python基础之 面向对象
1.什么是面向对象?
在大学学习c#的时候接触面向对象,知道好像有什么方法,属性,人狗大战啥的。但是都忘记了,也不知道面向对象到底是个啥!
在python中一切都是对象,linux中一切都是文件(突然想起来了) 什么是class?什么是对象?什么是属性?
人狗大战走起!!!
class People:
a =1000 #静态变量,是所有对象共同使用的值,通过类名或方法名来调用,但是静态变量一般使用类名来调用
def __init__(self, name, hp, ad, sex): #执行__ini__等价于People(),实例化这个类,主动调用。谁在实例化这个类,self这个参数就属于谁
#self指向了一块内存地址,里面存的是字典,用于接收传递进来的参数,然后自动返回给调用者
#调用__init__,自动传入了self函数,其他参数都是按照顺序传递进来的,并且添加到这个字典中
#执行__init__函数
#返给给调用者self
self.name = name #实例变量 对象属性
self.hp = hp
self.ad = ad
self.sex = sex
def fight(self, dog): #动态变量 对象方法
dog.hp -= self.ad
print("%s打了%s,%s掉了%s血" % (self.name, dog.name, dog.name, self.ad)) class Dog():
def __init__(self, name, hp, ad, sex):
self.name = name
self.hp = hp
self.ad = ad
self.sex = sex def bite(self, people):
people.hp -= self.ad
print("%s咬了%s,%s掉了%s血" % (self.name, people.name, people.name, self.ad)) jordan = People("alex", 300, 20, '男') #创建一个对象也是在创建一个实例
james = Dog('hei', 400, 10, '女')
jordan.fight(james) #对象名调用类里面的函数,并将调用者的名字和参数传递到方法里面,jordan=self
jordan.hp = 20000 #通过对象名添加属性,这个属性只是这个对象拥有
del jordan.sex #通过对象名删除属性
print(james.__dict__) #通过dict查看对象中的变量 1.class:用于定义一个具有相同方法和属性的一类事物
2.对象:根据一个模板(class)刻画出来的一个实体,具有模板里面的一切方法和属性
3.不同的对象有不同的属性,比如我们都有手,但是我的手比你的好看,这就是属性 查看类当中的所有变量:print(类名.__dict__)
查看对象当中的指定变量:
方法一:print(对象.__dict__['变量'])
方法二:print(对象.变量) ---常用 面向对象编程:把属性和动作封装到一个类型当中,就是面向对象编程(通过Dog类生成好多具有Dog类属性和方法的狗)
2.类的加载顺序
class A:
def __init__(self): #初始化函数是在对象实例化的时候执行
print('执行我了') def func(self):
print('') def func(self):
print('',A.country) country = 'China'
country = 'English' a = A() #执行初始化函数
a.func() #按照类的加载顺序来看,内存中先是开辟一个__init__的空间,然后开辟函数func的空间,看见第二个函数func的名字和第一个相同,就将第一个func的指向断掉,将func指向第二个内存地址
#然后接受两个country,所以打印出来的就是初始化函数的print(),第二个func函数,其中A.country的值是第二个country的值 注意类的加载顺序如下:
1.类内部的一个缩进的所有代码块都是在py文件从上到下解释的时候就已经被执行了
2.类中的代码永远是从上到下依次执行的

3.类的对象的命名空间
class B:
l = [0] #可变变量
def __init__(self,name): #类在实例化是被执行
