《Macro-Micro Adversarial Network for Human Parsing》论文阅读笔记
《Macro-Micro Adversarial Network for Human Parsing》
摘要:在人体语义分割中,像素级别的分类损失在其低级局部不一致性和高级语义不一致性方面存在缺陷。对抗性网络的引入使用单个鉴别器来解决这两个问题。然而,两种类型的解析不一致是由不同的机制产生的,因此单个鉴别器很难解决它们。为解决这两种不一致问题,本文提出了宏观 - 微观对抗网络(MMAN)。它有两个鉴别器,一个鉴别器Macro D作用于低分辨率标签图并且惩罚语义不一致性,例如错位的身体部位。另一个鉴别器Micro D专注于高分辨率标签映射的多个像素块,以解决局部不一致性,例如图片模糊和裂口。与传统的对抗性网络相比,MMAN不仅明确地强制实现了局部和语义一致性,而且避免了处理高分辨率图像时对抗性网络的收敛性差的问题。在我们的实验中,我们验证了两个鉴别器在提高人类解析准确性方面是相互补充的。与现有技术方法相比,所提出的框架能够产生有竞争力的解析性能,即分别在LIP和PASCAL-Person-Part上的mIoU = 46.81%和59.91%。在相对较小的数据集PPSS上,我们的预训练模型展示了令人印象深刻的泛化能力。该代码可在https://github.com/RoyalVane/MMAN上公开获取。
关键词:人体解析,对抗网络,不连续性,宏观-微观
1 介绍
人体解析旨在将人类图像分割成多个语义部分。 它是像素级预测任务,需要在全局级别和本地级别理解人类图像。 人类解析可以广泛应用于人类行为分析[9],姿势估计[34]和潮流综合[40]。人类解析和语义分割的最新进展[19,34,10,23,37,36]主要探讨卷积神经网络(CNN)的潜力。
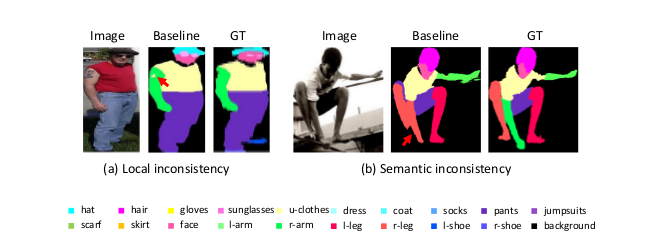
图1:像素化分类损失的缺点。 (a)局部不一致,导致手臂上有孔。 (b)语义不一致,导致不合理的人体姿势。 红色箭头表示不一致。
基于CNN架构,通常使用像素级分类损失[19,34,10],其惩罚每个像素的分类误差。尽管提供了有效的基线,但是针对每像素类别预测设计的像素级分类损失具有两个缺点。首先,逐像素分类损失可能导致局部不一致,例如图片的裂口和模糊。原因在于它仅在不明确考虑相邻像素之间的相关性的情况下惩罚每个像素上的错误预测。为了说明,我们使用逐像素分类损失训练基线(当前现状,参照物?)模型(参见第3.2节)。如图1(a)所示,属于“手臂”的一些像素被基线错误地预测为“上衣”。这是不合需要的,但这是基线损失局部不一致的结果。其次,逐像素分类丢失可能导致整个分割图中的语义不一致,例如不合理的人体姿势和身体部位的不正确的空间关系。与局部不一致相比,语义不一致是从更深层生成的。仅查看局部区域时,所学习的模型不具有身体部位拓扑的整体意识。如图1(b)所示,“手臂”与相邻的“腿”合并,表示不正确的部分拓扑(三条腿)。因此,逐像素分类丢失没有明确地考虑语义一致性,因此可能无法很好地捕获长远的依赖性。
为了解决不一致性问题,可采用条件随机场(CRF)[17]用作后处理方法。 然而,由于pairwise potentials(成对势,结对能力?)的存在,CRF通常在非常有限的范围内(局部地)处理不一致性,并且由于初始分割结果差,甚至可能产生更差的标记图。 作为CRF的替代方案,最近的一项工作提出使用对抗性网络[24]。 由于对抗性损失通过联合配置许多标签变量来评估标签图是真的还是假的,因此它可以强制执行更高级别的一致性,但这不能通过成对术语或每像素分类丢失来实现。
