[大牛翻译系列]Hadoop(1)MapReduce 连接:重分区连接(Repartition join)
4.1 连接(Join)
连接是关系运算,可以用于合并关系(relation)。对于数据库中的表连接操作,可能已经广为人知了。在MapReduce中,连接可以用于合并两个或多个数据集。例如,用户基本信息和用户活动详情信息。用户基本信息来自于OLTP数据库。用户活动详情信息来自于日志文件。
MapReduce的连接操作可以用于以下场景:
- 用户的人口统计信息的聚合操作(例如:青少年和中年人的习惯差异)。
- 当用户超过一定时间没有使用网站后,发邮件提醒他们。(这个一定时间的阈值是用户自己预定义的)
- 分析用户的浏览习惯。让系统可以基于这个分析提示用户有哪些网站特性还没有使用到。进而形成一个反馈循环。
所有这些场景都要求将多个数据集连接起来。
最常用的两个连接类型是内连接(inner join)和外连接(outer join)。如下图所示,内连接比较两个关系中所有的元组,判断是否满足连接条件,然后生成一个满足连接条件的结果集。与内连接相反的是,外连接并不需要两个关系的元组都满足连接条件。在连接条件不满足的时候,外连接可以将其中一方的数据保留在结果集中。
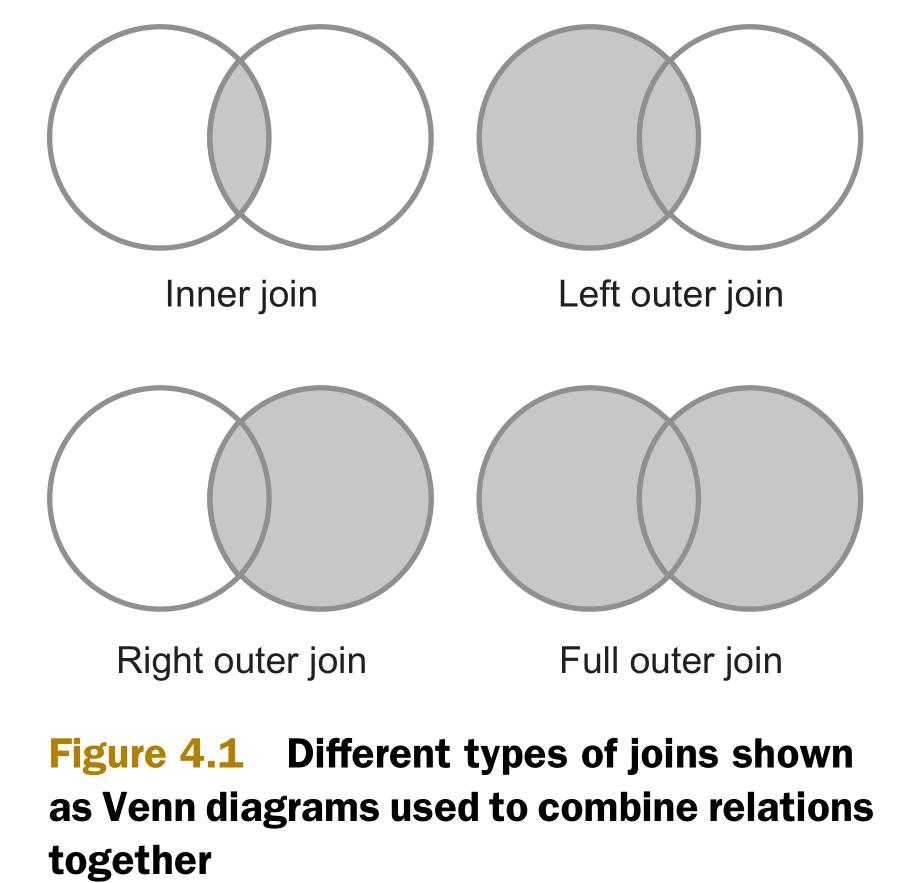
为了实现内连接和外连接,MapReduce中有三种连接策略,如下所示。这三种连接策略有的在map阶段,有的在reduce阶段。它们都针对MapReduce的排序-合并(sort-merge)的架构进行了优化。
- 重分区连接(Repartition join)—— reduce端连接。使用场景:连接两个或多个大型数据集。
- 复制连接(Replication join)—— map端连接。使用场景:待连接的数据集中有一个数据集足够小到可以完全放在缓存中。
- 半连接(Semi-join)—— 另一个map端连接。使用场景:待连接的数据集中有一个数据集非常大,但同时这个数据集可以被过滤成小到可以放在缓存中。
在介绍完这些连接策略之后,还会介绍另一个策略:决策树。可以根据实际情况选择最优策略。
4.1.1 重分区连接(Repartition join)
重分区连接是reduce端连接。它利用MapReduce的排序-合并机制来分组数据。它只使用一个单独的MapReduce任务,并支持多路连接(N-way join)。多路指的是多个数据集。
Map阶段负责从多个数据集中读取数据,决定每个数据的连接值,将连接值作为输出键(output key)。输出值(output value)则包含将在reduce阶段被合并的值。
Reduce阶段,一个reduce接收map函数传来的每一个输出键的所有输出值,并将数据分为多个分区。在此之后,reduce对所有的分区进行笛卡尔积(Cartersian product)连接运算,并生成全部的结果集。
以上MapReduce过程如图4.2所示:

|
注:过滤(filtering)和投影(projection) 在MapReduce重分区连接中,最好能够减少map阶段传输到reduce阶段的数据量。因为通过网络在这两个阶段中排序和传输数据会产生很高的成本。如果不能避免reduce端的工作,那么一个最佳实践就是尽可能在map阶段多过滤数据和投影。过滤指的是将map极端的输入数据中不需要的部分丢弃。投影是关系代数的概念。投影用于减少发送给reduce的字段。例如:在分析用户数据的时候,如果只关注用户的年龄,那么在map任务中应该只投影(或输出)年龄字段,不考虑用户的其他的字段。 |
技术19:优化重分区连接
《Hadoop in Action》给出了一个例子,说明如何使用Hadoop的社区包(contrib package)org.apache.hadoop.contrib.utils.join实现重分区连接。这个贡献包打包了所有的处理细节,仅仅需要实现一个非常简单的方法。
然而,这个社区包对重分区的实现方法的空间效率低下。它需要将待连接的所有输出值都读取到内存中,然后进行多路连接(multiway join)。实际上,如果仅仅将小数据集读取到内存中,然后用小数据集遍历大数据集来进行连接,这样将更加高效。
问题
需要在MapReduce中进行重分区连接,但是不希望在reduce阶段将所有的数据都放到缓存中。
解决方案
这个技术运用了优化后的重分区框架。它仅仅将一个待连接的数据集放在缓存中,减少了reduce需要放在缓存中的数据。
讨论
