利用Python进行数据分析(7) pandas基础: Series和DataFrame的简单介绍
一、pandas 是什么
和
DataFrame。
二、Series
,类似于 NumPy 的一维 array。它除了包含一组数据还包含一组索引,所以可以把它理解为一组带索引的数组。


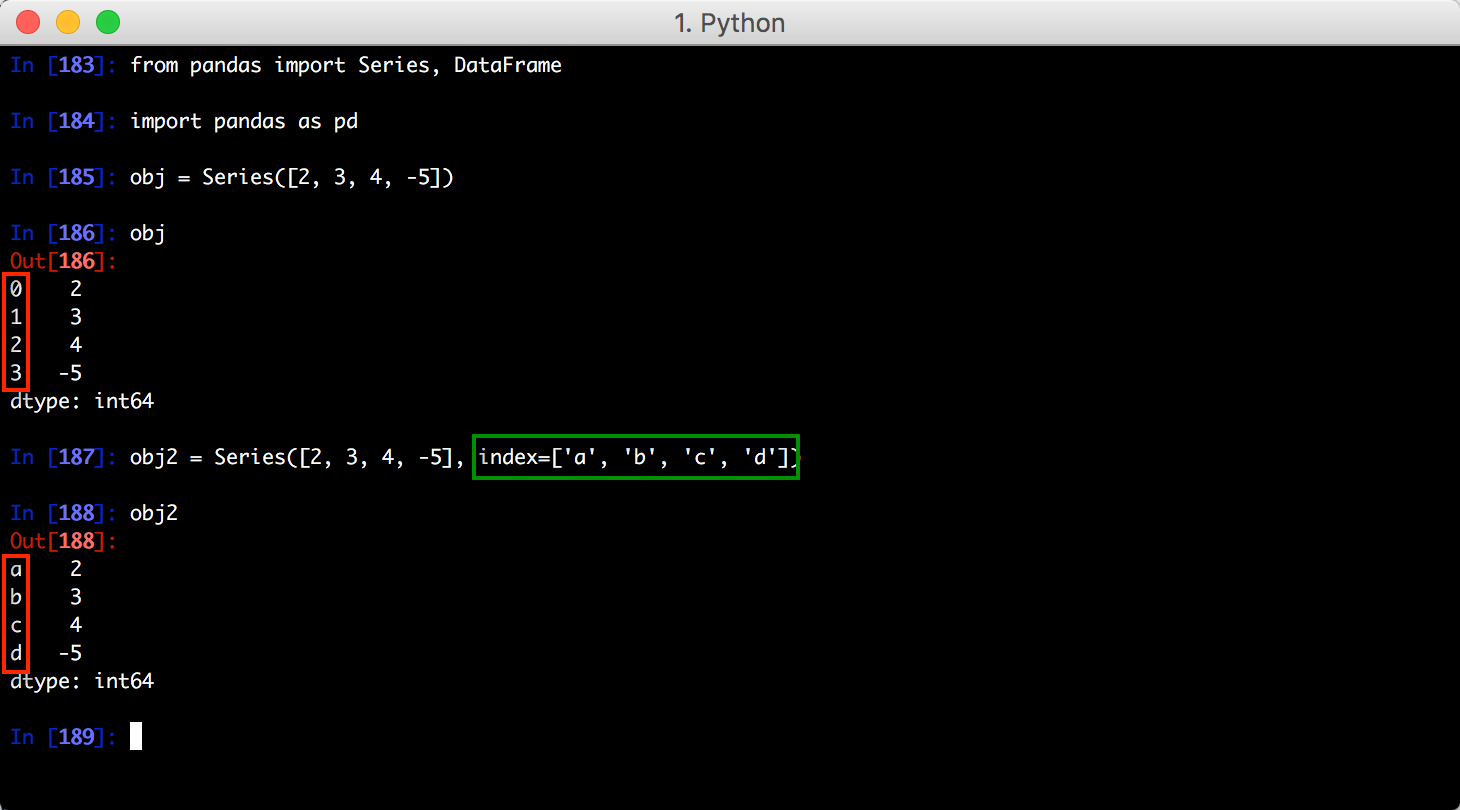

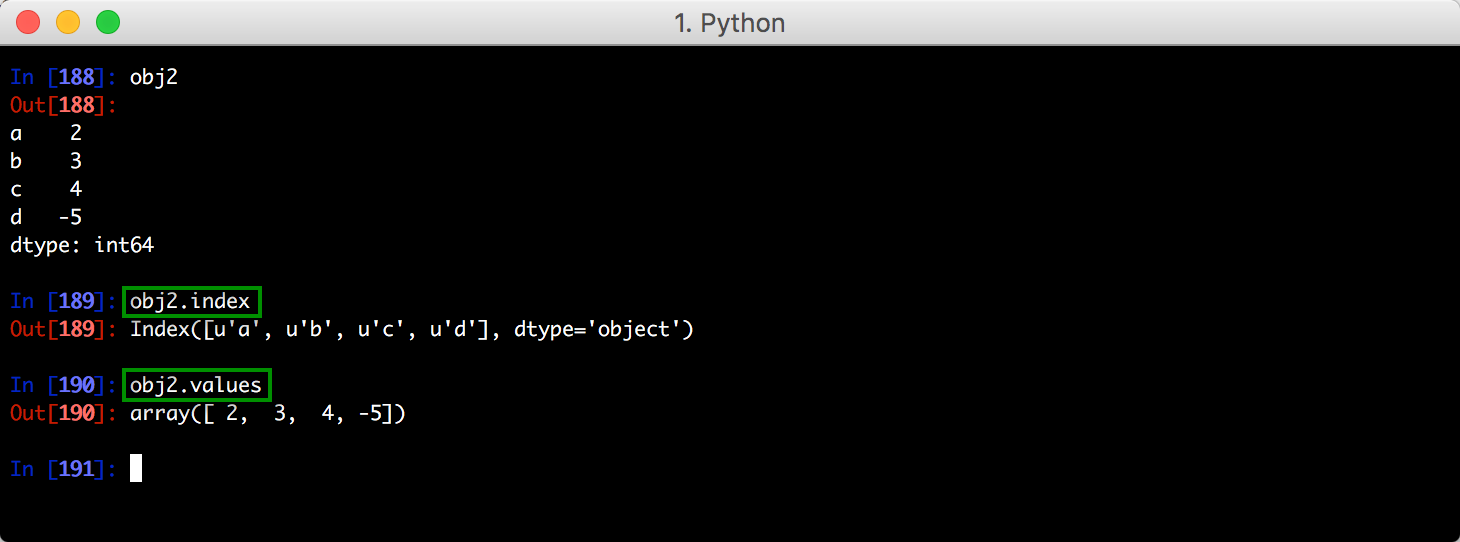
index
和
values
