决策树--信息增益,信息增益比,Geni指数的理解
- 特征选择
- 决策树生成
- 决策树剪枝
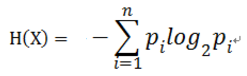
对于样本集合D来说,随机变量X是样本的类别,即,假设样本有k个类别,每个类别的概率是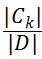 ,其中|Ck|表示类别k的样本个数,|D|表示样本总数
,其中|Ck|表示类别k的样本个数,|D|表示样本总数
则对于样本集合D来说熵(经验熵)为:
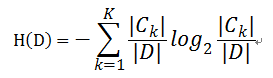
- 信息增益( ID3算法 )
定义: 以某特征划分数据集前后的熵的差值
在熵的理解那部分提到了,熵可以表示样本集合的不确定性,熵越大,样本的不确定性就越大。因此可以使用划分前后集合熵的差值来衡量使用当前特征对于样本集合D划分效果的好坏。
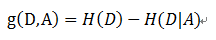
- 解决方法 : 信息增益比( C4.5算法 )
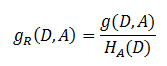
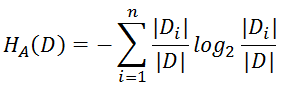
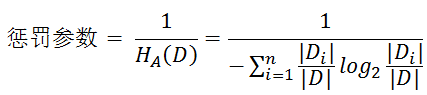
- 基尼指数( CART算法 ---分类树)
定义:基尼指数(基尼不纯度):表示在样本集合中一个随机选中的样本被分错的概率。
注意: Gini指数越小表示集合中被选中的样本被分错的概率越小,也就是说集合的纯度越高,反之,集合越不纯。
即 基尼指数(基尼不纯度)= 样本被选中的概率 * 样本被分错的概率
书中公式:
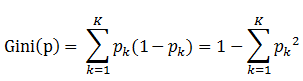
说明:
1. pk表示选中的样本属于k类别的概率,则这个样本被分错的概率是(1-pk)
2. 样本集合中有K个类别,一个随机选中的样本可以属于这k个类别中的任意一个,因而对类别就加和
3. 当为二分类是,Gini(P) = 2p(1-p)
样本集合D的Gini指数 : 假设集合中有K个类别,则:
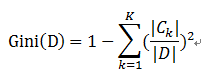
基于特征A划分样本集合D之后的基尼指数:
需要说明的是CART是个二叉树,也就是当使用某个特征划分样本集合只有两个集合:1. 等于给定的特征值 的样本集合D1 , 2 不等于给定的特征值 的样本集合D2
实际上是对拥有多个取值的特征的二值处理。
举个例子:
假设现在有特征 “学历”,此特征有三个特征取值: “本科”,“硕士”, “博士”,
当使用“学历”这个特征对样本集合D进行划分时,划分值分别有三个,因而有三种划分的可能集合,划分后的子集如下:
- 划分点: “本科”,划分后的子集合 : {本科},{硕士,博士}
- 划分点: “硕士”,划分后的子集合 : {硕士},{本科,博士}
- 划分点: “硕士”,划分后的子集合 : {博士},{本科,硕士}
对于上述的每一种划分,都可以计算出基于 划分特征= 某个特征值 将样本集合D划分为两个子集的纯度:
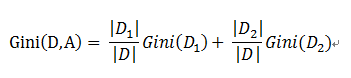
因而对于一个具有多个取值(超过2个)的特征,需要计算以每一个取值作为划分点,对样本D划分之后子集的纯度Gini(D,Ai),(其中Ai 表示特征A的可能取值)
然后从所有的可能划分的Gini(D,Ai)中找出Gini指数最小的划分,这个划分的划分点,便是使用特征A对样本集合D进行划分的最佳划分点。
决策树--信息增益,信息增益比,Geni指数的理解的更多相关文章
- python实现简单决策树(信息增益)——基于周志华的西瓜书数据
数据集如下: 色泽 根蒂 敲声 纹理 脐部 触感 好瓜 青绿 蜷缩 浊响 清晰 凹陷 硬滑 是 乌黑 蜷缩 沉闷 清晰 凹陷 硬滑 是 乌黑 蜷缩 浊响 清晰 凹陷 硬滑 是 青绿 蜷缩 沉闷 清晰 ...
- 《机器学习实战》学习笔记第三章 —— 决策树之ID3、C4.5算法
主要内容: 一.决策树模型 二.信息与熵 三.信息增益与ID3算法 四.信息增益比与C4.5算法 五.决策树的剪枝 一.决策树模型 1.所谓决策树,就是根据实例的特征对实例进行划分的树形结构.其中有两 ...
