RabbitMQ入门:工作队列(Work Queue)
在上一篇博客《RabbitMQ入门:Hello RabbitMQ 代码实例》中,我们通过指定的队列发送和接收消息,代码还算是比较简单的。
假设有这一些比较耗时的任务,按照上一次的那种方式,我们要一直等前面的耗时任务完成了之后才能接着处理后面耗时的任务,那要等多久才能处理完?别担心,我们今天的主角--工作队列就可以解决该问题。我们将围绕下面这个索引展开:
- 什么是工作队列
- 代码准备
- 循环分发
- 消息确认
- 公平分发
- 消息持久化
废话少说,直接展开。
一、什么是工作队列
工作队列--用来将耗时的任务分发给多个消费者(工作者),主要解决这样的问题:处理资源密集型任务,并且还要等他完成。有了工作队列,我们就可以将具体的工作放到后面去做,将工作封装为一个消息,发送到队列中,一个工作进程就可以取出消息并完成工作。如果启动了多个工作进程,那么工作就可以在多个进程间共享。
二、代码准备
- 生产者类:NewTask.java
public class NewTask {
//队列名称
public static final String QUEUE_NAME = "TASK_QUEUE";
//队列是否需要持久化
public static final boolean DURABLE = false; //需要发送的消息列表
public static final String[] msgs = {"task 1", "task 2", "task 3", "task 4", "task 5", "task 6"}; public static void main(String[] args) {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
Connection connection = null;
Channel channel = null; try {
// 1.connection & channel
connection = factory.newConnection();
channel = connection.createChannel(); // 2.queue
channel.queueDeclare(QUEUE_NAME, DURABLE, false, false, null); // 3.publish msg
for (int i = 0; i < msgs.length; i++) {
channel.basicPublish("", QUEUE_NAME, null, msgs[i].getBytes());
System.out.println("** new task ****:" + msgs[i]);
}
} catch (IOException e) {
e.printStackTrace();
} catch (TimeoutException e) {
e.printStackTrace();
} finally {
if (channel != null) {
try {
channel.close();
} catch (IOException e) {
e.printStackTrace();
} catch (TimeoutException e) {
e.printStackTrace();
}
} if (connection != null) {
try {
connection.close();
} catch (IOException e) {
e.printStackTrace();
}
} } }
} - 消费者类:Work.java
public class Work { public static void main(String[] args) {
System.out.println("*** Work ***");
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost"); try {
//1.connection & channel
final Channel channel = factory.newConnection().createChannel(); //2.queue
channel.queueDeclare(NewTask.QUEUE_NAME, NewTask.DURABLE, false, false, null); //3. consumer instance
Consumer consumer = new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope, BasicProperties properties,
byte[] body) throws IOException {
String msg = new String(body, "UTF-8");
//deal task
doWork(msg); }
}; //4.do consumer
boolean autoAck = true;
channel.basicConsume(NewTask.QUEUE_NAME, autoAck, consumer);
} catch (IOException e) {
e.printStackTrace();
} catch (TimeoutException e) {
e.printStackTrace();
}
} private static void doWork(String msg) {
try {
System.out.println("**** deal task begin :" + msg); //假装task比较耗时,通过sleep()来模拟需要消耗的时间
if ("sleep".equals(msg)) {
Thread.sleep(1000 * 60);
} else {
Thread.sleep(1000);
} System.out.println("**** deal task finish :" + msg);
} catch (InterruptedException e) {
e.printStackTrace();
}
} } - 再来一个消费者类:Work2.java,代码同Work.java一模一样。
三、循环分发
我们先启动Work和Work2,然后启动NewTask,运行结果如下:
NewTask运行结果:
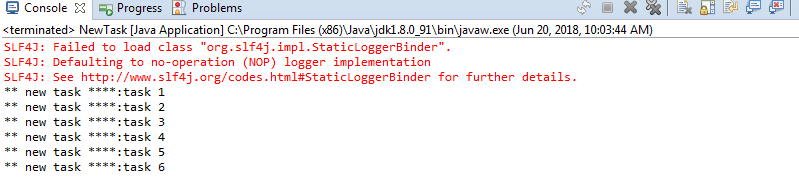
Work运行结果:
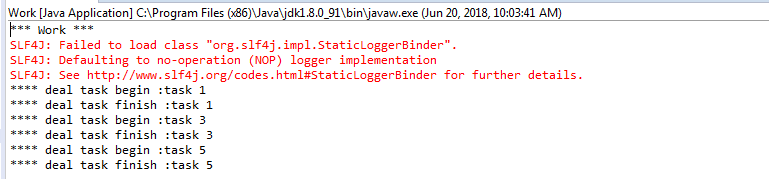
Work2运行结果:
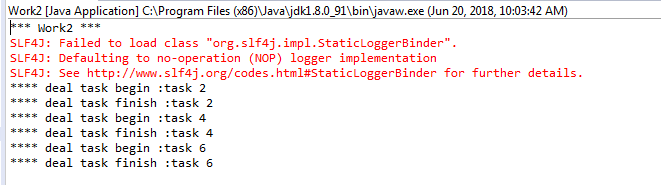
我们发现,消息生产者发送了6条消息,消费者work和work2分别分到了3个消息,而且是循环轮流分发到的,这种分发的方式就是循环分发。
四、消息确认
假如我们在发送的消息里面添加“sleep"
//需要发送的消息列表
public static final String[] msgs = {"sleep", "task 1", "task 2", "task 3", "task 4", "task 5", "task 6"};
根据代码中的实现,这个sleep要耗时1分钟,万一在这1分钟之内,工作进程崩溃了或者被kill了,会发生什么情况呢?根据上面的代码:
//4.do consumer
boolean autoAck = true;
channel.basicConsume(NewTask.QUEUE_NAME, autoAck, consumer);
自动确认为true,每次RabbitMQ向消费者发送消息之后,会自动发确认消息(我工作你放心,不会有问题),这个时候消息会立即从内存中删除。如果工作者挂了,那将会丢失它正在处理和未处理的所有工作,而且这些工作还不能再交由其他工作者处理,这种丢失属于客户端丢失。
我们来验证下,和刚才的步骤一样执行程序:
1.NewTask的控制台打印结果:
** new task ****:sleep
** new task ****:task 1
** new task ****:task 2
** new task ****:task 3
** new task ****:task 4
** new task ****:task 5
** new task ****:task 6 2.Work的控制台打印结果:
**** deal task begin :sleep 3.Work2的控制台打印结果:
**** deal task begin :task 1
**** deal task finish :task 1
**** deal task begin :task 3
**** deal task finish :task 3
**** deal task begin :task 5
**** deal task finish :task 5
根据上面的内容,消息生产者发送了7条消息, work2消费了1、3、5 三条,那剩下的sleep、2、4、6 这四条消息肯定是work来处理,只是sleep耗时一分钟 ,时间差后面的还没来得及处理,这个时候我们kill掉work,去看下RabbitMQ 管理页面,没有未处理的消息,消息随着work被kill也跟着丢失了。