self.name = name
b1 = B('科比')
b2 = B('jordan')
print(B.l)
print(b1.l)
print(b2.l)
b1.l[0] += 1 #相当于使用类B里面的静态变量可变的L,并且为L的第0个元素赋值为1,所以所有使用类B实例化的对象都会随之改变
print(b2.l[0]) #是对象b2调用类里面的可变的数据变量l,再上一步中b1已经修改过了此变量,所以结果为1
b1.l = [123] #相当于在b1的空间里面新定义了一个l,并且赋值为123,和类B没有关系,和使用类B进行实例化的对象也没有关系
print(b2.l) #所以b2.l还是为1 1.类中的内容和对象中的内容是分别存储的,是存储在两个不同的内存空间
2.类是全部加载完整个类之后,类名才指向给类开辟的内存地址
而函数不是,函数从Python解释器解释到定义函数之后,就将函数名和参数一起分配一个内存地址了,但是函数内部代码在函数被调用的时候才会分配内存地址
3.在对象的内存空间的上方有一个指向类的内存地址的指针,叫类指针,是一个变量
4.对象去类空间中找名字:通常是在自己的空间中没有这个名字的时候,通过类指针找到类的内存地址然后在类中去找变量 注意:在操作类里面的静态变量的时候,应该尽量使用类名操作而不是对象名
对于可变的数据类型,最好使用对象名来进行调用
对于不可变的数据类型最好使用类名来进行调用 结论:只要是一个[对象.名字]直接赋值,那么就是在这个对象的空间内创建了一个新的属性
只要是对一个可变的数据类型内部进行改变,那么会改变所有的通过该类进行实例化的属性 other:(重要)
1.如果有同名的方法和属性,总是后面的先执行
2.对象的命名空间在对象初始化的时候就已经开始创建
类指针:__init__初始化之间就存在了
对象的属性:在__init__初始化之后执行的
4.组合:一个类的对象是另一个类的属性(往往表达的什么里面有什么)
class Student:
def __init__(self,name,num,course):
self.name = name
self.num = num
self.course = course
class Course:
def __init__(self,name,price,period):
self.name = name
self.price = price
self.period = period
python = Course('python',20000,'6 months')
s1 = Student('kobe',10086,python) #s1中的python是使用Course实例化出来的对象,s1.course.(name|price|period) 是s1这个学生的课程具有了python对象的name,price,period属性
ju = Student('james',10010,python)
s3 = Student('jordan',10011,python)
# print(s1.name)
# print(s1.num)
# print(s1.course.period)
print(s1.__dict__) #打印这个对象的变量,可以看到course里面存放的是python对象的内存地址(一个类的对象可以传给另一个类的属性) 类和类嵌套的组合组合的好处:能够减少重复代码,最重要的是能够"松耦合"
5.面向对象的三大特性
继承(往往表达的什么是什么的关系)
继承:
继承实现了 IS-A 关系,例如 Cat 和 Animal 就是一种 IS-A 关系,因此 Cat 可以继承自 Animal,从而获得 Animal 非 private 的属性和方法。
继承应该遵循里氏替换原则,子类对象必须能够替换掉所有父类对象。
Cat 可以当做 Animal 来使用,也就是说可以使用 Animal 引用 Cat 对象。父类引用指向子类对象称为 向上转型 。
继承的好处是:
1.提高代码的利用率,减少代码的冗余
2.继承最大的好处是子类获得了父类的全部功能(属性和方法)
3.继承的另一个好处是多态
当子类和父类同时都存在run()方法的时候,通常都是子类的方法覆盖父类的方法,在代码运行的时候,总是执行子类的方法,这样就获得了另外一个好处:多态 为什么要学习继承?
