Feature Extractor[googlenet v1]
1 - V1
google团队在模型上,更多考虑的是实用性,也就是如何能让强大的深度学习模型能够用在嵌入式或者移动设备上。传统的想增强模型的方法无非就是深度和宽度,而如果简单的增加深度和宽度,那么带来的更大参数要训练和需要更强大的计算资源去计算。所以,google团队要做的就是如何在保证模型准确度的情况下减少模型参数。
解决模型复杂和计算资源两个问题的基本方法是:将全连接转换成稀疏连接的结构,甚至在卷积层中都希望有稀疏链接的结构。除了说这是模仿生物结构的一方面,这样的好处还有更加支持了arora等人的开创性的理论工作:arora等人认为如果数据集的概率分布可以通过一个非常大的,非常稀疏的dnn来表示,那么最优的网络拓扑模型可以通过分析最后一层的激活函数值的相关统计信息和对高相关性的输出做一个神经元聚类来逐层构建。虽然严格的数学证明需要非常强的假设,不过这个现状的确符合hebbian原则:神经元都是一起被激活的,如tica的结构一样。同样的该原则也给出了一些潜在的idea,即实际操作中可以适当放宽严格的约束条件(稀疏性,聚类准确度等等)。
然而现在的计算设备对于非均匀的稀疏的数据结构的数值计算并不高效。即使所需要的算数操作降低100倍之多也没用,因为主要的瓶颈在于值的查找和每次cache的失效,所以就算转换成稀疏矩阵的形式去计算也没有太大改善。而且当如果程序使用的还是不断改进的,高度调整的,为了更快计算密矩阵相乘的,不断的去压榨底层cpu和gpu的数值库,那么这两者之间的差距会进一步被拉大。
非均匀系数模型需要更老练的工程技术和计算设备来计算。当前大多数的视觉机器模型都是通过使用卷积来实现空间上的稀疏,然而在cnn的前层中卷积都被实现成到patch的密连接集合。虽然最早的cnn(lenet5)在特征维度上使用随机和稀疏连接,从而就能打破对称性,并有助于学习。然而后面又变成全连接是因为有利于并行计算,且统一的结构和大量的滤波器和更大的batch size都是为了使用更有效的密计算。
那么我们就想了,是否有一个结构能使用额外的稀疏性,即使在卷积层,并且在现有的设备上使用的还是现在常用的密集矩阵的计算方式。虽然在稀疏矩阵计算方面大量的文献都推荐将稀疏矩阵聚类成相对密集的子矩阵,从而在实际中能达到很好的结果。不过这并不表示可以在近期能用在非均匀稀疏的深度结构上。
所以从模型稀疏性角度出发,让模型在结构设计上尽可能的稀疏,即使是在传统的卷积层结构中,也要强化稀疏的重要性。
googlenet v1受到《network in network》和《Robust object recognition with cortex-like mechanisms》的启发,成功的提出了一个构建块模型,Inception。而且实验发现,在明显增加了深度和宽度的基础上,准确度没下降。
1.1 模型
inception结构主要的想法就是为了找出在卷积视觉网络中能够基于现有的密集组件去构成的一种最优的局部稀疏结构。
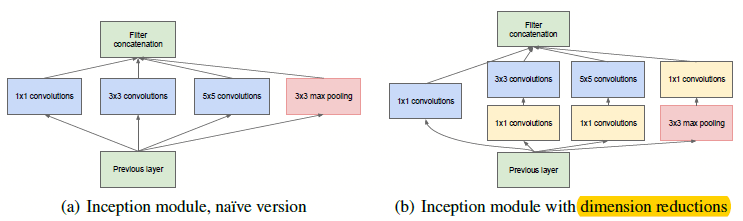
图1.1 inception模块
如图1.1,inception模块的好处是可以同时得到不同尺度的卷积,且能够同时馈送到下一层;且有\(1*1\)的帮助,能够允许在每个阶段显着增加单元数量,却不会让计算复杂性急剧上升。

