Ensemble_learning 集成学习算法 stacking 算法
原文:https://herbertmj.wikispaces.com/stacking%E7%AE%97%E6%B3%95
stacked 产生方法是一种截然不同的组合多个模型的方法,它讲的是组合学习器的概念,但是使用的相对于bagging和boosting较少,它不像bagging和boosting,而是组合不同的模型,具体的过程如下:
1.划分训练数据集为两个不相交的集合。
2. 在第一个集合上训练多个学习器。
3. 在第二个集合上测试这几个学习器
4. 把第三步得到的预测结果作为输入,把正确的回应作为输出,训练一个高层学习器,
这里需要注意的是1-3步的效果与cross-validation,我们不是用赢家通吃,而是使用非线性组合学习器的方法
下面是weka的stacking方法的buildClassifier方法:
http://www.datakit.cn/blog/2014/11/02/Ensemble_learning.html
在机器学习和统计学习中, Ensemble Learning(集成学习)是一种将多种学习算法组合在一起以取得更好表现的一种方法。与 Statistical Ensemble(统计总体,通常是无限的)不同,机器学习下的Ensemble 主要是指有限的模型相互组合,而且可以有很多不同的结构。相关的概念有多模型系统、Committee Learning、Modular systems、多分类器系统等等。这些概念相互之间相互联系,又有区别,而对这些概念的界定,业界目前还没有达成共识。
本文主要参考wikipedia, wikipedia中参考文章不再罗列!部分参考scholarpedia。本文对Ensemble方法仅作概述!
目录
- 1.Overview
- 2.Ensemble theory
- 3.Common types of ensembles
- 3.4 Bayesian model averaging
- 4. Ensemble combination rules
1.Overview
机器学习中,监督式学习算法(Supervised learning)可以描述为:对于一个具体问题,从一堆”假设”(hypothesis space,”假设”空间)中搜索一个具有较好且相对稳定的预测效果的模型。有些时候,即使”假设”空间中包含了一些很好的”假设”(hypothesis) ,我们也很难从中找到一个较好的。Ensemble 的方法就是组合多个”假设”以期望得到一个较优的”假设”。换句话说,Ensemble的方法就是组合许多弱模型(weak learners,预测效果一般的模型) 以得到一个强模型(strong learner,预测效果好的模型)。Ensemble中组合的模型可以是同一类的模型,也可以是不同类型的模型。
Ensemble方法对于大量数据和不充分数据都有很好的效果。因为一些简单模型数据量太大而很难训练,或者只能学习到一部分,而Ensemble方法可以有策略的将数据集划分成一些小数据集,分别进行训练,之后根据一些策略进行组合。相反,如果数据量很少,可以使用bootstrap进行抽样,得到多个数据集,分别进行训练后再组合(Efron 1979)。
使用Ensemble的方法在评估测试的时候,相比于单一模型,需要更多的计算。因此,有时候也认为Ensemble是用更多的计算来弥补弱模型。同时,这也导致模型中的每个参数所包含的信息量比单一模型少很多,导致太多的冗余!
