爬虫:输入网页之后爬取当前页面的图片和背景图片,最后打包成exe
环境:py3.6
核心库:selenium(考虑到通用性,js加载的网页)、pyinstaller
颜色显示:colors.py
colors.py
用于在命令行输出文字时,带有颜色,可有可无。
# -*- coding:utf-8 -*-# # filename: prt_cmd_color.py import ctypes, sys STD_INPUT_HANDLE = -10
STD_OUTPUT_HANDLE = -11
STD_ERROR_HANDLE = -12 # 字体颜色定义 text colors
FOREGROUND_BLUE = 0x09 # blue.
FOREGROUND_GREEN = 0x0a # green.
FOREGROUND_RED = 0x0c # red.
FOREGROUND_YELLOW = 0x0e # yellow. # 背景颜色定义 background colors
BACKGROUND_YELLOW = 0xe0 # yellow. # get handle
std_out_handle = ctypes.windll.kernel32.GetStdHandle(STD_OUTPUT_HANDLE) def set_cmd_text_color(color, handle=std_out_handle):
Bool = ctypes.windll.kernel32.SetConsoleTextAttribute(handle, color)
return Bool # reset white
def resetColor():
set_cmd_text_color(FOREGROUND_RED | FOREGROUND_GREEN | FOREGROUND_BLUE) # green
def printGreen(mess):
set_cmd_text_color(FOREGROUND_GREEN)
sys.stdout.write(mess)
resetColor() # red
def printRed(mess):
set_cmd_text_color(FOREGROUND_RED)
sys.stdout.write(mess)
resetColor() # yellow
def printYellow(mess):
set_cmd_text_color(FOREGROUND_YELLOW)
sys.stdout.write(mess + '\n')
resetColor() # white bkground and black text
def printYellowRed(mess):
set_cmd_text_color(BACKGROUND_YELLOW | FOREGROUND_RED)
sys.stdout.write(mess + '\n')
resetColor() if __name__ == '__main__':
printGreen('printGreen:Gree Color Text')
printRed('printRed:Red Color Text')
printYellow('printYellow:Yellow Color Text')
spider.py
主要在于通用性的处理
# -*- coding: utf-8 -*-
## import some modules
import os
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
from os import path
import requests
import re
from urllib.parse import urlparse, urljoin
from colors import *
d = path.dirname(__file__)
bar_length = 20
def output(List, percent, msg ,url):
hashes = '#' * int(percent / len(List) * bar_length)
spaces = ' ' * (bar_length - len(hashes))
loadingStr = str(int(100 * percent / len(List)))+ u'%'
length = len('100%')
if len(loadingStr) < length:
loadingStr += ' '*(length-len(loadingStr))
sys.stdout.write("\rPercent: [%s %s]" % (hashes + spaces, loadingStr ))
printYellow(" [%s] %s " % ( msg, url))
sys.stdout.flush()
time.sleep(2) class Spider():
'''spider class'''
def __init__(self):
self.url = 'https://www.cnblogs.com/cate/csharp/#p5'
self.checkMsg = ''
self.fileName = path.join(d, 'image/')
self.fileDirName = ''
self.chrome_options = Options()
self.chrome_options.add_argument('--headless')
self.chrome_options.add_argument('--disable-gpu')
self.driver = webdriver.Chrome(chrome_options=self.chrome_options)
self.topHostPostfix = (
'.com', '.la', '.io', '.co', '.info', '.net', '.org', '.me', '.mobi',
'.us', '.biz', '.xxx', '.ca', '.co.jp', '.com.cn', '.net.cn',
'.org.cn', '.mx', '.tv', '.ws', '.ag', '.com.ag', '.net.ag',
'.org.ag', '.am', '.asia', '.at', '.be', '.com.br', '.net.br',
'.bz', '.com.bz', '.net.bz', '.cc', '.com.co', '.net.co',
'.nom.co', '.de', '.es', '.com.es', '.nom.es', '.org.es',
'.eu', '.fm', '.fr', '.gs', '.in', '.co.in', '.firm.in', '.gen.in',
'.ind.in', '.net.in', '.org.in', '.it', '.jobs', '.jp', '.ms',
'.com.mx', '.nl', '.nu', '.co.nz', '.net.nz', '.org.nz',
'.se', '.tc', '.tk', '.tw', '.com.tw', '.idv.tw', '.org.tw',
'.hk', '.co.uk', '.me.uk', '.org.uk', '.vg', ".com.hk") def inputUrl(self):
'''input url'''
self.url = input('please input your target: ')
print('[*] url: %s' % self.url) def check(self):
'''check url'''
self.checkMsg = input('Are your sure to grab this site? [Y/N/Exit] :')
if self.checkMsg == 'Y':
self.middle = self.url.replace('http://', '')
self.middle = self.middle.replace('https://', '')
self.fileDirName = path.join(d, 'image/%s' % self.middle)
self.makeFile()
self.parse()
elif self.checkMsg == 'N':
self.inputUrl()
self.check()
elif self.checkMsg == 'Exit':
sys.exit()
else:
print('please input one of [Y/N/Exit]!!')
