cuda by example【读书笔记2】
常量内存
用常量内存来替换全局内存可以有效的减少内存带宽
__constant__修饰符标识常量内存,从主机内存复制到GPU上的常量内存时,需要特殊版本的cudaMemcpy(): cudaMemcpyToSymbol(),从而会复制到常量内存,而原来的会复制到全局内存。
1. 对常量内存的单次读操作可以广播到其他的邻近线程,这将节约15次读取操作(因为这里线程块包含16个线程)
2. 常量内存的数据将缓存起来,因此对相同地址的连续读操作将不会产生额外的内存通信量。
解释邻近线程:CUDA架构中,线程束是指一个包含32个线程的集合,编织在一起,'步调一致'Lockstep,程序中的每一行,线程束中的每个线程都将在不同数据上执行相同的指令。 当处理常量内存时,GPU硬件把单次内存读取操作广播到每个半线程束(16个线程),如果其中每个线程都从常量内存的相同地址上读取数据,那么GPU只会产生一次读取请求并随后将数据广播到每个线程,这时内存流量是只使用全局内存时的1/16。
另外并不仅限于此,由于这块内存的内容是不变的,因此硬件会主动把这个常量数据缓存到GPU上,在第一次从常量内存的某个地址上读取后,其他半线程请求同一地址时,将命中缓存,从而不会产生内存流量。
1. 线程在半线程束的广播中收到这个数据
2. 从常量内存缓存中收到数据
然而常量内存半线程广播也是双刃剑,当16个线程分别读取不同的地址时,会降低性能,会被串行化,从而需要16倍的时间发出请求,如果从全局内存读,那么会同时请求,这样常量内存就慢于全局内存了。
cuda设备代码计时的设计cudaEventRecord是cpu和gpu上是异步的,这样统计gpu的运行时间很麻烦,为了同步,可以将其改为cudaEventSynchronize(stop)。值得注意的是,CUDA事件是直接在GPU上实现的,因此不适用于同时包含设备代码和主机代码的混合代码计时。
纹理内存
它也是一种只读内存,同样缓存在芯片上,专门针对那些在内存访问模式中存在大量空间局部性。即一个线程读取的位置可能与邻近线程读取位置非常接近。
texture<float> 将输入的数据声明为texture类型,分配内存后需要通过cudaBindTexture( )将这些变量绑定到内存缓冲区。
1. 我们希望将指定的缓冲区作为纹理来使用
2. 我们希望将纹理引用作为纹理的名字
当读取内存时不再使用方括号从缓冲区中读取,而是使用tex1Dfetch( ),因为纹理引用必须声明为文件作用域的全局变量,所以不再将输入缓冲区和输出缓冲区作为参数传递,而是用bool值标识使用哪个缓冲区作为输入或输出。 最后需要对纹理解绑,cudaUnbindTexture( )
二维纹理,代码会更简洁,并可以自动处理边界问题 texture<float,2> 表示二维纹理引用,将tex1Dfetch( )改为tex2D( )如果超出边界,自动返回合法值。不用线性化offset,直接用x,y访问纹理,在绑定二维纹理缓存时,CUDA运行时需要提供一个cudaChannelFormatDesc,文中指定浮点描述符,然后通过cudaBindTexture2D( )绑定。解绑函数相同。
原子性
举个例子x++,通过某种方式一次性的执行完读取-修改-写入这三个操作,并且在执行过程中不会被其他线程中断。除非已经完成了这三个操作,否则其他的线程都不能读取或写入x的值。
atomicAdd(&x, 1 ) //原子操作加一
在全局内存中的原子操作效率很低,数千个线程发生竞争。在共享内存中的原子操作,只有线程块内的线程之间竞争,会缓解很多。注意__syncthreads( )的同步使用,最后要在全局内存中再次对所有线程块中共享内存数组原子求和。
流
用于不同任务之间的并行
页锁定主机内存