单继承:可以有效的帮助我们提高代码的重用性
多继承:规范复杂的功能与功能之间的关系,多继承的工作原理能够帮助我们看源码 单继承
class A(要继承的类的名字B):------>括号必须写要继承的类的名字
#B:--->父类,基类,超类
#A:--->子类,派生类
class Animal(object): #创建一个类,python中所有的类都默认基于object,叫新式类。
def __init__(self,name,kind): #Animal类的初始化方法,会和所有缩进4个空格的内容一起写进内存
self.name = name #Animal的属性
self.kind = kind def eat(self,food): #Animal类的方法
print('%s eat %s'%(self.name,food)) class Cat(Animal): #基于Animal类创建Cat类,Cat类继承Animal
def __init__(self,name,kind,eyes_color): #Cat类中的初始化方法
# super(Cat,self).__init__(name,kind)
# super().__init__(name,kind) # 相当于执行父类的init方法,必须要将Cat类获得的值传递给Cat的父类,只要传递共同拥有的就行,剩下子类中有的属性而父类中没有的属性是子类的私有属性
# Animal.__init(self,name,kind)
self.eyes_color = eyes_color #派生属性,是Cat这个类的特有属性
Animal.__init__(self,name,kind) # 在子类和父类有同名方法的时候,默认只执行子类的方法,如果想要执行父类的方法和获得父类的属性,可以在子类的方法中再 指名道姓 的调用父类的方法 def climb(self): # 派生方法,Cat这个类的特有方法
print('%s climb tree'%self.name)
hua = Cat('小花','橘猫','蓝色')
print(hua.__dict__) #当Cat自己拥有__init__的时候,就不再调用父类的了
单继承类的继承顺序:
1.如果子类和父类都有相同的方法,默认子类的方法覆盖父类的方法:子类的对象会优先使用子类的方法
2.如果即想使用子类的方法,又想使用父类的方法,就要在子类中指名道姓的调用父类的方法,但是子类的派生类和派生方法只能自己拥有
super().方法名(arg1,arg2)
父类名.方法名(self,agr1,agr2) other:
1.python3中所有的类都是新式类,因为默认所有类都继承object类
2.python2中的类如果【类名()】扩号里面不写object,就是经典类(只有py2.x中存在),加上object就是新生类
3,也可以说父类是object的类都是新式类 多继承
多继承是python种特有的一种继承方式,虽然java,c#等都有继承,但是不支持多继承,c++支持多继承
多继承中的继承顺序
1.如果对象使用名字(方法和属性)是子类中存在的,就和单继承一样,使用子类中有的名字
如果子类中没有,就去父类中寻找,如果父类中也没有,就是报错
2.如果多个父类中都有,那么使用哪一个父类的那?
a.砖石继承问题
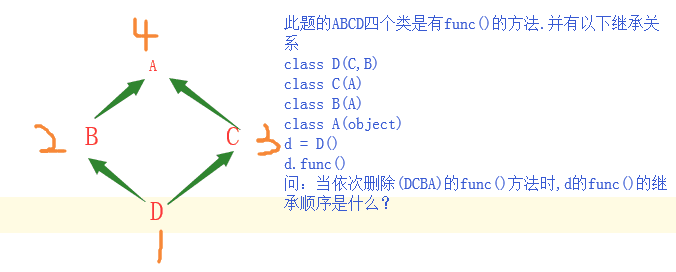
