非线性优化(高翔slam---第六讲 )
1.线性最小二乘问题
2.非线性最小二乘问题
因为它非线性,所以df/dx有时候不好求,那么可以采用迭代法(有极值的话,那么它收敛,一步步逼近):

这样求导问题就变成了递归逼近问题,那么增量△xk如何确定?
这里介绍三种方法:
(1)一阶和二阶梯度法
将目标函数在x附近进行泰勒展开:
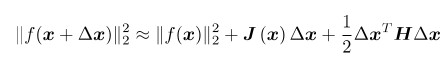

(2)高斯牛顿法
将f(x)一阶展开: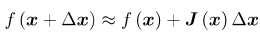 (1)
(1)
这里J(x)为f(x)关于x的导数,实际上是一个m×n的矩阵,也是一个雅克比矩阵。现在要求下降矢量△x,使得||f(x+△x)|| 达到最小。
为求△ x,我们需要解一个线性的最小二乘问题:
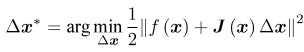
这里注意变量是△ x,而非之前的x。所以是线性函数,好求。为此,先展开目标函数的平方项:
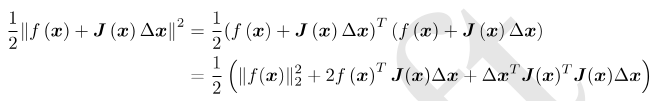

我们称为高斯牛顿方程。我们把左边的系数定义为H,右边定义为g,那么上式变为:
H △x=g
跟牛顿法对比可以发现,我们用J(x)TJ(x)代替H的求法,从而节省了计算量。所以高斯牛顿法跟牛顿法相比的优点就在于此,步骤列于下:


但是,还是有缺陷,就是它要求我们所用的近似H矩阵是可逆的(而且是正定的),但实际数据中计算得到的JTJ却只有半正定性。也就是说,在使用Gauss Newton方法时,可能出现JTJ为奇异矩阵或者病态(ill-condition)的情况,此时增量的稳定性较差,导致算法不收敛。更严重的是,就算我们假设H非奇异也非病态,如果我们求出来的步长△x太大,也会导致我们采用的局部近似(1)不够准确,这样一来我们甚至都无法保证它的迭代收敛,哪怕是让目标函数变得更大都是可能的。
所以,接下来的Levenberg-Marquadt方法加入了α,在△x确定了之后又找到了α,从而||f(x+α△x)||2达到最小,而不是直接令α=1。
(3)列文伯格-马夸尔特方法(Levenberg-Marquadt法)
由于Gauss-Newton方法中采用的近似二阶泰勒展开只能在展开点附近有较好的近似效果,所以我们很自然地想到应该给△x添加一个信赖区域(Trust Region),不能让它太大而使得近似不准确。非线性优化中有一系列这类方法,这类方法也被称之为信赖区域方法(Trust Region Method)。在信赖区域里边,我们认为近似是有效的;出了这个区域,近似可能会出问题。
那么如何确定这个信赖区域的范围呢?
一个比较好的方法是根据我们的近似模型跟实际函数之间的差异来确定这个范围:如果差异小,我们就让范围尽可能大;如果差异大,我们就缩小这个近似范围。因此,考虑使用: 来判断泰勒近似是否够好。ρ的分子是实际函数下降的值,分母是近似模型下降的值。如果ρ接近于1,则近似是好的。如果ρ太小,说明实际减小的值远少于近似减小的值,则认为近似比较差,需要缩小近似范围。反之,如果ρ比较大,则说明实际下降的比预计的更大,我们可以放大近似范围。
来判断泰勒近似是否够好。ρ的分子是实际函数下降的值,分母是近似模型下降的值。如果ρ接近于1,则近似是好的。如果ρ太小,说明实际减小的值远少于近似减小的值,则认为近似比较差,需要缩小近似范围。反之,如果ρ比较大,则说明实际下降的比预计的更大,我们可以放大近似范围。
于是,我们构建一个改良版的非线性优化框架,该框架会比Gauss Newton有更好的效果。
1. 给定初始值x0,以及初始化半径μ。
2. 对于第k次迭代,求解:
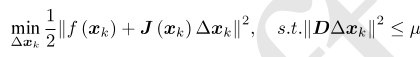 (2)
(2)
这里面的限制条件μ是信赖区域的半径,D将在后文说明。
3. 计算ρ。
4. 若ρ>3/4,则μ=2μ;
5. 若ρ<1/4,则μ=0.5μ;
6. 如果ρ大于某阈值,认为近似可行。令xk+1=xk+△xk。
7. 判断算法是否收敛。如不收敛则返回2,否则结束。
这里近似扩大范围的倍数和阈值都是经验值,亦可替换成别的数值。在式(1)中,我们把增量范围限定在一个半径为μ的球中。带上D之后,这个球可以看成是个椭球。
(Levenberg提出的优化方法中,把D取成单位矩阵I,相当于直接把△x约束在球中。Marquart提出将D取成非负数对角阵---通常用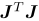 的对角元素平方根。)
的对角元素平方根。)
无论怎样,都需要解(2)这样一个问题来获得梯度,其是带不等式约束的优化问题,我们用Lagrange乘子将它转化为一个无约束优化问题:
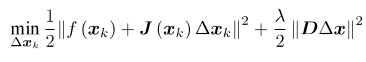
λ为Lagrange乘子。展开后,化简得到:
当λ比较小时,H占主要地位,接近于牛顿高斯法;当λ比较大时,接近于最速下降法。
L-M的求解方式,可在一定程度上避免线性方程组的系数矩阵的非奇异和病态问题,提供更稳定更准确的增量△x。
小结:



视觉SLAM里,这个矩阵往往有特定的稀疏形式,为实时求解优化问题提供了可能性。利用
稀疏形式的消元,分解,最后再求解增量,会让求解效率大大提高。(第十讲)
实践:
1.Ceres库(谷歌)



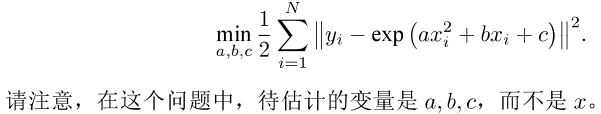
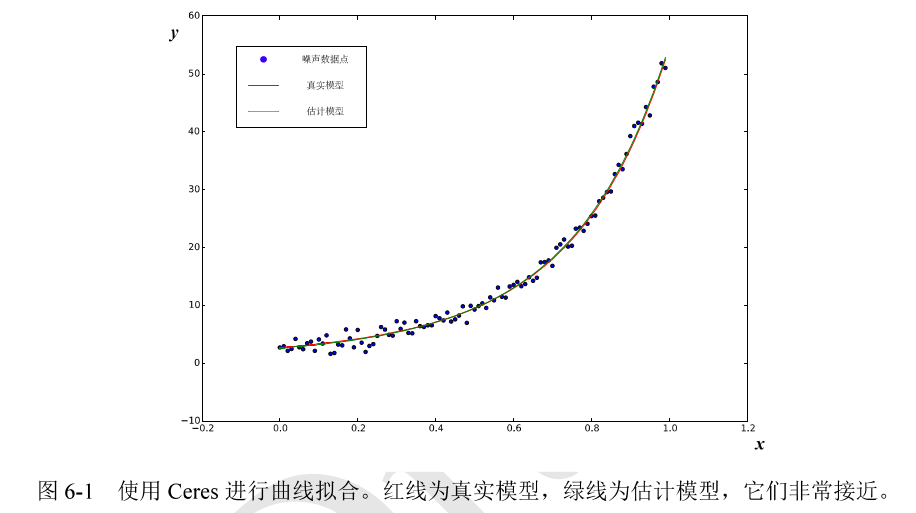

2.g20库(基于图优化)



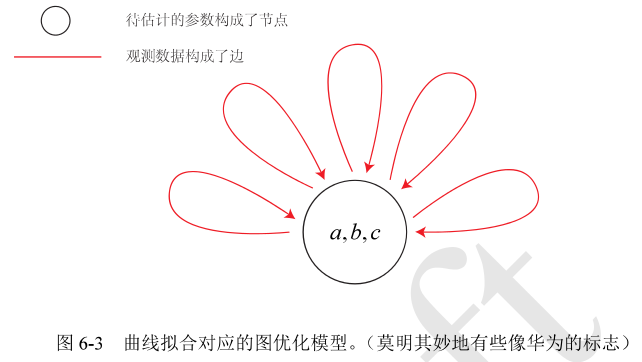
g20步骤:

总结:

非线性优化(高翔slam---第六讲 )的更多相关文章
- 高翔《视觉SLAM十四讲》从理论到实践
目录 第1讲 前言:本书讲什么:如何使用本书: 第2讲 初始SLAM:引子-小萝卜的例子:经典视觉SLAM框架:SLAM问题的数学表述:实践-编程基础: 第3讲 三维空间刚体运动 旋转矩阵:实践-Ei ...
- 《SLAM十四讲》个人学习知识点梳理
0.引言 从六月末到八月初大概一个月时间一直在啃SLAM十四讲[1]这本书,这本书把SLAM中涉及的基本知识点都涵盖了,所以在这里做一个复习,对这本书自己学到的东西做一个梳理. 书本地址:http:/ ...
- 高博-《视觉SLAM十四讲》
0 讲座 (1)SLAM定义 对比雷达传感器和视觉传感器的优缺点(主要介绍视觉SLAM) 单目:不知道尺度信息 双目:知道尺度信息,但测量范围根据预定的基线相关 RGBD:知道深度信息,但是深度信息对 ...
- 《视觉SLAM十四讲》第2讲
目录 一 视觉SLAM中的传感器 二 经典视觉SLAM框架 三 SLAM问题的数学表述 注:原创不易,转载请务必注明原作者和出处,感谢支持! 本讲主要内容: (1) 视觉SLAM中的传感器 (2) 经 ...
- Stanford机器学习---第六讲. 怎样选择机器学习方法、系统
原文:http://blog.csdn.net/abcjennifer/article/details/7797502 本栏目(Machine learning)包括单参数的线性回归.多参数的线性回归 ...
- 机器学习基石的泛化理论及VC维部分整理(第六讲)
第六讲 第五讲主要讲了机器学习可能性,两个问题,(1)\(E_{in} 要和 E_{out}\) 有很接近,(2)\(E_{in}\)要足够小. 对于第一个假设,根据Hoefding's Inequa ...
- 《ArcGIS Engine+C#实例开发教程》第六讲 右键菜单添加与实现
原文:<ArcGIS Engine+C#实例开发教程>第六讲 右键菜单添加与实现 摘要:在这一讲中,大家将实现TOCControl控件和主地图控件的右键菜单.在AE开发中,右键菜单有两种实 ...
- 32位汇编第六讲,OllyDbg逆向植物大战僵尸,快速定位阳光基址
32位汇编第六讲,OllyDbg逆向植物大战僵尸,快速定位阳光基址 一丶基址,随机基址的理解 首先,全局变量的地址,我们都知道是固定的,是在PE文件中有保存的 但是高版本有了随机基址,那么要怎么解决这 ...
- PE格式第六讲,导出表
PE格式第六讲,导出表 请注意,下方字数比较多,其实结构挺简单,但是你如果把博客内容弄明白了,对你受益匪浅,千万不要看到字数多就懵了,其实字数多代表它重要.特别是第五步, 各种表中之间的关系. 作者: ...
- C++反汇编第六讲,认识C++中的Try catch语法,以及在反汇编中还原
C++反汇编第六讲,认识C++中的Try catch语法,以及在反汇编中还原 我们以前讲SEH异常处理的时候已经说过了,C++中的Try catch语法只不过是对SEH做了一个封装. 如果不懂SEH异 ...
随机推荐
- [PC]PHPCMS配置文件的读取
--------------------------------------------------------------------------------------------------- ...
- 18. socket io
类似dataservice 我们socket io 和后端交互 我们也可以做成专门的service 我们先引入 为什么不是cdn呢? 因为client就是从我们的server端拿到的socket.io ...
- win8安装iis asp.net
http://www.sanrengo.net/thread-62-1-1.html本文主要解决的是在win8操作系统下IIS配置asp.net的运行环境,当然win7的配置方法也大致相似,只有少许部 ...
- 学JS的心路历程-Promise(二)
昨天有说到Promise的创建以及then的用法,今天我们来看错误处理. then onRejected 我们昨天有提到说,then两个函式参数,onFulfilled和onRejected,而onR ...
- Oracle监听程序未启动或数据库服务未注册到该监听
oracle新建数据库的时候提示Could not find appropriate listener for this database要做的操作如下: 1.查看netmanager里面的liste ...
- Linux部署项目
1 安装jdk 第一步:获取Linux系统中jdk安装包和tomcat安装包(后面要用,所以上传两个) 第二步:使用secureCRT客户端工具连到服务器 第三步:使用命令创建一个目录,作为软件的安装 ...
- echarts 树图
1 事件:事件绑定,事件命名统一挂载到require('echarts/config').EVENT(非模块化为echarts.config.EVENT)命名空间下,建议使用此命名空间作为事件名引用, ...
- NCB之taxonomy系列
1.taxonomy之简介 生物分类学是研究生物系统的一种强有力的组织原则.遗传.共同遗传的同源性以及在确定功能时保护序列和结构,这些都是生物学的中心思想,直接关系到任何一组生物体的进化史.因此,分类 ...
- 加载 AssetBundle 的四种方法
[加载 AssetBundle 的四种方法] 1.AssetBundle.LoadFromMemoryAsync(byte[] binary, uint crc = 0); 返回AssetBundle ...
- 第七篇:Jmeter连接MySQL的测试
.准备一个有数据表格的MySQL数据库: 2.在测试计划面板上点击浏览按钮,把你的JDBC驱动添加进来: mysql-connector-java-5.1.26-bin.jar 3.添加一个线程组-- ...