机器学习-Sklearn
Scikit learn 也简称 sklearn, 是机器学习领域当中最知名的 python 模块之一.
Sklearn 包含了很多种机器学习的方式: Classification 分类
Regression 回归
Clustering 非监督分类
Dimensionality reduction 数据降维
Model Selection 模型选择
Preprocessing 数据预处理
我们总能够从这些方法中挑选出一个适合于自己问题的, 然后解决自己的问题.
安装
Scikit-learn (sklearn)
Windows 注意事项
如果你是 Windows 用户, 你也可以选择使用 Anaconda 来安装所有 python 的科学计算模块. Anaconda的相关资料在这
一般使用
1、选择学习方法:看图
Sklearn 官网提供了一个流程图, 蓝色圆圈内是判断条件,绿色方框内是可以选择的算法:
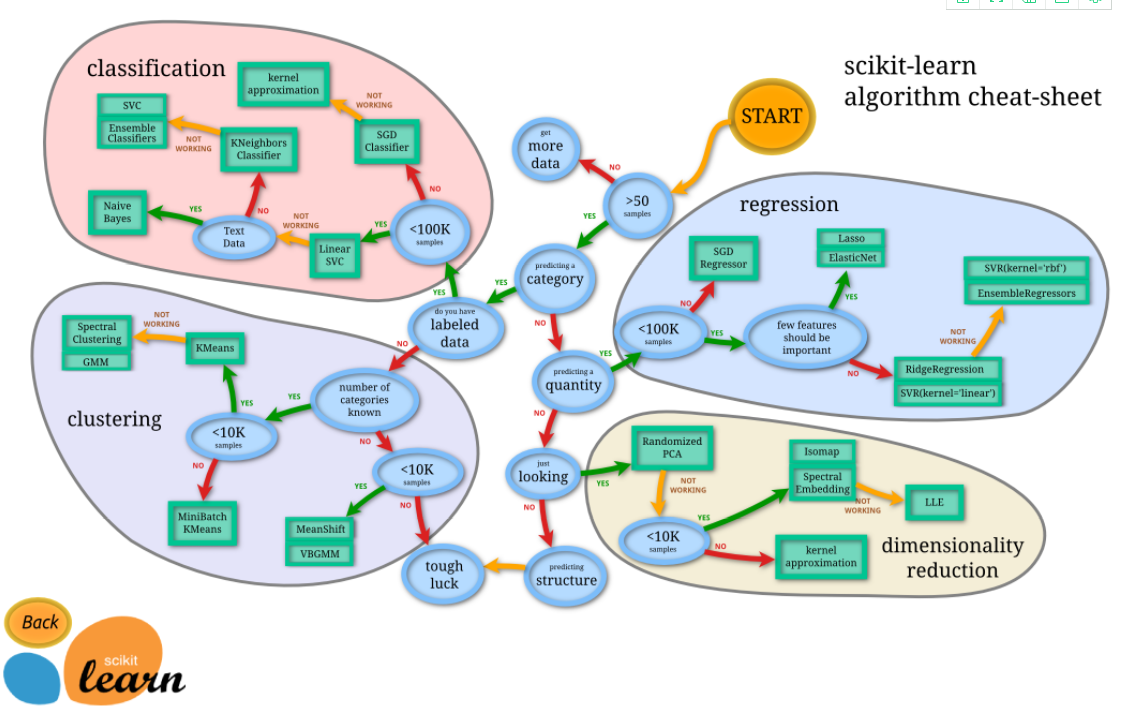
从 START 开始,首先看数据的样本是否 >50,小于则需要收集更多的数据。 由图中,可以看到算法有四类,分类,回归,聚类,降维。 其中 分类和回归是监督式学习,即每个数据对应一个 label。 聚类 是非监督式学习,即没有 label。
另外一类是 降维,当数据集有很多很多属性的时候,可以通过 降维 算法把属性归纳起来。
例如 20 个属性只变成 2 个,注意,这不是挑出 2 个,而是压缩成为 2 个,
它们集合了 20 个属性的所有特征,相当于把重要的信息提取的更好,不重要的信息就不要了。 然后看问题属于哪一类问题,是分类还是回归,还是聚类,就选择相应的算法。 当然还要考虑数据的大小,例如 100K 是一个阈值。 可以发现有些方法是既可以作为分类,也可以作为回归,例如 SGD。
回归:regression 英 /rɪ'greʃ(ə)n/ 美 /rɪ'ɡrɛʃən/
聚类:clustering 英 /'klʌstərɪŋ/ 美 /'klʌstɚ/
维度:dimensionality 英 /dɪ,menʃə'nælətɪ/ 美 /daɪmɛnʃə'næləti/
2、通用学习模式
要点
导入模块
创建数据
建立模型-训练-预测
要点
sklearn包不仅囊括很多机器学习的算法,也自带了许多经典的数据集,鸢尾花数据集就是其中之一。
Sklearn 把所有机器学习的模式整合统一起来了,学会了一个模式就可以通吃其他不同类型的学习模式。 例如,分类器, Sklearn 本身就有很多数据库,可以用来练习。 以 Iris 的数据为例,这种花有四个属性,花瓣的长宽,茎的长宽,根据这些属性把花分为三类。 我们要用 分类器 去把四种类型的花分开。
# 导入模块
import pandas as pd
# sklearn包不仅囊括很多机器学习的算法,也自带了许多经典的数据集,(yuan)鸢尾花数据集就是其中之一。
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
# 创建数据
# 加载 iris 的数据,把属性存在 X,类别标签存在 y
iris = datasets.load_iris()
iris_X = iris.data
iris_y = iris.target
# 观察一下数据集,X 有四个属性,y 有 0,1,2 三类:
print(iris_X[:2, :])
print(iris_y)

# 把数据集分为训练集和测试集,其中 test_size=0.3,即测试集占总数据的 30%:
X_train, X_test, y_train, y_test = train_test_split(
iris_X, iris_y, test_size=0.3)
