论文笔记:Improving Deep Visual Representation for Person Re-identification by Global and Local Image-language Association
Improving Deep Visual Representation for Person Re-identification by Global and Local Image-language Association
2018-09-29 19:36:43
1. Introduction:
本文针对 person re-ID 的问题,提出利用 Natural language 来辅助进行特征的学习(仅在 training 阶段),最终测试时,仅利用学习到的图像 feature,进行 prob-gallery 的检索。示意图如下所示:
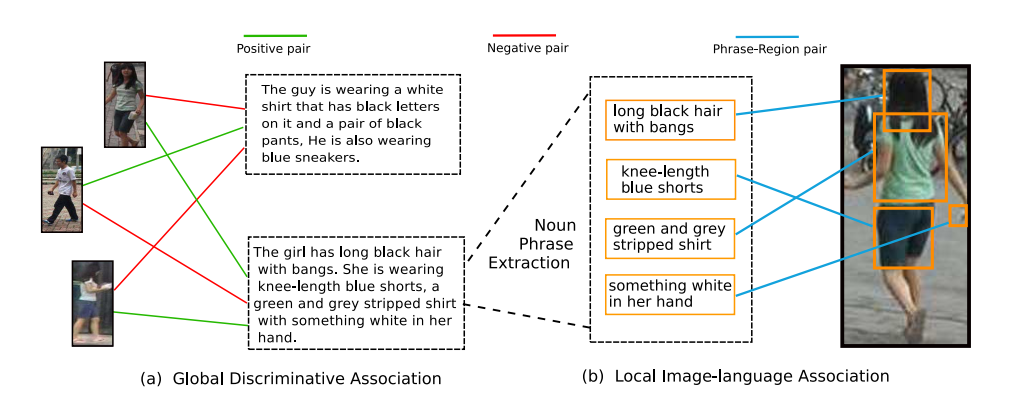
如标题所示,本文提出利用 global 的文本信息,以及 local 的单词信息来分别进行 language/phase 和 image/image patch 之间关系的学习。
在前人的工作中,也有结合其他模态的信息,来辅助提升 rgb image 的任务,如:the camera ID information, human poses, person attributes, depth maps, infrared person image。从这方面来看,学术界早已出现多模态的思路来提升某一个 task 的性能。那么,person re-ID 也不例外。本文聚焦在如何充分的利用 文本的信息来辅助提升 person re-ID 的效果。
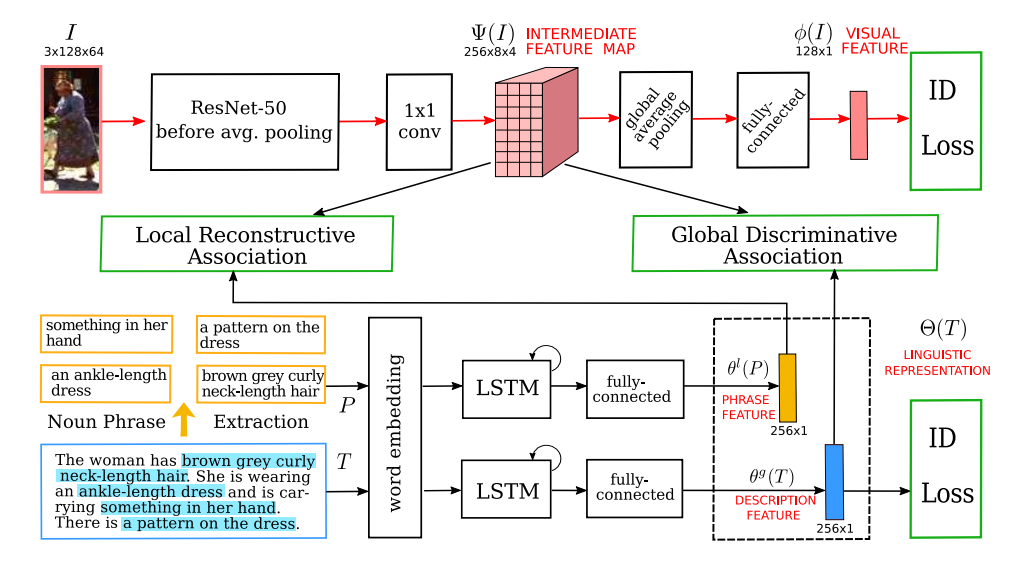
2. The Proposed Method:
(1)Visual and Linguistic Representation:
给定图像和语言描述,我们首先要进行输入的感知。
对于图像,就用 CNN 来提取 feature,得到 feature map,本文采用的是 ResNet-50,然后用 1*1 Conv 进行降维处理,得到中间的 feature map。然后用 global average pooling 进行降维后,输入到 fc layers,得到 128*1 的 visual features,此时,已经可以进行 re-ID 的训练。此处的 Loss 是 ID Loss。
对于文本,首先进行词汇的提取,然后对整个句子以及多个变长的词汇,都用 LSTM 进行编码,用最后时刻的 hidden state,表示当前文本或者词汇的特征表达。其中,词汇提取的过程,用到了 NLP 中语法树的概念,利用了 recurrsive 的思想,进行单词的有效组合,得到响应的词汇。大致过程如下所示:

作者此处也给 global 的文本信息加了一个 ID Loss,如下所示:

(2)Global Discriminative Image-language Association.
