Hadoop Hive概念学习系列之hive里的JDBC编程入门(二十二)
Hive与JDBC示例
在使用 JDBC 开发 Hive 程序时, 必须首先开启 Hive 的远程服务接口。在hive安装目录下的bin,使用下面命令进行开启:
hive -service hiveserver & //Hive低版本提供的服务是:Hiveserver
hive --service hiveserver2 & //Hive0.11.0以上版本提供了的服务是:Hiveserver2
我这里使用的Hive1.0版本,故我们使用Hiveserver2服务,下面我使用 Java 代码通过JDBC连接Hiveserver。

18.1 测试数据
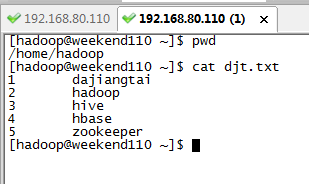
本地目录/home/hadoop/下的djt.txt文件内容(每行数据之间用tab键隔开)如下所示:
1 dajiangtai
2 hadoop
3 Hive
4 hbase
5 spark
18.2 程序代码
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
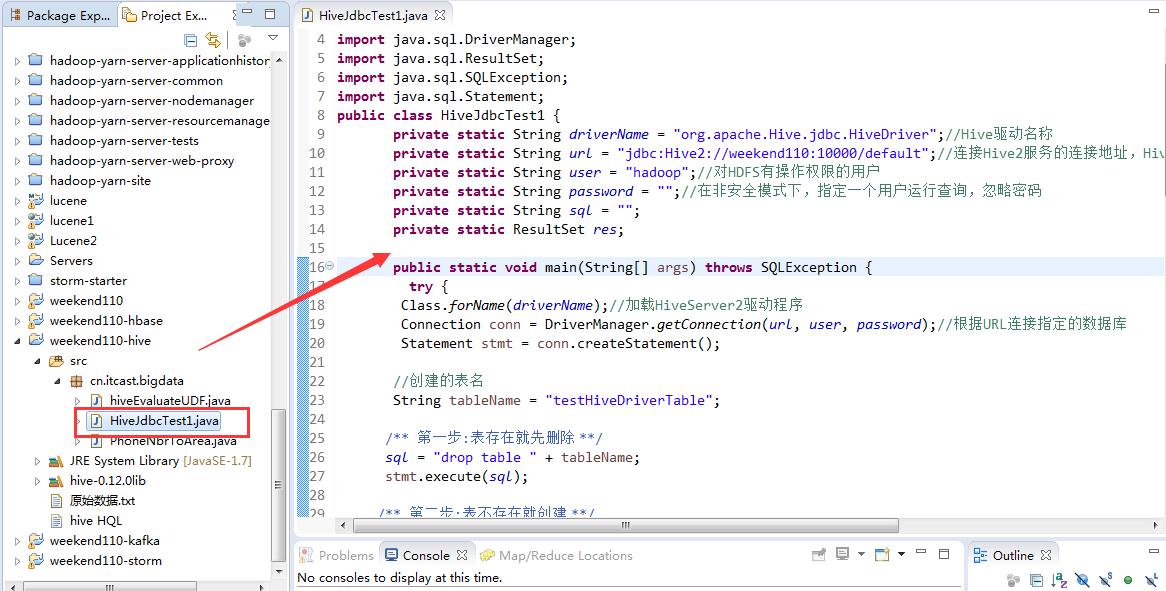
public class HiveJdbcTest1 {
private static String driverName = "org.apache.Hive.jdbc.HiveDriver";//Hive驱动名称
private static String url = "jdbc:Hive2://djt11:10000/default";//连接Hive2服务的连接地址,Hive0.11.0以上版本提供了一个全新的服务:HiveServer2
private static String user = "hadoop";//对HDFS有操作权限的用户
private static String password = "";//在非安全模式下,指定一个用户运行查询,忽略密码
private static String sql = "";
private static ResultSet res;
public static void main(String[] args) {
try {
Class.forName(driverName);//加载HiveServer2驱动程序
