SQLALchemy中关于复杂关系表模型的映射处理
映射在第五步,我们还是一步一步来哈
一. 关系介绍
举一个比较经典的关系,部门与员工(以下是我的需求情况,算是把该有的关系都涉及到了)
1.每个部门会有很多成员(这里排除一个成员属于多个部门的情况) ---> 一对多
2.每个部门都有一个负责人 ---> 多对一
3.每个部门可能有一个上级部门 ---> 自关联多对一
4.每个员工都有一个主属部门 ---> 多对一
5.每个员工可能有很多附属部门 ---> 多对多
6.每个员工可能有很多上级员工 ---> 自关联多对多
二. 设计部门与成员表模型
直接附上模型表代码,但是不包含关系映射(单独写一步)
from sqlalchemy.ext.declarative import declarative_base
BaseModel = declarative_base() # 创建模型对象的基类 # 部门
class Department(BaseModel):
__tablename__ = 'dep'
id = Column(Integer(), primary_key=True, autoincrement=True)
name = Column(String(30),nullable=False,unique=True) # 部门名称
staff_id = Column(Integer(),ForeignKey('staff.id')) # 负责人
up_dep_id = Column(Integer(),ForeignKey('dep.id')) # 上级部门----自关联
def __repr__(self): # 方便打印查看
return '<Department %s>' % self.name # 员工
class Staff(BaseModel):
__tablename__ = 'staff'
id = Column(Integer(), primary_key=True, autoincrement=True)
name = Column(String(30),nullable=False,unique=True) # 员工名称
main_dep_id = Column(Integer(),ForeignKey('dep.id')) # 主要部门
def __repr__(self):
return '<Staff %s>' % self.name
三. 设计第三方表模型--附属部门与上级员工
建立多对多关系映射时secondary参数需要指定一个第三方表模型对象,但不是自己写的Class哦,而是一个Table对象
from sqlalchemy import Table # 使用Table专门生成第三方表模型 # 第三方表--附属部门
aux_dep_table = Table('staff_aux_dep',BaseModel.metadata,
Column('id',Integer(),primary_key=True, autoincrement=True),
Column('dep_id', Integer(), ForeignKey('dep.id',ondelete='CASCADE')),
Column('staff_id', Integer(), ForeignKey('staff.id',ondelete='CASCADE'))
)
# 第三方表--上级员工
up_obj_table = Table('staff_up_obj',BaseModel.metadata,
Column('id',Integer(),primary_key=True, autoincrement=True),
Column('up_staff_id', Integer(), ForeignKey('staff.id',ondelete='CASCADE')),
Column('down_staff_id', Integer(), ForeignKey('staff.id',ondelete='CASCADE'))
)
四. 生成表
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker engine = create_engine('mysql+pymysql://root:123456@localhost:3306/test?charset=utf8') # 关联数据库
DBSession = sessionmaker(engine) # 创建DBSession类
session = DBSession() # 创建session对象 BaseModel.metadata.create_all(engine) # 数据库生成表
五. relationship--关系映射