self.check() def makeFile(self):
'''创建文件夹函数'''
if os.path.exists(self.fileName):
pass
else:
os.makedirs(self.fileName) if os.path.exists(self.fileDirName):
pass
else:
os.makedirs(self.fileDirName) def getCssImage(self,url):
'''获取css中的image'''
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'}
try:
response = requests.get(url, headers = headers, timeout=500).text
bgCssList = re.findall("url\((.*?\))", response)
bgCssSrc = []
if len(bgCssList) > 0:
for v in bgCssList:
v = v.replace('url(', '')
v = v.replace('\\', "")
v = v.replace(')', "")
print(v)
print('-----------------------------------')
bgCssSrc.append(v)
return bgCssSrc
except:
print('connection timeout!!!') def getHostName(self, url):
'''获取url主域名'''
regx = r'[^\.]+(' + '|'.join([h.replace('.', r'\.') for h in self.topHostPostfix]) + ')$'
pattern = re.compile(regx, re.IGNORECASE)
parts = urlparse(self.url)
host = parts.netloc
m = pattern.search(host)
urlm = 'http://www.' + m.group() if m else host
return urlm def joinUrl(self, url):
'''图片url处理'''
# if url[:2] == '//':
# url = url.replace('//', '')
# url = 'http://' + url
# elif url.startswith('/'):
# ## 需要处理
# regx = r'[^\.]+(' + '|'.join([h.replace('.', r'\.') for h in self.topHostPostfix]) + ')$'
# pattern = re.compile(regx, re.IGNORECASE)
# parts = urlparse(self.url)
# host = parts.netloc
# m = pattern.search(host)
# urlm = 'http://www.' + m.group() if m else host
# url = urlm + url
# try:
# ## 处理字符串 获取 www http https
# if url[:2] == '//':
# url = url.replace('//', '')
# url = 'http://' + url
# elif url.startswith('/'):
# ## 需要处理
# regx = r'[^\.]+(' + '|'.join([h.replace('.', r'\.') for h in self.topHostPostfix]) + ')$'
# pattern = re.compile(regx, re.IGNORECASE)
# parts = urlparse(self.url)
# host = parts.netloc
# m = pattern.search(host)
# urlm = 'http://www/' + m.group() if m else host
# url = urlm + url
# else:
# try:
# url = url.split('www', 1)[1]
# url = u'http://www' + url
# except:
# try:
# url = url.split('http', 1)[1]
# url = u'http' + url
# except:
# pass
# except:
# pass
## ex1 '//example.png'
## ex2 'http://'
if url.startswith('http'):