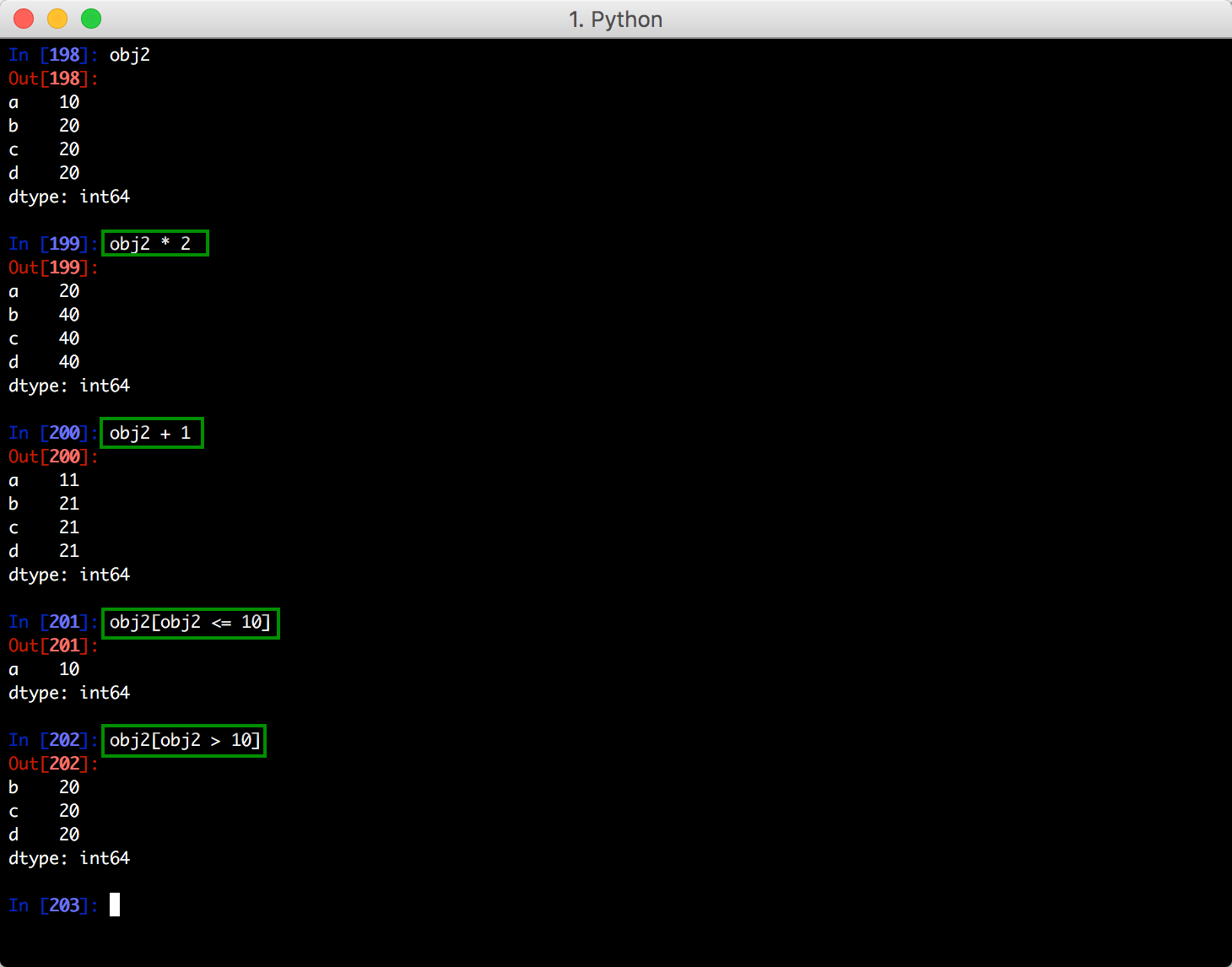
属性,例如:
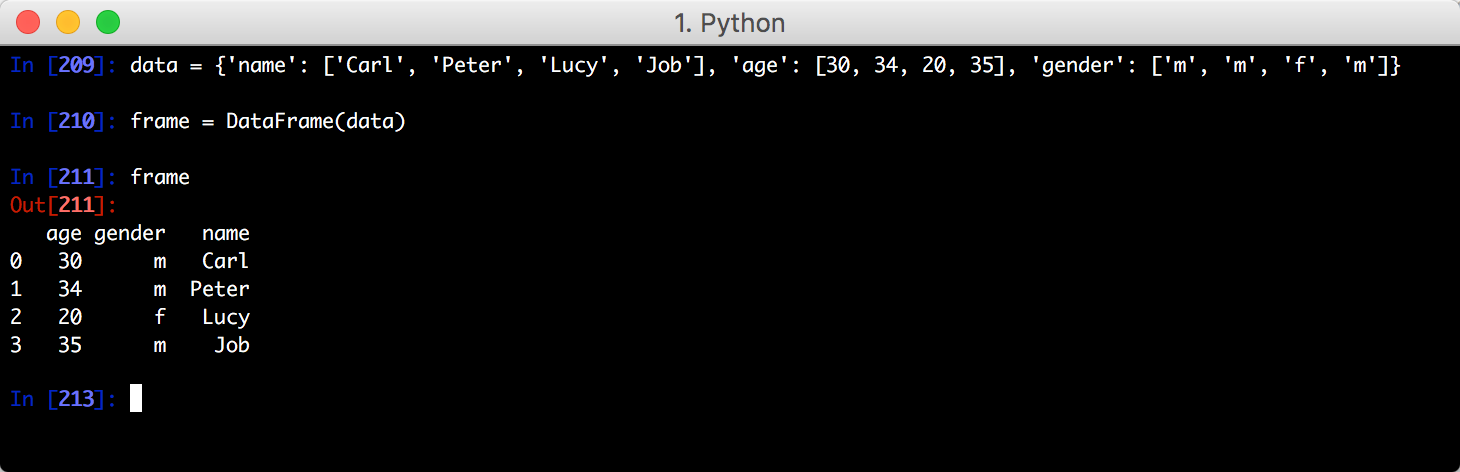
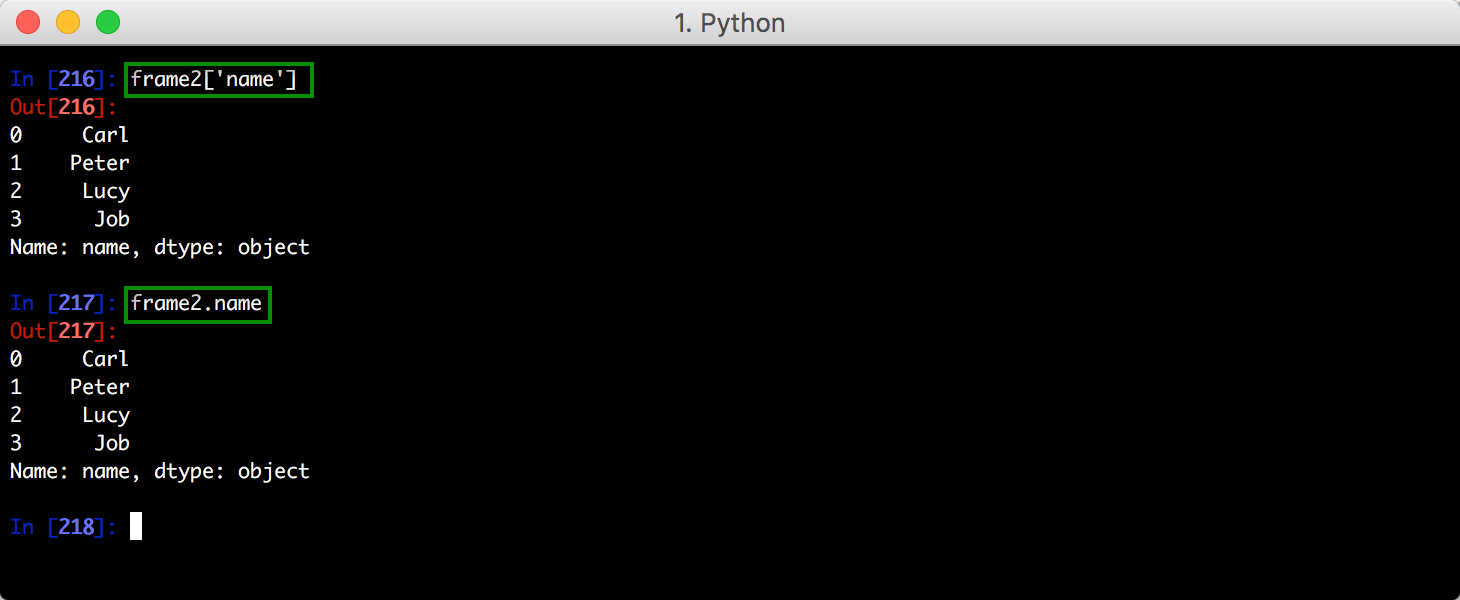
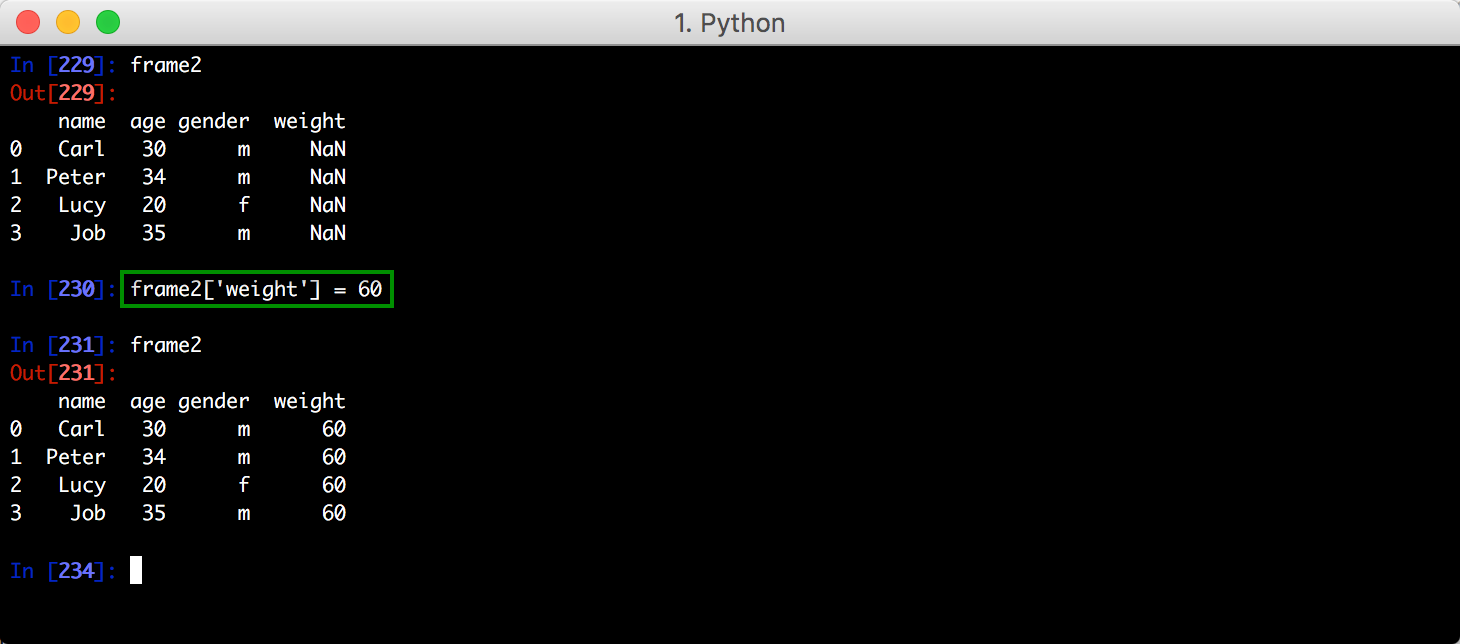
三、DataFrame



利用Python进行数据分析(7) pandas基础: Series和DataFrame的简单介绍的更多相关文章