简单来说, relationship函数是sqlalchemy对关系之间提供的一种便利的调用方式, relationship的返回值赋给的变量名为正向调用的属性名,绑定给当前表模型类中,而backref参数则是指定反向调用的属性名,绑定给关联的表模型类中,如下部门表中Department.staffs就为正向,Staff.main_dep就为反向。
先导入relationship
from sqlalchemy.orm import relationship
先映射部门表,需要注意的是:
1. 是由于部门与员工之间有多重外键约束,在多对一或一对多关系相互映射时需要用foreign_keys指定映射的具体字段
2. 自关联多对一或一对多时候,需要用remote_side参数指定‘一’的一方,值为一个Colmun对象(必须唯一)
# 部门
class Department(BaseModel):
__tablename__ = 'dep'
id = Column(Integer(), primary_key=True, autoincrement=True)
name = Column(String(30), nullable=False, unique=True) # 部门名称
staff_id = Column(Integer(), ForeignKey('staff.id')) # 负责人
up_dep_id = Column(Integer(), ForeignKey('dep.id')) # 上级部门----自关联
# 主属部门为此部门的所有员工,反向Staff实例.main_dep获取员工的主属部门
main_staffs = relationship('Staff', backref='main_dep', foreign_keys='Staff.main_dep_id')
# 部门的直属上级部门,反向Department实例.down_deps,获取部门的所有直属下级部门(自关联多对一需用remote_side=id指定‘一’的一方)
up_dep = relationship('Department', backref='down_deps', remote_side=id)
重新生成数据(当调用属性映射的为‘多’的一方,则代表的是一个InstrumentedList 类型的结果集,是List的子类,对这个集合的修改,就是修改外键关系)
staff_names = ['我','你','他','她','它']
dep_names = ['1部','2部','21部','22部']
staff_list = [Staff(name=name) for name in staff_names]
dep_list = [Department(name=name) for name in dep_names] # 为所有员工初始分配一个主属部门(按列表顺序对应)
[dep.main_staffs.append(staff) for staff,dep in zip(staff_list,dep_list)] # 关联上下级部门(2部的上级为1部,2部的下级为21、22部)
dep_list[1].up_dep = dep_list[0]
dep_list[1].down_deps.extend(dep_list[2:]) session.add_all(staff_list + dep_list)
session.commit() # 数据持久化到数据库
部门表关系映射 查询测试
dep_2 = session.query(Department).filter_by(name='2部').one() # 获取 2部 部门
staff_me = session.query(Staff).filter(Staff.name=='我').one() # 获取 ‘我’ 员工
print(dep_2.main_staffs) # 主属部门为2部的所有员工
print(dep_2.up_dep) # 2部的上级部门
print(dep_2.down_deps) # 2部的所有直属下级部门
print(staff_me.main_dep) # 员工‘我’ 的主属部门 # [<Staff 你>]
# <Department 1部>
# [<Department 21部>, <Department 22部>]
# <Department 1部>
映射员工表,需要注意的是:
1. 多对多关系中需要用secondary参数指定第三方表模型对象
2. 自关联多对多需要用primaryjoin和secondaryjoin指定主副连接关系,查询逻辑是根据主连接关系对应的第三方表的字段查询(例,查询id为10的员工的所有上级对象,就会在第三方表里查询down_staff_id=10对应的所有数据,而把每条数据的up_staff_id值对应员工表的id查询出来的对象集合,就为id为10的员工的所有上级对象了)
