dubbo的spi机制
SPI
SPI是一种扩展机制,在java中SPI机制被广泛应用,比如Spring中的SpringServletContainerInitializer 使得容器启动的时候SpringServletContainerInitializer 执行onStartup方法。在dubbo中,dubbo实现了自己的spi扩展机制,下面详细的讲解下,dubbo的扩展机制。
dubbo SPI使用-Filter的定义使用
dubbo中的fiter是使用spi机制实现的典型应用,现在使用filter作为例子,展示先dubbo的spi机制。
首先定义一个filter。
public class MyFilter implements Filter {
public Result invoke(Invoker<?> invoker, Invocation invocation)
throws RpcException {
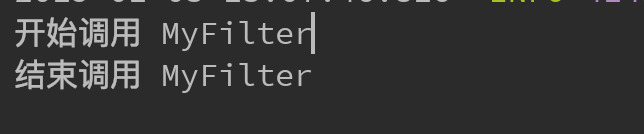
System.out.println("开始调用 MyFilter");
Result result = invoker.invoke(invocation);
System.out.println("结束调用 MyFilter");
return result;
}
}
将filter加到dubbo默认的filter
@Activate(group = {Constants.CONSUMER})
在消费端使用filter
在消费者的resource文件下建
/META-INF/dubbo/internal/com.alibaba.dubbo.rpc.Filter
内容为:
myFilter=com.lenny.sample.dubbo.common.filter.MyFilter
在消费端指定filter
@Reference(version = "1.0.0",filter = "myFilter")
private UserDubboService userDubboService;
在调用userDubboService的服务器时在控制台打印如下内容:
在服务端使用filter
在服务端的resource文件下建
/META-INF/dubbo/internal/com.alibaba.dubbo.rpc.Filter
内容为:
myFilter=com.lenny.sample.dubbo.common.filter.MyFilter
在服务提供者指定filter:
@Service(version = "1.0.0",filter = "myFilter")
同样在控制台打印如下内容:
dubbo默认filter
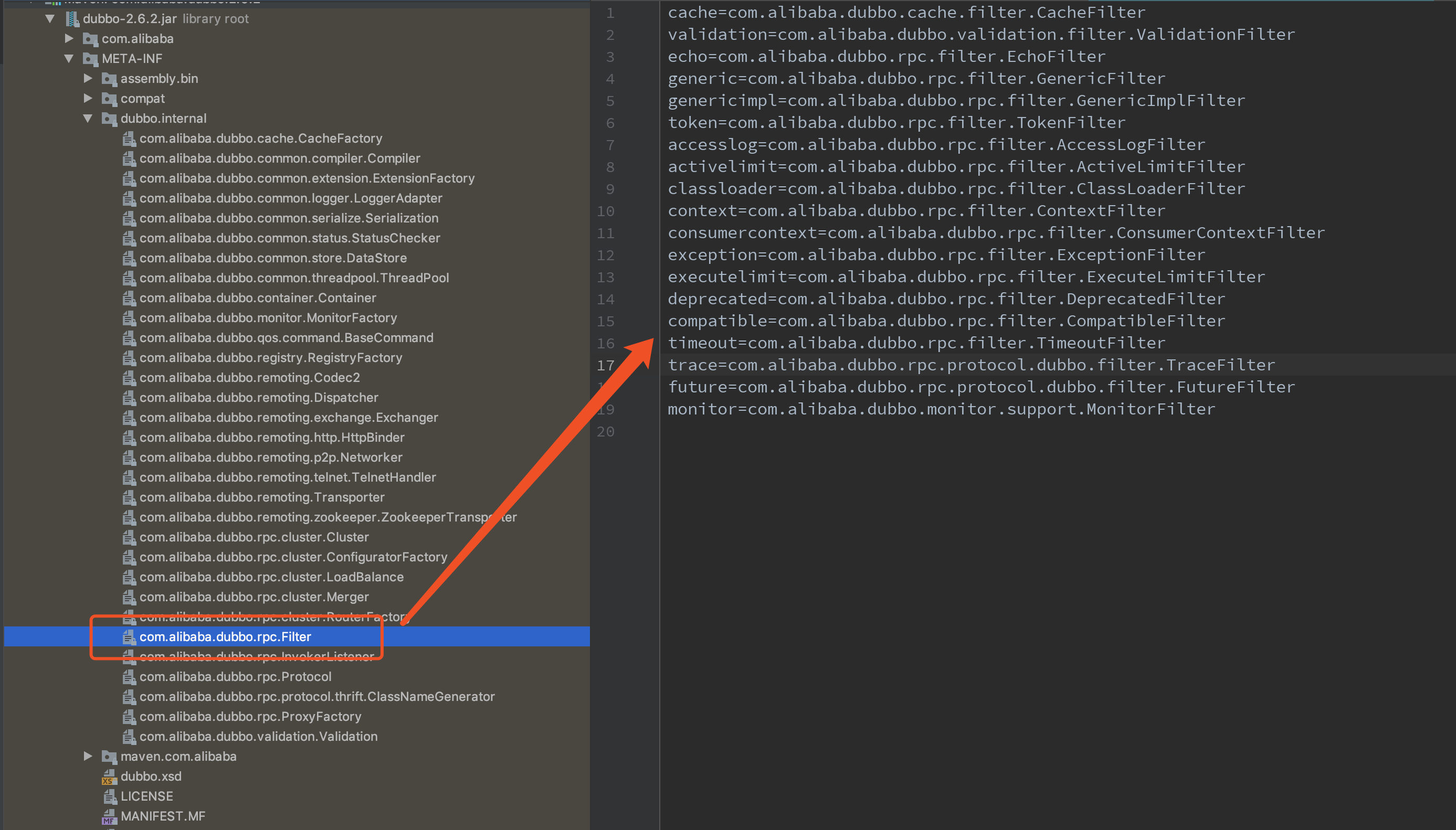
dubbo默认提供一些filter。
dubbo filter源码分析
Filter的加载源码位于ProtocolFilterWrapper类,具体实现过程
// 服务端暴露
@Override
public <T> Exporter<T> export(Invoker<T> invoker) throws RpcException {
if (Constants.REGISTRY_PROTOCOL.equals(invoker.getUrl().getProtocol())) {
return protocol.export(invoker);
}
return protocol.export(buildInvokerChain(invoker, Constants.SERVICE_FILTER_KEY, Constants.PROVIDER));
}
// 消费端
@Override
public <T> Invoker<T> refer(Class<T> type, URL url) throws RpcException {
if (Constants.REGISTRY_PROTOCOL.equals(url.getProtocol())) {
return protocol.refer(type, url);
}
return buildInvokerChain(protocol.refer(type, url), Constants.REFERENCE_FILTER_KEY, Constants.CONSUMER);
}
主要看buildInvokerChain。
private static <T> Invoker<T> buildInvokerChain(final Invoker<T> invoker, String key, String group) {