上面的1234就是多继承类的继承顺序。
首先子类D先在自己的空间内寻找func()方法,如果有的话,就使用自己的方法,如果没有的话寻找父类的func()方法
其次D类继承了两个父类B,C。在python3中多继承的继承顺序默认是用广度优先的排序算法,又因为在继承的时候C在B的前面所以先继承C
其次继承B,最后在继承A,A类中也没有的话,就去A的父类中object寻找,object也没有的话就报错。
所以继承顺序为D-->C-->B-->A--object(如没有就报错)
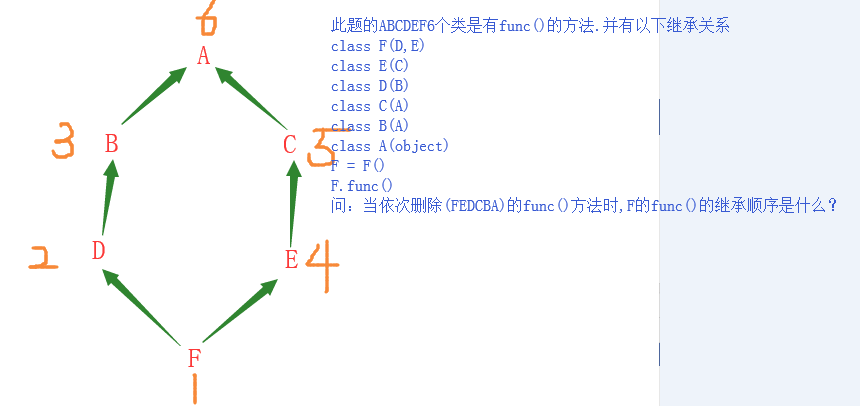
b.乌龟继承问题
上面的123456就是继承顺序
首先F类先在自己的空间内寻找func()方法,如果有,就继承自己空间内的方法,如果没有就寻找父类的空间内的func()方法
其次F类继承了D,E两个父类,由于在python3中多继承的继承顺序默认是广度优先,又因为在F继承的时候D在E前面,所以先继承D的分支
依次向下继承顺序为F-->D-->B-->E-->C-->A-->object(如果没有就报错) other:
print(B.mro()) #用来显示类的继承顺序
print(B.__bases__) #用来显示B继承了多少个类
先抽象,在继承。
应该是先从具体的东西往不具体的东西走,叫做抽象。
对象-->类-->父类
越往基类上走就越抽象
基类-->继承-->子类-->实例化-->对象 Python2.x
默认不继承object,是经典类,除非在扩号里面申明,才是新式类
多个类之间寻找继承关系的时候,遵循深度优先的算法
经典类没有super()方法和mro()方法
C3算法:
#提取第一个点
# 如果从左到右第一个类,
# 在后面的继承顺序中也是第一个,或者不再出现在后面的继承顺序中
# 那么就可以把这个点提取出来,作为继承顺序中的第一个类
https://blog.csdn.net/u011467553/article/details/81437780
注意:
1.单继承中,super()方法找的是子类的父类
2.多继承中,super()方法找的是mro的顺序,和子类父类无关
经典的累的继承顺序问题

1.Son()是在实例化一个对象,但是没有接受的变量
2.在执行Son()的时候,会先寻找__init__函数,没有的话回去寻找父类中的__init__方法
3.在执行父类中的__init__的时候会调用self.func(),但是这个self指的是类实例化的对象的
4.所以会执行Son()函数的print()方法
6.经典类和新式类的区别?
经典类:
1. 是py2.x版本才有的
2. py2.x里面的类默认不继承object,需要默认在类后面的括号里面添加(object)
3. 经典类的多继承的继承顺序使用的是深度优先的排序算法 c3算法
4.没有super()方法和mro方法
新式类:
1. 是py3.x才有的
2. py3.x默认都是继承的object类
3. 新式类的多继承的继承顺序使用的是广度优先的排序算法
4. 新式类具有super()方法
在单继承中super()寻找的时父类
在多继承中super()是根据mro排序来寻找累的顺序
5. 新式类具有mro()方法,用来查看多继承中类的继承顺序
7.type和抽象类
什么是type类型?什么是元类?