# 员工
class Staff(BaseModel):
__tablename__ = 'staff'
id = Column(Integer(), primary_key=True, autoincrement=True)
name = Column(String(30), nullable=False, unique=True) # 员工名称
main_dep_id = Column(Integer(), ForeignKey('dep.id')) # 主要部门 # 员工的所有附属部门,反向为所有附属部门为此部门的员工
aux_deps = relationship(Department, secondary=aux_dep_table,backref = 'aux_staffs')
# 员工的所有直属上级员工,反向为员工的所有直属下级员工(自关联多对多需要指定第三方表主连接关系与副连接关系,查询逻辑是根据主连接关系对应的第三方表的字段查询)
up_staffs = relationship('Staff', secondary=up_obj_table,
primaryjoin = id == up_obj_table.c.down_staff_id, # 主连接关系 为 本表id字段对应第三方表的down_staff_id
secondaryjoin = id == up_obj_table.c.up_staff_id, # 副连接关系 为 本表id对应第三表的up_staff_id
backref = 'down_staffs')
建立数据映射关系
staff_all_list = session.query(Staff).all() # 获取所有员工对象列表
dep_1 = session.query(Department).filter_by(name='1部').one() # 获取 部门 1部
dep_2 = session.query(Department).filter_by(name='2部').one() # 获取 部门 2部
staff_me = session.query(Staff).filter_by(name='我').one() # 获取员工 ‘我’ dep_1.aux_staffs.extend(staff_all_list) # 分配所有员工的附属部门都为1部
staff_me.aux_deps.append(dep_2) # 给员工‘我’额外分配附属部门2部
staff_all_list.remove(staff_me)
staff_me.down_staffs.extend(staff_all_list) # 将所有除员工‘我’以外的员工 都成为 员工‘我’的下级
session.commit()
员工表关系映射 查询测试
staff_you = session.query(Staff).filter_by(name='你').one() # 获取员工 你 print(dep_1.aux_staffs.all()) # 所有附属部门为1部的员工
print(staff_me.aux_deps.all()) # 员工‘我’ 的所有附属部门
print(staff_me.down_staffs.all()) # 员工‘我’ 的所有直属下级员工
print(staff_you.up_staffs.all()) # 员工‘你’ 的所有直属上级员工 # [<Staff 我>, <Staff 你>, <Staff 他>, <Staff 她>, <Staff 它>]
# [<Department 1部>]
# [<Staff 你>, <Staff 他>, <Staff 她>, <Staff 它>]
# [<Staff 我>]
如果我们想根据调用属性获得的集合,再进行筛选,可以吗?
模拟个场景,我已经知道了员工‘我’有一个附属部门叫‘1部’了,我想知道除了‘1部’的其他附属部门,如下:
from sqlalchemy import not_
staff_me.aux_deps.filter(not_(Department.name=='1部')) # AttributeError: 'InstrumentedList' object has no attribute 'filter'
报错了,也是,之前都说了,调用属性映射的为‘多’的一方代表的是一个InstrumentedList 对象,只有为Query对象才能有filter、all、one等的方法。
那么该怎么转换成Query对象呢,通过查看relationship的参数,发现了lazy,通过改变它的值可以在查询时可以得到不同的结果,他有很多值可以选择:
1. 默认值为select, 他直接会导出所有的结果对象合成一个列表
aux_deps = relationship(Department, secondary=aux_dep_table, backref='aux_staffs', lazy='select')
