node.js主从分布式爬虫
前言
前文介绍过用Python写爬虫,但是当任务多的时候就比较慢, 这是由于Python自带的http库urllib2发起的http请求是阻塞式的,这意味着如果采用单线程模型,那么整个进程的大部分时间都阻塞在等待服务端把数据传输过来的过程中。所以我们这次尝试用node.js去做这个爬虫。
为什么选择node.js
node.js是一款基于google的V8引擎开发javascript运行环境。在高性能的V8引擎以及事件驱动的单线程异步非阻塞运行模型的支持下,node.js实现的web服务可以在没有Nginx的http服务器做反向代理的情况下实现很高的业务并发量。
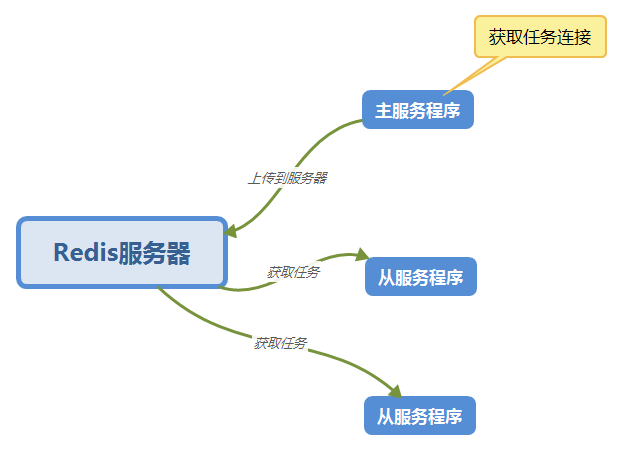
分布式爬虫设计
这次也用上次的分布式设计,使用Redis服务器来作为任务队列。
如图:
异步
node.js是基于异步的写法,有时一个函数需要上一个函数的返回值做参数,这样下来一不小心就会陷入回调地狱的陷阱中。
所以这次我们用async模块控制流程。
准备工作
- 安装node.js和Redis
- 安装request、async与Redis相关的库
代码
主函数(master.js)
"use strict"
const request = require('request')
const cheerio = require('cheerio')
const fs = require('fs')
const utils = require('./utils')
const log = utils.log
const config = require('./config')
const task_url_head = config.task_url_head
const main_url = config.main_url
const proxy_url = config.proxy_url
const redis_cache = require('./redis_cache')
const redis_client = redis_cache.client
const Task = function() {
this.id = 0
this.title = ''
this.url = ''
this.file_name = ''
this.file_url = 0
this.is_download = false
}
//总下载数
var down_cont = 0
//当前下载数
var cur_cont = 0
const taskFromBody = function(task_url, body) {
const task = new Task()
// cheerio.load 用字符串作为参数返回一个可以查询的特殊对象
// body 就是 html 内容
const e = cheerio.load(body)
// 查询对象的查询语法和 DOM API 中的 querySelector 一样
const title = e('.controlBar').find('.epi-title').text()
const file_url = e('.audioplayer').find('audio').attr('src')
const ext = file_url.substring(file_url.length-4)
const task_id = task_url.substring(task_url.length-5)
const file_name = task_id+'.'+title+ext
task.id = task_id
task.title = title
task.url = task_url
task.file_name = file_name.replace(/\//g,"-").replace(/:/g,":")
task.file_url = file_url
task.is_download = false
redis_client.set('Task:id:'+task_id,JSON.stringify(task),function (error, res) {
if (error) {
log('Task:id:'+task_id, error)
} else {
log('Task:id:'+task_id, res)
}
cur_cont = cur_cont + 1
if (down_cont == cur_cont) {
// 操作完成,关闭redis连接
redis_client.end(true);
log('已完成')
}
})
}
const taskFromUrl = function(task_url) {
request({
'url':task_url,
'proxy':proxy_url,
},
function(error, response, body) {
// 回调函数的三个参数分别是 错误, 响应, 响应数据
// 检查请求是否成功, statusCode 200 是成功的代码
if (error === null && response.statusCode == 200) {
taskFromBody(task_url, body)
} else {
log('*** ERROR 请求失败 ', error)
}
})
}
const parseLink = function(div) {
let e = cheerio.load(div)
let href = e('a').attr('href')
return href
}
const dataFromUrl = function(url) {
// request 从一个 url 下载数据并调用回调函数
request({
'url' : url,
'proxy' : proxy_url,
},
function(error, response, body) {
// 回调函数的三个参数分别是 错误, 响应, 响应数据
// 检查请求是否成功, statusCode 200 是成功的代码
if (error === null && response.statusCode == 200) {
// cheerio.load 用字符串作为参数返回一个可以查询的特殊对象
// body 就是 html 内容
const e = cheerio.load(body)
// 查询对象的查询语法和 DOM API 中的 querySelector 一样
const itmeDivs = e('.epiItem.video')
for(let i = 0; i < itmeDivs.length; i++) {
let element = itmeDivs[i]
// 获取 div 的元素并且用 itmeFromDiv 解析
// 然后加入 link_list 数组中
const div = e(element).html()
// log(div)
const url_body = parseLink(div)
const task_url = task_url_head+url_body
down_cont = itmeDivs.length
taskFromUrl(task_url)
// redis_client.set('Task:id:'+task_id+':url', task_link, )
}
// 操作完成,关闭redis连接
// redis_client.end(true)
log('*** success ***')
} else {
log('*** ERROR 请求失败 ', error)
}
})
}
const __main = function() {
// 这是主函数
const url = main_url
dataFromUrl(url)
}
__main()
从函数(salver.js)
"use strict"
const http = require("http")
const fs = require("fs")
const path = require("path")
const redis = require('redis')
const async = require('async')
const utils = require('./utils')
const log = utils.log
const config = require('./config')
const save_dir_path = config.save_dir_path
const redis_cache = require('./redis_cache')
const redis_client = redis_cache.client
//总下载数
var down_cont = 0
//当前下载数
var cur_cont = 0
const getHttpReqCallback = function(fileUrl, dirName, fileName, downCallback) {
