Orders matters: seq2seq for set 实验
论文提出了input的顺序影响seq2seq结果 有一些输入本身是无序的怎么去处理呢
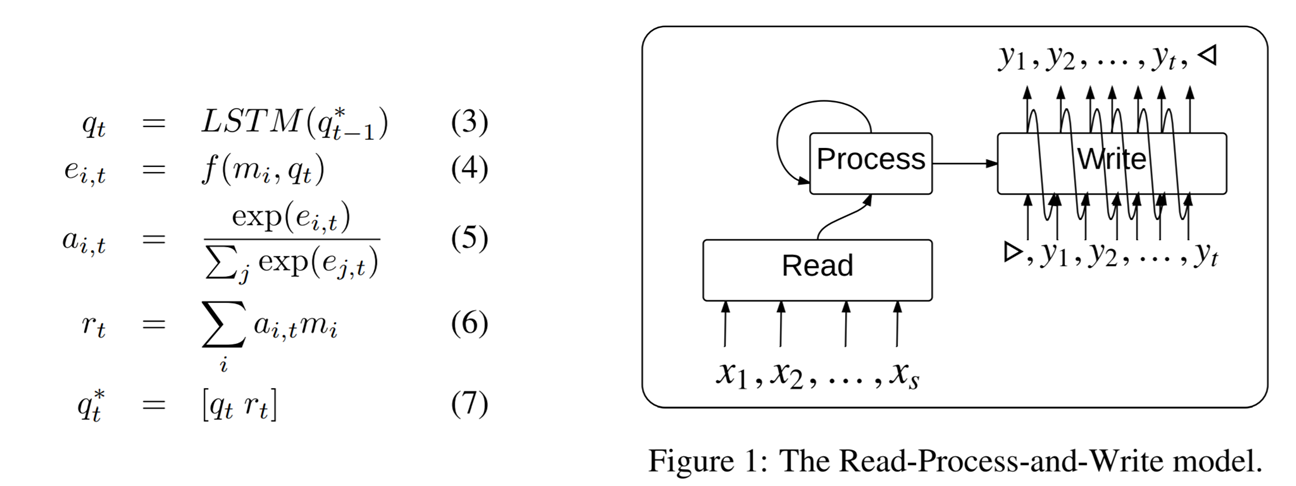
作者提出LSTM controller的方式 替代输入的LSTM encode方式
作者实验这种方式对应无序浮点数序列排序效果好于直接seq2seq

N是要排序的数的数目
P = 10 steps 表示 LSTM contorller process 10次
glimpses = 1 表示输出使用attention机制
不过实验复现这个结果不太一致
这里实验结果如下,也许实验细节和论文有出入,比如排序问题
要求输入是set 与顺序无关,那么LSTM的初始 input query是啥?
这里使用了全0向量作为input query实验
另外这个排序训练过程decoder是否使用feed prev?
这里使用feed prev 同时
使用soft attention读取输入作为下一步输入
实验结论:
- Ptr-Net 和作者提出的 set2seq方式
都是收敛有效的 - Ptr-Net 采用glimplse=1 N=15 使用tensorflow lstm训练,adgrad optimizer,learning rate 0.1初始,
运行10000次的结果
比上图所示要好很多AverageEvals:[0.37186, 0.14407] loss 是0.37186 序列完全预测准确情况的比例是14.4% 远远好于上面提到的4%的结果
- Set2seq虽然work 但是没有看出比直接ptr-net效果要好。。。
开始几步收敛确实更快
但是后续收敛远远慢于ptr net
选用Step = 20 对比 ptr net

所以是哪里出了问题
没有正确复现?
还是本来sort这个例子 lstm controller相比直接lstm序列encode就没有提升效果呢?
实验地址
https://github.com/chenghuige/hasky/tree/master/applications/set2seq
Orders matters: seq2seq for set 实验的更多相关文章
- 数据库中间件DBLE学习(二) 学习配置schema.xml
前言 一边有一个经常引诱我让我"娱乐至死"的视频,还有一个不停"鞭策"我让我快点学习的大BOSS.正是有这两种极端的爱才让我常常在自信中明白自己努力的方向.嗯, ...
- 《Do Neural Dialog Systems Use the Conversation History Effectively? An Empirical Study》
https://zhuanlan.zhihu.com/p/73723782 请复制粘贴到markdown 查看器查看! Do Neural Dialog Systems Use the Convers ...
