cuda编程-并行规约
利用shared memory计算,并避免bank conflict;通过每个block内部规约,然后再把所有block的计算结果在CPU端累加
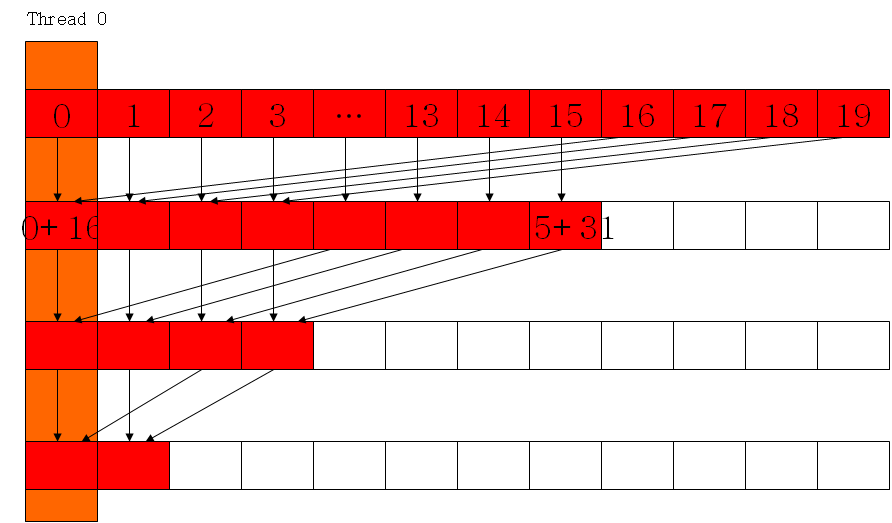
代码:
#include <cuda_runtime.h>
#include <device_launch_parameters.h>
#include <stdio.h>
#include <stdlib.h>
#include <memory>
#include <iostream> #define DATA_SIZE 128
#define TILE_SIZE 64 __global__ void reductionKernel(float *in, float *out){
int tx = threadIdx.x;
int bx = blockIdx.x; __shared__ float data_shm[TILE_SIZE];
data_shm[tx] = in[bx * blockDim.x + tx];
__syncthreads(); for (int i = blockDim.x / ; i > ; i >>= ){
if (tx < i){
data_shm[tx] += data_shm[tx + i];
}
__syncthreads();
} if (tx == )
out[bx] = data_shm[];
} void reduction(){
int out_size = (DATA_SIZE + TILE_SIZE - ) / TILE_SIZE;
float *in = (float*)malloc(DATA_SIZE * sizeof(float));
float *out = (float*)malloc(out_size*sizeof(float));
for (int i = ; i < DATA_SIZE; ++i){
in[i] = i;
}
memset(out, , out_size*sizeof(float)); float *d_in, *d_out;
cudaMalloc((void**)&d_in, DATA_SIZE * sizeof(float));
cudaMalloc((void**)&d_out, out_size*sizeof(float));
cudaMemcpy(d_in, in, DATA_SIZE * sizeof(float), cudaMemcpyHostToDevice); dim3 block(TILE_SIZE, );
dim3 grid(out_size, );
reductionKernel << <grid, block >> >(d_in, d_out); cudaMemcpy(in, d_in, DATA_SIZE * sizeof(float), cudaMemcpyDeviceToHost);
cudaMemcpy(out, d_out, out_size * sizeof(float), cudaMemcpyDeviceToHost); float sum = ;
for (int i = ; i < out_size; ++i){
sum += out[i];
}
std::cout << sum << std::endl; // Check on CPU
float sum_cpu = ;
for (int i = ; i < DATA_SIZE; ++i){
sum_cpu += in[i];
}
std::cout << sum_cpu << std::endl; }
cuda编程-并行规约的更多相关文章
- CUDA中并行规约(Parallel Reduction)的优化
转自: http://hackecho.com/2013/04/cuda-parallel-reduction/ Parallel Reduction是NVIDIA-CUDA自带的例子,也几乎是所有C ...
- 【Cuda编程】加法归约
目录 cuda编程并行归约 AtomicAdd调用出错 gpu cpu下时间计算 加法的归约 矩阵乘法 矩阵转置 统计数目 平方和求和 分块处理 线程相邻 多block计算 cuda编程并行归约 At ...
