pgm7
和 Koller 的 video 最大的不同莫过于书上讲 LBP 的角度不是 procedural 的,而是原理性的。我们先看个 procedural 的,在一般的 cluster graph 上的 BP 改进版即 loopy belief propagation 先将所有的 message 初始化为 1,然后依照原先的策略进行消息传递,直到收敛为止。这里面收敛很可能不是所有的消息都能收敛,同时传递消息的顺序一般比较 tricky,过去认为有效的同步传递方式已经被搞清楚很多情况下不能收敛到合理的解了。另外一旦收敛了,我们可以证明得到的结果是 calibrated。问题是我们就算了解了这些过程性的东西,仍然无法弄清楚 LBP 究竟在干啥,有的 margin 似乎能收敛到正确的,有的却不行。
为此我们需要换一个角度来理解 LBP,这也就是这部分我们讨论的重点。值得注意的是很多方法上的东西的确在历史上出现在前,但是“换思路”有时候才能揭示一些更深层的东西。这里的思路就是把 inference 通过 optimization 的形式表述出来,这样我们就得到了 LBP 的另外一种 interpretation:使用 fixed point 优化这个近似的目标函数。这也提供给我们了一些其他的思路,比如 expectation propagation 使用的仍然是精确的目标函数,但是传递的是近似的消息。又比如 mean field approximation,这也是用的精确的目标函数,但是将约束松弛到一族给定了分解形式的分布上。
那么问题就来了,如何能把 inference 转换到 optimization 上来呢?这就要借助前面讨论的 I-projection 和 M-projection 了。咋一看似乎前面的讨论偏向 M-projection,但实际上却不是,因为 



这势必要求我们找到的 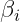


一个要求
我们进一步讨论关于能量函数 





为了进行求解,我们需要将 

(注:对一般的 cluster graph 一般说来 


这样我们分别计算对


如果令 


这个条件由于对应的是 fixed point 方程的一个迭代解法,这导致了我们一般 LBP 算法的另一个 interpretation。对 tree 结构而言,迭代一次后 message 就收敛了(没有 loop 的原因)。事实上,在 cluster graph 上沿袭 clique tree 的算法,也可以类似的应用到
为了研究 LBP 的近似程度,我们可以在 cluster graph 选择一个子树,如果原图是 calibrated,我们的这棵子树也将是 calibrated,我们可以检查其上的 belief 是否和其上的 marginal 一致,事实上存在一致的也存在不一致的情形。对收敛性的分析一般在 synchronous 更新上比较容易做(但是 synchronous 效果很差,不建议使用),使用的技巧是 
和 clique tree 类似,选择合理的 cluster graph 意味着对计算精度和效率的 tradeoff,常用的一种选择是 Bethe cluster graph,这似乎就是 Frey 所说的 factor graph:每个 
那么从算法上对 BP 的修正意味着对目标函数如何的变化呢?注意前面的目标函数(自由能)虽然并不方便(计算难),我们仍然可以使用 factorized 的版本 
当我们选择 Bethe cluster graph 时对应的 energy functional 也称为 Bethe free energy,其中熵的部分可以写成

其中 



类似我们也能定义 calibration,另外我们为了在合适的 region graph 上导出对应的 message passing 以及对应的 fixed point equations,还需要
- variable connectedness:一个 r.v. 对应的顶点形成一个联通分支
- factor connected ness:对每个 factor
也形成联通分支
- factor preservation:
- RIP,对每个变量


关于 LBP 一个很重要的应用是 turbocodes 里面,我们知道解码往往就是通过观测到被污染的编码后的信息解析出来生成这个编码的数据(因为我们知道原始数据和编码方式,我们可以简单的用这个手段分析一个编码的优劣,并且 Shannon 同志已经搞定了理论下界,我们只需要想办法接近它就行),turbocodes 通过两个 codec 并且在两部分 inference 进行 LBP 这获得了非常接近理论界的 codec。这个发现也使得本来已经停滞不前的 approximate inference 研究重新审视 LBP。
从 Koller 的 video 里面我们还知道下面几个东西:
- LBP 很可能出现问题的情况是 tight loop,strong potential 且 conflicting message
- LBP 的 convergence 是 local property,有的就是不会收敛,通常实现的时候达到迭代次数后就会停止
- LBP 的 message passing order 很重要,常用的有 tree reparameterization(TRP),选择一个树,然后在该结构上做一次(因为收敛了),然后不停的重复,尽量选大的树(如 expanding tree);residual belief prpagation(RBP),选择在 sepset 上 disagree 最多的 cluster 进行消息传递
- 加速 LBP 的策略还有 damping:和上次的 message 凸组合。
后面我们讨论另外两种 approximate inference 的策略。
——————
And yet indeed she is my sister; she is the daughter of my father, but not the daughter of my mother; and she became my wife.
pgm7的更多相关文章
- Moodle插件之Filters(过滤器)
Moodle插件之Filters(过滤器) 过滤器是一种在输出之前自动转换内容的方法. 目的: 创建名为helloworld的过滤器,实现将预输出的“world”字符串替换成“hello world” ...
随机推荐
- Jquery属性练习
<!DOCTYPE html> <html lang="en" xmlns="http://www.w3.org/1999/xhtml"> ...
- CAN总线学习系列之三——CAN控制器的选择
CAN总线学习系列之三——CAN控制器的选择 在进行CAN总线开发前,首先要选择好CAN总线控制器.下面就比较一些控制器的特点. 一些主要的CAN总线器件产品 制造商 产品型号 器件功能及特点 Int ...
- 【LeetCode9】Palindrome Number★
题目描述: 解题思路: 求回文数,并且要求不能使用额外的空间.思路很简单,算出x的倒置数reverse,比较reverse是否和x相等就行了. Java代码: public class LeetCod ...
- cmake源码包安装后的卸载问题
cmake源码包安装 CMake是一个跨平台的安装(编译)工具,可以用简单的语句来描述所有平台的安装(编译过程),具体学习请移步官网CMake 本文介绍的就是用cmake去安装的别人的包. 一般流程: ...
- [CF986F]Oppa Funcan Style Remastered[exgcd+同余最短路]
题意 给你 \(n\) 和 \(k\) ,问能否用 \(k\) 的所有 \(>1\) 的因子凑出 \(n\) .多组数据,但保证不同的 \(k\) 不超过 50 个. \(n\leq 10^{1 ...
- [CF1010E]Store[kd-tree]
题意 有一个长方体,不知道它的位置,给出 \(n\) 个一定在长方体内的点和 \(m\) 个一定不在的点,有 \(k\) 次询问,每次询问一个点是否 在.不在.不确定 在长方体内. \(n\leq 1 ...
- springboot @PropertySource
@ConfigurationProperties(prefix="person") 默认加载全局配置文件 application.properties或application.ym ...
- stl源码剖析 详细学习笔记 仿函数
//---------------------------15/04/01---------------------------- //仿函数是为了算法而诞生的,可以作为算法的一个参数,来自定义各种操 ...
- mysql select 字段别名是否可以用在 select中或者where中
select column1+10 as c1,c1+10 as c2 from table1;想实现上面的效果,结果在mysql里面报错了,提示找不到c1这个列; -- 不同的 数据库不一样 一般不 ...
- 团队作业Week6:规格说明书编写
(1)请分析你们团队项目的典型用户和场景,并写一个团队博客发布你们团队项目的功能规格说明书. (2)再写一个博客团队博客发布你们项目的设计文档(技术规格说明书). 截止时间:2015-11-03