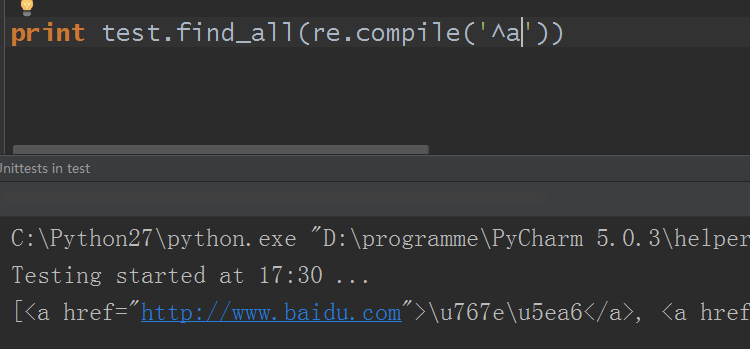
这个就厉害了对吧?
3)name参数可以是一个列表,BeautifulSoup对象会将与列表中任一元素匹配的内容返回
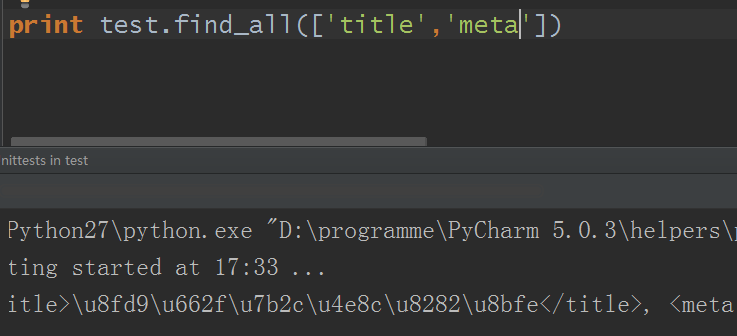
4)name参数可以是Bool函数的True,True即代表可以匹配任何值(即所有值)
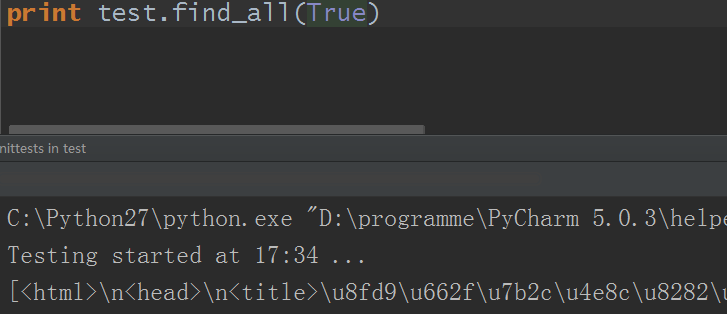
5)name参数可以是一个函数/方法
自定义了一个has方法,只返回拥有href属性的标签
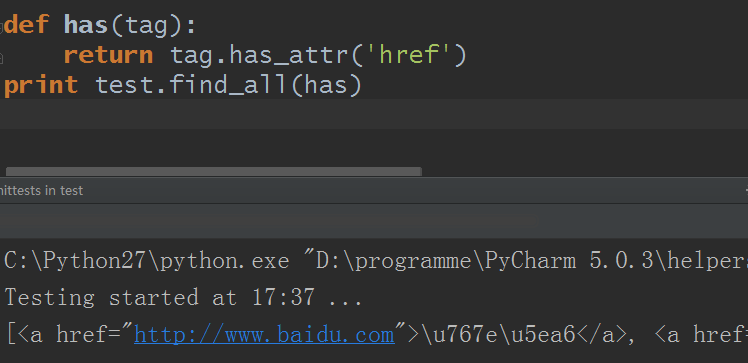
keyword参数
- 如果一个指定名字的参数不是搜索内置的参数名,搜索时会把该参数当作指定名字tag的属性来搜索
- 如果包含一个名字为id的参数,BeautifulSoup对象会搜索每个tag的”id”属性
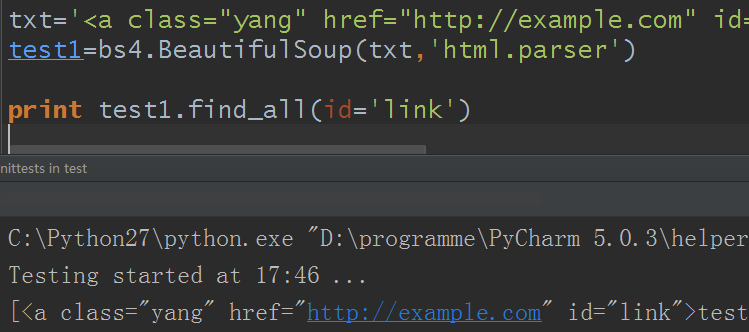
1)如果参数是id:
由于前面的html标签里没有适合的标签,所以这里新设一个例子
txt='<a class="yang" href="http://example.com" id="link">test</a>' test1=bs4.BeautifulSoup(txt,'html.parser') print test1.find_all(id='link')
结果:
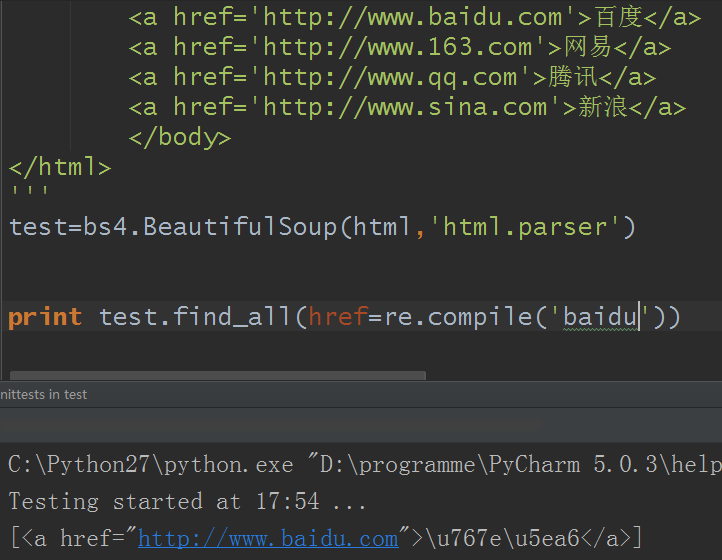
2)如果参数是href:
还是原来的例子
当然你可以使用多个指定名字的参数可以同时过滤tag的多个属性。略过
注意:
- 当关键词是class时,由于class也是python的关键词语句,当作关键词使用时,使用【class_】就行
- 当遇到特殊情况不能被搜索时,可以使用attrs参数定义一个字典参数来搜索包含特殊属性的tag
不过以上情况基本少见,略过
text参数:可以搜索文档中的字符串内容,与name参数的可选值一样,可以是字符串 , 正则表达式 , 列表, True
略过
limit参数:如果文档很大那么搜索会很慢,而我们并不需要全部结果,使用limit参数限制返回结果的数量,效果与SQL中的limit关键字类似,当搜索到的结果数量达到limit的限制时,就停止搜索返回结果。
limit参数在很多地方都有用到