图1.2 googlenet网络结构
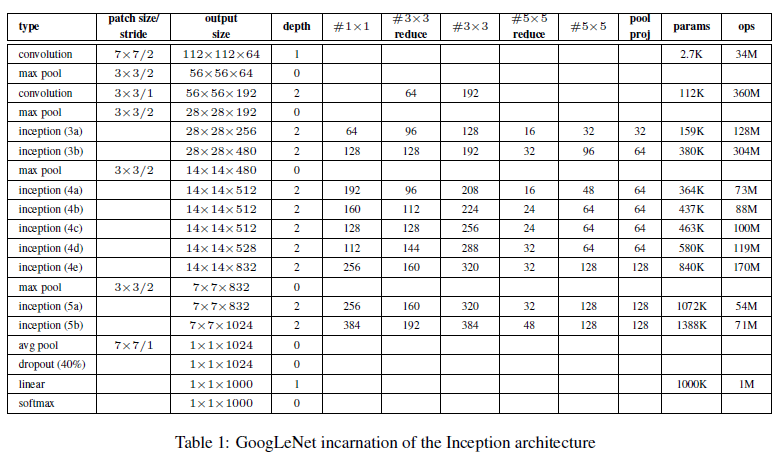
图1.3 googlenet的网络参数结构图
图1.2中有2个辅助的子网络,这是因为对于很深的网络来说,BP传递残差的时候,最前面得到的梯度会越来越小,所以通过增加辅助子网络,有助于前面层也得到更大的梯度。其中2个辅助子网络在训练阶段存在,预测阶段就扔掉不参与预测。且2个子网络都以0.3的权重比例将最后的损失值加到主分类器上。
其中辅助子网络有如下结构:
- 0 - 一个\(5*5\)大小尺寸的平均池化,stride为3,在4a上生成\(4*4*512\)的输出;在4d上生成\(4*4*528\)的输出;
- 1 - 128个\(1*1\)的卷积核用来维度约间,使用的是Relu;
- 2 - 一个1024个单元的全连接层,使用的是Relu;
- 3 - 一个dropout层,其中的概率是70%;
- 4 - 用softmax作为分类器。
参考文献:
[] - Thomas Serre, Lior Wolf, Stanley M. Bileschi, Maximilian Riesenhuber, and Tomaso Poggio. Robust object recognition with cortex-like mechanisms. IEEE Trans. Pattern Anal. Mach. Intell., 29(3):411–426, 2007.
[] - Min Lin, Qiang Chen, and Shuicheng Yan. Network in network. CoRR, abs/1312.4400, 2013
[] - Sanjeev Arora, Aditya Bhaskara, Rong Ge, and Tengyu Ma. Provable bounds for learning some deep representations. CoRR, abs/1310.6343, 2013.
Feature Extractor[googlenet v1]的更多相关文章
- Feature Extractor[inception v2 v3]
0 - 背景 在经过了inception v1的基础上,google的人员还是觉得有维度约间的空间,在<Rethinking the Inception Architecture for Com ...
- Feature Extractor[content]
0. AlexNet 1. VGG VGG网络相对来说,结构简单,通俗易懂,作者通过分析2013年imagenet的比赛的最好模型,并发现感受野还是小的好,然后再加上<network in ne ...
- Feature Extractor[ResNet]
0. 背景 众所周知,深度学习,要的就是深度,VGG主要的工作贡献就是基于小卷积核的基础上,去探寻网络深度对结果的影响.而何恺明大神等人发现,不是随着网络深度增加,效果就好的,他们发现了一个违背直觉的 ...
- Feature Extractor[SENet]
0.背景 这个模型是<Deep Learning高质量>群里的牛津大神Weidi Xie在介绍他们的VGG face2时候,看到对应的论文<VGGFace2: A dataset f ...
