scala flatmap、reduceByKey、groupByKey
1、test.txt文件中存放
asd sd fd gf g
dkf dfd dfml dlf
dff gfl pkdfp dlofkp
// 创建一个Scala版本的Spark Context
val conf = new SparkConf().setAppName("wordCount")
val sc = new SparkContext(conf)
// 读取我们的输入数据
val input = sc.textFile(inputFile)
// 把它切分成一个个单词
val words = input.flatMap(line => line.split(" "))
//words为------------------
asd
sd
fd
gf
g
dkf
dfd
dfml
dlf
dff
gfl
pkdfp
dlofkp
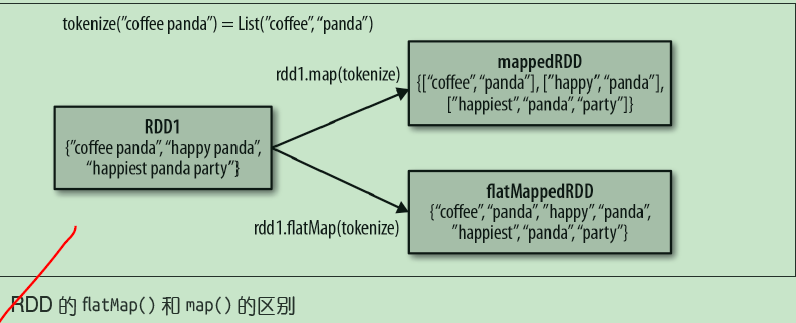
val counts = words.map(word => (word, 1)).reduceByKey{case (x, y) => x + y}
// 将统计出来的单词总数存入一个文本文件,引发求值
counts.saveAsTextFile(outputFile)
//reduceByKey 合并key计算

2、reduceByKey 合并key计算
按key求和
val rdd = sc.parallelize(List((“a”,2),(“b”,3),(“a”,3))) 合并key计算
val r1 = rdd.reduceByKey((x,y) => x + y) 输出结果如下 (a,5)