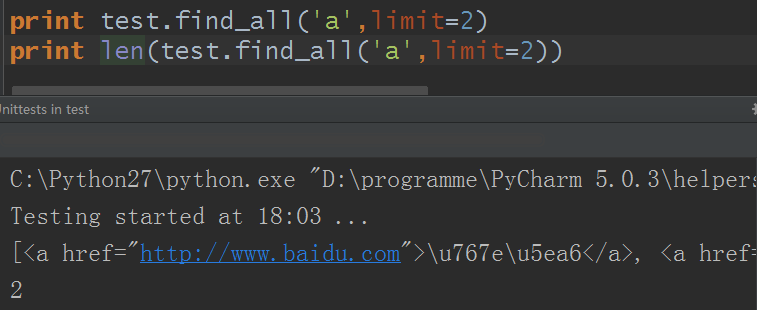
本来html代码里有四个a标签,设置limit参数后只得到两个值
recursive参数:recursive值默认为True,即BeautifulSoup对象会默认检索当前tag的所有子孙节点,如果只想搜索tag的直接子节点,可以使用参数recursive=False
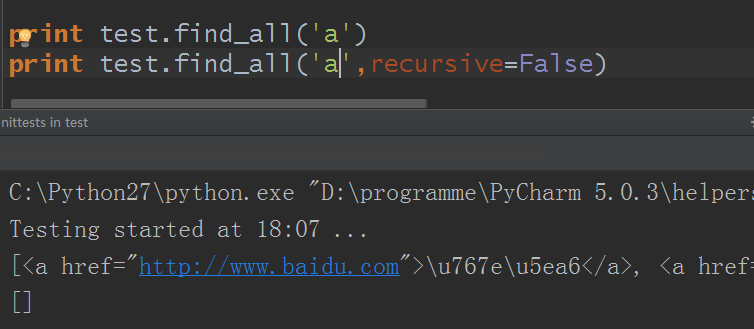
使用与不使用的差别
14.还有以下这些方法,使用基本和find_all类似,所以直接略过:
find( name,attrs, recursive, text, **kwargs ): 类似find_all(),不过find() 方法直接返回结果
find_parents()和find_parent()
find_all() 和 find()只搜索当前节点的所有子节点,孙子节点等。find_parents() 和 find_parent() 用来搜索当前节点的父辈节点,搜索方法与普通tag的搜索方法相同,搜索文档搜索文档包含的内容
find_next_siblings()和find_next_sibling()
这2个方法通过next_siblings 属性对当 tag 的所有后面解析的兄弟 tag 节点进行迭代, find_next_siblings() 方法返回所有符合条件的后面的兄弟节点,find_next_sibling() 只返回符合条件的后面的第一个tag节点
find_previous_siblings()和find_previous_sibling()
这2个方法通过previous_siblings 属性对当前 tag 的前面解析的兄弟 tag 节点进行迭代, find_previous_siblings() 方法返回所有符合条件的前面的兄弟节点, find_previous_sibling() 方法返回第一个符合条件的前面的兄弟节点
find_all_next()和find_next()
这2个方法通过next_elements 属性对当前 tag 的之后的 tag 和字符串进行迭代, find_all_next() 方法返回所有符合条件的节点, find_next() 方法返回第一个符合条件的节点
find_all_previous() 和 find_previous()
这2个方法通过previous_elements 属性对当前节点前面的 tag 和字符串进行迭代, find_all_previous() 方法返回所有符合条件的节点, find_previous()方法返回第一个符合条件的节点
