大数据学习笔记3 - 并行编程模型MapReduce
分布式并行编程用于解决大规模数据的高效处理问题。分布式程序运行在大规模计算机集群上,集群中计算机并行执行大规模数据处理任务,从而获得海量计算能力。
MapReduce是一种并行编程模型,用于大规模数据集的并行运算,那么MapReduce又是如何进行并行编程的呢?
MapReduce采用“分而治之”的策略,将存储在分布式文件系统的大数据集切分成独立小数据块(即Split,分片),这些分片可以被多个Map任务并行处理。MapReduce强调“计算向数据靠拢”而非“数据向计算靠拢”,传统模式下,对数据进行处理时需要将待处理的数据集中到程序所在机器上(数据向计算靠拢),数据的移动需要网络开销。而在MapReduce模型下,一般将计算程序就近运行在数据所在节点,即将计算节点和存储节点放在一起运行,从而减少节点间数据移动开销。在架构上,采用Master/Slave架构,Master上运行JobTracker(负责任务调度),Slave运行TaskTracker(负责执行任务)。适用于MapReduce来处理的数据集需要满足一个前提条件:待处理的数据集可以分解成许多小的数据集,且每一个小数据集都能完全并行地处理。
MapReduce将复杂的运行于大规模集群上的并行计算过程抽象到Map和Reduce两个函数,两个函数均由程序开发者负责具体实现,程序员只需关注实现两个函数,无需处理并行编程中其他问题,如分布式存储、工作调度等。Map和Reduce函数都是以<key, value>作为输入,按一定的映射规则转换成另一个或一批<key, value>进行输出。
Map函数
输入:<key, value> 如:WordCount中的<行号,行内容>
输出:List(<key2, value2>) 如:<字母, 字母出现的频数>
Map函数的输入来自分布式文件系统的文件块(文件块格式任意,如文档、二进制等),文件块是一系列元素的集合,同一元素不能跨文件块存储。Map函数将输入的元素转换成<key, value>形式,其中key不具有唯一性。一个<key, value>会输出一批<key2, value2>,<key2, value2>是计算的中间结果。
Reduce函数
输入:<key2, list(value2)> 这里输入的中间结果<key2, list(value2)>中的List(value2)是一批属于同一个key2的value
输出:<key3, value3>
Reduce负责将输入的一系列具有相同键的键值对以某种方式结合起来,输出处理之后的键值对,输出结果会合并成一个文件。用户可以指定Reduce任务数,通知实现系统,主控进程通过Hash函数,将Map输出的键经过Hash计算结果,根据hash结果将键值对输入给相应的Reduce任务。
MapReduce工作流程
MapReduce采用分而治之的思想,把大的数据集拆分成多个小数据块在多台机器上并行处理。一个大的MapReduce作业,首先被拆分成多个Map任务在多台机器上并行执行,每个Map任务通常运行在数据存储的节点上,Map任务结束后,生成<key, value>形式的中间结果,这些中间结果被分发到多个Reduce任务在多台机器上并行执行,具有相同key的Map中间结果会被分配到相同的Reduce任务上,Reduce任务对中间结果进行汇总计算得到最后结果。
MapReduce的各个执行阶段如下:
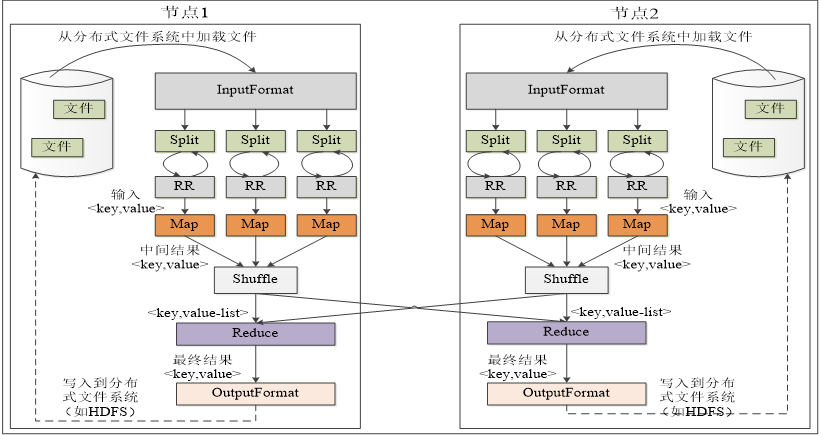
(1)首先IputFormat模块进行Map前的预处理,对输入进行格式验证,然后把大的输入文件切分为逻辑上的多个InputSplite ,这里注意 InputSplit是逻辑概念,并未对文件进行实际切割,只是记录要处理的数据的位置和长度。
(2)通过RecordReader(RR)根据InputSplit中的信息处理具体记录,加载数据并转换成适合Map任务读取的键值对,输入给Map任务;