class Course:
def __init__(self,name,price):
self.name = name
self.price = price python = Course('python',20000)
print(type(python)) #type一个对象时,结果返回的总是这个对象实例化的类
print(type(123)) #返回一个整形
print(type(Course)) #返回一个type类型
print(type(int)) #返回一个type类型
print(type(str)) #返回一个type类型 注意:
1.type在type一个对象的时候,返回的是这个对象所属的类
2.type一个类的时候,类也变成了对象,所有用class创造出来的类都是type类型
3.类也是一个'对象',类是一个'类(type)'类型的对象
4.所有类的鼻祖是type类型,object也的类型也是type
5.对象是被创造出来的:被类实例化出来的
类也是被创造出来的:特殊的方法创造类
常规创造的类的特性:
1.能够被实例化
2.能有属性
3.能有方法
元类:创造出来的不同寻常的类
特殊需求一:不能实例化
特殊需求二:只能有一个实例
抽象类
from abc import ABCMeta,abstractmethod
class Payment(metaclass=ABCMeta): #抽象类,相当于是子类的模板,告诉子类必须要按照我这个类里面的来写
@abstractmethod #约束所有子类,加上这个而装饰器以后,后面所有继承我的子类必须要有该方法,否则不能实例化
def pay(self):
pass # 创建的这个pay并没有内容,
# 之所以写一个pay是为了提醒所有子类,一定要实现一个pay方法
@abstractmethod
def back(self):
pass
class Wechatpay(Payment):
def __init__(self,name,money):
self.name = name
self.money = money
def pay(self):
print('%s通过微信支付了%s元'%(self.name,self.money)) class Alipay(Payment):
def __init__(self,name,money):
self.name = name
self.money = money
def pay(self):
print('%s通过支付宝支付了%s元'%(self.name,self.money))
def back(self):
print("退款")
#归一化设计
def pay(persion): #--->实例化的一个类的对象
persion.pay()
alp = Alipay('p0st',2000000)
pay(alp) 抽象类的特点:
1.class Payment(metaclass=ABCMeta):有metclass=ABCmeta的都是抽象类
2.抽象类约束所有子类,必须要实现abstractmethod装饰的方法,给我们的代码指定规范
3.抽象类最主要的特点:不能被实例化,只是作为子类的规范
抽象类中不一定包含抽象方法,包含抽象方法的类一定是抽象类。
文档
8.多态
python中处处是多态,一切皆对象 # 鸭子类型
python当中写程序的一种特殊的情况
其他语言中 正常的我们说一个数据类型具有某个特点,通常是通过继承来实现
继承迭代器类,来证明自己本身是个迭代器
继承可哈希的类,来证明自己本事是可哈希的
但是所有的这些都不是通过继承来完成的
我们只是通过一种潜规则的约定,如果具有__iter__,__next__就是迭代器
如果具有__hash__方法就是可哈希
如果具有__len__就是可以计算长度的
这样数据类型之间的关系并不仅仅是通过继承来约束的
而是通过约定俗成的关系来确认的
多个相似的类具有相同的方法名,但是又不通过抽象类/或者继承父类的约束,这几个具有相同方法的类就是鸭子类型
# 多态
广义的多态:
一个类能表现出的多种形式
狭义的多态
在传递参数的时候,如果要传递的对象有可能是多个类的对象
我们又必须在语言中清楚的描述出到底是那一个类型的对象
我们就可以使用继承的形式,有一个父类作为这些所有可能被传递进来的对象的基类
基础类型就可以写成这个父类
于是所有子类的对象都是属于这个父类的
在python当中,因为要传递的对象的类型在定义阶段不需要明确,所以我们在python中处处都是多态
数据的类型不需要通过继承来维护统一
注意:
python中多态体现的并不明显,但是Python中处处都是多态
但是python中鸭子类型体现的明显
9.namedtuple
from collections import namedtuple
Course = namedtuple('Course',['name','price','period'])
python = Course('python',20000,'6 month')
print(python.name)
print(python.price)
print(python.period)
print(type(python)) 其中的Course相当于在创建一个类,python相当于实例化一个Course的对象
通过print(type(python))来看python的类型发现,python是Course的子类<class '__main__.Course'>
namedtuple实际上在帮助我们创建了一个类,这个类只有方法,没有属性.并且属性只能在初始化的时候写,不能修改,namedtuple是一个特别的元类
nametuple的使用场景:在我们需要描述一个只有属性并且不需要修改的时候,使用namedtuple是最好的:例如扑克牌。
站在面向对象的角度来看:namedtuple的本质就是:一个元类+元组的特性
10.pickle
在以前学习的洗后,json能处理的是较为简单的,固定的数据类型,而pickle能处理任意的python的数据类型和对象,包括类
import pickle
class Course:
def __init__(self,name,price,period):
self.name = name
self.price = price
self.period = period # python = Course('python',20000,'6 months')
# linux = Course('linux',15800,'5 months')
# import pickle
# with open('pickle_file','ab') as f:
# pickle.dump(python,f)
# pickle.dump(linux,f) import pickle
with open('pickle_file','rb') as f:
# obj1 = pickle.load(f)
# obj2 = pickle.load(f)
while True:
try:
obj = pickle.load(f)
print(obj.__dict__)
except EOFError:
break pickle可以序列化python中出现的所有的数据类型,甚至能序列化类的对象,和一些复杂的数据类型,相比于json,pickle的应用场景会更多!