return url
else:
return urljoin(self.url, url) def download(self, key, url):
if key == 0:
pass
else:
print('')
url = self.joinUrl(url)
try:
imgType = os.path.split(url)[1]
imgType = imgType.split('.',1)[1]
imgType = imgType.split('?',1)[0]
except:
msg = u' Error '
return msg
fileName = int(time.time())
path = self.fileDirName+ u'/'+str(fileName) + u'.' + imgType
try:
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'}
try:
response = requests.get(url, headers=headers, timeout=500).content
except:
msg = u' Error '
return msg
f = open(path, 'wb+')
try:
f.write(response.encode('utf-8'))
except:
f.write(response)
f.close()
except Exception as e:
msg = u' Error '
return msg
return u'Success' def parse(self):
'''parse html'''
self.driver.get(self.url)
time.sleep(3)
html_content = self.driver.page_source
bs = BeautifulSoup(html_content, "html.parser")
## 先获取所有的图片
imgList = bs.find_all('img')
srcList = []
if len(imgList) > 0:
for v in imgList:
srcList.append(v['src'])
print(v['src'])
print('-----------------------------------')
srcList = list(set(srcList))
print('[*] Find %s image in page',len(srcList))
## 获取当前页面style里面的背景图
bgStyleList = re.findall("url\((.*?\))", html_content)
bgSrc = []
if len(bgStyleList) > 0:
for v in bgStyleList:
v = v.replace('url(', '')
v = v.replace('\\',"")
v = v.replace(')', "")
print(v)
print('-----------------------------------')
bgSrc.append(v)
bgSrc = list(set(bgSrc))
print('[*] Find %s image in Page style', len(bgSrc))
## 获取所有的背景图
## 获取所有的css文件
cssList = re.findall('<link rel="stylesheet" href="(.*?)"',html_content)
cssImageUrls = []
if len(cssList) > 0:
cssImageUrl = []
for url in cssList:
cssImageUrl += self.getCssImage(url)
cssImageUrls = cssImageUrl
cssImageUrls = list(set(cssImageUrls))
print('[*] Find %s image in Page css', len(cssImageUrls)) ## 开始获取图片https://www.cnblogs.com/shuangzikun/
## 开始下载标签的图片
print('---------------------------------------------') if len(srcList) > 0:
print('Start Load Image -- %s' % len(srcList))
for percent,url in enumerate(srcList):