注:本文直接使用Ensemble这个词,而不使用翻译,如“组合”等等
2.Ensemble theory
Ensemble方法是监督式学习的一种,训练完成之后就可以看成是单独的一个”假设”(或模型),只是该”假设”不一定是在原”假设”空间里的。因此,Ensemble方法具有更多的灵活性。理论上来说,Ensemble方法也比单一模型更容易过拟合。但是,实际中有一些方法(尤其是Bagging)也倾向于避免过拟合。
经验上来说,如果待组合的各个模型之间差异性(diversity )比较显著,那么Ensemble之后通常会有一个较好的结果,因此也有很多Ensemble的方法致力于提高待组合模型间的差异性。尽管不直观,但是越随机的算法(比如随机决策树)比有意设计的算法(比如熵减少决策树)更容易产生强分类器。然而,实际发现使用多个强学习算法比那些为了促进多样性而做的模型更加有效。
下图是使用训练集合中不同的子集进行训练(以获得适当的差异性,类似于合理抽样),得到不同的误差,之后适当的组合在一起来减少误差。
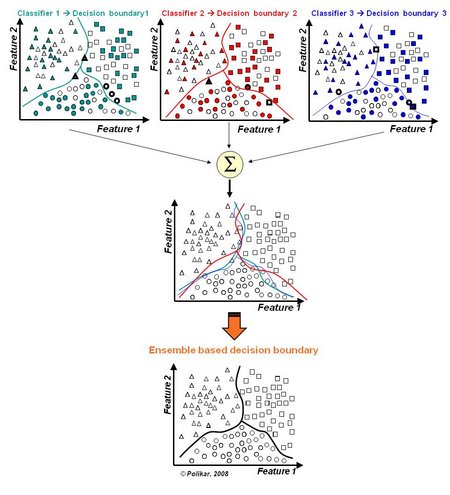
3.Common types of ensembles
3.1 Bayes optimal classifier
贝叶斯最优分类器(Bayes Optimal Classifier)是分类技术的一种,他是”假设”空间里所有”假设”的一个Ensemble。通常来说,没有别的Ensemble会比它有更好的表现!因此,可以认为他是最优的Ensemble(见Tom M. Mitchell, Machine Learning, 1997, pp. 175)。如果”假设”是对的话,那每一个”假设”对从系统中产生训练数据的似然性都有一个投票比例。为了促使训练数据集大小是有限的,我们需要对每个”假设”的投票乘上一个先验概率。因此,完整的Bayes Optimal Classifier如下:
y=argmaxcj∈C∑hi∈HP(cj|hi)P(T|hi)P(hi)
这里y是预测的类,C是所有可能的类别,H是”假设”空间,P是概率分布, T是训练数据。作为一个Ensemble,Bayes Optimal Classifier代表了一个”假设”,但是不一定在H中,而是在Ensemble空间(是原”假设”空间里的”假设”的所有可能的Ensemble)里的最优”假设”。然而,在实际中的很多例子中(即使很简单的例子),Bayes Optimal Classifier并不能很好的实现。实际中不能很好的实现Bayes Optimal Classifier的理由主要有以下几个:
- 1) 绝大多数”假设”空间都非常大而无法遍历(无法 argmax了);
- 2) 很多”假设”给出的结果就是一个类别,而不是概率(模型需要P(cj|hi));
- 3) 计算一个训练数据的无偏估计P(T|hi)是非常难的;
- 4) 估计各个”假设”的先验分布P(hi)基本是不可行的;
3.2 Bootstrap aggregating
Bootstrap aggregating通常又简称为Bagging(装袋法),它是让各个模型都平等投票来决定最终结果。为了提高模型的方差(variance, 差异性),bagging在训练待组合的各个模型的时候是从训练集合中随机的抽取数据。比如随机森林(random forest)就是多个随机决策树平均组合起来以达到较优分类准确率的模型。 但是,bagging的一个有趣应用是非监督式学习中,图像处理中使用不同的核函数进行bagging,可以阅读论文Image denoising with a multi-phase kernel principal component approach and an ensemble version 和 Preimages for Variation Patterns from Kernel PCA and Bagging。

3.3 Boosting
Boosting(提升法)是通过不断的建立新模型而新模型更强调上一个模型中被错误分类的样本,再将这些模型组合起来的方法。在一些例子中,boosting要比bagging有更好的准确率,但是也更容易过拟合。目前,boosting中最常用的方法是adaboost.

3.4 Bayesian model averaging
Bayesian model averaging (BMA, 贝叶斯模型平均)是一个寻求近似于Bayes Optimal Classifier 的方法,他通过从”假设”空间里抽样一些”假设”,再使用贝叶斯法则合并起来。 与Bayes Optimal Classifier不同,BMA是可以实际实现的。可以使用 Monte Carlo sampling 来采样”假设”。 比如, 使用Gibbs 抽样(Gibbs sampling)来得到一堆”假设”P(T|H)。事实证明在一定情况下,当这些生成的”假设”按照贝叶斯法则合并起来后,期望误差不大于2倍的Bayes Optimal Classifier 的期望误差。先不管理论上的证明,事实表明这种方法比简单的Ensemble方法(如bagging)更容易过拟合、且表现更差。然而,这些结论可能是错误理解了Bayesian model averaging和model combination的目的(前者是为了近似Bayes Optimal Classifier,而后者是为了提高模型准确率)。
伪代码如下:
function train_bayesian_model_averaging(T)
z = -infinity
For each model, m, in the ensemble:
Train m, typically using a random subset of the training data, T.