11.封装
封装:
私有化的封装:私有化的方法和属性,将属性封装起来
广义上的封装:把方法和属性根据类别封装到类中
私有化:
方法\静态变量\实例变量(对象属性)都可以私有化
什么是私有化:就是只能在类的内部可见,类的外部不可见,不能访问
class Goods:
__country = 'china' #静态变量的私有化
def __init__(self,name,price):
self.name =name
# self.price =price
self.__price =price #私有的属性,将价格变成类的私有化,只能在类的内部调用
def get_price(self):
print(self.__price)
def __get_name(self): #私有方法在外部不能被调用,只能在内部被使用
print(self.name)
#print(Goods.country)
apple = Goods('苹果',5)
apple._Goods__get_name() #通过对象名来调用类的变量(类名.__dict__)里面存的变量名
print(apple.name)
print(apple.price)
apple.get_price() #调用类内部方法获得私有化属性
1. python在私有化的时候,都是从python语法角度上做的了修改,在内部定义了一个私有属性,使用print(对象__dict__)能看到对象的变量
2. 所有的私有的变化都是类的内部定义的时候完成的,都是通过self所在的类名和私有化的名字存起来---> _类名__属性名,通过print(对象__dict__)
3.注意:私有的概念,但凡在类的外面,都不能用,是不可以被继承的
私有的所有内容:实例变量(对象属性),静态属性(类变量),方法等都不能被子类继承,只能在类的内部使用
4.私有化整体的逻辑:_类名__方法名()---》来调用私有方法,也是私有方法在内存中的变量名
5.凡是在类的内部定义的私有的就都是私有的(_类名__私有变量名),但是在类的外部定义的时候就不是私有的了
关于私有化的经典面试题
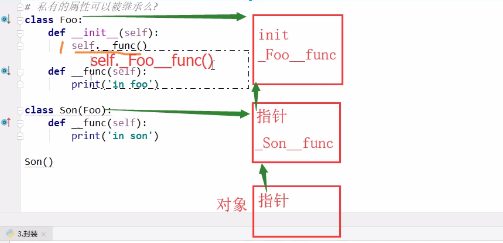
此题的结果打印的是is foo。在Son()实例化之前,会在内存中开辟两个类的内存空间和一个对象的内存空间,并且内存空间的类指针如上图所示。
在实例化Son()之后,由于此Son()没有__init__方法,所以会去父类中区寻找,找到父类中的__init__()函数之后,会执行self__fun(),但是此时
的__func是私有化函数,并且在Foo类里面的名字为_Foo_func(),但是其实例化的类中没有_Foo_func()方法,所以只再起父类中寻找,所以打印is foo
13.@property
@property 把装饰的一个方法伪装成一个属性
class Goods:
discount = 0.8 def __init__(self, name, price):
self.name = name
self.__price = price @property # 只支持obj.price的方式查看这个结果,不支持修改,也不支持删除
def price(self):
p = self.__price * self.discount
return p @price.setter
def price(self,value):
if type(value) is int or type(value) is float:
self.__price = value apple = Goods('苹果', 5)
banana = Goods('香蕉', 10)
apple.price = 16 #对应的调用的是被setter装饰的price方法
print(apple.price) #对应调用的是被property装饰的price方法
# 私有的 :通过过给__名字这样的属性或者方法加上当前所在类的前缀,把属性隐藏起来了
# 只能在本类的内部使用,不能在类的外部使用,不能被继承
# property 把一个方法伪装成属性
# property和私有的两个概念一起用
# 定义一个私有的
# 再定义一个同名共有的方法,被property装饰 # @方法名.setter
# @方法名.deleter
12.classmethod和staticmethod