是不是很可怕?
为了应对这种情况,RabbitMQ支持消息确认。消费者处理完消息之后,会发送一个确认消息告诉RabbitMQ,消息处理完了,你可以删掉它了。
代码修改(Work.java和Work2.java同步修改):1.将自动确认改为false,2.消息处理之后再通过channel.basicAck进行消息确认
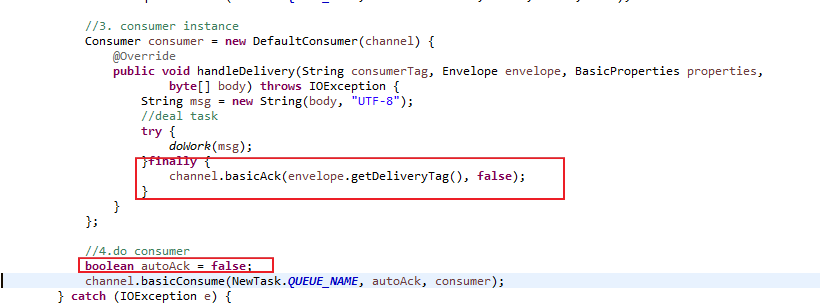
修改完后,执行程序:
1.NewTask的控制台打印结果:
** new task ****:sleep
** new task ****:task 1
** new task ****:task 2
** new task ****:task 3
** new task ****:task 4
** new task ****:task 5
** new task ****:task 6 2.Work的控制台打印结果:
**** deal task begin :sleep 3.Work2的控制台打印结果:
**** deal task begin :task 1
**** deal task finish :task 1
**** deal task begin :task 3
**** deal task finish :task 3
**** deal task begin :task 5
**** deal task finish :task 5
然后kill掉work,去看RabbitMQ管理页面,会发现有4条未确认:

再去看下work2的控制台,work2将work未处理完和未来得及处理的消息都给处理了:
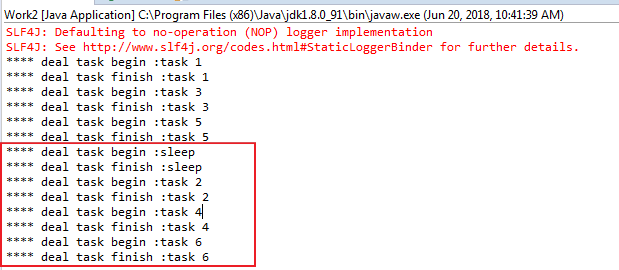
等work2处理完后,你再去看RabbitMQ管理页面,会发现页面的消息数值也都变成0 了。
五、公平分发
按照上面那种循环分发的方式,每个消费者会分到相同数量的任务,这样会有一个问题:假如有一些task非常耗时,之前的任务还没有完成,后面又来了那么多任务,来不及处理,那咋办? 有的消费者忙的不可开交,有的消费者却很快处理完事情然后无所事事浪费资源,那咋整?答案就是:公平分发。 怎么实现呢?
发生上述问题的原因就是RabbitMQ收到消息后就立即分发出去,而没有确认各个工作者未返回确认的消息数量。因此我们可以使用basicQos方法,并将参数prefetchCount设为1,告诉RabbitMQ 我每次值处理一条消息,你要等我处理完了再分给我下一个。这样RabbitMQ就不会轮流分发了,而是寻找空闲的工作者进行分发。
代码修改(work和Work2同步修改):

执行代码:
1.NewTask的控制台打印结果:
** new task ****:sleep
** new task ****:task 1
** new task ****:task 2
** new task ****:task 3
** new task ****:task 4
** new task ****:task 5
** new task ****:task 6 2.Work的控制台打印结果:
**** deal task begin :sleep
**** deal task finish :sleep 3.Work2的控制台打印结果:
**** deal task begin :task 1
**** deal task finish :task 1
**** deal task begin :task 2
**** deal task finish :task 2
**** deal task begin :task 3
**** deal task finish :task 3
**** deal task begin :task 4
**** deal task finish :task 4
**** deal task begin :task 5
**** deal task finish :task 5
**** deal task begin :task 6
**** deal task finish :task 6
Work只处理了sleep,Work2处理了1、2、3、4、5、6 这个六条消息。
六、消息持久化
上面说到消息确认的时候,提到了工作者被kill的情况。那如果RabbitMQ被stop掉了呢?我们来看下:
这次只启动Work和NewTask,不启动Work2,所有消息都交给Work来处理,控制台打印信息:
1.NewTask的控制台打印结果:
** new task ****:sleep
** new task ****:task 1
** new task ****:task 2
** new task ****:task 3
** new task ****:task 4
** new task ****:task 5
** new task ****:task 6 2.Work的控制台打印结果:
**** deal task begin :sleep
在work处理sleep的过程中,我们停掉RabbitMQ服务
然后重新start服务并执行rabbitmq-plugins enable rabbitmq_management命令,然后查看管理页面:

你会发现,所有消息都将被清空了。这种丢失属于服务端丢失。
因此需要将消息进行持久化来应对这种情况。
持久化需要做两件事情:
- 队列持久化,在声明队列的时候,将第二个参数设为true


另外,由于RabbitMQ不允许重新定义已经存在的队列,否则就会报错(上一篇博客中已经提到过了),因此我们将这次的队列名改下:

- 消息持久化,在发送消息的时候,将第三个参数设为2

然后运行代码,在work处理sleep的时候将服务停掉,并重新启动且执行rabbitmq-plugins enable rabbitmq_management命令,然后查看管理页面:

一共7条消息,未确认的1条(sleep)和ready的6条(1、2、3、4、5、6)。消息被保存了下来。
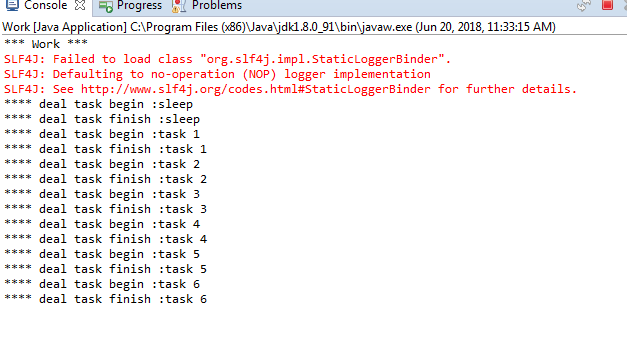
重新启动Work,所有消息被消费:

RabbitMQ入门:工作队列(Work Queue)的更多相关文章
- RabbitMQ学习总结 第三篇:工作队列Work Queue
目录 RabbitMQ学习总结 第一篇:理论篇 RabbitMQ学习总结 第二篇:快速入门HelloWorld RabbitMQ学习总结 第三篇:工作队列Work Queue RabbitMQ学习总结 ...
- RabbitMQ入门教程(四):工作队列(Work Queues)
原文:RabbitMQ入门教程(四):工作队列(Work Queues) 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https:/ ...
- RabbitMQ入门(二)工作队列
在文章RabbitMQ入门(一)之Hello World,我们编写程序通过指定的队列来发送和接受消息.在本文中,我们将会创建工作队列(Work Queue),通过多个workers来分配耗时任务. ...
- RabbitMQ入门(2)——工作队列
前面介绍了队列接收和发送消息,这篇将学习如何创建一个工作队列来处理在多个消费者之间分配耗时的任务.工作队列(work queue),又称任务队列(task queue). 工作队列的目的是为了避免立刻 ...
- [转]RabbitMQ入门教程(概念,应用场景,安装,使用)
原文地址:https://www.jianshu.com/p/dae5bbed39b1 RabbitMQ 简介 RabbitMQ是一个在AMQP(Advanced Message Queuing Pr ...
- RabbitMQ入门:总结
随着上一篇博文的发布,RabbitMQ的基础内容我也学习完了,RabbitMQ入门系列的博客跟着收官了,以后有机会的话再写一些在实战中的应用分享,多谢大家一直以来的支持和认可. RabbitMQ入门系 ...
- RabbitMQ入门:发布/订阅(Publish/Subscribe)
在前面的两篇博客中 RabbitMQ入门:Hello RabbitMQ 代码实例 RabbitMQ入门:工作队列(Work Queue) 遇到的实例都是一个消息只发送给一个消费者(工作者),他们的消息 ...
- RabbitMQ入门(6)——远程过程调用(RPC)
在RabbitMQ入门(2)--工作队列中,我们学习了如何使用工作队列处理在多个工作者之间分配耗时任务.如果我们需要运行远程主机上的某个方法并等待结果怎么办呢?这种模式就是常说的远程过程调用(Remo ...
- RabbitMQ入门(3)——发布/订阅(Publish/Subscribe)
在上一篇RabbitMQ入门(2)--工作队列中,有一个默认的前提:每个任务都只发送到一个工作人员.这一篇将介绍发送一个消息到多个消费者.这种模式称为发布/订阅(Publish/Subscribe). ...
随机推荐
- FreeMarker标签使用
FreeMarker标签使用 模板技术在现代的软件开发中有着重要的地位,主要用于view层的展示,freemarker是比较流行的一种. 一.FreeMarker模板文件主要有4个部分组成 ①文本,直 ...
- javascript库概念与连缀
一.JavaScript 库 1.什么是javascript库: javascript库,说白了,就是把各种常用的代码片段,组织起来放在一个 js 文件里,组成一个包,这个包就是 JavaScript ...
- 【目录】利用Python进行数据分析(第2版)
第一章 准备工作 1.1 What Is This Book About(这本书是关于什么的) 1.2 Why Python for Data Analysis?(为什么使用Python做数据分析) ...
- 64. [Mcoi2018]终末之诗(上)
Description 求出\(k^{k^{k^{k^{...}}}} \pmod p\) 的结果 扩展欧拉定理:\[a^x=a^{min(x,x\%\varphi(p)+\varphi(p))}(m ...
- [luogu2312] 解方程
题面 秦九韶公式 看了上面这个之后大家应该都会了, 就是读入的时候边读入边取模, 从\(1\)到\(m\)间将每一个数带进去试一下就可以了, 复杂度是\(O(nm)\)的. 古人的智慧是无 ...
- 造成MySQL全表扫描的原因
全表扫描是数据库搜寻表的每一条记录的过程,直到所有符合给定条件的记录返回为止.通常在数据库中,对无索引的表进行查询一般称为全表扫描:然而有时候我们即便添加了索引,但当我们的SQL语句写的不合理的时候也 ...
- Python自动化之form验证二
class LoginForm(forms.Form): user = fields.CharField() pwd = fields.CharField(validators=[]) def cle ...
- 1347: Last Digit (周期函数)
1347: Last Digit Submit Page Summary Time Limit: 1 Sec Memory Limit: 128 Mb Submitted: ...
- 【转载】Caffe + Ubuntu 14.04 + CUDA 6.5 新手安装配置指南
洋洋洒洒一大篇,就没截图了,这几天一直在折腾这个东西,实在没办法,不想用Linux但是,为了Caffe,只能如此了,安装这些东西,遇到很多问题,每个问题都要折磨很久,大概第一次就是这样的.想想,之后应 ...
- 404 Note Found 队-Beta6
目录 组员情况 组员2:胡青元 组员3:庄卉 组员4:家灿 组员5:恺琳 组员6:翟丹丹 组员7:何家伟 组员8:政演 组员9:黄鸿杰 组员10:刘一好 组员11:何宇恒 展示组内最新成果 团队签入记 ...