上面第一步,只是简单的对每一个模态进行了学习,但是并没有构建 image-language 之间的关联。所以,这两者之间其实可以联合的进行学习,从而实现 language 指导 visual feature 的学习。首先构成一个联合的表达: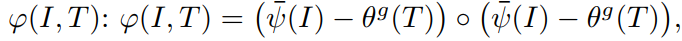 其中的圈圈代表 Hadamard product。然后通过公式(4)将该结果转换为(0,1)之间的一个 value,这里得到的其实就是网络的输出了,即:
其中的圈圈代表 Hadamard product。然后通过公式(4)将该结果转换为(0,1)之间的一个 value,这里得到的其实就是网络的输出了,即:

这里就是简单的将 positive image-language pair 设置为 label =1,negative image-language pair 设置为 label=0,通过二元交叉熵来进行该关系的学习:
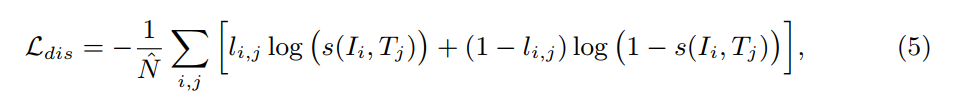
(3)Local Representation Image-language Association.
词汇信息仅仅描述了 person 的部分信息,所以,这两者之间不是对等的相关联的关系。但是,词汇仍然描述了 person image 的部分信息,所以,我们可以构建 词汇和图像特定区域的关联。
Image feature aggregation:
假设 P 是一个词汇,并且该词汇描述了图像 In 中特定的区域,我们想要预测一个向量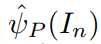 ,其反映了该区域的 feature。为了达到这个目标,我们通过加权聚合特征向量
,其反映了该区域的 feature。为了达到这个目标,我们通过加权聚合特征向量 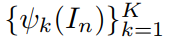 ,来得到
,来得到 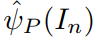 ,即:
,即: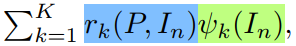 其中 rk 是 attention weight,翻译了词汇和特征向量之间的相关性,是通过一个 attention function 计算得到的。
其中 rk 是 attention weight,翻译了词汇和特征向量之间的相关性,是通过一个 attention function 计算得到的。
左侧的  ,是归一化
,是归一化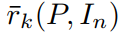 之后得到的。这个过程可以表达为:
之后得到的。这个过程可以表达为:
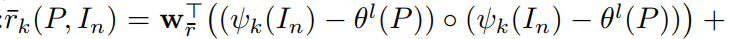
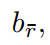