现在,越来越多的论文采用了交叉熵损失与对抗性损失结合起来的方法,以产生更接近真实值的标签图[5,27,12]。
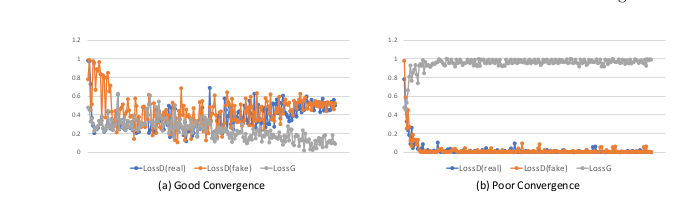
图2:对抗性网络训练中的两种收敛方式。 LossD(真)和LossD(假)分别表示真实和假图像上的鉴别器的对抗性损失,而LossG表示发生器的损失。(a)良好的收敛,其中LossD(真)和LossD(假)收敛到0.5并且 LossG收敛到0。它表示成功的对抗性网络训练,其中G能够欺骗D。(b)收敛性差,其中LossD(真实)和LossD(假)收敛到0同时LossG收敛到1。它代表一个不平衡的对抗性网络训练,其中D可以容易地将生成的图像与真实图像区分开。
然而,之前的对抗性网络也有其局限性。 首先,单个鉴别器反向仅向生成器传播一个对抗性损失。但是局部不一致性是从顶层产生的,语义不一致性是从深层产生的。只有一个对抗性损失,不能对两个目标层进行离散训练。 其次,单个鉴别器必须查看整体高分辨率图像(或其大部分)以监督全局一致性。 正如文献[7,14]所提到的,生成器很难在高分辨率图像上欺骗判别器。其结果是,单一的鉴别器总是反向传播一个最大的对抗损失,这使得训练不平衡。我们称之为收敛性差的问题,如图2所示。
在本文中,基本目标是在人体解析中提高标签贴图的局部和语义一致性。我们采用对抗性训练的思想,旨在解决其局限性,即在单一对抗性损失和不良收敛问题下提高解析一致性的能力较差的问题。具体来说,我们介绍了Macro-Micro Adversarial Nets(MMAN,宏-微观对抗网络)。 MMAN由双输出发生器(G)和两个鉴别器(D)组成,分别命名为Macro D和Micro D。这三个模块分别构成两个对抗网络(Macro AN,Micro AN),分别解决了语义一致性和局部一致性问题。给定输入人体图像,基于CNN的产生器输出具有不同分辨率等级的两个分割图,即低分辨率和高分辨率图。Macro D的输入是低分辨率分割图,输出是语义一致性的置信度得分。Micro D的输入是高分辨率分割结果,其输出是局部一致性的置信度得分。框架的简要流程如图3所示。MMAN与之前的方法主要有两个不同。首先,本文的方法明确地使用两个特定于任务的对抗网络来处理局部不一致和语义不一致问题。其次,我们的方法在高分辨率图像上不使用大尺寸FOVs,因此可以避免不良收敛问题。第3.5节提供了对所提出网络优点的更详细描述。
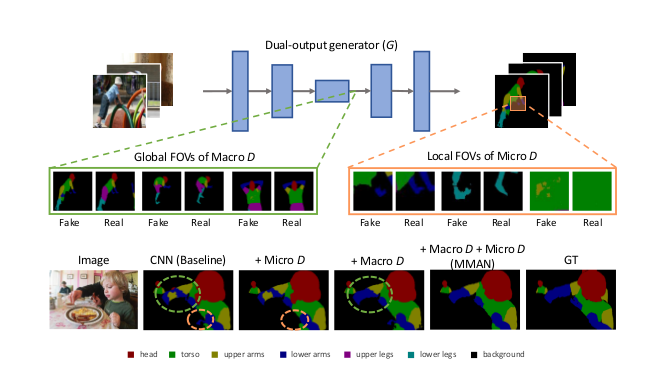
图3:顶部:MMAN的简要流水线。 两个判别器连接到基于CNN的发生器(G)。 Macro D适用于低分辨率标签贴图,并具有全局感知字段,侧重于语义一致性。 Micro D专注于多个补丁,在高分辨率标签图上具有较小的感受域,从而监控局部一致性。 如果观察到语义(局部)不一致,宏(微)判别器为“假”,否则它给出“真实”。底部:分别使用Macro D,Micro D和MMAN的定性结果。我们观察到Macro D和Micro D分别纠正语义不一致(绿色虚线圆圈)和局部不一致(橙色虚线圆圈),MMAN同时具有两者的优点。
我们的贡献总结如下:
- 我们提出了一种名为Macro-Micro Adversarial Network(MMAN)的新框架,用于人体解析。 Macro AN和Micro AN分别关注语义和局部不一致,并以互补的方式工作以提高解析质量。