那有朋友说,假如html代码里有css样式表等使用符号【#】的又怎么处理呢?
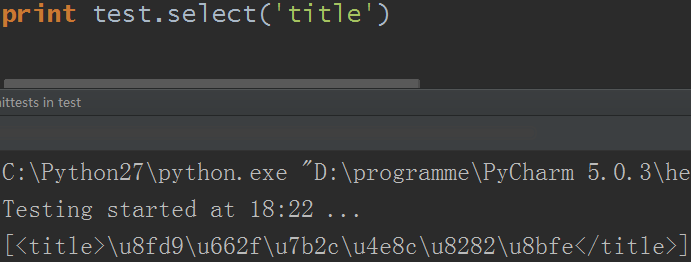
15.select()方法
可以对css样式表查询,返回列表对象
1)通过标签名查找
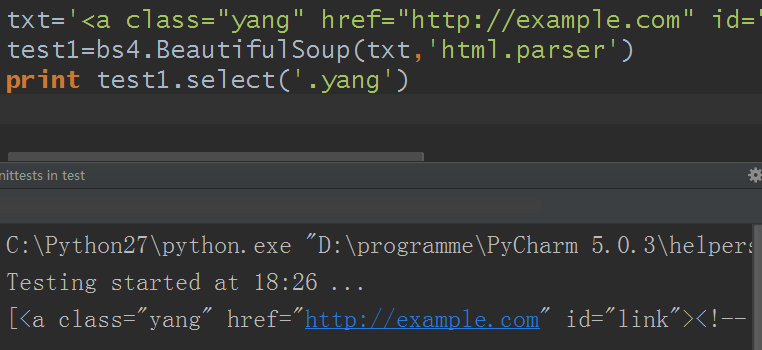
2)通过class类名查找
那个常用例子并没有class的,所以另设一个例子
txt='<a class="yang" href="http://example.com" id="link"><!-- test --></a>'
test1=bs4.BeautifulSoup(txt,'html.parser')
print test1.select('.yang')
结果:
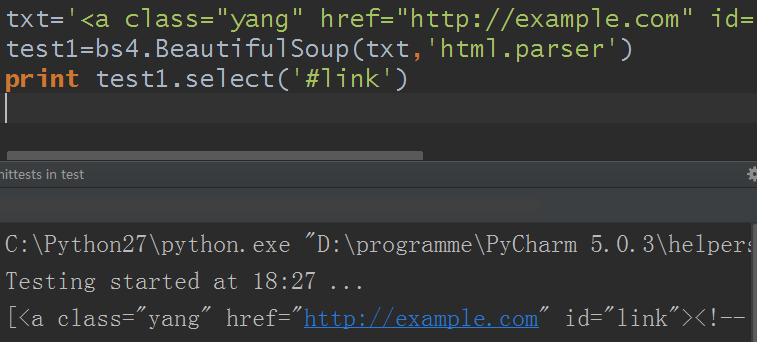
3)通过 id 名查找
与通过class查找一样:
txt='<a class="yang" href="http://example.com" id="link"><!-- test --></a>'
test1=bs4.BeautifulSoup(txt,'html.parser')
print test1.select('#link')
结果:
4)组合查找
组合使用标签名与类名、id名进行查找,和单独查找原理一样,注意不在同一节点的空格隔开,同一节点的不加空格。详细的略过
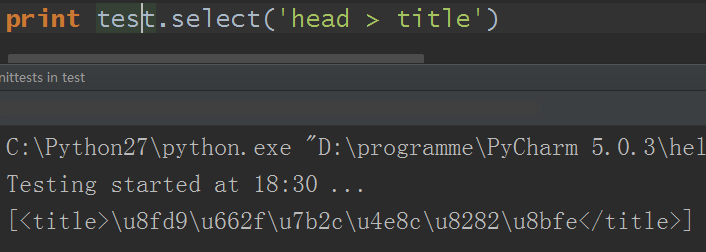
5)子标签查找
原来的例子:
6)属性查找
可以加入属性元素,属性需要用中括号括起来,注意属性和标签属于同一节点,所以中间不能加空格,否则会无法匹配到
属性查找同样可以与上面的查找方式组合,不在同一节点的空格隔开,同一节点的不加空格
注意:
- select()返回的既然是列表,那么可以运用所有符合列表的方法,自己去发现了
- 利用select()可以达到同find_all效果相同
内容比较多,其实官方的文档都还有些,不过那些基本不怎么用了,所以就这些吧,只有查找提取的方法,这已经完完全全的够用了
Normal
0
7.8 磅
0
2
false
false
false
EN-US
ZH-CN
X-NONE
/* Style Definitions */
table.MsoNormalTable