classmethod是用来指定一个类的方法为类方法,没有此参数指定的类的方法为实例方法
@classmethod:修饰符对应的函数不需要实例化,不需要 self 参数,但第一个参数是需要表示类自身的cls参数,可以来调用类的属性,类的方法,实例化对象等。
class A(object): # 属性默认为类属性(可以直接被类本身调用)
num = "类属性" # 实例化方法(必须实例化类之后才能被调用,对象方法)
def func1(self): # self : 表示实例化类后的对象地址id
print("func1")
print(self) # 类方法(不需要实例化类就可以被类本身调用)
@classmethod
def func2(cls): # cls : 表示没用被实例化的类本身
print("func2")
print(cls)
print(cls.num)
cls().func1()
# 不传递默认self参数的方法(该方法也是可以直接被类调用的,但是这样做不标准)也叫普通方法,如果加上self的话,类在调用的时候必须要将类本身传递进去 A.func3(A),才不会报错,
def func4():
print("func4")
print(A.num) # 属性是可以直接用类本身调用的 # A.func1() 这样调用是会报错:因为func1()调用时需要默认传递实例化类后的地址id参数,如果不实例化类是无法调用的
A.func2()
A.func4() 类方法总结:
1.类方法是给类来用的,是类的方法,类在使用的时候会将类本身传递给类方法的第一个参数,python为我们提供了classmethod内置方法来将类中的函数定义成类方法(也可以说成将对象方法(函数)变成类方法)
2.在类调用类方法的时候不需要实例化就可以直接调用,也不需要self参数
3.虽然说类的方法可以通过对象名来调用,但是通常都是使用类名来调用,因为是类的方法
总结:
1、实例方法,该实例属于对象,该方法的第一个参数是当前实例,拥有当前类以及实例的所有特性。
2、类方法,该实例属于类,该方法的第一个参数是当前类,可以对类做一些处理,如果一个静态方法和类有关但是和实例无关,那么使用该方法。
类方法的使用场景:在使用类之前,需要使用类中的方法来进行一些计算
3、静态方法,该实例属于类,但该方法没有参数,也就是说该方法不能对类做处理,相当于全局方法
静态方法使用场景:编写类时需要采用很多不同的方式来创建实例,而我们只有一个__init__函数,此时静态方法就派上用场了
@staticmethod就是普通函数,也是静态函数
python基础之 面向对象的更多相关文章
- Python 基础 四 面向对象杂谈
Python 基础 四 面向对象杂谈 一.isinstance(obj,cls) 与issubcalss(sub,super) isinstance(obj,cls)检查是否obj是否是类 cls ...
- 自学Python之路-Python基础+模块+面向对象+函数
自学Python之路-Python基础+模块+面向对象+函数 自学Python之路[第一回]:初识Python 1.1 自学Python1.1-简介 1.2 自学Python1.2-环境的 ...
- 二十. Python基础(20)--面向对象的基础
二十. Python基础(20)--面向对象的基础 1 ● 类/对象/实例化 类:具有相同属性.和方法的一类人/事/物 对象(实例): 具体的某一个人/事/物 实例化: 用类创建对象的过程→类名(参数 ...
- python基础,函数,面向对象,模块练习
---恢复内容开始--- python基础,函数,面向对象,模块练习 1,简述python中基本数据类型中表示False的数据有哪些? # [] {} () None 0 2,位和字节的关系? # ...
- (转)Python成长之路【第九篇】:Python基础之面向对象
一.三大编程范式 正本清源一:有人说,函数式编程就是用函数编程-->错误1 编程范式即编程的方法论,标识一种编程风格 大家学习了基本的Python语法后,大家就可以写Python代码了,然后每个 ...