- 我们框架中的两个鉴别器在具有小视场(FOVs)的标签图上实现了局部和全局监督,这避免了由高分辨率图像引起的不良收敛问题。
- 本文提出的对抗网络在LIP和PASCAL-Person-Part数据集上实现了极具竞争力的mIoU,并且可以在相对较小的数据集PPSS上得到很好的推广。
2 相关研究
我们的评审侧重于与工作相关的三个文献,即基于CNN的人体解析、条件随机场(CRFs)和对抗性网络。
人体解析。 人体解析的最新进展归因于两个因素:1)大规模数据集的可用性[10,19,25,4]。与小数据集相比,大规模数据集包含人们的共同视觉差异并提供全面的评估。 2)端到端的学习模型。人体解析需要在像素级别上理解人。 最近的研究应用卷积神经网络(CNN)以端到端的方式学习分割结果。 在[34]中,人体姿势被提前提取并用作强结构线索来指导解析。 在[21]中,四个与人类相关的背景被整合到一个统一的网络中。 [29]提出了一种新的与人相关的语法,它结合了人体姿势和人体部分分割来推测。
条件随机场。使用像素分类损失,CNN通常忽略像素之间的微观上下文和语义部分之间的宏观上下文。 条件随机字段(CRFs)[17,22,18]是在输出标签映射中强制实现空间连续性的常用方法之一。 作为图像分割的后处理程序,CRFs进一步微调输出图。 然而,最常用的CRFs具有成对电位[2,26],其具有非常有限的参数,并且可以在小范围内处理低水平的不一致性。 高阶势[16,18]也被认为在执行语义有效性方面是有效的,但相应的能量模式和集团形式通常很难设计。 总之,在CNN中使用上下文仍然是一个悬而未决的问题。
对抗性网络。 对抗网络已经证明了图像合成的有效性[13,28,30,39,38]。 通过最小化对抗性损失,鉴别器引导发生器产生高保真度图像。 在[24]中,Luc等人为训练语义分割添加对抗性损失并得到竞争性结果。 类似的想法已经应用于街景分割[12]和医学图像分割[5,27]。 目前,越来越多的文献[7,14]报道了在高分辨率图像上训练对抗性网络的难度。 鉴别器可以轻松识别假的高分辨率图像,从而导致训练失衡。 发生器和鉴别器容易陷入局部最小值。
MMAN与上述对抗性学习方法的主要区别在于我们明确地赋予对等训练宏观和微观子任务。 我们观察到两个子任务相互补充,以便在单个对抗性损失的情况下实现优于基线的解析精度,并且能够降低训练失衡的风险。
3 Macro-Micro Adversarial Network
图4说明了所提出的宏 - 微对抗网络的体系结构。 该网络由三个部分组成,即双输出发生器(G)和两个任务专用鉴别器(D M a和D M i)。 给定尺寸为3×256×256的输入图像,G分别输出尺寸为C×16×16和C×256×256的两个标签图。 D M a监视C×16×16的整个标签图,并且D M i分别关注尺寸为C×256×256的标签图的块,使得全局和局部不一致性受到惩罚。 在3.1节中,说明训练目标,然后在3.2,3.3和3.4节中说明结构。 第3.5节讨论了所提出的网络的优点。
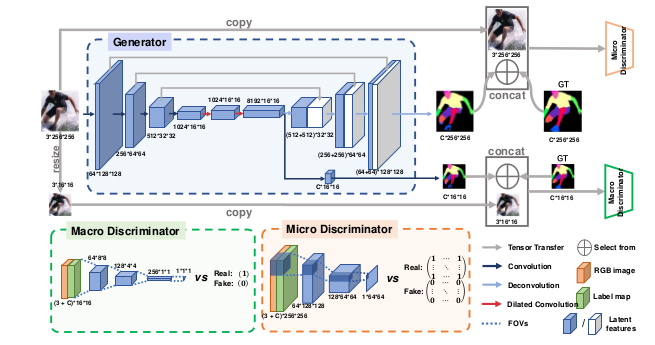
图4:MMAN有三个部分:双输出发生器(蓝色虚线框),宏观鉴别器(绿色虚线框)和微观鉴别器(橙色虚线框)。给定尺寸为3×256×256的输入图像,生成器G首先产生低分辨率(8192×16×16)张量,从中得到低分辨率标签图(C×16×16)和高分辨率生成标签图(C×256×256),其中C是类的数量。 最后,对于每个标签贴图(例如,尺寸为C×16×16),我们将其与第一轴(通道数)的RGB图像(尺寸为3×16×16)相连,并将其输入相应的鉴别器。