percent += 1
msg = self.download(percent, url)
output(srcList, percent, msg ,url) if len(bgSrc) >0:
print('\nStart Load Image In Style -- %s' % len(bgSrc))
for percent, url in enumerate(bgSrc):
percent += 1
msg = self.download(percent, url)
output(srcList, percent, msg, url) if len(cssImageUrls) > 0:
print('\nStart Load Image In Css -- %s' % len(cssImageUrls))
for percent, url in enumerate(cssImageUrls):
percent += 1
msg = self.download(percent, url)
output(srcList, percent, msg, url) print('\nEnd----------------------------------Exit') if __name__ == '__main__':
print(''' ____ __ __ __ __ _______ _______
/__ \\ \\_\\/_/ / / / /____ / ___ / / ___ /
/ /_/ / \\__/ / /___ / /__ / / / / / / / / /
/ ____/ / / / /___/ / / / / / /__/ / / / / /
/_/ /_/ /_/___/ /_/ /_/ \\_____/ /_/ /_/ version 3.6''')
descriptionL = ['T', 'h', 'i', 's', ' ', 'i', 's' , ' ', 'a', ' ', 's', 'p', 'i', 'd', 'e', 'r', ' ','p', 'r', 'o', 'c', 'e', 'd', 'u', 'r', 'e', ' ', '-', '-', '-',' IMGSPIDER', '\n'] for j in range(len(descriptionL)):
sys.stdout.write(descriptionL[j])
sys.stdout.flush()
time.sleep(0.1)
urlL = ['[First Step]', ' input ', 'a', ' url ' , 'as ', 'your ', 'target ~ \n'] for j in range(len(urlL)):
sys.stdout.write(urlL[j])
sys.stdout.flush()
time.sleep(0.2)
pathL = ['[Second Step]', ' check ', 'this ', 'url ~\n'] for j in range(len(pathL)):
sys.stdout.write(pathL[j])
sys.stdout.flush()
time.sleep(0.2)
## new spider
MySpider = Spider()
## input url path
MySpider.inputUrl()
# ## checkMsg
MySpider.check()
运行效果
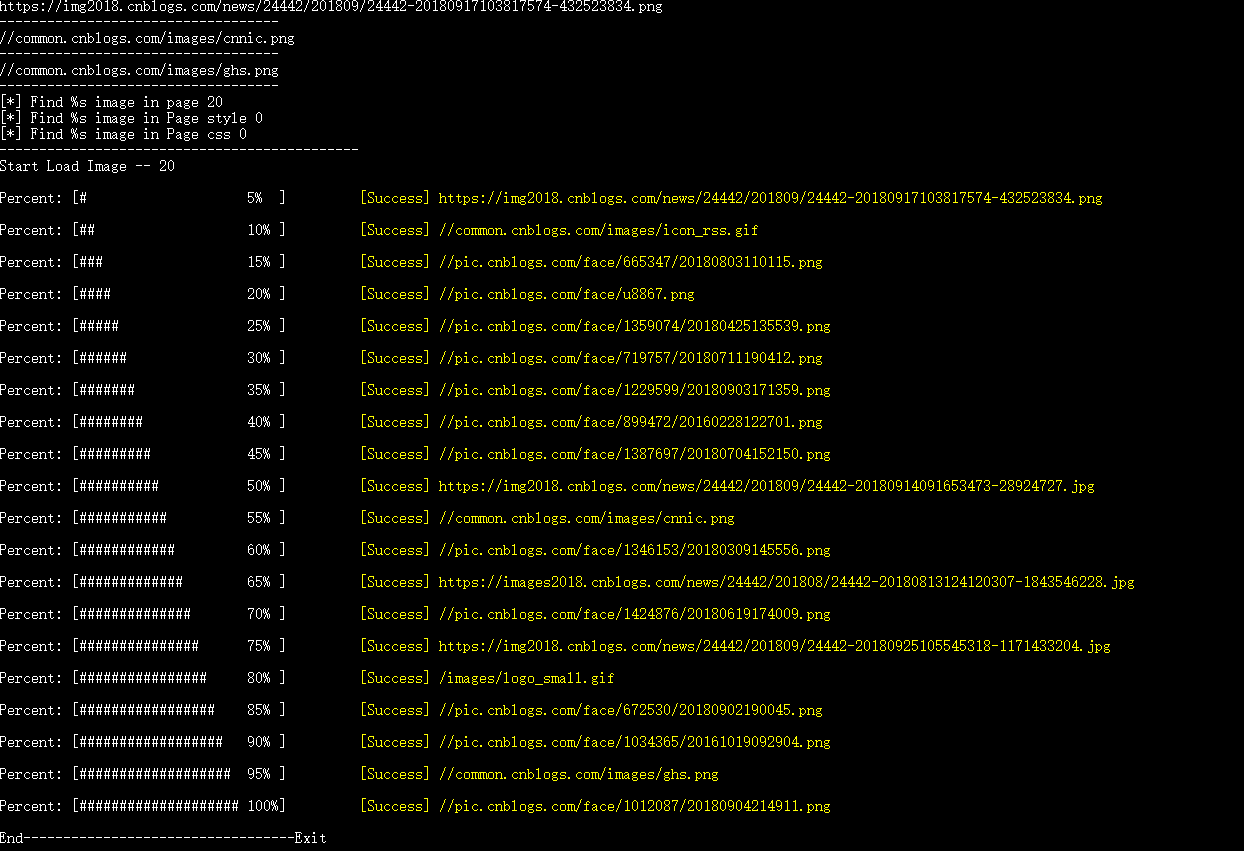
打包
使用到其它扩展
pyinstaller -f spider.py 打包成单一文件。
由于要在其它电脑上使用,需要修改下谷歌驱动的位置,把谷歌驱动放在spider.exe的同目录下。
try:
self.chrome_options.add_argument(r"user-data-dir = %s" % path.join('Chrome\Application'))
self.driver = webdriver.Chrome(path.join(d,'chromedriver.exe'),chrome_options=self.chrome_options)
except Exception as e:
print(e)
点击spider.exe,初始化没有报错即ok了。
爬虫:输入网页之后爬取当前页面的图片和背景图片,最后打包成exe的更多相关文章
- 爬虫从网页中去取的数据中包含 空格
爬虫从网页中爬取的数据中带了一个 这样的空格,使用trim()函数和replace(" ", "")去掉不了,找了一下资料发现,空格有两种一种是从键盘输入的对应 ...
