spark原理
SparkContext将应用程序代码分发到各Executors,最后将任务(Task)分配给executors执行
- Application: Appliction都是指用户编写的Spark应用程序,其中包括一个Driver功能的代码和分布在集群中多个节点上运行的Executor代码
- Driver: Spark中的Driver即运行上述Application的main函数并创建SparkContext,创建SparkContext的目的是为了准备Spark应用程序的运行环境,在Spark中有SparkContext负责与ClusterManager通信,进行资源申请、任务的分配和监控等,当Executor部分运行完毕后,Driver同时负责将SparkContext关闭,通常用SparkContext代表Driver
Driver重点:创建和关闭sparkcontext.
- Executor: 某个Application运行在worker节点上的一个进程, 该进程负责运行某些Task, 并且负责将数据存到内存或磁盘上,每个Application都有各自独立的一批Executor, 在Spark on Yarn模式下,其进程名称为CoarseGrainedExecutor Backend。一个CoarseGrainedExecutor Backend有且仅有一个Executor对象, 负责将Task包装成taskRunner,并从线程池中抽取一个空闲线程运行Task, 这个每一个oarseGrainedExecutor Backend能并行运行Task的数量取决与分配给它的cpu个数
excutor重点:某个Application运行在worker节点上的一个进程,该进程负责运行某些Task,运行Task的数量取决与分配给它的cpu个数。
Work为子节点。
Job:根据Job构建基于Stage的DAG
Stage:多个taskset(task集合)
Task:执行的任务的最小单位。
Spark Cluster模式:
- 在YARN-Cluster模式中,当用户向YARN中提交一个应用程序后,YARN将分两个阶段运行该应用程序:
- 第一个阶段是把Spark的Driver(创建sparkcontext,构建环境)作为一个ApplicationMaster在YARN集群中先启动;
- 第二个阶段是由ApplicationMaster创建应用程序,然后为它向ResourceManager申请资源,并启动Executor来运行Task,同时监控它的整个运行过程,直到运行完成
- YARN-cluster的工作流程分为以下几个步骤
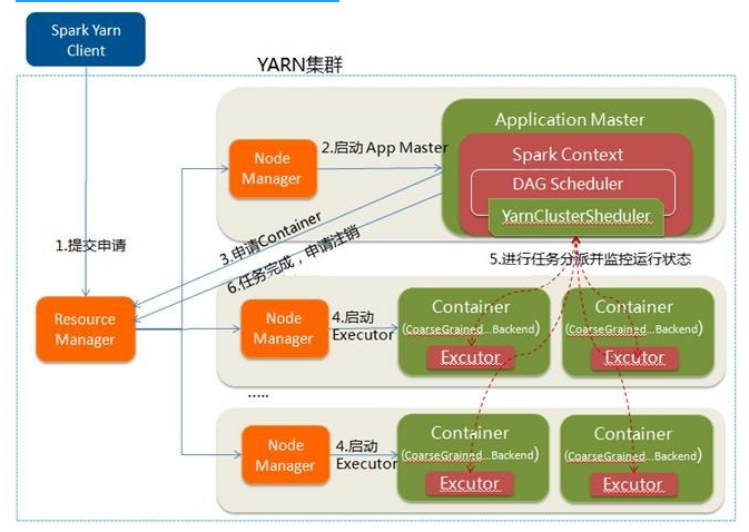
待续
spark原理的更多相关文章
- Spark原理分析目录
1 Spark原理分析 -- RDD的Partitioner原理分析 2 Spark原理分析 -- RDD的shuffle简介 3 Spark原理分析 -- RDD的shuffle框架的实现概要分析 ...
- Spark原理小总结
1.spark是什么? 快速,通用,可扩展的分布式计算引擎 2.弹性分布式数据集RDD RDD(Resilient Distributed Dataset)叫做分布式数据集,是Spark中最基本的数据 ...