然后用 softmax 函数进行归一化,即: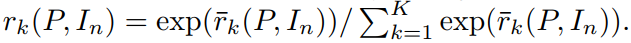
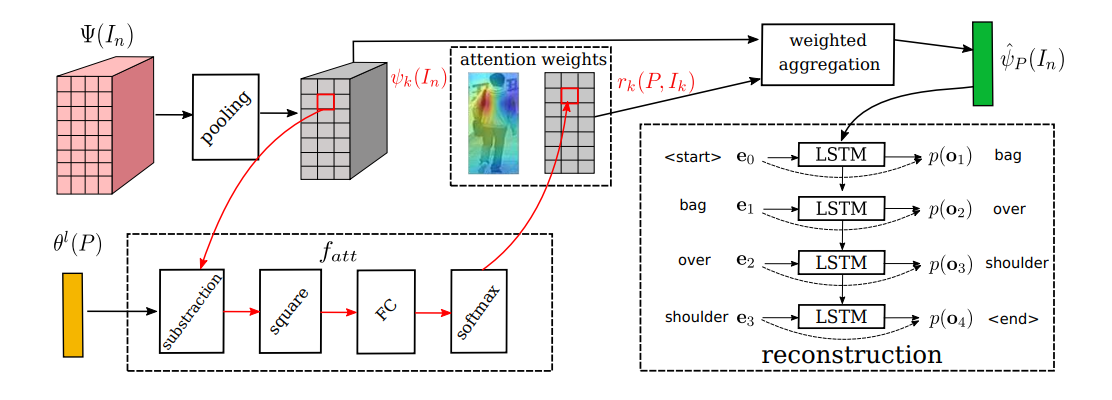
Phrase reconstruction:
为了强化 聚合后的特征图 以及 输入词汇 P 之间的一致性,我们构建了一个条件概率
以及 输入词汇 P 之间的一致性,我们构建了一个条件概率 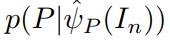 来重构 P。由于词汇并没有固定的长度,所以通常利用 chain rule,即 链式法则,来进行建模:
来重构 P。由于词汇并没有固定的长度,所以通常利用 chain rule,即 链式法则,来进行建模: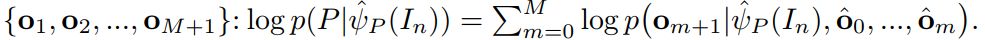 受到 Image Caption 任务的启发,我们采用 LSTM 模型来建模该概率模型。具体来说,我们首先将图像的 feature 输入到 LSTM,然后将当前单词的映射输入进去,得到下一个单词的 hidden state。下一个单词的概率是通过 hidden state $h_{m+1}$ 以及 Word embedding $e_m$。这样单词的概率分布可以表达为:
受到 Image Caption 任务的启发,我们采用 LSTM 模型来建模该概率模型。具体来说,我们首先将图像的 feature 输入到 LSTM,然后将当前单词的映射输入进去,得到下一个单词的 hidden state。下一个单词的概率是通过 hidden state $h_{m+1}$ 以及 Word embedding $e_m$。这样单词的概率分布可以表达为:
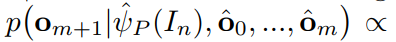
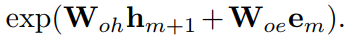
所以,重构 loss 可以表达为:
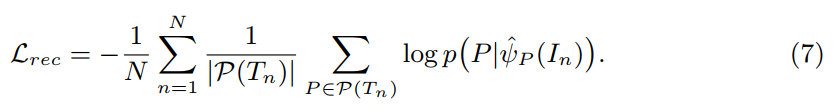
4. Training and Testing :

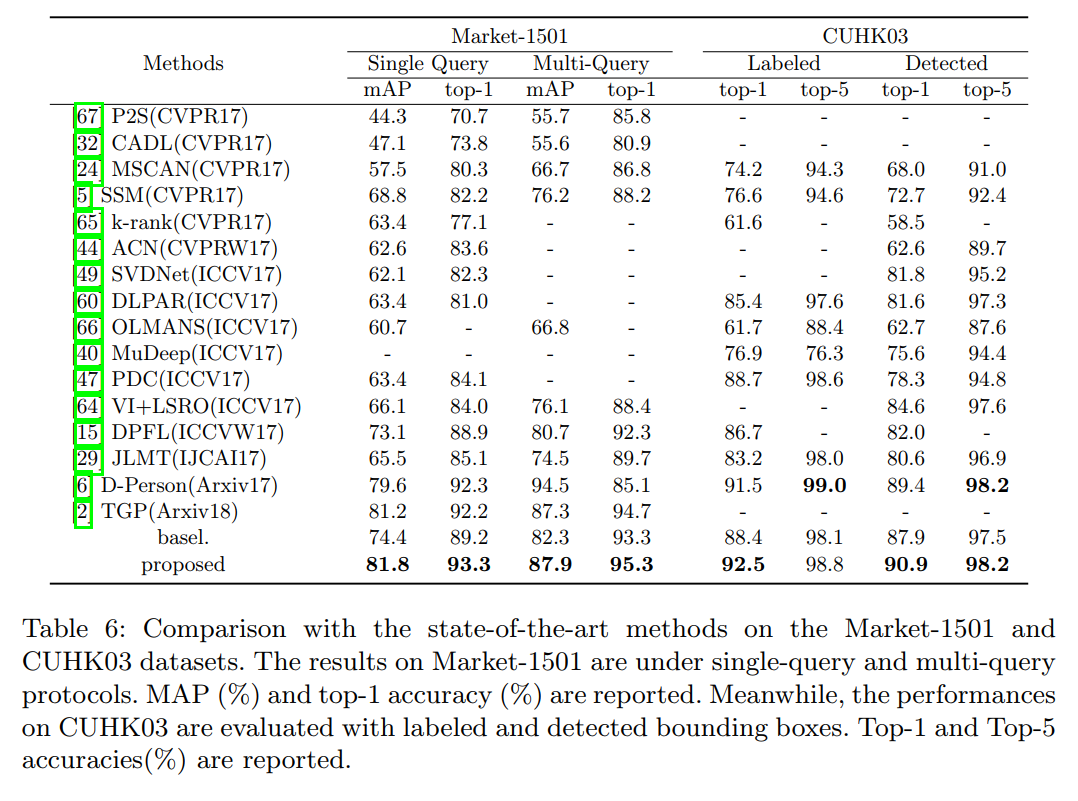
5. Experiments :



论文笔记:Improving Deep Visual Representation for Person Re-identification by Global and Local Image-language Association的更多相关文章
- 论文笔记之:Visual Tracking with Fully Convolutional Networks
论文笔记之:Visual Tracking with Fully Convolutional Networks ICCV 2015 CUHK 本文利用 FCN 来做跟踪问题,但开篇就提到并非将其看做 ...