{mso-style-name:普通表格;
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-noshow:yes;
mso-style-priority:99;
mso-style-parent:"";
mso-padding-alt:0cm 5.4pt 0cm 5.4pt;
mso-para-margin:0cm;
mso-para-margin-bottom:.0001pt;
mso-pagination:widow-orphan;
font-size:10.5pt;
mso-bidi-font-size:11.0pt;
font-family:"Calibri","sans-serif";
mso-ascii-font-family:Calibri;
mso-ascii-theme-font:minor-latin;
mso-hansi-font-family:Calibri;
mso-hansi-theme-font:minor-latin;
mso-font-kerning:1.0pt;}
洗礼灵魂,修炼python(66)--爬虫篇—BeauitifulSoup进阶之“我让你忘记那个负心汉,有我就够了”的更多相关文章
- 洗礼灵魂,修炼python(15)--列表进阶话题—>列表解析/列表生成器
是的,我是想到什么知识点就说什么,没有固定的主题,我的标题都是在写完博客再给的.本篇博文说说列表进阶话题.其实列表应该是比较熟悉的了,而毫不夸张的说,在实际的开发中,列表也是使用的最多的,以后你会体会 ...
- 洗礼灵魂,修炼python(16)--列表进阶话题—>上节作业讲解+copy模块,浅拷贝,深拷贝
上节课后作业: 1.使用列表解析输出结果:[(0,0),(0,2),(2,0),(2,2)] 方法1: 方法2: 方法3: 2.使用列表生成器打印斐波那契数列 3.使用列表解析生成列表[1x2,3x4 ...
- Python学习——爬虫篇
requests 使用requests进行爬取 下面是我编写的第一个爬虫的脚本 import requests # 导入reques ...
- Python学习—爬虫篇之破解ntml登陆问题
之前帮公司爬取过内部的一个问题单网站,要求将每个问题单的下的附件下载下来.一开始的时候我就遇到一个破解登陆验证的大坑...... (╬ ̄皿 ̄)=○ 由于在公司使用的都是内网,代码和网站的描述 ...