- Update(Stage4):Spark原理_运行过程_高级特性
如何判断宽窄依赖: =================================== 6. Spark 底层逻辑 导读 从部署图了解 Spark 部署了什么, 有什么组件运行在集群中 通过对 W ...
- spark原理介绍
1.spark是一个基于内存计算的开源的集群计算系统,目的是让数据分析更加快速.因此运行spark的机器应该尽量的大内存,如96G以上. 2.spark所有操作均基于RDD,操作主要分成2大类:tra ...
- spark原理介绍 分类: B8_SPARK 2015-04-28 12:33 1039人阅读 评论(0) 收藏
1.spark是一个基于内存计算的开源的集群计算系统,目的是让数据分析更加快速.因此运行spark的机器应该尽量的大内存,如96G以上. 2.spark所有操作均基于RDD,操作主要分成2大类:tra ...
- Spark原理概述
原文来自我的个人网站:http://www.itrensheng.com/archives/Spark_basic_knowledge 一. Spark出现的背景 在Spark出现之前,大数据计算引擎 ...
- 《Spark大数据处理》---Spark原理
- 大数据组件原理总结-Hadoop、Hbase、Kafka、Zookeeper、Spark
Hadoop原理 分为HDFS与Yarn两个部分.HDFS有Namenode和Datanode两个部分.每个节点占用一个电脑.Datanode定时向Namenode发送心跳包,心跳包中包含Datano ...
- Spark基本架构及原理
Hadoop 和 Spark 的关系 Spark 运算比 Hadoop 的 MapReduce 框架快的原因是因为 Hadoop 在一次 MapReduce 运算之后,会将数据的运算结果从内存写入到磁 ...
随机推荐
- 关于maven项目的servlet-api的问题
因为maven带servlet-api的,但是不导入jsp又报错,所以导入servlet-jar的时候配置scope -------------provided 发布到服务器的时候,自动去除
- js:一些基础
JavaScript 基础(一) JavaScript的引入方式 直接编写 <!DOCTYPE html> <html lang="en"> <h ...
- linux下redis的安装方法
一.Linux环境下安装Redis Redis的官方下载网址是:http://redis.io/download (这里下载的是Linux版的Redis源码包) Redis服务器端的默认端口是6 ...
- tabpanel如何隐藏页签表头以及基本用法总结
tabpanel是extjs中一种比较常用的布局容器控件,也比较简单. ///1:相关的插件, var tabScrollerMenu = Ext.create("Ext.ux.TabScr ...
- 同机器与不同机器redis集群
此文为另外一位大神原创由于没有找到分享功能 粘贴复制到此 原地址为https://blog.csdn.net/u012042021/article/details/72818759 一.同机器下的 ...
- IDEA连接数据库自动生成实体类
1.连接数据库 (1)按下图 , 点击view-----选择tool windows----------选择database并点击 (2)弹出Database窗口,点击加号--------- ...
- Go语言编程读书笔记:Go channel(2)
单向channel 概念 单向channel是只能用于发送或者接收数据,channel本身必然是同时支持读写,否则根本没法用.假如一个channel只能读,那么肯定只会是空的,因为你没有机会向里面写数 ...
- Selenium+TestNG+Maven(2)
转载自http://www.cnblogs.com/hustar0102/p/5885115.html selenium介绍和环境搭建 一.简单介绍 1.selenium:Selenium是一个用于W ...
- Joe Hocking - Unity in Action. 2nd Ed [2018]
Unity in Action. 2nd Ed, 一本关于unity开发的英文书籍,初中级 PDF格式 扫码时备注或说明中留下邮箱 付款后如未回复请至https://shop135452397.tao ...
- 《AlwaysRun!》第一次作业:团队亮相
项目 内容 这个作业属于哪个课程 2016级软件工程(西北师范大学) 这个作业的要求在哪里 实验五 团队作业1:软件研发团队组建 团队名称 Always Run! 作业学习目标 熟悉软件的开发流程与 ...