(3)Map任务根据用户定义的规则输出一系列<key, value>作为中间结果;
(4)在Reduce并行处理Map结果前,对Map的输出进行一定分区、排序、合并、归并等操作。得到<key, value-list>形式的中间结果,再交给Reduce处理,这个过程称作Shuffle,完成从无序的<key, value>到有序的<key, value-list>
(5)Reduce以<key, value-list>为输入,执行用户自定义逻辑,输出结果给OutputFormat模块;
(6)OutputFormat模块验证输出目录是否已经存在以及输出结果类型是否符合配置文件中的配置类型,如果满足,则将Reduce结果输出到分布式文件系统。
注:
- Map任务的输入和Reduce任务的输出都被保存在分布式文件系统中,Map得到的中间结果保存在本地磁盘中
- 只有当Map处理全部结束后,Reduce过程才能开始
- Map需要考虑数据局部性,实现计算向数据靠拢,Reduce无需考虑
- 块和分片的关系,block是HDFS的基本存储单位,是物理概念,split是MapReduce的处理单位,是逻辑概念,只包含类似块的起始位置、数据长度等信息,它的划分由用户决定,hadoop会为每个split创建一个Map任务,split划分过大,并行效率低,划分过小,增加数据传输,多数时候理想的split大小是一个block。
- Map任务数量取决于split的数量,reduce任务的数量取决于集群中可用的reduce的slot数,通常稍小于slot数。
Shuffle过程
Shuffle是MapReduce工作流程中的核心环节,是指对Map输出的中间结果进行分区、排序、合并等处理并交给Reduce的过程,分为Map端和Reduce端的操作。
Map端的Shuffle:
(1)读取并处理一个split:从分布式文件系统读取数据并进行映射计算,得到一批<key, value>进行输出;
(2)Map输出结果首先写入缓存,每个Map任务都会被分配一个缓存(使用缓存减少磁盘交互);
(3)缓存满(默认100M)后启动溢写(Spill)操作,把当前Map任务缓存中的数据一次性批量写入磁盘, 并清空缓存。溢写操作通常由单独的后台线程来完成,不影响Map结果写入缓存。一般设置一个溢写比例(如0.8),保证缓存中一直有可用的空间,满足持续写入中间结果的需求。
在溢写之前,需要先对缓存中的数据进行分区(Partition),分区的任务是为了确定下一步的reduce任务。 通过Partitoner接口对缓存中的键值对进行分区,默认分区方式是采用Hash函数对key进行哈希再用Reduce任务数进行取模,将Map结果分配给Reducce任务。用户可通过重载接口自定义分区方式。
对于每个分区内的所有键值对,后台线程会根据key对其进行内存排序。排序是默认操作
排序后,合并(Combine)操作是可选的,它的目的是减少磁盘操作。如果用户事先定义Combine函数,执行合并操作。合并是将具有相同key的键值对合并(将value加起来),减少键值对的数量。并不是所有场景都可以进行合并,Combiner的输出是Reduce的输入,合并不能改变Reduce任务的最终计算结果,一般而言,累加、最大值等场景可以进行合并操作。
在这些操作结束后,缓存中的数据被写入磁盘,每次溢写都会在磁盘中生成一个新的溢写文件,文件中数据都是经过分区和排序的。
(4)文件归并
当磁盘中溢写文件过多时,在Map任务全部结束之前,系统会对所有溢写文件中的数据进行归并(Merge),生成大的溢写文件,这个大溢写文件的数据也都是经过分区和排序的。归并是将具有相同key的键值对归并成一个新的键值对,如,<k1, v1>……<k1, vn>会被归并成新的键值对<k1, <v1……vn>>