Invoker<T> last = invoker;
// 获取全部的filter
List<Filter> filters = ExtensionLoader.getExtensionLoader(Filter.class).getActivateExtension(invoker.getUrl(), key, group);
if (!filters.isEmpty()) {
for (int i = filters.size() - 1; i >= 0; i--) {
final Filter filter = filters.get(i);
final Invoker<T> next = last;
last = new Invoker<T>() {
@Override
public Class<T> getInterface() {
return invoker.getInterface();
}
@Override
public URL getUrl() {
return invoker.getUrl();
}
@Override
public boolean isAvailable() {
return invoker.isAvailable();
}
@Override
public Result invoke(Invocation invocation) throws RpcException {
// 执行filter的invoke方法
return filter.invoke(next, invocation);
}
@Override
public void destroy() {
invoker.destroy();
}
@Override
public String toString() {
return invoker.toString();
}
};
}
}
return last;
}
在执行export的时候获取全部的filter,绑定到要执行的方法上面,在要执行的方面的时候,执行filter方法。
Spi的加载原理
在ExtensionLoader中有loadExtensionClasses方法,加载全部的扩展类。
private static final String SERVICES_DIRECTORY = "META-INF/services/";
private static final String DUBBO_DIRECTORY = "META-INF/dubbo/";
private static final String DUBBO_INTERNAL_DIRECTORY = DUBBO_DIRECTORY + "internal/";
private static final Pattern NAME_SEPARATOR = Pattern.compile("\\s*[,]+\\s*");
private Map<String, Class<?>> loadExtensionClasses() {
final SPI defaultAnnotation = type.getAnnotation(SPI.class);
if (defaultAnnotation != null) {
String value = defaultAnnotation.value();
if ((value = value.trim()).length() > 0) {
String[] names = NAME_SEPARATOR.split(value);
if (names.length > 1) {
throw new IllegalStateException("more than 1 default extension name on extension " + type.getName()
+ ": " + Arrays.toString(names));
}
if (names.length == 1) cachedDefaultName = names[0];
}
}
Map<String, Class<?>> extensionClasses = new HashMap<String, Class<?>>();
// 去相应的文件路径下扫描文件
loadDirectory(extensionClasses, DUBBO_INTERNAL_DIRECTORY);
loadDirectory(extensionClasses, DUBBO_DIRECTORY);
loadDirectory(extensionClasses, SERVICES_DIRECTORY);