log('getHttpReqCallback fileName ', fileName)
var callback = function (res) {
log("request: " + fileUrl + " return status: " + res.statusCode)
if (res.statusCode != 200) {
startDownloadTask(fileUrl, dirName, fileName, downCallback)
return
}
var contentLength = parseInt(res.headers['content-length'])
var fileBuff = []
res.on('data', function (chunk) {
var buffer = new Buffer(chunk)
fileBuff.push(buffer)
})
res.on('end', function () {
log("end downloading " + fileUrl)
if (isNaN(contentLength)) {
log(fileUrl + " content length error")
return
}
var totalBuff = Buffer.concat(fileBuff)
log("totalBuff.length = " + totalBuff.length + " " + "contentLength = " + contentLength)
if (totalBuff.length < contentLength) {
log(fileUrl + " download error, try again")
startDownloadTask(fileUrl, dirName, fileName, downCallback)
return
}
fs.appendFile(dirName + "/" + fileName, totalBuff, function (err) {
if (err){
throw err;
}else{
log('download success')
downCallback()
}
})
})
}
return callback
}
var startDownloadTask = function (fileUrl, dirName, fileName, downCallback) {
log("start downloading " + fileUrl)
var option = {
host : '127.0.0.1',
port : '8087',
method:'get',//这里是发送的方法
path : fileUrl,
headers:{
'Accept-Language':'zh-CN,zh;q=0.8',
'Host':'maps.googleapis.com'
}
}
var req = http.request(option, getHttpReqCallback(fileUrl, dirName, fileName, downCallback))
req.on('error', function (e) {
log("request " + fileUrl + " error, try again")
startDownloadTask(fileUrl, dirName, fileName, downCallback)
})
req.end()
}
const beginTask = function(task_key, callback) {
log('beginTask', task_key)
redis_client.get(task_key,function (err,v){
let task = JSON.parse(v)
// log('task', task)
let file_url = task.file_url
let dir_path = save_dir_path
let file_name = task.file_name
if (task.is_download === false) {
startDownloadTask(file_url, dir_path, file_name,function(){
task.is_download = true
redis_client.set(task_key, JSON.stringify(task), function (error, res) {
log('update redis success', task_key)
// cur_cont = cur_cont + 1
// if(cur_cont == down_cont){
// redis_client.end(true)
// }
callback(null,"successful !");
})
})
}else{
callback(null,"successful !");
}
})
}
const mainTask = function() {
redis_client.keys('Task:id:[0-9]*',function (err,v){
// log(v.sort())
let task_keys = v.sort()
down_cont = task_keys.length
log('down_cont', down_cont)
//控制异步
async.mapLimit(task_keys, 2, function(task_key,callback){
beginTask(task_key, callback)
},function(err,result){
if(err){
log(err);
}else{
// log(result); //会输出多个“successful”字符串的数组
log("all down!");
redis_client.end(true)
}
});
})
}
const initDownFile = function() {
fs.readdir(save_dir_path, function(err, files){
if (err) {
return console.error(err)
}
let file_list = []
files.forEach( function (file){
file_list.push(file.substring(0, 5))
})
// log(file_list)
redis_client.keys('Task:id:[0-9]*',function (err,v){
let task_keys = v
// log(task_keys)
let unfinish_len = task_keys.filter((item)=>file_list.includes(item.substring(item.length - 5)) == false).length
let cur_unfinish_lent = 0
task_keys.forEach(function (task_key){
let task_id = task_key.substring(task_key.length - 5)
if (file_list.includes(task_id) == false) {
// log(task_key)
redis_client.get(task_key,function (err,v){
let task = JSON.parse(v)
task.is_download = false
// log(task)
// log(task_key)
redis_client.set(task_key, JSON.stringify(task), function (error, res) {
cur_unfinish_lent++
// log('cur_unfinish_lent', cur_unfinish_lent)
if (cur_unfinish_lent == unfinish_len) {
redis_client.end(true)
log('init finish')
}
})
})
}
})
})
})
}
const __main = function() {
// 这是主函数
// initDownFile()
mainTask()
}
__main()
完整代码的地址
https://github.com/zhourunliang/nodejs_crawler
node.js主从分布式爬虫的更多相关文章
- 基于Node.js的强大爬虫 能直接发布抓取的文章哦
基于Node.js的强大爬虫 能直接发布抓取的文章哦 基于Node.js的强大爬虫能直接发布抓取的文章哦!本爬虫源码基于WTFPL协议,感兴趣的小伙伴们可以参考一下 一.环境配置 1)搞一台服务器,什 ...