# 可以看到分开后的数据集,顺序也被打乱,这样更有利于学习模型:
print(y_train)
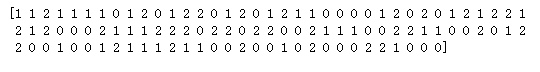
# 建立模型-训练-预测 # 定义模块方式 KNeighborsClassifier(), 用 fit 来训练 training data,这一步就完成了训练的所有步骤, 后面的 knn 就已经是训练好的模型,可以直接用来 predict 测试集的数据, 对比用模型预测的值与真实的值,可以看到大概模拟出了数据,但是有误差,是不会完完全全预测正确的。、
knn = KNeighborsClassifier()
knn.fit(X_train, y_train)
print(knn.predict(X_test))
print(y_test)

3、sklearn 强大数据库
要点
导入模块
导入数据-训练模型
创建虚拟数据-可视化
学习资料:
今天来看 Sklearn 中的 datasets,很多而且有用,可以用来学习算法模型。
eg: boston 房价, 糖尿病, 数字, Iris 花。 也可以生成虚拟的数据,例如用来训练线性回归模型的数据,可以用函数来生成。
from __future__ import print_function
from sklearn import datasets
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt # 导入数据-训练模型
# 用 datasets.load_boston() 的形式加载数据,并给 X 和 y 赋值,这种形式在 Sklearn 中都是高度统一的。
loaded_data = datasets.load_boston()
data_X = loaded_data.data
data_y = loaded_data.target # 定义模型。
model = LinearRegression()# 线性回归
model.fit(data_X, data_y) # 再打印出预测值,这里用 X 的前 4 个来预测,同时打印真实值,作为对比,可以看到是有些误差的。 print(model.predict(d
print(model.predict(data_X[:4, :]))
print(data_y[:4])
# 为了提高准确度,可以通过尝试不同的 model,不同的参数,不同的预处理等方法,入门的话可以直接用默认值。 # 创建虚拟数据-可视化
# 用函数来建立 100 个 sample,有一个 feature,和一个 target,这样比较方便可视化。
# 用 scatter(散点图) 的形式来输出结果。
X, y = datasets.make_regression(n_samples=100, n_features=1, n_targets=1, noise=10)
plt.scatter(X, y)
plt.show()
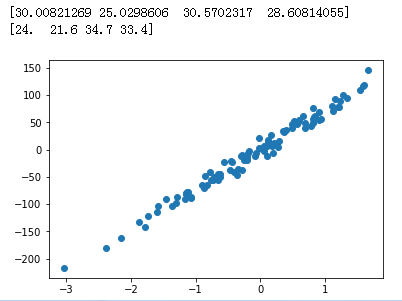
# 可以看到用函数生成的 Linear Regression 用的数据。 # noise 越大的话,点就会越来越离散,例如 noise 由 10 变为 50.
X, y = datasets.make_regression(n_samples=100, n_features=1, n_targets=1, noise=50)
plt.scatter(X, y)
plt.show()noise : float, optional (default=0.0)
The standard deviation of the gaussian noise applied to the output.