- 利用Python进行数据分析(8) pandas基础: Series和DataFrame的基本操作
一.reindex() 方法:重新索引 针对 Series 重新索引指的是根据index参数重新进行排序. 如果传入的索引值在数据里不存在,则不会报错,而是添加缺失值的新行. 不想用缺失值,可以用 ...
- pandas基础: Series和DataFrame的简单介绍
一.pandas 是什么 pandas 是基于 NumPy 的一个 Python 数据分析包,主要目的是为了数据分析.它提供了大量高级的数据结构和对数据处理的方法. pandas 有两个主要的数据结构 ...
- 利用Python进行数据分析(12) pandas基础: 数据合并
pandas 提供了三种主要方法可以对数据进行合并: pandas.merge()方法:数据库风格的合并: pandas.concat()方法:轴向连接,即沿着一条轴将多个对象堆叠到一起: 实例方法c ...
- 利用Python进行数据分析(9) pandas基础: 汇总统计和计算
pandas 对象拥有一些常用的数学和统计方法. 例如,sum() 方法,进行列小计: sum() 方法传入 axis=1 指定为横向汇总,即行小计: idxmax() 获取最大值对应的索 ...
- 利用Python进行数据分析(11) pandas基础: 层次化索引
层次化索引 层次化索引指你能在一个数组上拥有多个索引,例如: 有点像Excel里的合并单元格对么? 根据索引选择数据子集 以外层索引的方式选择数据子集: 以内层索引的方式选择数据: 多重索引S ...