3.1 培训目标
给定形状为3×H×W的人像x和形状为C×H×W的目标标签图y,其中C为包括背景的类的数量,传统的像素分类损失(多类交叉熵) 损失)可以表述为:
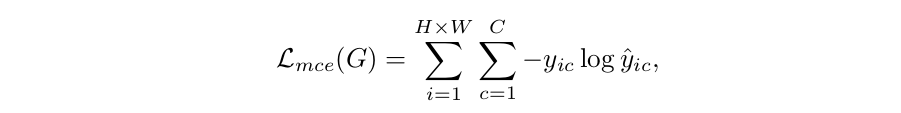 (1)
(1)
其中ŷic表示第i个像素上的类c的预测概率。 yic表示第i个像素上的类c的地面实况概率。 如果第i个像素属于c类,yic = 1,则yic = 0。为了强制执行空间一致性,我们将逐像素分类损失与对抗性损失相结合。 它可以表述为:
 (2)
(2)
其中λ控制像素分类损失和对抗性损失的相对重要性。 具体来说,对抗性损失Ladver(G,D)为:
 (3)
(3)
如图4所示,所提出的MMAN采用“交叉熵损失+对抗性损失”来监督来自发生器G的底部和顶部输出:
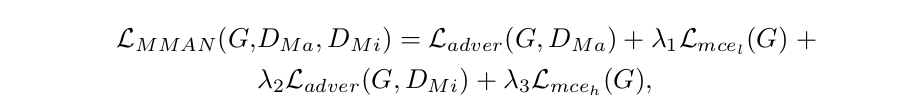 (4)
(4)
其中Lmcel(G)给出了低分辨率输出和小尺寸目标标签图之间的交叉熵损失,而Lmceh(G)是指高分辨率输出和原始真值之间的交叉熵损失label map。 类似地,L adver(G,DMa)是关注低分辨率map的对抗性损失,Ladver(G,DMi)基于高分辨率地图。超参数λ1,λ2和λ3控制四个损失的相对重要性。 MMAN的训练任务是:
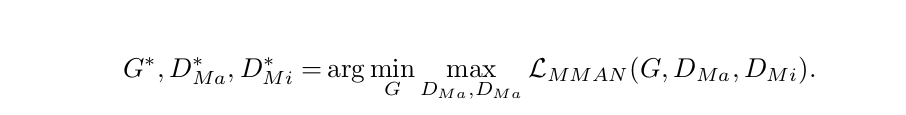 (5)
(5)
我们通过优化G,DMa和DMi之间的交替来求解方程式5,直到LMMAN(G,DMa,DMi)收敛。
3.2 双输出生成器
对于生成器(G),由于它的简单性和有效性,我们利用DeepNet-ASPP [2]框架和ResNet-101 [11]模型在ImageNet数据集[6]上预先训练作为我们的起点。我们使用级联的上采样层来扩充DeepLab-ASPP架构,并跳过与早期层的连接,这与U-net类似[31]。此外,我们添加一个旁路从底层输出深度特征张量,并将其转移到带卷积层的label map。小尺寸标签图切换为与顶部原始尺寸标签图平行的第二个输出层。将增强的双输出架构称为Do-DeepLab-ASPP并将其作为baseline。对于双输出,使用原始大小的真值label map监控顶层的交叉熵损失,因为它可以保留视觉细节。此外,使用调整大小的label map监控底层的交叉熵损失,即原始大小的1/16倍。缩小的label map更加关注粗粒度的人体结构。同样的策略适用于对抗性损失。在类通道上,我们将相应的label map(标签映射,标签图,标签变换?)与对应大小的RGB图像连接起来,作为判别器的强条件。
3.3 宏观判别器
宏观判别器(DMa)旨在引导发生器产生逼真的标签图,其具有高级人体特征,例如合理的人体姿势和身体部位的正确空间关系。 DMa附着在G的底层,并聚焦在整体低分辨率标签图上。 它由4个卷积层组成,内核大小为4×4,步长为2。每个卷积层后跟一个实例范数层和一个LeakyRelu函数。 给定来自G的输出标签图,DM将其下采样到1×1以实现对其的全局监督,DMa的输出是语义一致性的置信度得分。
3.4 微型判别器