Let prior[m] be the prior probability that m is the generating hypothesis.
Typically, uniform priors are used, so prior[m] = 1.
Let x be the predictive accuracy (from 0 to 1) of m for predicting the labels in T.
Use x to estimate log_likelihood[m]. Often, this is computed as
log_likelihood[m] = |T| * (x * log(x) + (1 - x) * log(1 - x)),
where |T| is the number of training patterns in T.
z = max(z, log_likelihood[m])
For each model, m, in the ensemble:
weight[m] = prior[m] * exp(log_likelihood[m] - z)
Normalize all the model weights to sum to 1.3.5 Bayesian model combination
Bayesian model combination(BMC) 是 BMA 的一个校正算法。它不是独立的生成Ensemble中的一个个模型,而是从可能的Ensemble Space中生成(模型的权重是由同一参数的Dirichlet分布生成)。这个修正克服了BMA算法给单个模型所有权重的倾向。尽管BMC比BMA有更多的计算量,但是它的结果也非常的好!有很多例子证明了BMC比BMA和bagging的效果更好。
对于BMA而言,使用贝叶斯法来计算模型权重就必须要计算给定各个模型时生成数据的概率P(T|hi)。通常情况下,Ensemble中的模型都不是严格服从训练数据的生成分布来生成数据,所以这一项一般都非常接近于0。如果Ensemble足够大到可以抽样整个”假设”空间,那么理论上结果是比较好。但是,Ensemble空间有限,不可行。因此,训练数据中的每个模式会导致Ensemble中与训练数据分布最接近的模型的权重增大。举一个例子来说,比如”假设”空间有5个假设,BMA与BMC可以简单的如下图所示:

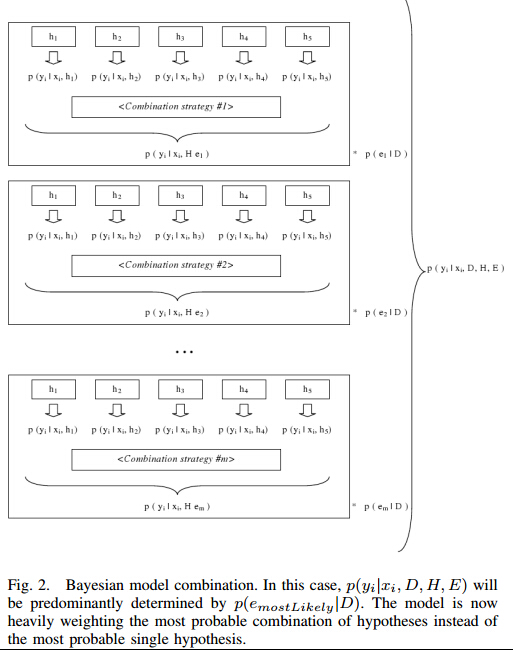
BMA是选择一个与生成数据的分布最接近的模型,而BMC是选择一个与生成数据的分布最接近的模型组合方式。BMA可以看成是从一堆模型中使用交叉验证来选择一个最优模型。而BMC可以认为是从一堆随机模型组合中选择一个最好的组合(Ensemble)。
伪代码如下:更多信息可以阅读Turning Bayesian Model Averaging Into Bayesian Model Combination
function train_bayesian_model_combination(T)
For each model, m, in the ensemble:
weight[m] = 0
sum_weight = 0
z = -infinity
Let n be some number of weightings to sample.
(100 might be a reasonable value. Smaller is faster.