print(type(staff_me.aux_deps))
print(staff_me.aux_deps) # <class 'sqlalchemy.orm.collections.InstrumentedList'>
# [<Department 1部>, <Department 2部>]
2. dynamic,他会生成一个继承与Query的AppenderQuery对象,可以用于继续做过滤操作,这就是我们模拟的场景想要的,需要注意的是,如果调用属性映射的不是‘多’而是‘一’的一方,那么就会报错(虽然为默认值select没有影响,但本来就一个结果,就不要加lazy参数了)
aux_deps = relationship(Department, secondary=aux_dep_table, backref='aux_staffs', lazy='dynamic')
print(type(staff_me.aux_deps))
print(staff_me.aux_deps.all()) # 获取员工‘我’的所有附属部门
print(staff_me.aux_deps.filter(not_(Department.name == '1部')).all()) # 获取员工‘我’除1部以外的所有附属部门 # <class 'sqlalchemy.orm.dynamic.AppenderQuery'>
# [<Department 1部>, <Department 2部>]
# [ <Department 2部>]
3. 其他的还有很多参数,例如joined,连接查询,使用不当会有性能问题,以下为谷歌翻译的,大家有兴趣可以去看看原文https://docs.sqlalchemy.org/en/latest/orm/relationship_api.html,ctrl+f搜lazy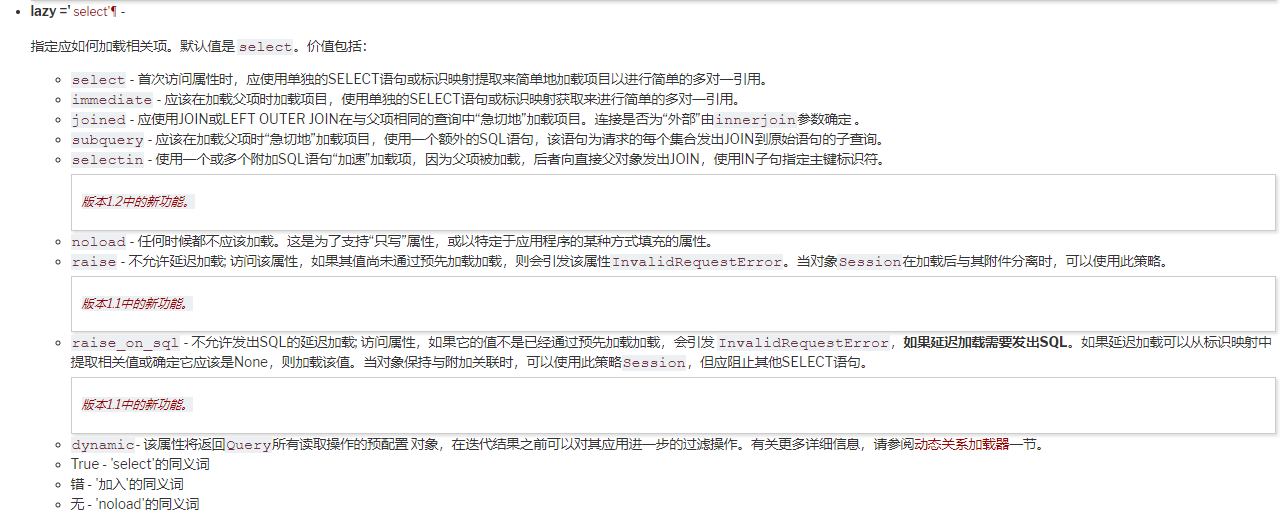
我们现在知道当需要对映射的结果集继续筛选的时候,可以在relationship指定lazy参数为'dynamic',但是在这里加好像只是正向调用的时候有效,反向还是为InstrumentedList 对象
dep_1 = session.query(Department).filter_by(name='1部').one() # 获取 部门 1部
print(dep_1.aux_staffs.all()) # 获取所有附属部门为1部的员工 # AttributeError: 'InstrumentedList' object has no attribute 'all'
如果反向的时候我们该加在哪里呢?其实backref参数也可以接受一个元祖,里面只能是两个参数,一个跟之前一样是个字符串,为反向调用的属性名,另一个就是一个加关于反向调用时的参数(dict对象)
aux_deps = relationship(Department, secondary=aux_dep_table, backref=('aux_staffs',{'lazy':'dynamic'}), lazy='dynamic')
print(type(dep_1.aux_staffs.all()))
print(dep_1.aux_staffs.all()) # 获取所有附属部门为1部的员工
# <class 'sqlalchemy.orm.dynamic.AppenderQuery'>
# [<Staff 我>, <Staff 你>, <Staff 他>, <Staff 她>, <Staff 它>]
掌握了如上,之后使用SQLALchemy在工作中遇到的奇葩关系应该都能处理了吧,我语言组织能力比较弱,有什么错误还请指出----1738268742@qq.com
SQLALchemy中关于复杂关系表模型的映射处理的更多相关文章
- Openstack_SQLAlchemy_一对多关系表的多表插入实现
目录 目录 Openstack 与 SQLAlchemy 一个多表插入的 Demo 小结 Openstack 与 SQLAlchemy SQLAlchemy 是 Python 语言下的一款开源软件,它 ...
- arclistsg独立单表模型文档列表
arclistsg独立单表模型文档列表 (DedeCMS > 5.3) 名称:arclistsg 功能:类似arclist标签,获取指定单表模型(例如:分类信息),指定栏目,指定排序及呈现样式的 ...
- flask SQLAlchemy中一对多的关系实现
SQLAlchemy是Python中比较优秀的orm框架,在SQLAlchemy中定义了多种数据库表的对应关系, 其中一对多是一种比较常见的关系.利用flask sqlalchemy实现一对多的关系如 ...