(b,3)
reduceByKey:reduceByKey会在结果发送至reducer之前会对每个mapper在本地进行merge,有点类似于在MapReduce中的combiner。
这样做的好处在于,在map端进行一次reduce之后,数据量会大幅度减小,从而减小传输,保证reduce端能够更快的进行结果计算。
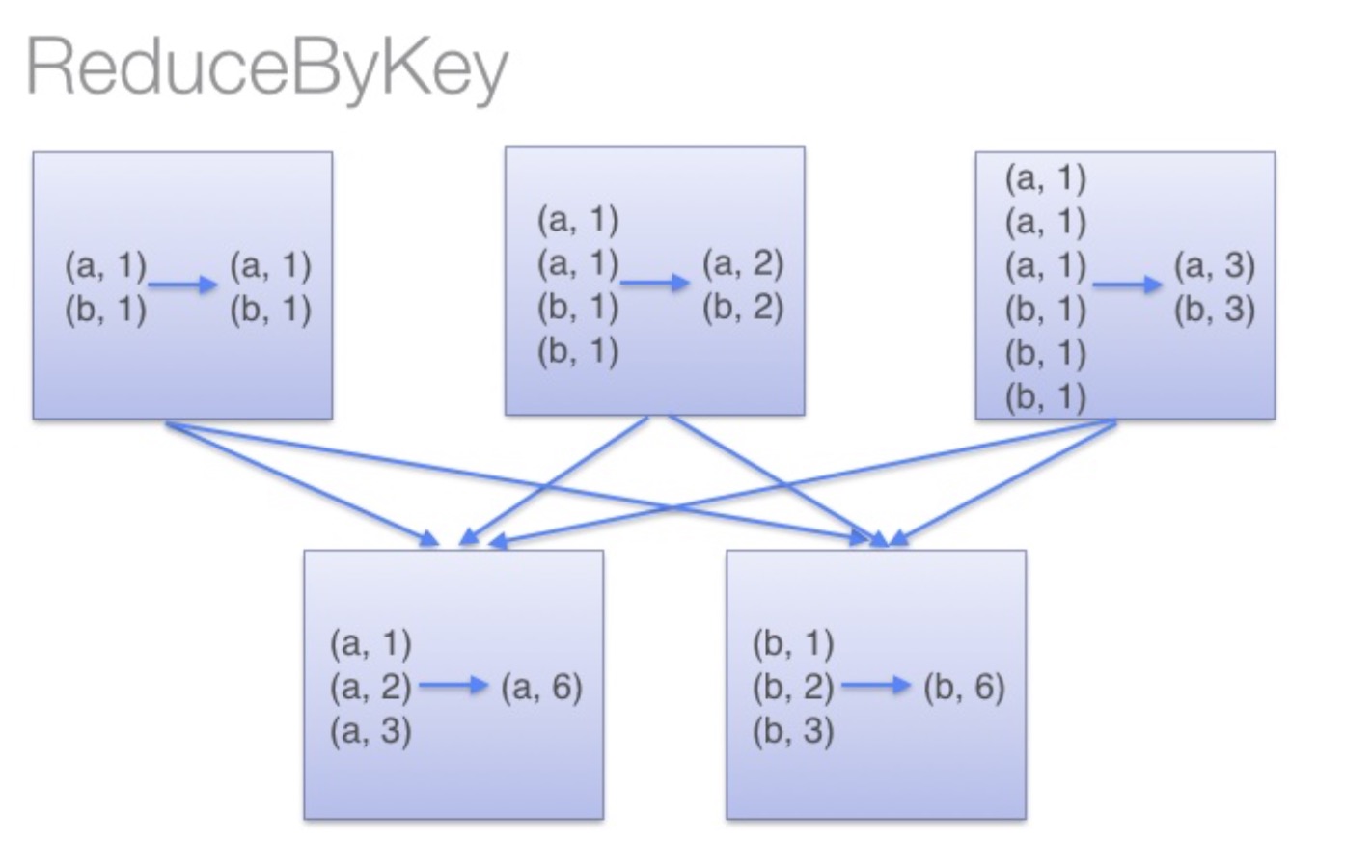
groupByKey:groupByKey会对每一个RDD中的value值进行聚合形成一个序列(Iterator),
此操作发生在reduce端,所以势必会将所有的数据通过网络进行传输,造成不必要的浪费。
同时如果数据量十分大,可能还会造成OutOfMemoryError。
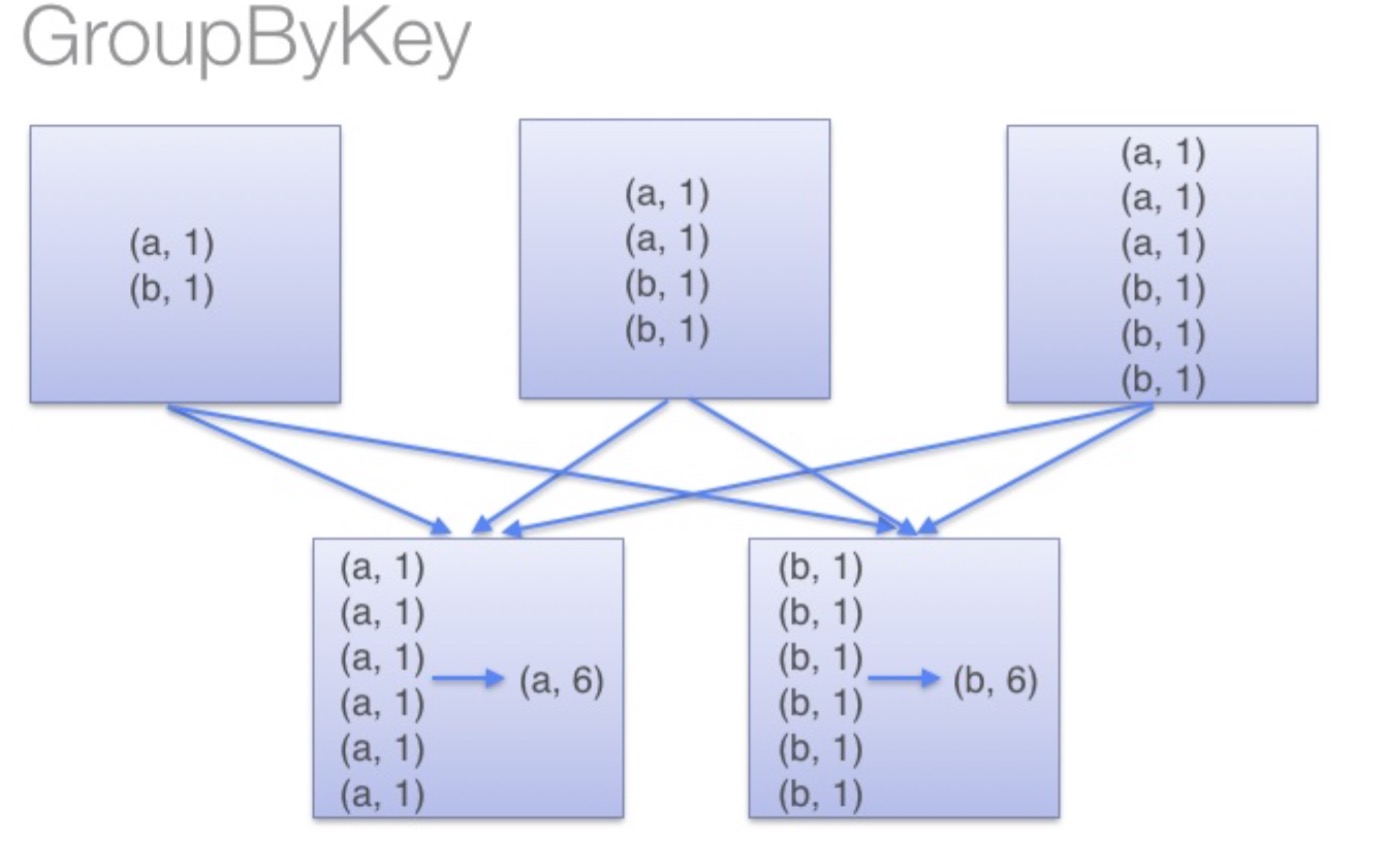
通过以上对比可以发现在进行大量数据的reduce操作时候建议使用reduceByKey。
不仅可以提高速度,还是可以防止使用groupByKey造成的内存溢出问题。




scala flatmap、reduceByKey、groupByKey的更多相关文章
- Spark RDD/Core 编程 API入门系列 之rdd案例(map、filter、flatMap、groupByKey、reduceByKey、join、cogroupy等)(四)
声明: 大数据中,最重要的算子操作是:join !!! 典型的transformation和action val nums = sc.parallelize(1 to 10) //根据集合创建RDD ...