Bigger leads to more precise results.)
for i from 0 to n - 1:
For each model, m, in the ensemble: // draw from a uniform Dirichlet distribution
v[m] = -log(random_uniform(0,1))
Normalize v to sum to 1
Let x be the predictive accuracy (from 0 to 1) of the entire ensemble, weighted
according to v, for predicting the labels in T.
Use x to estimate log_likelihood[i]. Often, this is computed as
log_likelihood[i] = |T| * (x * log(x) + (1 - x) * log(1 - x)),
where |T| is the number of training patterns in T.
If log_likelihood[i] > z: // z is used to maintain numerical stability
For each model, m, in the ensemble:
weight[m] = weight[m] * exp(z - log_likelihood[i])
z = log_likelihood[i]
w = exp(log_likelihood[i] - z)
For each model, m, in the ensemble:
weight[m] = weight[m] * sum_weight / (sum_weight + w) + w * v[m]
sum_weight = sum_weight + w
Normalize the model weights to sum to 1.3.6 Bucket of models
bucket of models是在Ensemble中针对具体问题进行最优模型选择的算法。当针对一个具体问题是,bucket of models 并不能够产生比最优模型更好的结果,但是在许多问题评估中,平均来说,它将比其他模型有更好的结果。
最常用的方法是交叉验证(cross-validation), 有时候称之为bake-off contest,伪代码如下:
For each model m in the bucket:
Do c times: (where 'c' is some constant)
Randomly divide the training dataset into two datasets: A, and B.
Train m with A
Test m with B
Select the model that obtains the highest average score交叉验证可以简单的总结为“在所有的训练集合上,看看它们的表现,选择表现最好的”。 Gating 是交叉验证的一种一般化。它在训练中多训练一个模型用于决定在特定问题下具体选择某个模型。通常情况下,感知器(perceptron)会被用于Gating model。它可以用于选择最优模型,也可以是bucket中各个模型的预测结果的一组线性权重。比如垃圾分类问题中,用感知器训练Gating 之后,可以训练成:在money单词出现2次以上时使用logistic的分类结果,否则使用朴素贝叶斯的结果;也可以训练成结果为a×money出现次数×决策树+b×money出现次数×朴素贝叶斯 + c的结果(结果是为是是垃圾邮件的概率,abc由感知器训练得到)。
Bucket of models也可以用于处理一大组问题,用以避免训练一些需要很长时间训练的模型。Landmark learning是一种旨在解决这个问题的元学习(meta-learning)方法。Bucket中,只包括一些训练比较快的模型(可能不是很准确),用这些模型的结果来确定哪些缓慢(但准确)算法是最有可能做最好。
3.7 Stacking
Stacking(有时候也称之为stacked generalization)是指训练一个模型用于组合(combine)其他各个模型。即首先我们先训练多个不同的模型,然后再以之前训练的各个模型的输出为输入来训练一个模型,以得到一个最终的输出。如果可以选用任意一个组合算法,那么理论上,Stacking可以表示上面提到的各种Ensemble方法。然而,实际中,我们通常使用单层logistic回归作为组合模型。