附录D.1(http://www.cnblogs.com/datacloud/p/3617079.html)中介绍了优化后的重分区框架的实现。这个实现是根据org.apache.hadoop.contrib.utils.join社区包进行建模。这个优化后的框架仅仅缓存两个数据集中比较小的那一个,以减少内存消耗。图4.3是优化后的重分区连接的流程图:

图4.4是实现的类图。类图中包含两个部分,一个通用框架和一些类的实现样例。

使用这个连接框架需要实现抽象类OptimizedDataJoinMapperBase和OptimizedDataJoinReducerBase。
例如,需要连接用户详情数据和用户活动日志。第一步,判断两个数据集中那一个比较小。对于一般的网站来说,用户详情数据会比较小,用户活动日志会比较大。
在如下示例中,用户数据中有用户姓名,年龄和所在州
$ cat test-data/ch4/users.txt
anne 22 NY
joe 39 CO
alison 35 NY
mike 69 VA
marie 27 OR
jim 21 OR
bob 71 CA
mary 53 NY
dave 36 VA
dude 50 CA
用户活动日志中有用户姓名,进行的动作,来源IP。这个文件一般都要比用户数据要大得多。
$ cat test-data/ch4/user-logs.txt
jim logout 93.24.237.12
mike new_tweet 87.124.79.252
bob new_tweet 58.133.120.100
mike logout 55.237.104.36
jim new_tweet 93.24.237.12
marie view_user 122.158.130.90
首先,必须实现抽象类OptimizedDataJoinMapperBase。这个将在map端被调用。这个类将创建map的输出键和输出值。同时,它还将提示整个框架,当前处理的文件是不是比较小的那个。
public class SampleMap extends OptimizedDataJoinMapperBase {
private boolean smaller;
@Override
protected Text generateInputTag(String inputFile) {
// tag the row with input file name (data source)
smaller = inputFile.contains("users.txt");
return new Text(inputFile);
}
@Override
protected String genGroupKey(Object key, OutputValue output) {
return key.toString();
}
@Override
protected boolean isInputSmaller(String inputFile) {
return smaller;
}
@Override
protected OutputValue genMapOutputValue(Object o) {
return new TextTaggedOutputValue((Text) o);
}
}
下一步,你需要实现抽象类 OptimizedDataJoinReducerBase。它将在reduce端被调用。在这个类中,将从map端传入不同数据集的输出键和输出值,然后返回reduce端的输出数组。
public class SampleReduce extends OptimizedDataJoinReducerBase {
private TextTaggedOutputValue output = new TextTaggedOutputValue();
private Text textOutput = new Text();
@Override
protected OutputValue combine(String key,
OutputValue smallValue,
OutputValue largeValue) {
if(smallValue == null || largeValue == null) {
return null;
}
Object[] values = {
smallValue.getData(), largeValue.getData()
};
