Spark程序本地运行
Spark程序本地运行
本次安装是在JDK安装完成的基础上进行的! SPARK版本和hadoop版本必须对应!!!
spark是基于hadoop运算的,两者有依赖关系,见下图:

前言:
1.环境变量配置:
1.1 打开“控制面板”选项

1.2.找到“系统”选项卡
1.3.点击“高级系统设置”

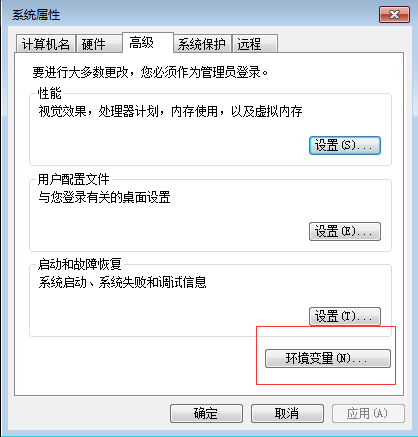
1.4.点击“环境变量”
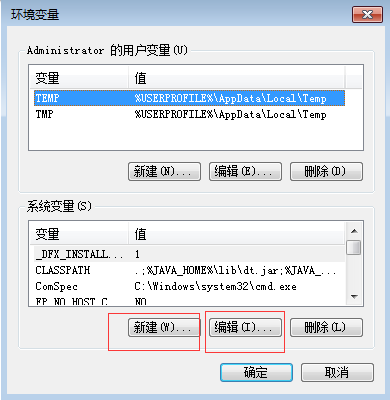
2.新建和编辑环境变量
1.下载hadoop-2.6.0.tar.gz文件,并解压在本地
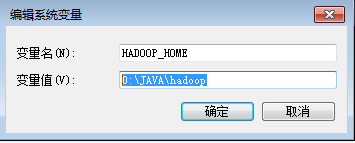
1.1 新建环境变量上配置
HADOOP_HOME
D:\JAVA\hadoop
1.2 修改PATH路径
$HADOOP_HOME/bin;
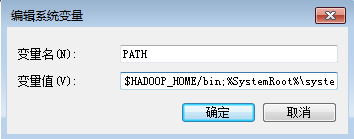
2.下载scala-2.10.6.zip文件,并解压在本地
2.1 新建环境变量上配置
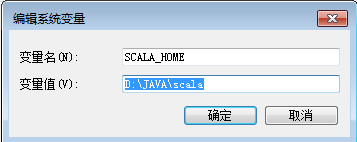
SCALA_HOME
D:\JAVA\scala
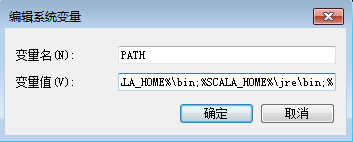
2.2 修改PATH路径
%SCALA_HOME%\bin;%SCALA_HOME%\jre\bin;
3.下载spark-1.6.2-bin-hadoop2.6.tgz文件,并解压在本地
3.1 新建环境变量上配置
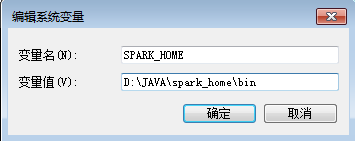
SPARK_HOME
D:\JAVA\spark_home\bin
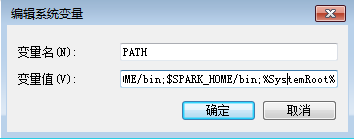
3.2 修改PATH路径
PATH $SPARK_HOME/bin;
4.下载scala-IDE.zip文件,并解压在本地
新建一个工程,修改library:
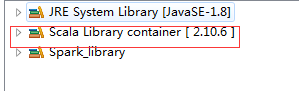
Scala library一定要是:2.10.X
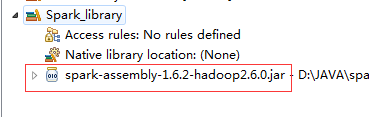
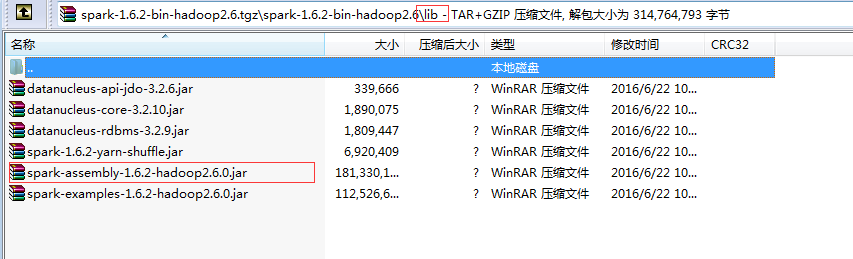
新建一个自己的library:添加一个Jar文件(${spark_home}/lib)
下跟Word Count代码