如下图,先在整个训练数据集上通过bootstrapped抽样得到各个训练集合,得到一系列分类模型,称之为Tier 1分类器, 然后将输出用于训练Tier 2 分类器(meta-classifier, Wolpert 1992)。潜在的一个思想是希望训练数据都得被正确的学习到了。比如某个分类器错误的学习到了特征空间里某个特定区域,因此错误分类就会来自这个区域,但是Tier 2分类器可能根据其他的分类器学习到正确的分类。交叉验证也通常用于训练Tier 1分类器:把这个训练集合分成T个块,Tier 1中的每个分类器根据各自余下的T-1块进行训练,并在T块(该块数据并未用于训练)上测试。之后将这些分类器的输出作为输入,在整个训练集合上训练Tier 2分类器。(这里未提及测试集,测试集是指不在任何训练过程中出现的数据)。
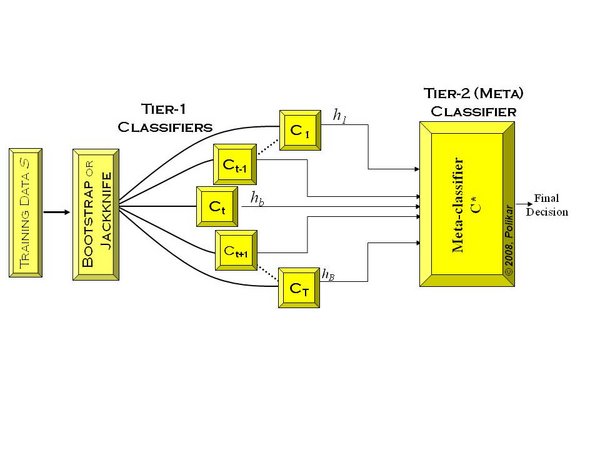
总的来说,Stacking 方法比任何单一模型的效果都要好,而且不仅成功应用在了监督式学习中,也成功应用在了非监督式(概率密度估计)学习中。甚至应用于估计bagging模型的错误率。据论文Feature-Weighted Linear Stacking(Sill, J. and Takacs, G. and Mackey L. and Lin D., 2009, arXiv:0911.0460)而言,Stacking比Bayesian Model Averaging表现要更好!此外在Kaggle上,很多比赛多是通过Stacking获取优秀的结果!
4. Ensemble combination rules
上面提到很多组合的方法,比如根据均值或者加权等等。但是,Ensemble内的各个模型不仅仅可以是同一个模型根据训练集合的随机子集进行训练(得到不同的参数),也可以不同的模型进行组合、甚至可以是针对不同的特征子集进行训练。之后各个模型可以通过不同的策略进行组合。但是不同的结果输出,组合的情况是不同的,这里主要包括三种情况:
- 1)Abstract-level:各个模型只输出一个目标类别,如猫、狗和人的图像识别中,仅输出人;
- 2)Rank-level:各个模型是输出目标类别的一个排序,如猫、狗和人的图像识别中,输出人-狗-猫;
- 3)measurement-level:各个模型输出的是目标类别的概率估计或一些相关的信念值,如猫、狗和人的图像识别中,输出0.7人-0.2狗-0.1猫;
可以用数学表示为,对于输出是Abstract-level的,第t个模型定义可以为 dt,j∈0,1,t=1,...,T;j=1,...,C, 这里T表示模型个数,C表示类别数。如果第t个模型选择了类别wj, 那么dt,j=1。如果输出是连续值, dt,j∈[0,1],我们总是可以归一化,使得每个值表示各个类别的后验概率估计Pt(wj|x).
Algebraic combiners(代数组合器)是非训练得到的组合器,这里通常用于有数值输出的情况。一般使用最小值、最大值、求和、均值、求积、中位数等等,进行最终的决策。也要Voting based methods(基于投票),一般用于离散的情况,比较常见的是按众数决策。也要按照 Weighted majority voting,即各个模型的结果有不同的权重,加权得到最终的结果,这里的权重可以通过学习得到。
当然,也可以使用其他的组合方法,比如上面提到的使用perceptron或logistic做组合器。但是,经验上来说,使用简单的组合规则比如求和或者众数投票,都可以达到非常好的结果!其他的一些方法可以参考Kuncheva 在2005的一些文章。
Ensemble_learning 集成学习算法 stacking 算法的更多相关文章
- 集成学习值Adaboost算法原理和代码小结(转载)
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类: 第一个是个体学习器之间存在强依赖关系: 另一类是个体学习器之间不存在强依赖关系. 前者的代表算法就是提升(bo ...
- 集成学习之Adaboost算法原理小结
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类,第一个是个体学习器之间存在强依赖关系,另一类是个体学习器之间不存在强依赖关系.前者的代表算法就是是boostin ...
- 集成学习之Adaboost算法原理
在boosting系列算法中,Adaboost是最著名的算法之一.Adaboost既可以用作分类,也可以用作回归. 1. boosting算法基本原理 集成学习原理中,boosting系列算法的思想:
- 集成学习总结 & Stacking方法详解
http://blog.csdn.net/willduan1/article/details/73618677 集成学习主要分为 bagging, boosting 和 stacking方法.本文主要 ...