微观判别器(DMi)旨在强制标签图中的局部一致性。 在设计DMi时遵循“PatchGAN”[13]的思想。 与在(缩小的)标签图上具有全局感受野的DMa不同,DMi仅在图像块的尺度上惩罚局部误差。DMi的内核大小为4×4,步幅为2。Micro D具有3个卷积层的浅层结构,每个卷积层后跟一个实例范数层和一个LeakyRelu函数。DMi的目的是对高分辨率图像中的每个22×22块是否真实或虚假进行分类,这适合于增强局部一致性。在标签图上以卷积方式运行DMi后,将从每个感受野中获得多个响应。 最终平均所有响应以提供DMi的最终输出。
3.5 讨论
在基于CNN的人体解析中,卷积层深入提取部分级特征,解卷积层将深度特征带回像素级位置。将宏D安排到更深层以监督高级别似乎是直观的。 语义特征和Micro D到顶层,侧重于低级视觉特征。 然而,除了直观的动机,我们可以从这种安排中获益更多。 MMAN的优点总结为以下四个方面。
Macro D和Micro D的功能专业化。与单独鉴别器试图解决两个不一致性水平相比,Macro D和Micro D在解决两个一致性问题中的一个时被指定。 以Macro D为例。 首先,Macro D附加到G的深层。因为语义不一致最初是从深层生成的,所以这样设计的Macro D允许损失更直接地反向传播到G。其次,Macro D作用于低分辨率标签图,该图保留了语义级人体结构,同时滤除了像素级细节。它使得Macro D专注于全局不一致而不会受到本地错误的干扰。相同的推理适用于Micro D。在4.5节中,我们验证MMAN始终优于具有单一对抗性损失的对抗性网络[24,5]。
Macro D和Micro D的功能互补。如[35]中所述,监督早期深层中的分类损失可以为后面的顶层提供良好的粗粒度初始化。相应地,减少顶层的损失可以通过细粒度的视觉细节来弥补粗略的语义特征。假设对抗性损失具有与互补模式相同的特征,在4.4节中证实了我们的假设。
小视场避免了收敛性差的问题。越来越多的文献[7,14]报道,现有的对抗网络在处理复杂的高分辨率图像方面存在缺陷。在我们的框架中,Macro D作用于低分辨率标签图,而Micro D在高分辨率标签地图上具有多个但小的FOV。因此,Macro D和微D都避免了使用大的FOV作为实际输入,从而有效地降低了高分辨率引起的收敛风险。我们在第4.5节中展示了这个优点。
效率。与单一的对抗网络[24,5]相比,MMAN通过两个参数较少的浅层判别器实现了对整个图像的监控。它还拥有判别器的小视场。MMAN的效率在第4.5节的变体研究中显示出来。
4 实验
4.1 数据集
LIP [10]是最近才引入的大规模数据集,在严重的姿势复杂性,严重的闭塞和身体截断方面具有挑战性。 它共包含50,462张图像,包括30,362张用于培训,10,000张用于测试,10,000张用于验证。LIP定义了19个人体(衣服)标签,包括帽子,头发,太阳镜,上衣,连衣裙,外套,袜子,裤子,手套 ,围巾,裙子,连身衣,面部,右臂,左臂,右腿,左腿,右鞋和左鞋,以及背景这些类别。
PASCAL-Person-Part [4]注释了人体部分的分割标签,是PASCAL-VOC 2010的一个子集[8]。 PASCAL-Person-Part包括1,716张用于训练的图像和1,817张用于测试的图像。 在该数据集中,图像可以包含具有不受约束的姿势和环境的多个人。 六个人体部分类别和背景类别被注释。
PPSS [25]包括3,673个带注释的样本,它们被分成1,781个图像的训练集和1,892个图像的测试集。 它定义了七个人体部分和一个背景类别。 从171个监控视频中收集的数据集可以反映真实场景中的遮挡和光照变化。