- Feature Extractor[VGG]
0. 背景 Karen Simonyan等人在2014年参加Imagenet挑战赛的时候提出的深度卷积神经网络.作者通过对2013年的ILSVRC中最好的深度神经网络模型(他们最初的对应模型都是ale ...
- Feature Extractor[Inception v4]
0. 背景 随着何凯明等人提出的ResNet v1,google这边坐不住了,他们基于inception v3的基础上,引入了残差结构,提出了inception-resnet-v1和inception ...
- Feature Extractor[ResNet v2]
0. 背景 何凯明大神等人在提出了ResNet网络结构之后,对其做了进一步的分析工作,详细的分析了ResNet 构建块能起作用的本质所在.并通过一系列的实验来验证恒等映射的重要性,并由此提出了新的构建 ...
- Feature Extractor[DenseNet]
0.背景 随着CNN变得越来越深,人们发现会有梯度消失的现象.这个问题主要是单路径的信息和梯度的传播,其中的激活函数都是非线性的,从而特别是乘法就可以使得随着层数越深,假设将传统的神经网络的每一层看成 ...
- 图像金字塔(pyramid)与 SIFT 图像特征提取(feature extractor)
David Lowe(SIFT 的提出者) 0. 图像金字塔变换(matlab) matlab 对图像金字塔变换接口的支持(impyramid),十分简单好用. 其支持在reduce和expand两种 ...
随机推荐
- Android gradle实现多渠道号打包
在build.gradle中添加 productFlavors{ LETV { applicationId "×××××××××××" //包名 buildConfigFiel ...
- python 交互式命令行数据库连接助手 -- mysql、sql server (mssql)、redis
目录 python 交互式命令行数据库连接助手 0. 操作示例 1. python 连接mssql 2. python 连接mysql 3. python 连接redis n. Tips python ...
- List泛型与DataTable相互转换
public static class ExtensionMethods{/// <summary>/// 将List转换成DataTable/// </summary>/// ...
- Amazon onsite behavior question
https://www.1point3acres.com/bbs/thread-307462-1-1.html http://kraftshala.com/how-to-raise-the-bar-i ...
- phprpc的使用示例以及报错Fatal error: Cannot redeclare gzdecode() in D:\wamp\www\immoc\phprpc\compat.php 处理
今天看书,发现了PHPRPC这个好东东,故在此写下来以作笔记. PHPRPC 是一个轻型的.安全的.跨网际的.跨语言的.跨平台的.跨环境的.跨域的.支持复杂对象传输的.支持引用参数传递的.支持内容输出 ...
- FastCGI Error Number: 5 (0x80070005).
在访问网站的时候,出现了以上这个错误: 在网上搜了很多方法,归纳起来就如下几种: 1, 网站安全狗]的安全策略问题 解决方案: 主动防御/禁止IIS执行程序 添加"php\php-cgi.e ...
- 线程--实现Runnable接口
实现Runnable接口,创建线程步骤: 1.定义类,并实现Runnable接口 2.重写Runnable接口中的run()方法 3.通过Thread类建立线程对象 4.将实现了Runnable接口的 ...
- spark基础知识
1.Spark是什么? UCBerkeley AMPlab所开源的类HadoopMapReduce的通用的并行计算框架. dfsSpark基于mapreduce算法实现的分布式计算,拥有HadoopM ...
- 学习RabbitMQ(三):AMQP事务机制
本文转自:http://m.blog.csdn.net/article/details?id=54315940 在使用RabbitMQ的时候,我们可以通过消息持久化操作来解决因为服务器的异常奔溃导致的 ...
- 51nod 1238 最小公倍数之和 V3
51nod 1238 最小公倍数之和 V3 求 \[ \sum_{i=1}^N\sum_{j=1}^N lcm(i,j) \] \(N\leq 10^{10}\) 先按照套路推一波反演的式子: \[ ...