- 论文笔记——A Deep Neural Network Compression Pipeline: Pruning, Quantization, Huffman Encoding
论文<A Deep Neural Network Compression Pipeline: Pruning, Quantization, Huffman Encoding> Prunin ...
- 论文笔记之:UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS
UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS ICLR 2 ...
- 论文笔记:Deep feature learning with relative distance comparison for person re-identification
这篇论文是要解决 person re-identification 的问题.所谓 person re-identification,指的是在不同的场景下识别同一个人(如下图所示).这里的难点是,由于不 ...
- 论文笔记:Cross-Domain Visual Matching via Generalized Similarity Measure and Feature Learning
Cross-Domain Visual Matching,即跨域视觉匹配.所谓跨域,指的是数据的分布不一样,简单点说,就是两种数据「看起来」不像.如下图中,(a)一般的正面照片和各种背景角度下拍摄的照 ...
- 论文笔记:Deep Residual Learning
之前提到,深度神经网络在训练中容易遇到梯度消失/爆炸的问题,这个问题产生的根源详见之前的读书笔记.在 Batch Normalization 中,我们将输入数据由激活函数的收敛区调整到梯度较大的区域, ...
- 论文笔记:Deep Attentive Tracking via Reciprocative Learning
Deep Attentive Tracking via Reciprocative Learning NIPS18_tracking Type:Tracking-By-Detection 本篇论文地主 ...
- 论文笔记(4)-Deep Boltzmann Machines
Deep Boltzmann Machines是hinton的学生写的,是在RBM基础上新提出的模型,首先看一下RBM与BM的区别 很明显可以看出BM是在隐含层各个节点以及输入层各个节点都是相互关联的 ...
- 论文笔记 Pose-driven Deep Convolutional Model for Person Re-identification_tianqi_2017_ICCV
1. 摘要 为解决姿态变化的问题,作者提出Pose-driven-deep convolutional model(PDC),结合了global feature跟local feature, 而loc ...
随机推荐
- nvm的安装
安装前可先卸载原来的node, npm, 安装成功后,可用nvm装node 一.用nvm-noinstall.zip安装 1.nvm-windows 下载 https://github.com/cor ...
- vue文件中引入外部js
1.在项目的入口文件中(app.js)定义remoteScript标签 Vue.component('remote-script', { render: function (createElement ...
- 关于Could not load driverClass ${jdbc.driverClassName}问题解决方案
在spring与mybatis3整合时一直遇到Could not load driverClass ${jdbc.driverClassName}报错如果将 ${jdbc.driverClassNam ...
- Python学习之旅(三十五)
Python基础知识(34):电子邮件(Ⅰ) 几乎所有的编程语言都支持发送和接收电子邮件 在使用Python收发邮件前,请先准备好至少两个电子邮件,如xxx@163.com,xxx@sina.com, ...
- iTextSharpH
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.T ...
- SpringMVC访问静态资源的三种方式
如何你的DispatcherServlet拦截 *.do这样的URL,就不存在访问不到静态资源的问题.如果你的DispatcherServlet拦截“/”,拦截了所有的请求,同时对*.js,*.jpg ...
- [No0000D1]WPF—TreeView无限极绑定集合形成树结构
1.如图所示:绑定树效果图 2.前台Xaml代码: <Window x:Class="WpfTest.MainWindow" xmlns="http://schem ...
- centos7更改网卡名称
1.编辑/etc/sysconfig/grub文件,加入net.ifnames=0 biosdevname=0 2.执行命令grub2-mkconfig -o /boot/grub2/grub.cfg ...
- Jemter 压测基础(一)——基本概念、JMeter安装使用、分布式测试、导出测试结果、编写测试报告
Jemter 压测基础(一) 1.压力测试的基本概念: 1.吞吐率(Requestspersecond) 服务器并发处理能力的量化描述,单位是reqs/s,指的是某个并发用户数下单位时间内处理的请 ...
- androidj基础:从网上下载图片
一.布局文件 设置界面,添加一个ImageView,和两个Button按钮,设置其属性及id <ImageView android:id="@+id/ImageView" a ...