- 决策树与树集成模型(bootstrap, 决策树(信息熵,信息增益, 信息增益率, 基尼系数),回归树, Bagging, 随机森林, Boosting, Adaboost, GBDT, XGboost)
1.bootstrap 在原始数据的范围内作有放回的再抽样M个, 样本容量仍为n,原始数据中每个观察单位每次被抽到的概率相等, 为1/n , 所得样本称为Bootstrap样本.于是可得到参数θ的 ...
- [机器学习]信息&熵&信息增益
关于对信息.熵.信息增益是信息论里的概念,是对数据处理的量化,这几个概念主要是在决策树里用到的概念,因为在利用特征来分类的时候会对特征选取顺序的选择,这几个概念比较抽象,我也花了好长时间去理解(自己认 ...
- 决策树-预测隐形眼镜类型 (ID3算法,C4.5算法,CART算法,GINI指数,剪枝,随机森林)
1. 1.问题的引入 2.一个实例 3.基本概念 4.ID3 5.C4.5 6.CART 7.随机森林 2. 我们应该设计什么的算法,使得计算机对贷款申请人员的申请信息自动进行分类,以决定能否贷款? ...
- 【Machine Learning】决策树案例:基于python的商品购买能力预测系统
决策树在商品购买能力预测案例中的算法实现 作者:白宁超 2016年12月24日22:05:42 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现的深入理解.本 ...
- 决策树和基于决策树的集成方法(DT,RF,GBDT,XGBT)复习总结
摘要: 1.算法概述 2.算法推导 3.算法特性及优缺点 4.注意事项 5.实现和具体例子 内容: 1.算法概述 1.1 决策树(DT)是一种基本的分类和回归方法.在分类问题中它可以认为是if-the ...
- 决策树模型 ID3/C4.5/CART算法比较
决策树模型在监督学习中非常常见,可用于分类(二分类.多分类)和回归.虽然将多棵弱决策树的Bagging.Random Forest.Boosting等tree ensembel 模型更为常见,但是“完 ...
- 决策树和基于决策树的集成方法(DT,RF,GBDT,XGB)复习总结
摘要: 1.算法概述 2.算法推导 3.算法特性及优缺点 4.注意事项 5.实现和具体例子 内容: 1.算法概述 1.1 决策树(DT)是一种基本的分类和回归方法.在分类问题中它可以认为是if-the ...
随机推荐
- 学习github心得
Git 是 Linux 的创始人 Linus Torvalds 开发的开源和免费的版本管理系统,利用底层文件系统原理进行版本控制的工具.Git是目前为止最著名运用最好最受欢迎的分布式的配置管理工具. ...
- jQuery(五)
wrap <script> //wrap:包装 //wrapAll:整体包装 //wrapInner:内部包装 //unwrap:删除包装(删除父级,不包括body) $(function ...
- 2017BUAA软工个人项目之数独生成与求解
1.项目GitHub地址:https://github.com/ZiJiaW/Soduko (由于一开始把sudoku看成了soduko,于是名字建错了,读起来可能有点奇怪…) 2.项目PSP表格如下 ...
- CodeIgniter 2.x和3.x修改默认控制器问题解答
首先明确一点,CodeIgniter框架的2.x和3.x版本中修改默认控制器是有一点区别的 但相同的操作都是修改application/config/routes.php $route['defaul ...
- 设备 VMnet0 上的网桥当前未运行。此虚拟机无法与主机或网络中的其他计算机通信。
http://www.cnblogs.com/baihuitestsoftware/articles/4223552.html 因为试用Windows10教育版下的Docker打开过Hyper-V,虽 ...
- Windows平台下面Oracle11.2.0.1 升级Oracle11.2.0.4 的简单步骤
1. 首先查看数据库的版本: 2. ESXi 上面的虚拟机挂在 oracle11.2.0.4的 iso磁盘 3. 执行set 进行升级 4. 安装选项进行选择 升级现有的数据库 5. 注意安装位置必须 ...
- ios微信浏览器中video视频播放问题
微信ios只支持几种特定的视频格式,一般使用mp4格式的视频(腾讯官方就是用的这种视频格式)
- ubuntu 环境 celery配置全解
继续尝试没有时间弄明白的技术. celery官方文档地址:http://docs.celeryproject.org/en/stable/getting-started/introduction.ht ...
- 关于python性能相关测试cProfile库
http://blog.csdn.net/gzlaiyonghao/article/details/1483728 收藏一个大神对这个问题的介绍. 我就不多做污染了.另外还有两个 增强库可以针对cPr ...
- Axure8.0从入门到精通
1. 新建工程 菜单->File->New 2. 添加组件并编辑组件 选中左侧Libary可选择Default/Flow/Icons,找到相应的组件并移动到工作区:并在右侧选中相应的组件属 ...