- sqlalchemy的数据库ORM操作(表之间的关系)
首先导入一些需要的东东 ,我是在flask中写的,也可以用纯python去写. from flask import Flask from sqlalchemy import create_engine ...
- 用SQLAlchemy创建一对多,多对多关系表
多对多关系表的创建: 如果建立好多对多关系后,我们就可以通过关系名进行循环查找,比如laowang = Teacher.query.filter(Teacher.name=='laowang').fi ...
- Django中模型层中ORM的多表操作
ORM的多表创建(一对一.一对多,多对多): 1模型创建 实例:我们来假定下面这些概念,字段和关系 作者模型:一个作者有姓名和年龄. 作者详细模型:把作者的详情放到详情表,包含生日,手机号,家庭住址等 ...
- Django 08 Django模型基础3(关系表的数据操作、表关联对象的访问、多表查询、聚合、分组、F、Q查询)
Django 08 Django模型基础3(关系表的数据操作.表关联对象的访问.多表查询.聚合.分组.F.Q查询) 一.关系表的数据操作 #为了能方便学习,我们进入项目的idle中去执行我们的操作,通 ...
- Python与数据库[2] -> 关系对象映射/ORM[5] -> 利用 sqlalchemy 实现关系表查询功能
利用 sqlalchemy 实现关系表查询功能 下面的例子将完成一个通过关系表进行查询的功能,示例中的数据表均在MySQL中建立,建立过程可以使用 SQL 命令或编写 Python 适配器完成. 示例 ...
- 如何使用sqlalchemy根据数据库里面的表反推出模型,然后进行查询
关于sqlalchemy映射数据库里面的表,一般情况下我们是需要定义一个模型来映射数据库里面的表的.但是很多时候数据库里面的表都是定义好的,而且字段很多,那么有没有不定义模型,还能使用orm语法查找数 ...
随机推荐
- hbase整合
hbase與hive整合 1. hive中有數據 --> 創建hive管理表映射hbase 例如: 1)hive創建內部表 create tabl ...
- 普通路由器刷开源固件DD-WRT的简单过程
DD-WRT是基于Linux的无线路由软件,功能强大,它提供了许多一般路由器的软体所没有的功能,将路由器固件升级到DD-WRT可以提升内建于预设固件的限制,并将其转换成强大且具有进阶功能的商业级路由器 ...
- wps excel
ET.Application etApp;ET.workbook etbook;ET.Worksheet etsheet ;ET.Range etrange;//获取工作表表格etApp = new ...
- How To Add Custom Build Steps and Commands To setup.py
转自:https://jichu4n.com/posts/how-to-add-custom-build-steps-and-commands-to-setuppy/ A setup.py scrip ...
- edgedb 内部pg 数据存储的探索 (四) 源码编译
edgedb 基于python开发,同时源码重包含了好多子项目,以下进行简单的源码编译 clone 代码 需要递归处理,加上recursive,比较慢稍等 git clone --recursiv ...
- bond-team
nmcli con add type team con-name team0 ifname team0 config '{"runner":{"name": & ...
- java中移位运算
转自: https://blog.csdn.net/wk1134314305/article/details/74891419
- defer、return、返回值,这三者的执行逻辑
defer.return.返回值,这三者的执行逻辑是: return 最先执行,return 负责将结果写入返回值中:接着defer执行,可能修改返回值:最后函数携带当前返回值退出.
- Qt applendPlainText()/append() 多添加一个换行解决方法
Qt applendPlainText()/append() 多添加一个换行解决方法 void ConsoleDialog::appendMessageToEditor(const QString & ...
- .NET 使用 Azure Blob 存储图片或文件
使用的是VS2017 一.先使用 NuGet 获取这两个包. 执行以下步骤: 在“解决方案资源管理器”中,右键单击你的项目并选择“管理 NuGet 包”. 1.在线搜索“WindowsAzure.St ...