- 32、reduceByKey和groupByKey对比
一.groupByKey 1.图解 val counts = pairs.groupByKey().map(wordCounts => (wordCounts._1, wordCounts._2 ...
- Spark记录-Spark性能优化(开发、资源、数据、shuffle)
开发调优篇 原则一:避免创建重复的RDD 通常来说,我们在开发一个Spark作业时,首先是基于某个数据源(比如Hive表或HDFS文件)创建一个初始的RDD:接着对这个RDD执行某个算子操作,然后得到 ...
- spark提交命令 spark-submit 的参数 executor-memory、executor-cores、num-executors、spark.default.parallelism分析
转载:https://blog.csdn.net/zimiao552147572/article/details/96482120 nohup spark-submit --master yarn - ...
- 转载-reduceByKey和groupByKey的区别
原文链接-https://www.cnblogs.com/0xcafedaddy/p/7625358.html 先来看一下在PairRDDFunctions.scala文件中reduceByKey和g ...
- reduceByKey和groupByKey的区别
先来看一下在PairRDDFunctions.scala文件中reduceByKey和groupByKey的源码 /** * Merge the values for each key using a ...
- Spark中groupByKey、reduceByKey与sortByKey
groupByKey把相同的key的数据分组到一个集合序列当中: [("hello",1), ("world",1), ("hello",1 ...
- 【Spark算子】:reduceByKey、groupByKey和combineByKey
在spark中,reduceByKey.groupByKey和combineByKey这三种算子用的较多,结合使用过程中的体会简单总结: 我的代码实践:https://github.com/wwcom ...
- 深入理解groupByKey、reduceByKey区别——本质就是一个local machine的reduce操作
下面来看看groupByKey和reduceByKey的区别: val conf = new SparkConf().setAppName("GroupAndReduce").se ...
随机推荐
- 渐进式迭代教学法--PHP
渐进式迭代教学法--PHP 目前常见的课程体系大致情况如下: 阶段1:前端基础(html+css+js) 阶段2:PHP&MySQL基础 + 框架 (PHP基本语法,面向对象,mvc,sql基 ...
- Xshell安装后,使用的优化
常见的远程连接软件 windows Xshell.secureCRT.Putty mac ssh命令.iterm2 手机 IOS-termius Android-JuiceSSH Xshell的优化 ...
- [TJOI2017]DNA
嘟嘟嘟 这题怎么想都想不出来,最后还是敲了暴力,喜提40分-- 正解竟然也是暴力-- 用\(s_0\)构造SAM,然后把\(s\)扔上去暴力dfs:记录一个修改次数tot,如果当前不匹配,就tot + ...
- Mybatis基础核心类说明
1: org.apache.ibatis.mapping.ParameterMapping 为Mybatis参数的抽象表示,包括Java类型与数据库类型以及类型处理器属性名字等等!! 例如: 其中i ...
- java和maven环境变量设置,Tomcat部署
Java环境变量设置 Win10我的电脑右击属性,高级系统设置,高级,环境变量设置 新建系统变量JAVA_HOME 和CLASSPATH 变量名:JAVA_HOME 变量值:C:\Program F ...
- 【angularjs】使用angular搭建项目,实现隔行换色
描叙:使用ng-class实现每隔3行换色 代码: <!DOCTYPE html> <html ng-app="myApp"> <head> & ...
- 【window】git安装教程
相关链接:https://blog.csdn.net/nly19900820/article/details/73379854 作者:smile.轉角 QQ:493177502
- linux命令之vmstat
vmstat 参数 功能:报告虚拟内存.swap.io.上下文和 CPU 统计信息. 分析了这些文件: /proc/meminfo /proc/stat /proc/*/stat 常用选项: -a 打 ...
- ogg BR – BOUNDED RECOVERY 测试案例
首先,我们来看两个OGG同步中可能的问题: l oracle在线日志包含已提交的和未提交的事务,但OGG只会将已提交的事务写入到队列文件.因此,针对未提交的事务,特别是未提交的长事务,OGG会怎样处理 ...
- Python 在 Terminal 中的自动补全
为了在 Terminal 中使用 Python 更加方便,在 home 目录下添加脚本 .pythonstartup,内容如下, 然后在 .bashrc 中添加 export PYTHONSTARTU ...