评价指标。根据像素交叉结合(IoU)来测量每个类的人体解析准确度。 通过对所有类别的IoU求平均来计算平均交叉联合(mIoU)。 我们将每个类的IoU和mIoU用作每个数据集的评价指标。
4.2 实现细节
在我们的实现中,输入图像被调整大小以使其较短边固定为288。从图像或其水平翻转版本中随机采样256×256裁剪。从裁剪图像中减去每像素平均值。在每次卷积后采用实例归一化[32],对于方程4中的超参数,我们设置λ1= 25,λ2= 1和λ3= 100.对于发生器的下采样网络,我们使用ImageNet[6]预训练网络作为初始化。使用标准偏差为0.001的高斯分布从头开始初始化网络其余部分的权重。我们使用小优化器[15],迷你批次为1。我们设置β1= 0.9,β2= 0.999和weightdecay = 0.0001。学习率从0.0002开始。在LIP数据集上,学习率在15个时期之后除以10,并且模型被训练30个时期。在Pascal-Person-Part数据集上,学习率在25个时期之后除以10,并且模型被训练50个时期。根据[13]中的实践,我们在反卷积层中使用了丢失。我们交替地优化D和G.在测试期间,我们对多个尺度的每像素分类平均值进行平均,即,将测试图像的大小调整为其原始大小的{0.8,1,1.2}倍。
4.3 与最先进的方法比较
在本节中,我们将结果与三个数据集上的最新方法进行比较。首先,在LIP数据集上,我们将MMAN与表1中的五种最先进的方法进行比较。提出的MMAN产生的mIoU为46.65%,而五种竞争方法的mIoU分别为18.17%[1],28.29 %[23],42.92%[3],44.13%[2]和44.73%[10]。为了公平比较,我们在基线上进一步实施ASN [24]和SSL [10],即Do-Deeplab-ASPP。在同一基线上,MMAN优于ASN [24]和SSL [10] + 1.40%并且mIoU分别为+ 0.62%。它清楚地表明我们的方法优于现有技术。每级IoU的比较表明,改善主要来自与人体姿势密切相关的类别,例如手臂,腿和鞋。特别是,MMAN能够区分“左”和“右”,这对以下人体部位有很大的推动作用:左/右臂改善+ 2.5%以上,左/右腿改善+ 10%以上左/右鞋的改进超过+ 5%。这些比较意味着MMAN能够强制转换语义级特征的一致性,即人体姿势。
表1:LIP验证集上每类IoU和mIoU的方法比较。

表2:在PASCAL-Person-Part测试集上使用五种最先进的方法进行每级IoU的性能比较。
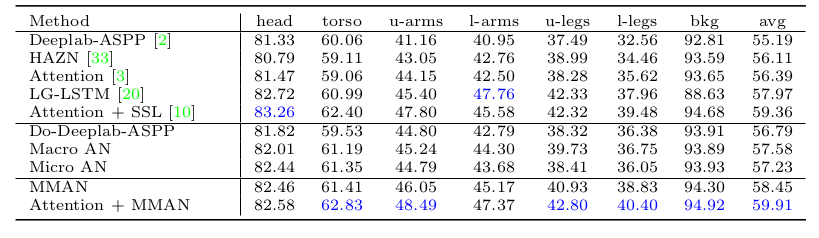
其次,在PASCAL-Person-Part上,如表2所示的比较结果。我们应用LIP数据集上使用的相同模型结构来训练PASCAL-Person-Part数据集。 我们的模型在测试集上产生58.45%的mIoU。 它高于大多数比较方法,仅略低于“注意+ SSL”[10] 0.91%。 这可能是由于该数据集中的人体尺度变化,可以通过[3]中提出并在[10]中应用的注意算法来解决。
因此,我们为我们的模型添加即插即用模块,即注意力网络[3]。特别是,我们采用多尺度输入并使用注意力网络来合并结果。 最终模型“注意+ MMAN”将mIoU提高到59.91%,这比目前最先进的方法[10]高+ 0.55%。 当我们研究每级的IoU分数时,我们对LIP的分数有类似的观察。 在手臂和腿部可以观察到改善是最大的。最先进的方法[10,20,3]的改善在上臂超过+ 0.6%,在下臂超过+ 1.8%,超过+0.4 大腿%,小腿大于+ 0.9%。 比较表明我们的方法非常有竞争力。