- 洗礼灵魂,修炼python(69)--爬虫篇—番外篇之feedparser模块
feedparser模块 1.简介 feedparser是一个Python的Feed解析库,可以处理RSS ,CDF,Atom .使用它我们可从任何 RSS 或 Atom 订阅源得到标题.链接和文章的 ...
- 洗礼灵魂,修炼python(72)--爬虫篇—爬虫框架:Scrapy
题外话: 前面学了那么多,相信你已经对python很了解了,对爬虫也很有见解了,然后本来的计划是这样的:(请忽略编号和日期,这个是不定数,我在更博会随时改的) 上面截图的是我的草稿 然后当我开始写博文 ...
- 洗礼灵魂,修炼python(71)--爬虫篇—【转载】xpath/lxml模块,爬虫精髓讲解
Xpath,lxml模块用法 转载的原因和前面的一样,我写的没别人写的好,所以我也不浪费时间了,直接转载这位崔庆才大佬的 原帖链接:传送门 以下为转载内容: --------------------- ...
- 洗礼灵魂,修炼python(70)--爬虫篇—补充知识:json模块
在前面的某一篇中,说完了pickle,但我相信好多朋友都不懂到底有什么用,那么到了爬虫篇,它就大有用处了,而和pickle很相似的就是JSON模块 JSON 1.简介 1)JSON(JavaScrip ...
- 洗礼灵魂,修炼python(63)--爬虫篇—re模块/正则表达式(1)
爬虫篇前面的某一章了,我们要爬取网站页面源代码的数据,要从中获取到我们想要的数据,是不是感觉很费力,确实费力对吧?那么有没有什么有利的工具来解决这个问题呢?那就是这一篇博文的主题—— 正则表达式简介 ...
随机推荐
- 西安活动 | 9月15号 "拥抱开源, 又见.NET" 线下交流活动
随着.NET Core的发布和开源,.NET又重新回到了人们的视野.除了开源.跨平台.高性能以及优秀的语言特性,越来越多的第三方开源库也出现在了github上——包括ML.NET机器学习.Xamari ...
- ES6躬行记(2)——扩展运算符和剩余参数
扩展运算符(Spread Operator)和剩余参数(Rest Parameter)的写法相同,都是在变量或字面量之前加三个点(...),并且只能用于包含Symbol.iterator属性的可迭代对 ...
- Deep learning with Python 学习笔记(11)
总结 机器学习(machine learning)是人工智能的一个特殊子领域,其目标是仅靠观察训练数据来自动开发程序[即模型(model)].将数据转换为程序的这个过程叫作学习(learning) 深 ...
- 【Go】优雅的读取http请求或响应的数据-续
原文链接:https://blog.thinkeridea.com/201902/go/you_ya_de_du_qu_http_qing_qiu_huo_xiang_ying_de_shu_ju_2 ...
- 实战!基于lamp安装wordpress详解-技术流ken
简介 LAMP 是Linux Apache MySQL PHP的简写,其实就是把Apache, MySQL以及PHP安装在Linux系统上,组成一个环境来运行动态的脚本文件.现在基于lamp搭建wor ...
- SpringBoot学习(三)-->Spring的Java配置方式之读取外部的资源配置文件并配置数据库连接池
三.读取外部的资源配置文件并配置数据库连接池 1.读取外部的资源配置文件 通过@PropertySource可以指定读取的配置文件,通过@Value注解获取值,具体用法: @Configuration ...
- 使用Topshelf开发Windows服务、log4net记录日志
开发windows服务,除了在vs里新建服务项目外(之前有写过具体开发方法,可点击查看),还可以使用Topshelf. 不过使用topshelf需要.netframework 4.5.2版本,在vs2 ...
- Java学习笔记之——String和Arrays常用方法
一.String常用方法 1.subString(int beginIndex,int endIndex) 截取字符串 从beginIndex开始截取,截取endIndex-beginIndex的长度 ...
- python中的eval函数
eval() 函数十分强大 -- 将字符串 当成 有效的表达式 来求值 并 返回计算结果 In [1]: eval("1 + 3") Out[1]: 4 In [2]: eval( ...
- python基础学习(三)变量和类型
变量的作用:变量就是用来存储数据的. 变量的定义 在python中,变量在使用之前需要进行赋值,变量只有赋值后才能使用,如果变量没有赋值就使用会出现什么情况呢?如下图,使用之前变量未定义,会报错,如下 ...