malloc( )分配的是可分页的主机内存。 cudaHostAlloc( )会分配页锁定主机内存(不可分页内存)。操作系统将不会对这块内存分页并交换到磁盘上,其他应用程序可以安全的访问该内存物理地址,因为这块内存将不会被破坏或重新定位。但它也是双刃剑,你将失去虚拟内存的所有功能。建议仅对cudaMemcpy( )调用中的源内存或目标内存使用页锁定内存,并在不再需要使用它们时立即释放。
CUDA流
cudaMemcpyAsync( )是异步的,只是放置一个请求,表示在流中执行一次内存复制操作,当函数返回时无法确认复制操作是否启动更无法保证是否完成,能够保证的是复制操作在下一个被放入流中的操作之前执行。另外,任何传递给cudaMemcpyAsync( )的主机内存指针必须已经通过cudaHostAlloc( )分配好,即只能以异步方式对页锁定内存进行复制操作。 核函数尖括号中可以带有一个流参数,并异步执行,流就像一个有序的工作队列。将GPU与主机同步,cudaStreamSynchronize(stream)
可重叠的GPU,可以利用多个流实现执行核函数的同时在主机和GPU之间执行内存复制。
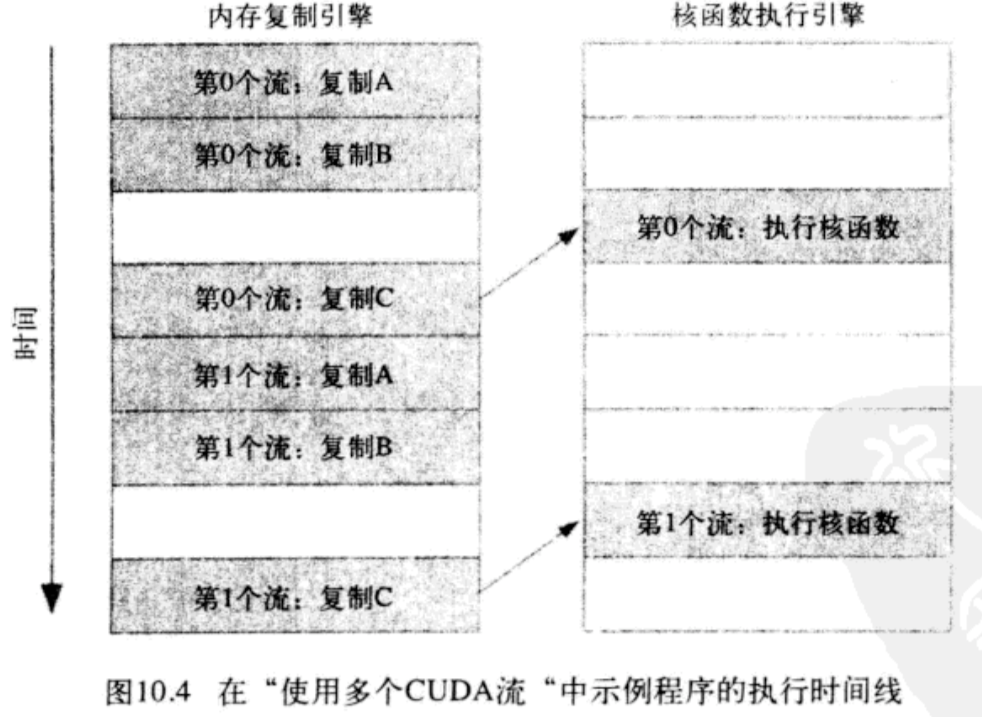
dfs模式,因为依赖关系的限制,第二个流的操作被阻塞

采用bfs模式多流交替执行的并行效果更好,第0个流复制C不会阻塞第1个流复制A和B
零拷贝内存
将cudaHostAlloc( )分配内存的参数修改为cudaHostAllocMapped可以申请零拷贝内存,它也是固定的内存,除了用于主机和GPU之间的内存复制之外,打破了之前的主机内存规则之一:可以在CUDA C核函数中直接访问这种类型的主机内存,由于这种内存不需要复制到GPU,因此也称为零拷贝内存。 在GPU上访问需要cudaHostGetDevicePointer( )得到CPU上这块内存的指针,然后传递给核函数。后面需要用cudaThreadSynchronize( )实现CPU和GPU之间的同步。使用前要先判断设备是否支持映射主机内存。
多GPU
每个GPU都需要一个不同的CPU线程来控制,将数据分块,书中给的例子在主线程中新建一个线程,被调用函数内指定GPU ID其他操作正常
可移动的固定内存
某个线程分配了固定内存,那么这些内存页仅对单个CPU线程来说是固定的(页锁定的),如果在其他线程之间共享指向这块内存的指针,那么其他的线程将把这块内存视为标准可分页的内存。 可移动内存可以解决这个问题,cudaMemcpyAsync( )的参数是cudaHostAllocPortable,可以与其他标志一起使用。
附录
CUFFT
优化后的快速傅里叶变换,实数复数之间的变换,一维二维三维变换
CUBLAS
基本线程代数子程序
NVIDIA GPU Computing SDK
有很多示例文档程序
CUDA-GDB
用来调试CUDA C

CUDA Visual Profiler
可视化分析工具运行核函数
programming massively parallel processors a hands-on approach
这本书会介绍GPU底层工作原理,CUDA架构的许多细节
论坛:
高级原子操作:实现锁定数据结构
CUDA散列表
由GPU向CPU拷贝散列表的指针处理

散列表的每个桶上都有一个互斥锁,解决不同线程映射到相同的桶同时改写的覆盖问题。
这里那个循环很特别,线程束是32个线程,每次在线程束中只有一个线程会获取这个锁,如果同时竞争会出现问题,最好的方式是在程序中执行一部分工作,遍历线程束并给每一个线程一次获取锁的机会。

cuda by example【读书笔记2】的更多相关文章
- 远程办公《Remote》读书笔记:中国程序员在家上班月入过六万不是梦
这不是一本新书,这是一本很值得中国程序员看的老书,所以我不是来做卖新书广告的:) 但它的确是一本好书,这本书在Amazon上3个business categories排第一.作者Jason Fried ...