第三,我们将在LIP上训练的模型部署到PPSS数据集的测试集,而不进行任何微调。 我们的目标是评估所提出模型的泛化能力。
为了使LIP和PPSS数据集中的标签保持一致,我们将LIP的细粒度标签合并到PPSS中定义的粗粒度人体标签中。
表3 PPSS数据集上人类解析准确性的比较[25]。 最佳表现以蓝色突出显示。


图5:Pascal-Person-Part数据集上的定性解析结果。
评估结果报告如表3所示。MMAN产生的mIoU为52.11%,其显着优于DL [25] DDN [25]和ASN [24]分别为+ 16.9%,+ 4.9%和+ 1.4%。 因此,当在具有不同图像样式的另一数据集上直接测试时,我们的模型仍然产生良好的性能。
在图5中,我们提供了分别通过Baseline(Do-Deeplab-ASPP)、Baseline+Micro D、Baseline+Micro D和完整MMAN获得的一些分割实例,还显示了真实标签图。 我们观察到Baseline + Micro D显着降低了模糊和噪声,有助于产生清晰的边界,Baseline + Macro D可以纠正不合理的人体姿势。 完整的MMAN方法集成了Micro AN和Micro AN的优点,并实现了更高的解析精度。 我们还在图6中的PPSS数据集上给出了定性结果。
4.4 变体研究
我们在LIP数据集上进一步评估MMAN的三种不同变体,即单AN,双AN和多AN。 表5详述了参数的数字,全局FOV(g.FOV)和局部FOV(1.FOV)大小,以及每个变体的架构草图。 还提供了原始MMAN的结果以进行清楚的比较。单个AN指的是传统的对抗网络,只有一个鉴别器。 鉴别器连接到顶层,并在256×256标签图上具有全局感受野。 结果显示,单个AN的平均IoU收益率为45.23%,略高于基线但低于MMAN。 这一结果表明采用Macro D和Micro D优于单一鉴别器,这证明了第3.5节中分析的正确性。 更重要的是,我们在训练单个AN时观察到收敛(pc)不良的问题。 这是由于在高分辨率标签地图上使用大型视野。
双AN与MMAN具有相同数量的鉴别符。 不同之处在于Double AN将Macro D附加到顶层。 与Double AN相比,MMAN显着改善了0.82%的结果。 结果说明了Macro D和Micro D的互补效果:Macro D作用于深层,并为后面的顶层提供了良好的粗粒度初始化,Micro D有助于通过细粒度的视觉细节来补救粗略的语义特征。
多个AN旨在评估使用两个以上鉴别器时的解析准确度。 为此,我们将额外的鉴别器附加到G的第三解卷积层。特别地,鉴别器具有与Micro D相同的架构并且聚焦在64×64标签图上的22×22贴片上。 结果如表5所示,采用三个鉴别器使平均IoU略有改善(0.16%),但结构更复杂,参数更多。
5 结论
在本文中,介绍了一种用于人体解析的新型Macro - Micro对抗网络(MMAN),它显著的减少了语义不一致性,例如错位的人体部分,以及解析结果中的局部不一致性,例如模糊和漏洞。 我们的模型使用最先进的方法在两个挑战人类解析数据集上实现了比较解析准确性,并且在其他数据集上具有良好的泛化能力。 这两种对抗性损失是互补的,并且优于以前采用单一对抗性损失的方法。 此外,MMAN通过较小的感受域实现了全局和局部监督,有效地避免了对抗性网络在处理高分辨率图像时收敛性差的问题。
Q:label map翻译为标签图?标签映射?标签转换?