- 利用Python进行数据分析(10) pandas基础: 处理缺失数据
数据不完整在数据分析的过程中很常见. pandas使用浮点值NaN表示浮点和非浮点数组里的缺失数据. pandas使用isnull()和notnull()函数来判断缺失情况. 对于缺失数据一般处理 ...
- 利用Python进行数据分析(14) pandas基础: 数据转换
数据转换指的是对数据的过滤.清理以及其他的转换操作. 移除重复数据 DataFrame里经常会出现重复行,DataFrame提供一个duplicated()方法检测各行是否重复,另一个drop_dup ...
- 利用Python进行数据分析(15) pandas基础: 字符串操作
字符串对象方法 split()方法拆分字符串: strip()方法去掉空白符和换行符: split()结合strip()使用: "+"符号可以将多个字符串连接起来: join( ...
- 利用Python进行数据分析(13) pandas基础: 数据重塑/轴向旋转
重塑定义 重塑指的是将数据重新排列,也叫轴向旋转. DataFrame提供了两个方法: stack: 将数据的列“旋转”为行. unstack:将数据的行“旋转”为列. 例如: 处理堆叠格式 ...
随机推荐
- 神马玩意,EntityFramework Core 1.1又更新了?走,赶紧去围观
前言 哦,不搞SQL了么,当然会继续,周末会继续更新,估计写完还得几十篇,但是我会坚持把SQL更新完毕,绝不会烂尾,后续很长一段时间没更新的话,不要想我,那说明我是学习新的技能去了,那就是学习英语,本 ...
- C++中的命名空间
一,命名空间(namespace)的基本概念以及由来 1.什么是标识符: 在C++中,标识符可以是基本的变量,类,对象,结构体,函数,枚举,宏等. 2.什么是命名空间: 所谓的命名空间是指标识符的可见 ...
- XML技术之DOM4J解析器
由于DOM技术的解析,存在很多缺陷,比如内存溢出,解析速度慢等问题,所以就出现了DOM4J解析技术,DOM4J技术的出现大大改进了DOM解析技术的缺陷. 使用DOM4J技术解析XML文件的步骤? pu ...
- 在jekyll模板博客中添加网易云模块
最近使用GitHub Pages + Jekyll 搭建了个人博客,作为一名重度音乐患者,博客里面可以不配图,但是不能不配音乐啊. 遂在博客里面引入了网易云模块,这里要感谢网易云的分享机制,对开发者非 ...
- Linux主机上使用交叉编译移植u-boot到树莓派
0环境 Linux主机OS:Ubuntu14.04 64位,运行在wmware workstation 10虚拟机 树莓派版本:raspberry pi 2 B型. 树莓派OS: Debian Jes ...
- Toast显示图文界面——Android开发之路1
Toast的多种使用方法 Toast其实是一个功能特别强大的组件,不仅仅可以吐司一个文本内容,还可以吐司图片以及图文混排的界面.具体用法如下: 第一种:简单的纯文本内容的吐司: Toast.makeT ...
- Hadoop 2.x 生态系统及技术架构图
一.负责收集数据的工具:Sqoop(关系型数据导入Hadoop)Flume(日志数据导入Hadoop,支持数据源广泛)Kafka(支持数据源有限,但吞吐大) 二.负责存储数据的工具:HBaseMong ...
- MySQL:常见使用问题
内容 1.Linux 上安装 MySQL 2.单机上安装多实例 3.不知root密码情况下,修改root密码 1.Linux 上安装MySQL 安装步骤: 1)解压 tar.gz文件 -linux-g ...
- Mono 3.2.3 TCP吞吐性能测试报告
在前几天简单地测试了一下Mono 3.2.3 TCP处理的稳定性,有同学问Mono 3.2.3的TCP处理性有怎样,以下是针对Mono 3.2.3TCP在吞吐方面的性能测试.主要测试分两种场分别是连接 ...
- (转)利用libcurl和国内著名的两个物联网云端通讯的例程, ubuntu和openwrt下调试成功(四)
1. libcurl 的参考文档如下 CURLOPT_HEADERFUNCTION Pass a pointer to a function that matches the following pr ...