return extensionClasses;
}
private void loadDirectory(Map<String, Class<?>> extensionClasses, String dir) {
// 文件路径加上全类名
String fileName = dir + type.getName();
try {
Enumeration<java.net.URL> urls;
ClassLoader classLoader = findClassLoader();
if (classLoader != null) {
urls = classLoader.getResources(fileName);
} else {
urls = ClassLoader.getSystemResources(fileName);
}
if (urls != null) {
while (urls.hasMoreElements()) {
java.net.URL resourceURL = urls.nextElement();
// 加载资源文件
loadResource(extensionClasses, classLoader, resourceURL);
}
}
} catch (Throwable t) {
logger.error("Exception when load extension class(interface: " +
type + ", description file: " + fileName + ").", t);
}
}
根据使用@SPI的注解的类全类名去如下路径,找到相应问文件,解析文件内容
- META-INF/dubbo/internal/全类名
- META-INF/dubbo/全类名
- META-INF/services/全类名
如以filter为例:
package com.alibaba.dubbo.rpc;
import com.alibaba.dubbo.common.extension.SPI;
@SPI
public interface Filter {
Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException;
}
Filter的全类名是com.alibaba.dubbo.rpc.Filter。所以可以去扫描如下路径
META-INF/dubbo/internal/com.alibaba.dubbo.rpc.Filter
META-INF/dubbo/com.alibaba.dubbo.rpc.Filter
META-INF/services/com.alibaba.dubbo.rpc.Filter
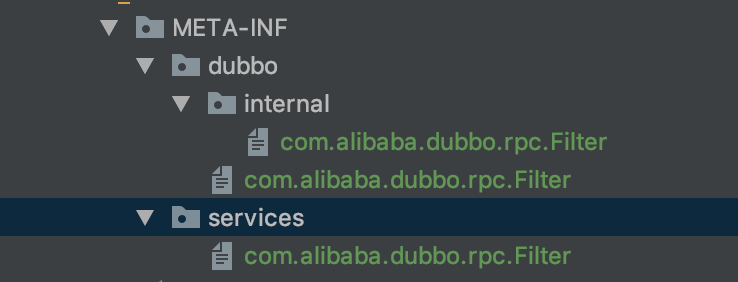
在上面的例子中将MyFilter的文件定义到了META-INF/dubbo/internal/com.alibaba.dubbo.rpc.Filter路径下。
当然也可以放到META-INF/dubbo/com.alibaba.dubbo.rpc.Filter和META-INF/services/com.alibaba.dubbo.rpc.Filter。
如图:放到下面三个位置任何一个位置都是可以的。
本文源代码:https://github.com/applenele/sample
dubbo的spi机制的更多相关文章
- Dubbo的SPI机制与JDK机制的不同及原理分析
从今天开始,将会逐步介绍关于DUbbo的有关知识.首先先简单介绍一下DUbbo的整体概述. 概述 Dubbo是SOA(面向服务架构)服务治理方案的核心框架.用于分布式调用,其重点在于分布式的治理. 简 ...
- 面试常问的dubbo的spi机制到底是什么?
前言 dubbo是一款微服务开发框架,它提供了 RPC通信 与 微服务治理 两大关键能力.作为spring cloud alibaba体系中重要的一部分,随着spring cloud alibaba在 ...
- Dubbo剖析-SPI机制
文章要点: 1.什么是SPi 2.Dubbo为什么要实现自己的SPi 3.Dubbo的IOC和AOP 4.Dubbo的Adaptive机制 5.Dubbo动态编译机制 6.Dubbo与Spring的融 ...
- jdk和dubbo的SPI机制
前言:开闭原则一直是软件开发领域中所追求的,开闭原则中的"开"是指对于组件功能的扩展是开放的,是允许对其进行功能扩展的,“闭”,是指对于原有代码的修改是封闭的,即不应该修改原有的代 ...