高斯噪声对输出的标准差。
4、 sklearn 常用属性与功能
训练和预测
参数和分数
from sklearn import datasets
from sklearn.linear_model import LinearRegression loaded_data = datasets.load_boston()
data_X = loaded_data.data
data_y = loaded_data.target model = LinearRegression()
# 训练和预测
# 接下来 model.fit 和 model.predict 就属于 Model 的功能,用来训练模型,用训练好的模型预测。
model.fit(data_X, data_y) print(model.predict(data_X[:4, :]))
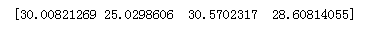
# 参数和分数 # 然后,model.coef_ 和 model.intercept_ 属于 Model 的属性, 例如对于 LinearRegressor 这个模型,
# 这两个属性分别输出模型的斜率和截距(与y轴的交点)。
print(model.coef_)
print('-----------------')
print(model.intercept_)

# model.get_params() 也是功能,它可以取出之前定义的参数。
print(model.get_params())

# model.score(data_X, data_y) 它可以对 Model 用 R^2 的方式进行打分,输出精确度。
# 关于 R^2 coefficient of determination 可以查看 wiki
print(model.score(data_X, data_y)) # R^2 coefficient of determination
0.7406077428649428
高级使用
1、正规化 Normalization
由于资料的偏差与跨度会影响机器学习的成效,因此正规化(标准化)数据可以提升机器学习的成效。
# 正规化 Normalization # 数据标准化 from sklearn import preprocessing #标准化数据模块
import numpy as np #建立Array
a = np.array([[10, 2.7, 3.6],
[-100, 5, -2],
[120, 20, 40]], dtype=np.float64)
print(a)
print('--------------------')
#将normalized后的a打印出
print(preprocessing.scale(a))
[[ 10. 2.7 3.6]
[-100. 5. -2. ]
[ 120. 20. 40. ]]
--------------------
[[ 0. -0.85170713 -0.55138018]
[-1.22474487 -0.55187146 -0.852133 ]
[ 1.22474487 1.40357859 1.40351318]] # 使用sklearn.preprocessing.scale()函数,可以直接将给定数据进行标准化。
# 标准方差(standard deviation)就是方差的平方根,
# 一组数据中的每一个数与这组数据的平均数的差的平方的和再除以数据的个数,取平方根即是。 # 使用sklearn.preprocessing.StandardScaler类,使用该类的好处在于可以保存训练集中的参数(均值、方差)直接使用其对象转换测试集数据。
# 可以使用preprocessing.normalize()函数对指定数据进行转换:
# 可以使用processing.Normalizer()类实现对训练集和测试集的拟合和转换: # 数据标准化对机器学习成效的影响
# 加载模块
--------------------------------------------------------------------------------------------------------------------
# 标准化数据模块
from sklearn import preprocessing
import numpy as np # 将资料分割成train与test的模块
from sklearn.model_selection import train_test_split # 生成适合做classification资料的模块
from sklearn.datasets.samples_generator import make_classification # Support Vector Machine中的Support Vector Classifier
from sklearn.svm import SVC # 可视化数据的模块
import matplotlib.pyplot as plt
# 生成适合做Classification数据 #生成具有2种属性的300笔数据
X, y = make_classification(
n_samples=300, n_features=2,
n_redundant=0, n_informative=2,
random_state=22, n_clusters_per_class=1,
scale=100) #可视化数据
plt.scatter(X[:, 0], X[:, 1], c=y)
plt.show()

# 数据标准化前 # 标准化前的预测准确率只有0.5111111111111111 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
clf = SVC()
clf.fit(X_train, y_train)
print(clf.score(X_test, y_test))
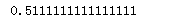
# 数据标准化后 # 数据的单位发生了变化, X 数据也被压缩到差不多大小范围. # 标准化后的预测准确率提升至0.9111111111111111
X = preprocessing.scale(X)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
clf = SVC()
clf.fit(X_train, y_train)
print(clf.score(X_test, y_test))
0.9111111111111111
检验神经网络 (Evaluation)
Training and Test data
误差曲线
准确度曲线
正规化
交叉验证
- Theano: l1 l2 regularization 教程
- Scikit-learn: cross validation 教程1
- Scikit-learn: cross validation 教程2
- Scikit-learn: cross validation 教程3
- Tensorflow: dropout 教程
今天我们会来聊聊在做好了属于自己的神经网络之后, 应该如何来评价自己的神经网络, 从评价当中如何改进我们的神经网络.
其实评价神经网络的方法, 和评价其他机器学习的方法大同小异. 我们首先说说为什么要评价,检验学习到的神经网络.
交叉验证 1 Cross-validation
Model 基础验证法
Model 交叉验证法(Cross Validation)
以准确率(accuracy)判断
以平均方差(Mean squared error)
Sklearn 中的 Cross Validation (交叉验证)对于我们选择正确的 Model 和 Model 的参数是非常有帮助的,
有了他的帮助,我们能直观的看出不同 Model 或者参数对结构准确度的影响。
交叉验证 2 Cross-validation
sklearn.learning_curve 中的 learning curve 可以很直观的看出我们的 model 学习的进度,
对比发现有没有 overfitting 的问题. 然后我们可以对我们的 model 进行调整, 克服 overfitting 的问题.