至此,Map端的Shuffle过程完成,最终生成一个大文件存储在本地磁盘上,大文件中的数据是被分区的,不同分区的数据被发送到不同的Reduce任务进行并行处理。JobTracker在监测到一个Map任务结束后,就会通知相关Reduce任务来领取数据,开始Reduce端的Shufllle过程。
Reduce端的Shuffle:
(1)“领取”数据
Reduce任务将写入Map任务本地磁盘的数据Fetch到自己所在机器的本地磁盘上。每个Reduce任务不断通过RPC向JobTracker询问Map是否完成,完成后,通知相应的Reduce来Fetch数据。一般系统中存在多个Map任务,因此Reduce会使用多个线程同时从多个Map机器领回数据。
(2)归并数据
从Map领回的数据先放入Reduce的缓存中,缓存满后进行溢写,写到磁盘中。由于fetch的数据来自多个Map机器,一般缓存中的数据还可以合并,在溢写过程启动时,会归并具有相同key的键值对,如果定义了Combiner,在归并后还可以合并,减少写入磁盘的数据量。磁盘上的多个溢写文件里的数据也需要经过排序和归并,当需要多轮归并的时候,可以调整每轮归并的文件数量。
(3)把数据输入给Reduce任务
磁盘中经过多轮归并的若干大文件,不会继续归并,而是直接输入给Reduce任务,至此,整个Shufflejieshu。Reduce任务执行Reduce函数定义的映射,输出最终结果。
注意:
- 合并(Combine)和归并(Merge)的区别:两个键值对<"a", 1>和<"a", 1>,合并后,得到<"a", 2>;如果归并,得到<"a", <1,1>>
MapReduce的具体应用
在使用MapReduce对数据进行处理时,
首先,需要考虑是否可以使用MapReduce,前面提到过,MapReduce处理的数据集需要满足:待处理的数据集可以分解成许多小的数据集,且每个小数据集可以完全并行地进行处理;
然后,需要确定MapReduce程序的实现思路,这一步主要考虑宏观上程序的逻辑步骤。
最后,要确定程序的具体实现方式。程序的实现需要考虑Map和Reduce函数的输入、输出、函数内部的映射逻辑等。
MapReduce可以应用于各种计算问题,如关系代数运算、分组聚合运算等。
1、MapReduce在关系代数运算中的应用
关系运算包括选择、投影、并、交差、自然连接等,下面介绍基于MapReduce模型的关系运算方式。
- 选择运算:
仅仅需要Map过程,对于关系R中的每个元组t,监测该元组是否满足条件,如果满足,则输出键值对<t,t>,Reduce函数使用恒等式。
- 投影运算:
设R投影后的属性集为S。Map函数中,对R中每个t剔除t中不属于S的字段,得到元组t‘,输出<t‘, t‘>。经过投影后生成的元组可能存在冗余,在Reduce函数中剔除冗余的<t‘, t‘>,把属性值完全相同的元组合并起来的到<t‘, <t‘,t‘,t‘>,剔除冗余后输出<t‘, t‘>。
大数据学习笔记3 - 并行编程模型MapReduce的更多相关文章
- 大数据学习笔记——Java篇之网络编程基础
Java网络编程学习笔记 1. 网络编程基础知识 1.1 网络分层图 网络分层分为两种模型:OSI模型以及TCP/IP网络模型,前者模型分为7层,是一个理论的,参考的模型:后者为实际应用的模型,具体对 ...
- 大数据学习笔记——Hadoop编程实战之HDFS
HDFS基本API的应用(包含IDEA的基本设置) 在上一篇博客中,本人详细地整理了如何从0搭建一个HA模式下的分布式Hadoop平台,那么,在上一篇的基础上,我们终于可以进行编程实操了,同样,在编程 ...
- 大数据学习笔记1-大数据处理架构Hadoop
Hadoop:一个开源的.可运行于大规模集群上的分布式计算平台.实现了MapReduce计算模型和分布式文件系统HDFS等功能,方便用户轻松编写分布式并行程序. Hadoop生态系统: HDFS:Ha ...