Connection conn = DriverManager.getConnection(url, user, password);//根据URL连接指定的数据库
Statement stmt = conn.createStatement();
//创建的表名
String tableName = "testHiveDriverTable";
/** 第一步:表存在就先删除 **/
sql = "drop table " + tableName;
stmt.execute(sql);
/** 第二步:表不存在就创建 **/
sql = "create table " + tableName + " (key int, value string) row format delimited fields terminated by '\t' STORED AS TEXTFILE";
stmt.execute(sql);
// 执行“show tables”操作
sql = "show tables '" + tableName + "'";
res = stmt.executeQuery(sql);
if (res.next()) {
System.out.println(res.getString(1));
}
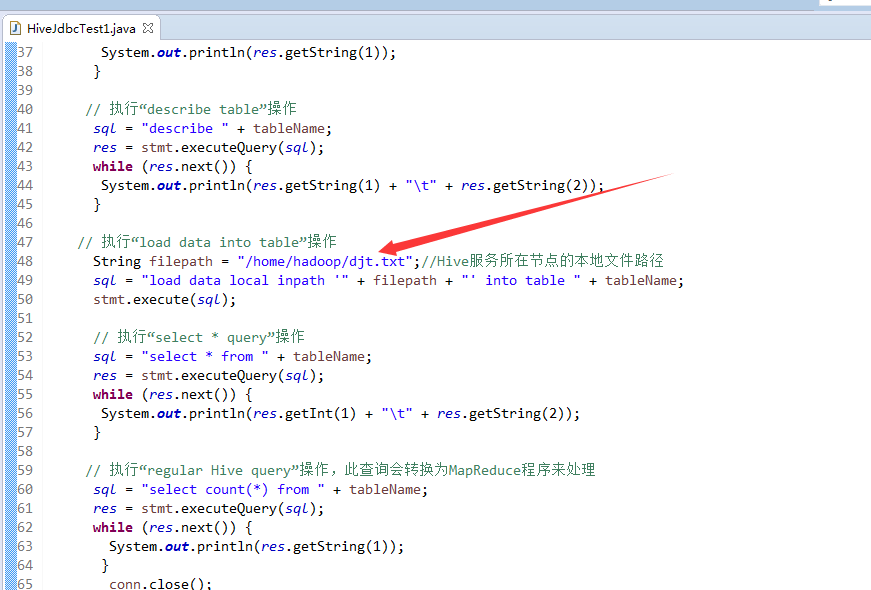
// 执行“describe table”操作
sql = "describe " + tableName;
res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(res.getString(1) + "\t" + res.getString(2));
}
// 执行“load data into table”操作
String filepath = "/home/hadoop/djt.txt";//Hive服务所在节点的本地文件路径
sql = "load data local inpath '" + filepath + "' into table " + tableName;
stmt.execute(sql);
// 执行“select * query”操作
sql = "select * from " + tableName;
res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(res.getInt(1) + "\t" + res.getString(2));