package com import org.apache.spark.SparkConf
import org.apache.spark.api.java.JavaSparkContext
import org.apache.spark.SparkContext /**
* 统计字符出现次数
*/
object WordCount {
def main(args: Array[String]): Unit = { System.setProperty("hadoop.home.dir", "D:\\JAVA\\hadoop");
val sc = new SparkContext("local", "My App")
val line = sc.textFile("/srv/1.txt") line.map((_, 1)).reduceByKey(_+_).collect().foreach(println) sc.stop()
println(111111)
}
}
hadoop下载点击这里
spark下载点击这里
scala安装包,scala IDE下载点击这里
Spark程序本地运行的更多相关文章
- spark 程序 windows 运行报错
1 java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries. at ...
- spark window本地运行wordcount错误
在运行本地运行spark或者hadoop代码时可能会遇到一下三种问题 1.Exception in thread "main" java.lang.UnsatisfiedLin ...
- 在local模式下的spark程序打包到集群上运行
一.前期准备 前期的环境准备,在Linux系统下要有Hadoop系统,spark伪分布式或者分布式,具体的教程可以查阅我的这两篇博客: Hadoop2.0伪分布式平台环境搭建 Spark2.4.0伪分 ...
- scala IDE for Eclipse开发Spark程序
1.开发环境准备 scala IDE for Eclipse:版本(4.6.1) 官网下载:http://scala-ide.org/download/sdk.html 百度云盘下载:链接:http: ...
- 初识Spark程序
执行第一个spark程序 普通模式提交任务: bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master spark ...
- [Spark]如何设置使得spark程序不输出 INFO级别的内容
Spark程序在运行的时候,总是输出很多INFO级别内容 查看了网上的一些文章,进行了试验. 发现在 /etc/spark/conf 目录下,有一个 log4j.properties.template ...
- spark之scala程序开发(本地运行模式):单词出现次数统计
准备工作: 将运行Scala-Eclipse的机器节点(CloudDeskTop)内存调整至4G,因为需要在该节点上跑本地(local)Spark程序,本地Spark程序会启动Worker进程耗用大量 ...
- 如何在本地使用scala或python运行Spark程序
如何在本地使用scala或python运行Spark程序 包含两个部分: 本地scala语言编写程序,并编译打包成jar,在本地运行. 本地使用python语言编写程序,直接调用spark的接口, ...
- Spark认识&环境搭建&运行第一个Spark程序
摘要:Spark作为新一代大数据计算引擎,因为内存计算的特性,具有比hadoop更快的计算速度.这里总结下对Spark的认识.虚拟机Spark安装.Spark开发环境搭建及编写第一个scala程序.运 ...
随机推荐
- [php] try - catch exceptiong handler
//http://stackoverflow.com/questions/1241728/can-i-try-catch-a-warningOne possibility is to set your ...
- AgentJob--无法重启Job--22022错误
错误描述: 发现有个Job计划为长期重复运行,但从某个时间点后未运行,无任何错误信息. 手动启动该Job后爆以下错误 运行环境: Window Server 2008 R2 Enterprise Mi ...
- Android实现带下划线的EditText(BUG修正)
之前写了一个关于实现EditText显示下划线的例子,发现仍然存在一些问题,在此继续探索,原文链接:http://www.cnblogs.com/ayqy/p/3599414.html (零)另一个b ...
- 【Kindeditor编辑器】 文件上传、空间管理
包括图片上传.文件上传.Flash上传.多媒体上传.空间管理(图片空间.文件空间等等) 一.编辑器相关参数 二.简单的封装类 这里只是做了简单的封装,欢迎大家指点改正. public class Ki ...
- VUE.js 中取得后台原生HTML字符串 原样显示问题
今天使用vue调试页面,发现了页面上的一个问题,后台数据传过来的HTML字符串并没有被转换为正常的HTML代码,一拍脑门,发现忘记转换了,于是满心欢喜加上了{{{}}}.但是之后构建发现报错: 为此去 ...
- 【cocos2d-x 手游研发小技巧(2)循环无限滚动的登陆背景】
原创文章,转载请附上链接:http://www.cnblogs.com/zisou/p/cocos2d-xARPG6.html 首先让大家知道我们想要实现的最终效果是什么样的? 看一个<逆天仙魔 ...
- L-BFGS算法介绍
可以看出,拟牛顿法每次迭代只需要根据前次迭代的即可以计算出,不需要求出Hesse矩阵的逆. 2.4 L-BFGS(limited-memory BFGS) BFGS算法中每次迭代计算需要前次迭代得到的 ...
- 如何将Spring Boot项目打包部署到外部Tomcat
1.项目打包 项目开发结束后,需要打包部署到外部服务器的Tomcat上,主要有几种方式. (1)生成jar包 cd 项目跟目录(和pom.xml同级)mvn clean package## 或 ...
- Tree-669. Trim a Binary Search Tree
Given a binary search tree and the lowest and highest boundaries as L and R, trim the tree so that a ...
- linux下各个目录里面都装了什么
文章来源:http://blog.csdn.net/sunstars2009918/article/details/7038772 搞电脑的人总想知道自己的系统里到底有些什么东西,于是我就在Linux ...