Learning curve 检视过拟合
机器学习-Sklearn的更多相关文章
- python机器学习-sklearn挖掘乳腺癌细胞(五)
python机器学习-sklearn挖掘乳腺癌细胞( 博主亲自录制) 网易云观看地址 https://study.163.com/course/introduction.htm?courseId=10 ...
- python机器学习-sklearn挖掘乳腺癌细胞(四)
python机器学习-sklearn挖掘乳腺癌细胞( 博主亲自录制) 网易云观看地址 https://study.163.com/course/introduction.htm?courseId=10 ...
- python机器学习-sklearn挖掘乳腺癌细胞(三)
python机器学习-sklearn挖掘乳腺癌细胞( 博主亲自录制) 网易云观看地址 https://study.163.com/course/introduction.htm?courseId=10 ...
- python机器学习-sklearn挖掘乳腺癌细胞(二)
python机器学习-sklearn挖掘乳腺癌细胞( 博主亲自录制) 网易云观看地址 https://study.163.com/course/introduction.htm?courseId=10 ...
- python机器学习-sklearn挖掘乳腺癌细胞(一)
python机器学习-sklearn挖掘乳腺癌细胞( 博主亲自录制) 网易云观看地址 https://study.163.com/course/introduction.htm?courseId=10 ...
- 机器学习sklearn的快速使用--周振洋
ML神器:sklearn的快速使用 传统的机器学习任务从开始到建模的一般流程是:获取数据 -> 数据预处理 -> 训练建模 -> 模型评估 -> 预测,分类.本文我们将依据传统 ...
- 机器学习——sklearn中的API
import matplotlib.pyplot as pltfrom sklearn.svm import SVCfrom sklearn.model_selection import Strati ...
- 机器学习sklearn
sklearn相关模块导入 from sklearn.feature_extraction import DictVectorizer from sklearn.feature_extraction. ...
- python机器学习sklearn 岭回归(Ridge、RidgeCV)
1.介绍 Ridge 回归通过对系数的大小施加惩罚来解决 普通最小二乘法 的一些问题. 岭系数最小化的是带罚项的残差平方和, 其中,α≥0α≥0 是控制系数收缩量的复杂性参数: αα 的值越大,收缩量 ...
随机推荐
- hnsdfz -- 6.21 -- day7
yjq ! yjq ! 今天yjq,感觉yjq好赞啊,路转粉 恩因为题很好所以大致讲一下题解吧 a题是几天前吕老板讲过的…… 一列点上每个点有两个权值ai和bi,每个点可以任选其中一个,但是要求任意一 ...
- What You Can Learn from Actifio Logs
The Actifio services generate many logs, some of which are useful for troubleshooting. This section ...
- 虚拟机安装精简版centos7过程
虚拟机配置工作如下所示 1.创建虚拟机 使用键盘组合键CTRL+N2.选择自定义(高级) 如图所示: 3.默认如何所示: 4.选择 稍后安装操作系统 如图所示: 5.选择对应的操作系统 如何所示 6 ...
- 类似py2exe软件真的能保护python源码吗
类似py2exe软件真的能保护python源码吗 背景 最近写了个工具用于对项目中C/C++文件的字符串常量进行自动化加密处理,用python写的,工具效果不错,所以打算在公司内部推广.为了防止代码泄 ...
- IntelliJ IDEA自动导入包去除星号(import xxx.*)
打开设置>Editor>Code Style>Java>Scheme Default>Imports ① 将Class count to use import with ...
- 分布式事务(二)Java事务API(JTA)规范
一.引子 既然出现了分布式场景(DTP模型), 大java也及时制定出一套规范来给各大应用服务器.数据库/mq等厂商使用,以方便管理互通--->JTA闪亮登场.JTA(Java Transact ...
- 剑指offer 12.代码的完整性 数值的整数次方
题目描述 给定一个double类型的浮点数base和int类型的整数exponent.求base的exponent次方. 本人渣渣代码: public double Power(double ba ...
- vn.trader的Ubuntu运行环境搭建教程
作者:量衍投资 转载请注明来源:维恩的派(www.vnpie.com) 准备Ubuntu 建议使用一个新安装干净的Ubuntu环境(如果你一定要使用老环境也行,万一不幸掉坑后再回到这步就好),我这里使 ...
- ubuntu ssh
客户端 Client端生成公钥和密钥 在Ubuntu服务器上安装ssh 安装方法: apt-get install ssh 安装完成后验证是否SSH安装成功 验证方法: 在命令行模式下执行命令:ssh ...
- Thread.Abort 方法
[SecurityPermissionAttribute(SecurityAction.Demand, ControlThread = true)] public void Abort() 在调用此方 ...