Scrapy实践----获取天气信息
scrapy是一个非常好用的爬虫框架,它是基于Twisted开发的,Twisted又是一个异步网络框架,既然它是异步的,那么执行起来肯定会很快,所以scrapy的执行速度也不会慢的!
如果你还没没有学过scrapy的话,那么我建议你先去学习一下,再来看这个小案例,毕竟这是基于scrapy来实现的!网上有很多有关scrapy的学习资料,你可以自行百度来学习!
接下来进入我们的正题:
如何利用scrapy来获取某个城市的天气信息呢?
我们爬取的网站是:天气网
城市我们可以自定义
1.创建项目名称
scrapy startproject weatherSpider
2.编写items.py文件
在这个文件中我们主要定义我们想要抓取的数据:
a.城市名(city)
b.日期(date)
c.天气状况(weather)
d.湿度(humidity)
e.空气质量(air_quality)
import scrapy
class WeatherspiderItem(scrapy.Item):
"""
设置要爬取的信息
"""
city = scrapy.Field()
date = scrapy.Field()
weather = scrapy.Field()
humidity = scrapy.Field()
air_quality = scrapy.Field()
3.打开网页
利用Chrome浏览器来提取上面5个信息
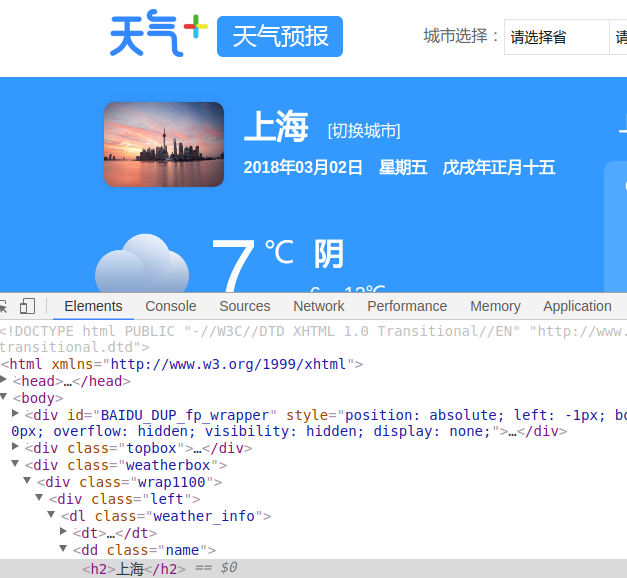
利用同样的方式我们可以找到其余4个信息个XPath表达式
4.编写爬虫文件
在第3步中我们已经找到我们想要的信息的XPath表达式了,我们就可以开始写代码了
import scrapy
from scrapy import loader
from ..items import WeatherspiderItem
class WeatherSpider(scrapy.Spider):
name = 'weather'
allowed_domains = ['tianqi.com']
# 这是事先定义好的城市,我们还可以在里面添加其他城市名称
cities = ['shanghai', 'hangzhou', 'beijing']
base_url = 'https://www.tianqi.com/'
start_urls = []
for city in cities:
start_urls.append(base_url + '{}'.format(city))
def parse(self, response):
"""
提取上海今天的天气信息
:param response:
:return:
"""
# 创建一个ItemLoader,方便处理数据
iloader = loader.ItemLoader(WeatherspiderItem(),response=response)
iloader.add_xpath("city", '//dl[@class="weather_info"]//h2/text()')
iloader.add_xpath('date', '//dl[@class="weather_info"]/dd[@class="week"]/text()')
iloader.add_xpath('weather', '//dl[@class="weather_info"]/dd[@class="weather"]'
'/p[@class="now"]/b/text()')
iloader.add_xpath('weather', '//dl[@class="weather_info"]/dd[@class="weather"]'
'/span/b/text()')
iloader.add_xpath('weather', '//dl[@class="weather_info"]/dd[@class="weather"]'
'/span/text()')
iloader.add_xpath('humidity', '//dl[@class="weather_info"]/dd[@class="shidu"]'
'/b/text()')
iloader.add_xpath('air_quality', '//dl[@class="weather_info"]/dd[@class="kongqi"]'
'/h5/text()')
iloader.add_xpath('air_quality', '//dl[@class="weather_info"]/dd[@class="kongqi"]'
'/h6/text()')
return iloader.load_item()
如果觉得困惑为何要使用ItemLoader的话,建议去读一下关于ItemLoader的官方文档:传送门
5.结果保存为JSON格式
要想把我们提取的结果保存到某种文件中,我们需要编写pipelines
import os
import json
class StoreAsJson(object):
def process_item(self, item, spider):
# 获取工作目录
pwd = os.getcwd()
# 在当前目录下创建文件
filename = pwd + '/data/weather.json'
with open(filename, 'a') as fp:
line = json.dumps(dict(item), ensure_ascii=False) + '\n'
fp.write(line)
6.添加设置信息
我们写的pipelines文件要起作用,需要在settings.py中设置
ITEM_PIPELINES = {
'WeatherSpider.pipelines.StoreAsJson': 300,
}
7.启动爬虫
scrapy crawl wether
8.参考资料
从零开始写Python爬虫 --- 2.3 爬虫实践:天气预报&数据存储
如果大家喜欢的话,请点个赞!!O(∩_∩)O
Scrapy实践----获取天气信息的更多相关文章
- 半吊子学习Swift--天气预报程序-获取天气信息
昨天申请的彩云天气Api开发者今天上午已审核通过  饭后运动过后就马不停蹄的来测试接口,接口是采用经纬度的方式来获取天气信息,接口地址如下 https://api.caiyunapp.com/v2/ ...