- 机器学习——集成学习之Stacking
摘自: https://zhuanlan.zhihu.com/p/27689464 Stacking方法是指训练一个模型用于组合其他各个模型.首先我们先训练多个不同的模型,然后把之前训练的各个模型的输 ...
- 集成学习算法汇总----Boosting和Bagging(推荐AAA)
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- 集成学习算法总结----Boosting和Bagging(转)
1.集成学习概述 1.1 集成学习概述 集成学习在机器学习算法中具有较高的准去率,不足之处就是模型的训练过程可能比较复杂,效率不是很高.目前接触较多的集成学习主要有2种:基于Boosting的和基于B ...
- 集成学习算法总结----Boosting和Bagging
1.集成学习概述 1.1 集成学习概述 集成学习在机器学习算法中具有较高的准去率,不足之处就是模型的训练过程可能比较复杂,效率不是很高.目前接触较多的集成学习主要有2种:基于Boosting的和基于B ...
- 集成学习的不二法门bagging、boosting和三大法宝<结合策略>平均法,投票法和学习法(stacking)
单个学习器要么容易欠拟合要么容易过拟合,为了获得泛化性能优良的学习器,可以训练多个个体学习器,通过一定的结合策略,最终形成一个强学习器.这种集成多个个体学习器的方法称为集成学习(ensemble le ...
随机推荐
- Linux设备驱动模型(sysfs)
<总线模型概述> 随着技术的发展,系统的拓扑结构也越来越复杂,对热插拔.跨平台移植性的要求越来越高,从Linux2.6内核开始提供全新的设备模型.将所有的驱动挂载到计算机的总线上(比如US ...
- 富文本插件KindEditor
具体用法查看官网http://kindeditor.net/doc.php {% load staticfiles %} <!DOCTYPE html> <html lang=&qu ...
- Django Q对象
使用Q 对象进行复杂的查询¶ filter() 等方法中的关键字参数查询都是一起进行“AND” 的. 如果你需要执行更复杂的查询(例如OR 语句),你可以使用Q 对象. Q 对象 (django.db ...
- Kolibri v2.0-Buffer Overflow成功复现
Kolibri v2.0-Buffer Overflow成功复现及分析 文件下载地址:http://pan.baidu.com/s/1eS9r9lS 正文 本次讲解用JMP ESP的方法溢出 关于网上 ...
- Android中Service与IntentService的使用比较
不知道大家有没有和我一样,以前做项目或者练习的时候一直都是用Service来处理后台耗时操作,却很少注意到还有个IntentService,前段时间准备面试的时候看到了一篇关于IntentServic ...
- hdu 4118 dfs
题意:给n个点,每个点有一个人,有n-1条有权值的边,求所有人不在原来位置所移动的距离的和最大值.不能重复 这题的方法很有看点啊,标记为巩固题 Sample Input 1 4 1 2 3 2 3 2 ...
- 【POJ】1419:Graph Coloring【普通图最大点独立集】【最大团】
Graph Coloring Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 5775 Accepted: 2678 ...
- Markdown中如何插入视频 > iframe?
关于Markdown中如何插入视频这一问题 网上众说纷纭,一直也没找到一个确切的答案,想来也是,这些东西毕竟还不算成熟.各种以前提供过的方法现在来讲,可能在更新或是关闭大潮中又没了 而且,Ma ...
- 证明 O(n/1+n/2+…+n/n)=O(nlogn)
前言 在算法中,经常需要用到一种与调和级数有关的方法求解,在分析该方法的复杂度时,我们会经常得到\(O(\frac{n}{1}+\frac{n}{2}+\ldots+\frac{n}{n})\)的复杂 ...
- 自动化运维之 ~cobbler~
一 .Cobbler简介 Cobbler是一个快速网络安装linux的服务,而且在经过调整也可以支持网络安装windows.该工具使用python开发,小巧轻便(才15k 行python代码),使用简 ...