textOutput.set(StringUtils.join(values, "\t"));
output.setData(textOutput);
return output;
}
最后,任务的主代码(driver code)需要指明InputFormat类,并设置次排序(Secondary sort)。
job.setInputFormat(KeyValueTextInputFormat.class);
job.setMapOutputKeyClass(CompositeKey.class);
job.setMapOutputValueClass(TextTaggedOutputValue.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setPartitionerClass(CompositeKeyPartitioner.class);
job.setOutputKeyComparatorClass(CompositeKeyComparator.class);
job.setOutputValueGroupingComparator(CompositeKeyOnlyComparator.class);
现在连接的准备工作就做完了,可以开始运行连接:
$ hadoop fs -put test-data/ch4/users.txt users.txt
$ hadoop fs -put test-data/ch4/user-logs.txt user-logs.txt
$ bin/run.sh com.manning.hip.ch4.joins.improved.SampleMain users.txt,user-logs.txt output
$ hadoop fs -cat output/part*
bob 71 CA new_tweet 58.133.120.100
jim 21 OR logout 93.24.237.12
jim 21 OR new_tweet 93.24.237.12
jim 21 OR login 198.184.237.49
marie 27 OR login 58.133.120.100
marie 27 OR view_user 122.158.130.90
mike 69 VA new_tweet 87.124.79.252
mike 69 VA logout 55.237.104.36
如果和连接的源文件相对比,可以看到因为实现了一个内连接,输出中不包括用户anne,alison等不存在于日志文件中的记录。
小结:
这个连接的实现通过只缓存比较小的数据集来提高来Hadoop社区包的效率。但是,当数据从map阶段传输到reduce阶段的时候,仍然产生了很高的网络成本。
此外,Hadoop社区包支持多路连接,这里的实现只支持二路连接。
如果要更多地减少reduce端连接的内存足迹(memory footprint),一个简单的机制是在map函数中更多地进行投影操作。投影减少了map阶段的输出中的字段。例如:在分析用户数据的时候,如果只关注用户的年龄,那么在map任务中应该只投影(或输出)年龄字段,不考虑用户的其他的字段。这样就减少了map和reduce之间的网络负担,也减少了reduce在连接时的内存消耗。
和原始的社区包一样,这里的重分区的实现也支持过滤和投影。通过允许genMapOutputValue方法返回空值,就可以支持过滤。通过在genMapOutputValue方法中定义输出值的内容,就可以支持投影。
如果你既想输出所有的数据到reduce,又想避免排序的损耗,就需要考虑另外两种连接策略,复制连接和半连接。
[大牛翻译系列]Hadoop(1)MapReduce 连接:重分区连接(Repartition join)的更多相关文章
- [大牛翻译系列]Hadoop(3)MapReduce 连接:半连接(Semi-join)
4.1.3 半连接(Semi-join) 假设一个场景,需要连接两个很大的数据集,例如,用户日志和OLTP的用户数据.任何一个数据集都不是足够小到可以缓存在map作业的内存中.这样看来,似乎就不能使用 ...
- [大牛翻译系列]Hadoop(4)MapReduce 连接:选择最佳连接策略
4.1.4 为你的数据选择最佳连接策略 已介绍的每个连接策略都有不同的优点和缺点.那么,怎么来判断哪个最适合待处理的数据? 图4.11给出了一个决策树.这个决策树是于论文<A Compariso ...