《Macro-Micro Adversarial Network for Human Parsing》论文阅读笔记的更多相关文章
- 《MuseGAN: Multi-track Sequential Generative Adversarial Networks for Symbolic Music Generation and Accompaniment》论文阅读笔记
出处:2018 AAAI SourceCode:https://github.com/salu133445/musegan abstract: (写得不错 值得借鉴)重点阐述了生成音乐和生成图片,视频 ...
- (转)Introductory guide to Generative Adversarial Networks (GANs) and their promise!
Introductory guide to Generative Adversarial Networks (GANs) and their promise! Introduction Neural ...
- 生成对抗网络(Generative Adversarial Networks,GAN)初探
1. 从纳什均衡(Nash equilibrium)说起 我们先来看看纳什均衡的经济学定义: 所谓纳什均衡,指的是参与人的这样一种策略组合,在该策略组合上,任何参与人单独改变策略都不会得到好处.换句话 ...
- 生成对抗网络(Generative Adversarial Networks, GAN)
生成对抗网络(Generative Adversarial Networks, GAN)是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的学习方法之一. GAN 主要包括了两个部分,即 ...
- StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks 论文笔记
StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks 本文将利 ...
- 论文笔记之:Semi-Supervised Learning with Generative Adversarial Networks
Semi-Supervised Learning with Generative Adversarial Networks 引言:本文将产生式对抗网络(GAN)拓展到半监督学习,通过强制判别器来输出类 ...
- 《Self-Attention Generative Adversarial Networks》里的注意力计算
前天看了 criss-cross 里的注意力模型 仔细理解了 在: https://www.cnblogs.com/yjphhw/p/10750797.html 今天又看了一个注意力模型 < ...
- Paper Reading: Perceptual Generative Adversarial Networks for Small Object Detection
Perceptual Generative Adversarial Networks for Small Object Detection 2017-07-11 19:47:46 CVPR 20 ...
- SalGAN: Visual saliency prediction with generative adversarial networks
SalGAN: Visual saliency prediction with generative adversarial networks 2017-03-17 摘要:本文引入了对抗网络的对抗训练 ...
- Generative Adversarial Networks,gan论文的畅想
前天看完Generative Adversarial Networks的论文,不知道有什么用处,总想着机器生成的数据会有机器的局限性,所以百度看了一些别人 的看法和观点,可能我是机器学习小白吧,看完之 ...
随机推荐
- Rarfile解压不了的问题
最近用python调用rarfile进行解压rar压缩包时,报了如下错误: rarfile.RarCannotExec: Unrar not installed? (rarfile.UNRAR_TOO ...
- 【转】Java学习---算法那些事
[更多参考] LeetCode算法 每日一题 1: Two Sum ----> 更多参考[今日头条--松鼠游学] 史上最全的五大算法总结 Java学习---7大经典的排序算法总结实现 程序员都应 ...
- 题解 P1550 【[USACO08OCT]打井Watering Hole】
题面(翻译有点问题,最后一句话) 农民John 决定将水引入到他的n(1<=n<=300)个牧场.他准备通过挖若 干井,并在各块田中修筑水道来连通各块田地以供水.在第i 号田中挖一口井需要 ...
- vultr vps(ubuntu)忘记密码
参考官方解决方案:https://www.vultr.com/docs/boot-into-single-user-mode-reset-root-password 在此仅给出ubuntu下的解决 D ...
- css实现常用的两栏三栏布局
1.两栏 <div class="wrapper"> <div class="half left">left box <p> ...
- 《Linux大棚命令百篇下》网络篇的总结
本文是<Linux大棚命令百篇下>网络篇的总结 ping -c 指定数量,在windows下会自动停止,linux下会一直ping下去 -q 简短报告 -s 指定每次ping的数据包大小, ...
- 有意思的flex 色子布局
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" ...
- android 7.0以上共享文件(解决调用系统照相和图片剪切出现的FileUriExposedException崩溃问题)
在android7.0开始试共享“file://”URI 将会导致引发 FileUriExposedException. 如果应用需要与其他应用共享私有文件,则应该使用 FileProvider, F ...
- 609E- Minimum spanning tree for each edge
Connected undirected weighted graph without self-loops and multiple edges is given. Graph contains n ...
- XML 的4种解析方式
在上一篇博客中,我们介绍了什么是 XML ,http://www.cnblogs.com/ysocean/p/6901008.html,那么这一篇博客我们介绍如何来解析 XML . 部分文档引用:ht ...