- 大数据学习笔记——Linux完整部署篇(实操部分)
Linux环境搭建完整操作流程(包含mysql的安装步骤) 从现在开始,就正式进入到大数据学习的前置工作了,即Linux的学习以及安装,作为运行大数据框架的基础环境,Linux操作系统的重要性自然不言 ...
- 大数据学习笔记——Java篇之集合框架(ArrayList)
Java集合框架学习笔记 1. Java集合框架中各接口或子类的继承以及实现关系图: 2. 数组和集合类的区别整理: 数组: 1. 长度是固定的 2. 既可以存放基本数据类型又可以存放引用数据类型 3 ...
- 大数据学习笔记——Hadoop编程实战之Mapreduce
Hadoop编程实战——Mapreduce基本功能实现 此篇博客承接上一篇总结的HDFS编程实战,将会详细地对mapreduce的各种数据分析功能进行一个整理,由于实际工作中并不会过多地涉及原理,因此 ...
- 大数据学习笔记之Hadoop(三):MapReduce&YARN
文章目录 一 MapReduce概念 1.1 为什么要MapReduce 1.2 MapReduce核心思想 1.3 MapReduce进程 1.4 MapReduce编程规范(八股文) 1.5 Ma ...
- 大数据学习笔记——Linux基本知识及指令(理论部分)
Linux学习笔记整理 上一篇博客中,我们详细地整理了如何从0部署一套Linux操作系统,那么这一篇就承接上篇文章,我们仔细地把Linux的一些基础知识以及常用指令(包括一小部分高级命令)做一个梳理, ...
- 大数据学习笔记——Java篇之IO
IO学习笔记整理 1. File类 1.1 File对象的三种创建方式: File对象是一个抽象的概念,只有被创建出来之后,文件或文件夹才会真正存在 注意:File对象想要创建成功,它的目录必须存在! ...
随机推荐
- Ubuntu16.04下安装Hyperledger Fabric 1.0.0
系统环境 * Ubuntu: 16.04 * Go: 1.9.2 * NodeJS: v6.12.0 * Docker: 17.09.0-ce * HyperLedger Fabric: 1.0.0 ...
- 打印上三角或下三角矩阵(9x9) - perl, R
欲打印矩阵位置示意图 #!/usr/bin/perl -w use strict; ## bottom left ..) { ..) { if($col <= $row) { print $ro ...
- symfony 踩坑之旅 视频实操从第九章开始
1.annotation定义路由 @Route("/**",defaults={"name":"world"},requirements={ ...
- 解除Portal for ArcGIS与ArcGIS Server的联合
将ArcGIS Server站点添加到Portal中,可以实现ArcGIS Server站点的单点登录特性,并可以与Portal共享Server站点发布的内容,同时通过将联合服务器注册为托管服务器后还 ...
- Qt之菜单栏工具栏入门
菜单栏基本操作 创建菜单栏 QMenuBar *menuBar = new QMenuBar(this); //1.创建菜单栏 menuBar->setGeometry(,,width(),); ...
- Java中ArrayList和LinkedList区别(转)
具体详情参考原博客: http://pengcqu.iteye.com/blog/502676
- 给查询出的SQL记录添加序号列,解决方法有以下两种
第一: select ROW_NUMBER() OVER (ORDER BY a.字段 ASC) AS XUHAO,a.* from table a (table 为表名,字段为表a中的字段名) 第二 ...
- 转:VB.NET Office操作之Word
在这里给出了一个Word操作的类,该类具备了对word 文档操作的基本功能,包括word 文档的新建,打开,保存,另存,插入图片,插入表格,插入文字,读取文字,定位光标位置,移动光标,移动到指定页等等 ...
- docker的核心概念和安装
里Dcoker的安装要求 我这里安装的是在vmware下的centos7 64位 并且通过模拟远程连接xshell 我在安装好之后就配置了静态ip,这里我就不多说怎么配置了 具体静态ip配置可以参考 ...
- Android几种视频播放方式,VideoView、SurfaceView+MediaPlayer、TextureView+MediaPlayer,以及主流视频播放器开源项目
简单的说下一Android的几种视频播放功能: 1.VideoView:最简单的视频播放 <FrameLayout xmlns:android="http://schemas.andr ...