- [大牛翻译系列]Hadoop(5)MapReduce 排序:次排序(Secondary sort)
4.2 排序(SORT) 在MapReduce中,排序的目的有两个: MapReduce可以通过排序将Map输出的键分组.然后每组键调用一次reduce. 在某些需要排序的特定场景中,用户可以将作业( ...
- [大牛翻译系列]Hadoop 翻译文章索引
原书章节 原书章节题目 翻译文章序号 翻译文章题目 链接 4.1 Joining Hadoop(1) MapReduce 连接:重分区连接(Repartition join) http://www.c ...
- [大牛翻译系列]Hadoop(2)MapReduce 连接:复制连接(Replication join)
4.1.2 复制连接(Replication join) 复制连接是map端的连接.复制连接得名于它的具体实现:连接中最小的数据集将会被复制到所有的map主机节点.复制连接有一个假设前提:在被连接的数 ...
- [大牛翻译系列]Hadoop(22)附录D.2 复制连接框架
附录D.2 复制连接框架 复制连接是map端连接,得名于它的具体实现:连接中最小的数据集将会被复制到所有的map主机节点.复制连接的实现非常直接明了.更具体的内容可以参考Chunk Lam的<H ...
- [大牛翻译系列]Hadoop(21)附录D.1 优化后的重分区框架
附录D.1 优化后的重分区框架 Hadoop社区连接包需要将每个键的所有值都读取到内存中.如何才能在reduce端的连接减少内存开销呢?本文提供的优化中,只需要缓存较小的数据集,然后在连接中遍历较大数 ...
- [大牛翻译系列]Hadoop(14)MapReduce 性能调优:减小数据倾斜的性能损失
6.4.4 减小数据倾斜的性能损失 数据倾斜是数据中的常见情况.数据中不可避免地会出现离群值(outlier),并导致数据倾斜.这些离群值会显著地拖慢MapReduce的执行.常见的数据倾斜有以下几类 ...
- [大牛翻译系列]Hadoop(6)MapReduce 排序:总排序(Total order sorting)
4.2.2 总排序(Total order sorting) 有的时候需要将作业的的所有输出进行总排序,使各个输出之间的结果是有序的.有以下实例: 如果要得到某个网站中最受欢迎的网址(URL),就需要 ...
随机推荐
- Python实践之(七)逻辑回归(Logistic Regression)
机器学习算法与Python实践之(七)逻辑回归(Logistic Regression) zouxy09@qq.com http://blog.csdn.net/zouxy09 机器学习算法与Pyth ...
- Linux内核加载全流程
无论是Linux还是Windows,在加电后的第一步都是先运行BIOS(Basic Input/Output System)程序——不知道是不是所以的电脑系统都是如此.BIOS保存在主板上的一个non ...
- 如何判断一个数是否为素数(zt)
怎么判断一个数是否为素数? 笨蛋的作法: bool IsPrime(unsigned n){ if (n<2) { //小于2的数即不是合数也不是素数 throw 0; ...
- SqlServer2008 之 应用积累
1.断开数据库连接,在原有查询窗口(断开数据库连接的未关闭查询窗口),对现在所连数据库进行操作,结果是对已断开数据库的误操作. 正确操作:重新连接数据库后,应关闭原有查询窗口,新建查询窗口后再执行操作 ...
- python(7)–类的多态实现
第一步: 先定义三个类: class Animal: def __init__(self, name): self.name = name #这个方法的意思是,如果继承该类,就得自己写talk方法,如 ...
- 关于 VS2012 创建 MVC4 Empty 项目的一个小问题
今天下午发现一个新建的项目工作异常,主要表现为应该返回JSON的Action没有返回JSON字符串,而是返回了JsonResult的对象名,即字符串“System.Web.Mvc.JsonResult ...
- 关于php一些数组函数
array_column($array,"key") 将二维数组中的键名为key的数据生成一个新数组 array_unique($array) 去除重复值
- Sublime Text 插件之常用20个插件
作为一个开发者你不可能没听说过 Sublime Text.不过你没听说过也没关系,下面让你明白. Sublime Text是一款非常精巧的文本编辑器,适合编写代码.做笔记.写文章.它用户界面十分整洁, ...
- winform 上传文件
using System; using System.Collections.Generic; using System.Text; using System.Net; using System.IO ...
- C#Winform版获取Excel文件的内容
public MainForm() { InitializeComponent(); //this.ofd_in.DefaultExt = ".xlsx"; this.ofd_in ...