- Node.js 网页瘸腿爬虫初体验
延续上一篇,想把自己博客的文档标题利用Node.js的request全提取出来,于是有了下面的初哥爬虫,水平有限,这只爬虫目前还有点瘸腿,请看官你指正了. // 内置http模块,提供了http服务器 ...
- Node.js大众点评爬虫
大众点评上有很多美食餐馆的信息,正好可以拿来练练手Node.js. 1. API分析 大众点评开放了查询商家信息的API,这里给出了城市与cityid之间的对应关系,链接http://m.api.di ...
- 使用node.js制作简易爬虫
最近看了些node.js方面的知识,就像拿它来做些什么.因为自己喜欢摄影,经常上蜂鸟网,所以寻思了一下,干脆做个简单的爬虫来扒论坛的帖子. 直接上代码吧. var sys = require(&quo ...
- node.js 89行爬虫爬取智联招聘信息
写在前面的话, .......写个P,直接上效果图.附上源码地址 github/lonhon ok,正文开始,先列出用到的和require的东西: node.js,这个是必须的 request,然发 ...
- 使用Node.js搭建数据爬虫crawler
0. 通用爬虫框架包括: (1) 将爬取url加入队列,并获取指定url的前端资源(crawler爬虫框架主要使用Crawler类进行抓取网页) (2)解析前端资源,获取指定所需字段的值,即获取有价值 ...
- 用Node.js写爬虫,撸羞羞的图片
说到爬虫,很多人都认为是很高大上的东西.哇塞,是不是可以爬妹纸图啊,是不是可以爬小片片啊.答案就是对的.爬虫可以完成这些东西的操作.但是,作为一个正直的程序员,我们要在法律允许范围内用爬虫来为我们服务 ...
- Node.js 使用爬虫批量下载网络图片到本地
图片网站往往广告众多,用Node.js写个爬虫下载图片,代码不长,省事不少,比手动一张张保存简直是天与地的区别.以前用Java也做过远程图片下载,但Node.js的下载速度更让人咂舌,这也是非阻塞式变 ...
- Node.js 网页爬虫再进阶,cheerio助力
任务还是读取博文标题. 读取app2.js // 内置http模块,提供了http服务器和客户端功能 var http=require("http"); // cheerio模块, ...
随机推荐
- 使用MS的ScriptDom来拆解TSQL脚本
此处提供9.1.40413.0版本的DLL一共4个:Microsoft.Data.Schema.dll.Microsoft.Data.Schema.ScriptDom.dll.Microsoft.Da ...
- python第一课——关于python的一些概念
day01(上午): 1.学习方法(建议): 1).不要依赖于我的视频,绝对不要晚上将视频全部在过一遍 2).上课不要记笔记,而且不要用纸质的笔记本去整理笔记 3).不要只看不敲,代码方面我们需要做到 ...
- 来自苹果的编程语言——Swift简单介绍【整理】
2014年06月03日凌晨,Apple刚刚公布了Swift编程语言,本文从其公布的书籍<The Swift Programming Language>中摘录和提取而成.希望对各位的iOS& ...
- MySQL - FEDERATED引擎实现跨服务器查询
1. MySQL插件的安装与卸载 # 查看插件信息 mysql> show plugins; mysql> select plugin_name,plugin_status,plugin_ ...
- Docker实战(七)之为镜像添加SSH服务
1.基于commit命令创建 Docker提供了docker commit命令,支持用户提交自己对制定容器的修改,并生成新的镜像.命令格式为docker commit CONTAINER [REPOS ...
- springboot整合mybatis将sql打印到日志
在前台请求数据的时候,sql语句一直都是打印到控制台的,有一个想法就是想让它打印到日志里,该如何做呢? 见下面的mybatis配置文件: <?xml version="1.0" ...
- POJ3268(Dijkstra_邻接矩阵)
https://vjudge.net/problem/POJ-3268 题目大意: n个农场的n头奶牛将前往x农场,要选择一条来回时间最短的路径. (一头牛的返回路线可能不同于她最初去派对的路线,因为 ...
- [Luogu P1120]小木棍·加强版
#\(\mathcal{Description}\) 乔治有一些同样长的小木棍,他把这些木棍随意砍成几段,直到每段的长都不超过 \(50\) . 现在,他想把小木棍拼接成原来的样子,但是却忘记了自己开 ...
- B. Sleepy Game
http://codeforces.com/problemset/problem/936/B Petya and Vasya arranged a game. The game runs by the ...
- 学习JavaWeb aop两种配置方式
aop aop:面向切面编程,它可以解决重复代码. aop有两种方式: 一..xml方式 1.在springmvc-servlet.xml中配置aop,应用bean文件: <!--aop配置-- ...