- 读书笔记汇总 - SQL必知必会(第4版)
本系列记录并分享学习SQL的过程,主要内容为SQL的基础概念及练习过程. 书目信息 中文名:<SQL必知必会(第4版)> 英文名:<Sams Teach Yourself SQL i ...
- 读书笔记--SQL必知必会18--视图
读书笔记--SQL必知必会18--视图 18.1 视图 视图是虚拟的表,只包含使用时动态检索数据的查询. 也就是说作为视图,它不包含任何列和数据,包含的是一个查询. 18.1.1 为什么使用视图 重用 ...
- 《C#本质论》读书笔记(18)多线程处理
.NET Framework 4.0 看(本质论第3版) .NET Framework 4.5 看(本质论第4版) .NET 4.0为多线程引入了两组新API:TPL(Task Parallel Li ...
- C#温故知新:《C#图解教程》读书笔记系列
一.此书到底何方神圣? 本书是广受赞誉C#图解教程的最新版本.作者在本书中创造了一种全新的可视化叙述方式,以图文并茂的形式.朴实简洁的文字,并辅之以大量表格和代码示例,全面.直观地阐述了C#语言的各种 ...
- C#刨根究底:《你必须知道的.NET》读书笔记系列
一.此书到底何方神圣? <你必须知道的.NET>来自于微软MVP—王涛(网名:AnyTao,博客园大牛之一,其博客地址为:http://anytao.cnblogs.com/)的最新技术心 ...
- Web高级征程:《大型网站技术架构》读书笔记系列
一.此书到底何方神圣? <大型网站技术架构:核心原理与案例分析>通过梳理大型网站技术发展历程,剖析大型网站技术架构模式,深入讲述大型互联网架构设计的核心原理,并通过一组典型网站技术架构设计 ...
- LOMA280保险原理读书笔记
LOMA是国际金融保险管理学院(Life Office Management Association)的英文简称.国际金融保险管理学院是一个保险和金融服务机构的国际组织,它的创建目的是为了促进信息交流 ...
- 《3D Math Primer for Graphics and Game Development》读书笔记2
<3D Math Primer for Graphics and Game Development>读书笔记2 上一篇得到了"矩阵等价于变换后的基向量"这一结论. 本篇 ...
- 《3D Math Primer for Graphics and Game Development》读书笔记1
<3D Math Primer for Graphics and Game Development>读书笔记1 本文是<3D Math Primer for Graphics and ...
随机推荐
- http和ftp下载的区别
HTTP和FTP是两种网络传输协议的缩写,FTP是File Transportation Protocol(文件传输协议)的缩写,而HTTP则是Hyper Text Transportation Pr ...
- 神经网络中的偏置项b到底是什么?
原文地址:https://blog.csdn.net/Uwr44UOuQcNsUQb60zk2/article/details/81074408 前言 很多人不明白为什么要在神经网络.逻 ...
- 微信小程序-聊天列表-角标
<div class="list-body" bindtap='openChat' data-Obj='{{oitem}}'> <!-- 头像 --> &l ...
- 修改SIP协议中的User-Agent名称
修改目的:如果user-agent 带上了 GIT 版本信息,容易被人抓住版本漏洞针对性的攻击. 示例如下: SIP/2.0 100 Trying Via: SIP/2.0/UDP 192.168.5 ...
- oracle 11.2.0.4 rac 打补丁
本次安装pus环境是11.2.0.4 rac,打的patch为11.2.0.4.180717 (Includes Database PSU),gi补丁和数据库补丁一起打 安装最新opatch版本 un ...
- django-form介绍
Django form表单 目录 普通方式手写注册功能 views.py login.html 使用form组件实现注册功能 views.py login2.html 常用字段与插件 initia ...
- Tornado学习笔记(一) helloword/多进程/启动参数
前言 当你觉得你过得很舒服的时候,你肯定没有在进步.所以我想学习新的东西,然后选择了Tornado.因为我觉得Tornado更匹配目前的我的综合素质. Tornado学习笔记系列主要参考<int ...
- JS打开新的窗口
一.使用JS打开新窗口 1. 超链接<a href="http://www.wumz.me" title="Mauger`s Blog">Welco ...
- Java对象之间的深度复制拷贝
/* * Copyright (c) 1995, 2011, Oracle and/or its affiliates. All rights reserved. * ORACLE PROPRIETA ...
- java如何将一个List传入Oracle存储过程
注:本文来源于 深圳gg < java如何将一个List传入Oracle存储过程 > 一:数据库端建一个PL/SQL的数组. CREATE OR REPLACE TYPE tabl ...