- Dubbo中SPI扩展机制解析
dubbo的SPI机制类似与Java的SPI,Java的SPI会一次性的实例化所有扩展点的实现,有点显得浪费资源. dubbo的扩展机制可以方便的获取某一个想要的扩展实现,每个实现都有自己的name, ...
- dubbo源码分析1——SPI机制的概要介绍
插件机制是Dubbo用于可插拔地扩展底层的一些实现而定制的一套机制,比如dubbo底层的RPC协议.注册中心的注册方式等等.具体的实现方式是参照了JDK的SPI思想,由于JDK的SPI的机制比较简单, ...
- dubbo 的 spi 思想是什么?
面试题 dubbo 的 spi 思想是什么? 面试官心理分析 继续深入问呗,前面一些基础性的东西问完了,确定你应该都 ok,了解 dubbo 的一些基本东西,那么问个稍微难一点点的问题,就是 spi, ...
- 4.dubbo 的 spi 思想是什么?
作者:中华石杉 面试题 dubbo 的 spi 思想是什么? 面试官心理分析 继续深入问呗,前面一些基础性的东西问完了,确定你应该都 ok,了解 dubbo 的一些基本东西,那么问个稍微难一点点的问题 ...
- Dubbo的SPI是个什么鬼
原文:https://mp.weixin.qq.com/s/bQc_tASkfsojlcd897kLtA # spi 是啥? spi,简单来说,就是 service provider interfac ...
随机推荐
- Docker学习2-虚拟化
虚拟化就是由位于下层的软件模块,根据上层的软件模块的期待,抽象(虚拟)出一个虚拟的软件或硬件模块,使上一层软件直接运行在这个与自己期待完全一致的虚拟环境上.从这个意义上来看,虚拟化既可以是软件层的抽象 ...
- 无法读取配置节“oracle.manageddataaccess.client”,因为它缺少节声明
程序发布后出现问题: 无法读取配置节“oracle.manageddataaccess.client”,因为它缺少节声明 解决办法: 1.安装了odac12. ODTwithODAC121010.z ...
- SVN之 trunk, branches and tags意义
--简单的对照 SVN的工作机制在某种程度上就像一颗正在生长的树: 一颗有树干和很多分支的树 分支从树干生长出来.而且细的分支从相对较粗的树干中长出 一棵树能够仅仅有树干没有分支(可是这样的情况不会持 ...
- [SDOI2009]HH的项链 BZOJ1878
分析: 听说是莫队裸题,很显然,我并不喜欢莫队. 我们可以考虑将询问离线,以右端点排序,之后从1枚举到n,依次树状数组中修改i和last[i],之后当i==询问的右节点时,find一下答案就可以了. ...
- English_word_learning
这次报名参加了学院的21天打卡活动,说实话,也是想给自己一个积累的平台. 毕竟,真的有时候感觉挺弱的 有的人用了一年考完了四六级,而有人却用四年还未考完. 听到有一位学长因为自己的四级成绩没有达到48 ...
- Android APK 签名比对(转)
Android apk签名的过程 1. 生成MANIFEST.MF文件: 程序遍历update.apk包中的所有文件(entry),对非文件夹非签名文件的文件,逐个生成SHA1的数字签名信息,再用Ba ...
- 20155216 Exp5 MSF基础应用
Exp5 MSF基础应用 基础问题回答 1.用自己的话解释什么是exploit,payload,encode? exploit : Exploit的英文意思就是利用,在做攻击时,通常称为漏洞利用. 一 ...
- 20155220 Exp5 MSF基础应用
Exp5 MSF基础应用 一个主动攻击实践,MS08-067 首先利用msfconsole启用msf终端 然后利用search MS08-067搜索漏洞,会显示相应漏洞模块 根据上图,我们输入use ...
- 2017-2018-2 20155333 《网络对抗技术》 Exp1 PC平台逆向破解
2017-2018-2 20155333 <网络对抗技术> Exp1 PC平台逆向破解 1. 逆向及Bof基础实践说明 1.1 实践目标 本次实践的对象是一个名为pwn1的linux可执行 ...
- Unused Method(不再使用的方法)——Dead Code(死亡代码)
系列文章目录: 使用Fortify进行代码静态分析(系列文章) Unused Method(不再使用的方法) 示例: private bool checkLevel(strin ...