- Day7 - Python基础7 面向对象编程进阶
Python之路,Day7 - 面向对象编程进阶 本节内容: 面向对象高级语法部分 经典类vs新式类 静态方法.类方法.属性方法 类的特殊方法 反射 异常处理 Socket开发基础 作业:开发一个 ...
- Python基础7 面向对象编程进阶
本节内容: 面向对象高级语法部分 经典类vs新式类 静态方法.类方法.属性方法 类的特殊方法 反射 异常处理 Socket开发基础 作业:开发一个支持多用户在线的FTP程序 面向对象高级语法部分 经典 ...
- Python之路【第六篇】python基础 之面向对象(一)
一.三大编程范式 1.面向过程编程 2.函数式编程 3.面向对象编程 二.编程进化论 1.编程最开始就是无组织无结构,从简单控制流中按步写指令 2.从上述的指令中提取重复的代码块或逻辑,组织到一起(比 ...
- python基础之面向对象高级编程
面向对象基本知识: 面向对象是一种编程方式,此编程方式的实现是基于对 类 和 对象 的使用 类 是一个模板,模板中包装了多个"函数"供使用(可以讲多函数中公用的变量封装到对象中) ...
- python基础(八)面向对象的基本概念
作者:Vamei 出处:http://www.cnblogs.com/vamei 欢迎转载,也请保留这段声明.谢谢! 谢谢逆水寒龙,topmad和Liqing纠错 Python使用类(class)和对 ...
随机推荐
- SQL获取当前时间月份为两位数
--获取当前时间月份为两位数 )),) --获取当前时间上月月份为两位数 , )),)
- TensorFlow官网无法访问
相信很多搞深度学习的小伙伴最近都为访问不了 TensorFlow官网 而苦恼吧!虽然网上也给出了一些方法,但是却缺少一个很重要的步骤.接下来,我就给大家讲解一个完整的过程,大牛绕过. 1.更改Host ...
- 你可能不知道的IDEA高级调试技巧
一.条件断点 循环中经常用到这个技巧,比如:遍历1个大List的过程中,想让断点停在某个特定值. 参考上图,在断点的位置,右击断点旁边的小红点,会出来一个界面,在Condition这里填入断点条件即可 ...
- 【iCore4 双核心板_FPGA】实验十九:使用JTAT UART终端打印信息
实验指导书及源代码下载地址: 链接:https://pan.baidu.com/s/1c3mqDkW 密码:4x9h iCore4链接:
- C# 正则表达式判断是否是数字、是否含有中文、是否是数字字母组合
//判断输入是否包含中文 不管你有没有输入英文,只要包含中文,就返回 true public static bool HasChinese(string content) { //判断是不是中文 st ...
- [转]html5: postMessage解决跨域和跨页面通信的问题
[转]html5: postMessage解决跨域和跨页面通信的问题 平时做web开发的时候关于消息传递,除了客户端与服务器传值,还有几个经常会遇到的问题: 多窗口之间消息传递(newWin = wi ...
- SQL 问题记录
今天在处理SQL的时候遇到几个问题: 1.如果指定了 SELECT DISTINCT,那么 ORDER BY 子句中的项就必须出现在选择列表中 select distinct id from 收费站 ...
- ES6 扩展运算符 三点(...)
含义 扩展运算符( spread )是三个点(...).它好比 rest 参数的逆运算,将一个数组转为用逗号分隔的参数序列. console.log(...[, , ]) // 1 2 3 conso ...
- 【MySQL】随机获取数据的方法,支持大数据量
在mysql中带了随机取数据的函数,在mysql中我们会有rand()函数,很多朋友都会直接使用,如果几百条数据肯定没事,如果几万或百万时你会发现,直接使用是错误的.下面我来介绍随机取数据一些优化方法 ...
- iOS WKWebView (NSURLProtocol)拦截js、css,图片资源
项目地址github:<a href="https://github.com/LiuShuoyu/HybirdWKWebVIew/">HybirdWKWebVIew&l ...