- 初识python 之 爬虫:使用正则表达式爬取“糗事百科 - 文字版”网页数据
初识python 之 爬虫:使用正则表达式爬取"古诗文"网页数据 的兄弟篇. 详细代码如下: #!/user/bin env python # author:Simple-Sir ...
- Python爬虫:为什么你爬取不到网页数据
前言: 之前小编写了一篇关于爬虫为什么爬取不到数据文章(文章链接为:Python爬虫经常爬不到数据,或许你可以看一下小编的这篇文章), 但是当时小编也是胡乱编写的,其实里面有很多问题的,现在小编重新发 ...
- 零基础掌握百度地图兴趣点获取POI爬虫(python语言爬取)(代码篇)
好,现在进入高阶代码篇. 目的: 爬取昆明市中学的兴趣点POI. 关键词:中学 已有ak:9s5GSYZsWbMaFU8Ps2V2VWvDlDlqGaaO 昆明市坐标范围: 左下角:24.390894 ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- 使用for或while循环来处理处理不确定页数的网页数据爬取
本文转载自以下网站: Python For 和 While 循环爬取不确定页数的网页 https://www.makcyun.top/web_scraping_withpython16.html 需 ...
- Python 爬虫练习: 爬取百度贴吧中的图片
背景:最近开始看一些Python爬虫相关的知识,就在网上找了一些简单已与练习的一些爬虫脚本 实现功能:1,读取用户想要爬取的贴吧 2,读取用户先要爬取某个贴吧的页数范围 3,爬取每个贴吧中用户输入的页 ...
- 【nodejs 爬虫】使用 puppeteer 爬取链家房价信息
使用 puppeteer 爬取链家房价信息 目录 使用 puppeteer 爬取链家房价信息 页面结构 爬虫库 pupeteer 库 实现 打开待爬页面 遍历区级页面 方法一 方法二 遍历街道页面 遍 ...
随机推荐
- Win10系列:C#应用控件进阶1
线形 线形没有内部空间,若要呈现一条直线,需要用Line对象的Stroke和StrokeThickness 属性分别为其轮廓的颜色及轮廓的粗细赋值,若不设置这两个属性,线形将不会呈现.绘制一条线形图形 ...
- Win10系列:C#应用控件基础21
ListView控件 ListView控件的常用方式是与后台数据进行绑定,并将所绑定的数据内容与前端界面布局相结合,按照特定的顺序将数据集合以列表形式展示在界面当中,如电子邮件列表或搜索结果列表等. ...
- SharePoint REST API - 一个请求批量操作
博客地址:http://blog.csdn.net/FoxDave 本篇主要讲解如何应用$batch查询选项来批量执行REST/OData请求,它将多个操作捆绑到一个请求中,可以改进应用程序的性能 ...
- union 和 case
UNION 指令的目的是将两个 SQL 语句的结果合并起来,可以查看你要的查询结果. CASE更多的是一种判断分类,就想其他语言的case一样 1. CASE WHEN 表达式有两种形式 --简单Ca ...
- 野(wild)指针与悬空(dangling)指针
1. 什么是野指针(wild pointer)? A pointer in c which has not been initialized is known as wild pointer. 野指针 ...
- 使用vector<vector<int>>实现的一个二维数组
本文为大大维原创,最早于博客园发表,转载请注明出处!!! 1 #include<iostream> #include<vector> using namespace std; ...
- 关于dos命令行脚本编写
dos常用命令另查 开始之前先简单说明下cmd文件和bat文件的区别:在本质上两者没有区别,都是简单的文本编码方式,都可以用记事本创建.编辑和查看.两者所用的命令行代码也是共用的,只是cmd文件中允许 ...
- 支持续传功能的ASP.NET WEB API文件下载服务
先把原文地址放上来,随后翻译
- yarn依赖管理工具的使用
Yarn是Facebook发布的一款依赖管理工具,它比npm更快.更高效. 与NPM命令对照 npm install => yarn install npm install --save [pa ...
- 解决使用C/C++配置ODBC链接使用SQLConnect返回-1
VS中建立空项目使用ODBC连接时,SQLConnect函数总是返回-1,mysql和命令行连接数据库都是没问题的 retcode = SQLConnect(hdbc, (SQLCHAR*)" ...