- CUDA编程(六)进一步并行
CUDA编程(六) 进一步并行 在之前我们使用Thread完毕了简单的并行加速,尽管我们的程序运行速度有了50甚至上百倍的提升,可是依据内存带宽来评估的话我们的程序还远远不够.在上一篇博客中给大家介绍 ...
- cuda编程基础
转自: http://blog.csdn.net/augusdi/article/details/12529247 CUDA编程模型 CUDA编程模型将CPU作为主机,GPU作为协处理器(co-pro ...
- CUDA学习笔记(一)——CUDA编程模型
转自:http://blog.sina.com.cn/s/blog_48b9e1f90100fm56.html CUDA的代码分成两部分,一部分在host(CPU)上运行,是普通的C代码:另一部分在d ...
- CUDA编程
目录: 1.什么是CUDA 2.为什么要用到CUDA 3.CUDA环境搭建 4.第一个CUDA程序 5. CUDA编程 5.1. 基本概念 5.2. 线程层次结构 5.3. 存储器层次结构 5.4. ...
- CUDA编程-(1)Tesla服务器Kepler架构和万年的HelloWorld
结合CUDA范例精解以及CUDA并行编程.由于正在学习CUDA,CUDA用的比较多,因此翻译一些个人认为重点的章节和句子,作为学习,程序将通过NVIDIA K40服务器得出结果.如果想通过本书进行CU ...
- CUDA编程模型
1. 典型的CUDA编程包括五个步骤: 分配GPU内存 从CPU内存中拷贝数据到GPU内存中 调用CUDA内核函数来完成指定的任务 将数据从GPU内存中拷贝回CPU内存中 释放GPU内存 *2. 数据 ...
- CUDA编程之快速入门
CUDA(Compute Unified Device Architecture)的中文全称为计算统一设备架构.做图像视觉领域的同学多多少少都会接触到CUDA,毕竟要做性能速度优化,CUDA是个很重要 ...
随机推荐
- 数组复制的五种方式(遍历循环一一赋值、System.arraycopy、地址赋值、克隆clone()、Arrays.copyof())
package com.Summer_0424.cn; import java.util.Arrays; import java.util.concurrent.CopyOnWriteArrayLis ...
- Java性能优化之编程技巧总结
程序的性能受代码质量的直接影响.在本文中,主要介绍一些代码编写的小技巧和惯例,这些技巧有助于在代码级别上提升系统性能. 1.慎用异常 在Java软件开发中,经常使用 try-catch 进行错误捕获, ...
- BZOJ1997 平面图判定 平面图性质 2-sat
相交的两条边不能在同一侧,用2-sat即可. 平面图点数-边数关系 \(E\le 3V-6\) 写这篇文章我只是想说明,知乎一小时,题解一分钟. lb Zhihu, gos langar Qarwet ...
- matplotlib中subplot的使用
#plt.subplot的使用 import numpy as npimport matplotlib.pyplot as pltx=[1,2,3,4]y=[5,4,3,2]plt.subplot(2 ...
- java问题
Collection 和 Collections的区别? Collection是集合类的上级接口,继承与他的接口主要有Set 和List. Collections是针对集合类的一个帮助类,他提供一系列 ...
- [2017BUAA软工助教]第0次作业小结
BUAA软工第0次作业小结 零.题目 作业链接: This is a hyperlink 一.评分规则 本次作业满分10分: 按时提交有分 一周内补交得0分 超过一周不交或抄袭倒扣全部分数 评分规则如 ...
- Notepad++插件下载和介绍
20款Notepad++插件下载和介绍 - findumars - 博客园https://www.cnblogs.com/findumars/p/5180562.html
- HTTL之初印象
概述 HTTL (Hyper-Text Template Language) 是一个高性能的开源JAVA模板引擎, 适用于动态HTML页面输出, 可替代JSP页面, 指令和Velocity相似. 简洁 ...
- 1 Expression of Possiblity
Expression of possibility Probably Perhaps There's a change(that) It's very likly(that) It's pos ...
- Select2 4.0.5 API
详细属性参考官方API,https://github.com/select2/select2/releases/tag/4.0.5 注:4.0.5版本API与3.x版本有差异,有些属性已废弃,以下列出 ...