- oracle 11g实验五——触发器的使用
实验要求: 实验五 触发器的使用 实验目的 1. 理解触发器的概念.作用及分类: 2. 掌握触发器的创建.使用: 实验内容 1. 建立表orders:用于存储订单列表信息:表order_item ...
- DL4NLP —— seq2seq+attention机制的应用:文档自动摘要(Automatic Text Summarization)
两周以前读了些文档自动摘要的论文,并针对其中两篇( [2] 和 [3] )做了presentation.下面把相关内容简单整理一下. 文本自动摘要(Automatic Text Summarizati ...
- Pytorch系列教程-使用Seq2Seq网络和注意力机制进行机器翻译
前言 本系列教程为pytorch官网文档翻译.本文对应官网地址:https://pytorch.org/tutorials/intermediate/seq2seq_translation_tutor ...
- pytorch做seq2seq注意力模型的翻译
以下是对pytorch 1.0版本 的seq2seq+注意力模型做法语--英语翻译的理解(这个代码在pytorch0.4上也可以正常跑): # -*- coding: utf-8 -*- " ...
- deeplearning.ai学习seq2seq模型
一.seq2seq架构图 seq2seq模型左边绿色的部分我们称之为encoder,左边的循环输入最终生成一个固定向量作为右侧的输入,右边紫色的部分我们称之为decoder.单看右侧这个结构跟我们之前 ...
- google nmt 实验踩坑记录
最近因为要做一个title压缩的任务,所以调研了一些text summary的方法. text summary 一般分为抽取式和生成式两种.前者一般是从原始的文本中抽取出重要的word o ...
- 时间序列深度学习:seq2seq 模型预测太阳黑子
目录 时间序列深度学习:seq2seq 模型预测太阳黑子 学习路线 商业中的时间序列深度学习 商业中应用时间序列深度学习 深度学习时间序列预测:使用 keras 预测太阳黑子 递归神经网络 设置.预处 ...
随机推荐
- redis:sentinel监控服务器
1. Sentinel工具完成监控--操作步骤 (1)把redis解压包中的sentinel.conf拷贝到redis的安装目录下: [root@192 redis]# cp /opt/redis-4 ...
- consul 文档
consul 服务发现 服务发现,用docker的时候可以使用,并且可以实现负载均衡. 因业务需要,所以留一下自己搜到比较好的资料吧 英文:https://www.consul.io/intro/ge ...
- word2vec skip-gram系列2
Word2Vec的CBOW模型和Skip-gram模型 故事先从NNLM模型说起,网络结构图如下图所示,接下来先具体阐述下这个网络, 输入是个one-hot representation的向量.比如你 ...
- mysql:Cannot proceed because system tables used by Event Scheduler were found damaged at server start
mysql 5.7.18 sqlyog访问数据库,查看表数据时,出现 Cannot proceed because system tables used by Event Scheduler were ...
- fiddler抓取手机上https数据失败,全部显示“Tunnel to......443”解决办法
与后端数据通信是前端日常开发的重要一环,在与后端接口联调的时候往往需要通过查看后端返回的数据进行调试.如果在PC端,Chrome自带的DevTools就已经足够用了,Network面板可以记录所有网络 ...
- mysql调优最大连接数
一.mysql调优 1.1 报错: Mysql: error 1040: Too many connections 1.2 原因: 1.访问量过高,MySQL服务器抗不住,这个时候就要考虑增加从服务器 ...
- 9款国内外垂直领域的在线作图工具:那些可以替代Visio的应用!【转】
http://www.csdn.net/article/2015-02-12/2823939 摘要:现在越来越多的创业公司都希望提升办公的效率,今天介绍的几款也能提升办公效率,不过它们都属于垂直领域的 ...
- http重定向到https
<?xml version="1.0" encoding="UTF-8"?> <configuration> <system.we ...
- shell中打印带有时间的日志的命令(转)
echo "`date "+%Y-%m-%d %H:%M:%S"` | [logadm -on@`date "+%Y%m%d%H%M%S"`] &qu ...
- php : 文件及文件夹操作(创建、删除、移动、复制)
Talk is cheap, show you the code : <?php /** * 操纵文件类 * */ class FileUtil { /** * 建立文件夹 * * @param ...