- 内网公告牌获取天气信息解决方案(C# WebForm)
需求:内网公告牌能够正确显示未来三天的天气信息 本文关键字:C#/WebForm/Web定时任务/Ajax跨域 规划: 1.天定时读取百度接口获取天气信息并存储至Txt文档: 2.示牌开启时请求Web ...
- C#调用WebService获取天气信息
概述 本文使用C#开发Winform应用程序,通过调用<WebXml/>(URL:http://www.webxml.com.cn)的WebService服务WeatherWS来获取天气预 ...
- java获取天气信息
通过天气信息接口获取天气信息,首先要给项目导入程序所需要的包,具体需要如下几个包: json-lib-2.4.jar ezmorph-1.0.6.jar commons-beanutils-1.8.3 ...
- Kettle通过Webservice获取天气信息
Kettle通过Webservice获取天气信息 需求: 通过kettle工具,通过webservice获取天气信息,写成xml格式文件. 思路: Kettle可通过两种选择获取webservic ...
- Java通过webservice接口获取天气信息
通过SOAP请求的方式获取天气信息并解析返回的XML文件. 参考: http://www.webxml.com.cn/WebServices/WeatherWS.asmx import java.io ...
- ajax无刷新获取天气信息
浏览器由于安全方面的问题,禁止ajax跨域请求其他网站的数据,但是可以再本地的服务器上获取其他服务器的信息,在通过ajax请求本地服务来实现: <?php header("conten ...
- Android实现自动定位城市并获取天气信息
定位实现代码: <span style="font-size:14px;">import java.io.IOException; import java.util.L ...
- java解析xml实例——获取天气信息
获取xml并解析其中的数据: package getweather.xml; import java.io.IOException; import java.util.HashMap; import ...
随机推荐
- 【linux】suse linux 常用命令
命令ls——列出文件 ls -la 给出当前目录下所有文件的一个长列表,包括以句点开头的“隐藏”文件 ls a* 列出当前目录下以字母a开头的所有文件 ls -l *.doc 给出当前目录下以.doc ...
- Tomcat Connector原理
Tomcat工作原理 要了解其中的工作原理我们首先看如下两个图 Tomcat基本架构图: Tomcat请求示意图: 客户端的请求通过Connector接受处理后在到容器Engine->Host- ...
- 一张图看懂Mysql的join连接
INNER JOIN:当两个表中都匹配时返回行. LEFT JOIN:返回左表中的所有行,即使右表中没有匹配项也是如此. RIGHT JOIN:返回右表中的所有行,即使左表中没有匹配项也是如此. FU ...
- html页面跳转传递参数
效果如下: a页面 点击跳转按钮后 在b页面可以获取到对应的值. 代码如下: a页面: <!DOCTYPE html> <html> <head lang="e ...
- localStorage/cookie 用法分析与简单封装
本地存储是HTML5中提出来的概念,分localStorage和sessionStorage.通过本地存储,web应用程序能够在用户浏览器中对数据进行本地的存储.与 cookie 不同,存储限制要大得 ...
- LeetCode题解之Rotate String
1.题目描述 2.问题分析 直接旋转字符串A,然后做比较即可. 3.代码 bool rotateString(string A, string B) { if( A.size() != B.size( ...
- PHP用正则匹配字符串中的特殊字符防SQL注入
本文出至:新太潮流网络博客 /** * [用正则匹配字符串中的特殊字符] * @E-mial wuliqiang_aa@163.com * @TIME 2017-04-07 * @WEB http:/ ...
- Sql Server 中如果使用TransactionScope开启一个分布式事务,使用该事务两个并发的连接会互相死锁吗
提问: 如果使用TransactionScope开启一个分布式事务,使用该事务两个并发的连接会互相死锁吗? 如果在.Net中用TransactionScope开启一个事务. 然后在该事务范围内启动两个 ...
- jQuery为元素设置css的问题
例子: 有如下的html代码 对文本框设置字体大小为20px ,即font-size:20px 首先会想到如下: $('input').css({font-size:'20px'}); 由于属性不能使 ...
- 利用percona-toolkit定位数据库性能问题
当你的性能瓶颈卡在数据库这块的时候,可以通过percona-toolkit来进行问题定位. 那么,首先,介绍下percona-toolkit.percona-toolkit是一组高级命令行工具的集合, ...