}
// 执行“regular Hive query”操作,此查询会转换为MapReduce程序来处理
sql = "select count(*) from " + tableName;
res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(res.getString(1));
}
conn.close();
conn = null;
} catch (ClassNotFoundException e) {
e.printStackTrace();
System.exit(1);
} catch (SQLException e) {
e.printStackTrace();
System.exit(1);
}
}
}
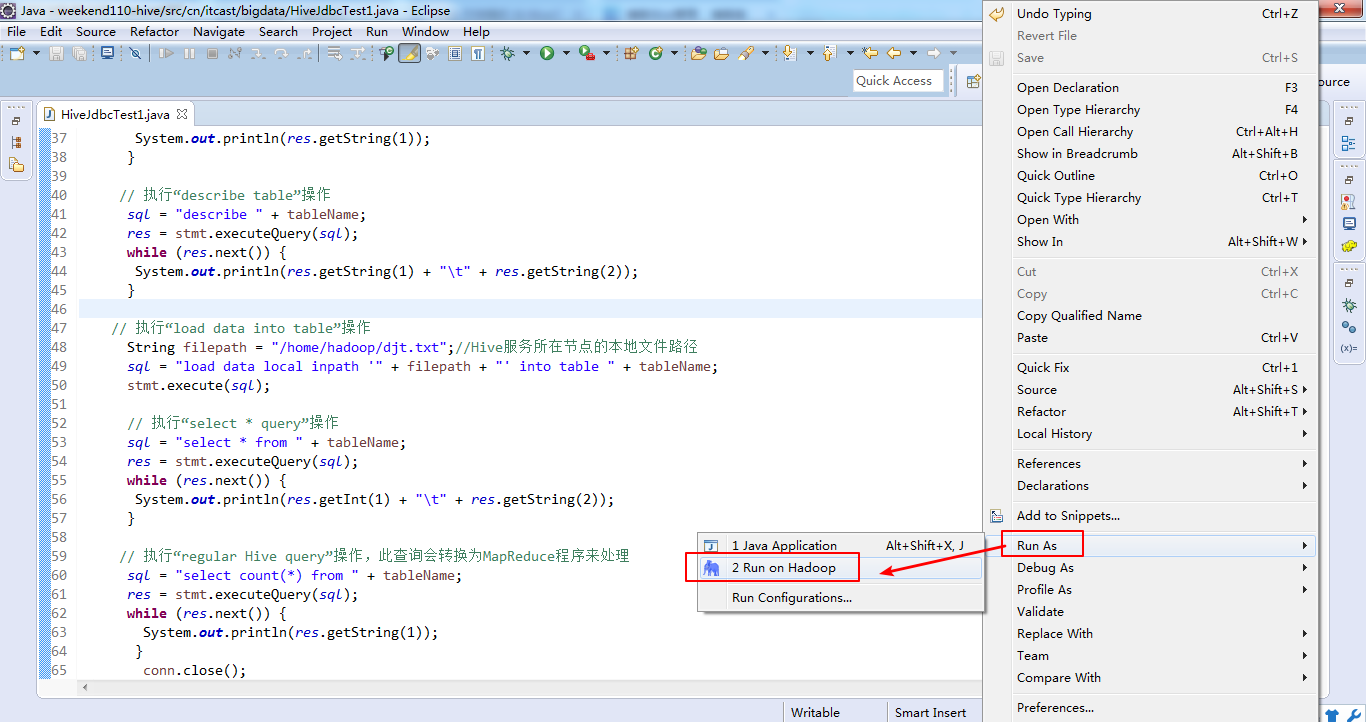
18.3 运行结果(右击-->Run as-->Run on Hadoop)
执行“show tables”运行结果:
testHivedrivertable
执行“describe table”运行结果:
key int
value string
执行“select * query”运行结果:
1 dajiangtai
2 hadoop
3 Hive
4 hbase
5 spark
执行“regular Hive query”运行结果:
5
hive jdbc使用
Hive项目开发环境搭建(Eclipse\MyEclipse + Maven)
Hadoop Hive概念学习系列之hive里的JDBC编程入门(二十二)的更多相关文章
- Hadoop HDFS概念学习系列之HDFS升级和回滚机制(十二)
不多说,直接上干货! HDFS升级和回滚机制 作为一个大型的分布式系统,Hadoop内部实现了一套升级机制,当在一个集群上升级Hadoop时,像其他的软件升级一样,可能会有新的bug或一些会影响现有应 ...
- Hadoop Hive概念学习系列之hive里的索引(十三)
Hive支持索引,但是Hive的索引与关系型数据库中的索引并不相同,比如,Hive不支持主键或者外键. Hive索引可以建立在表中的某些列上,以提升一些操作的效率,例如减少MapReduce任务中需要 ...
- Hadoop Hive概念学习系列之hive里的扩展接口(CLI、Beeline、JDBC)(十六)
<Spark最佳实战 陈欢>写的这本书,关于此知识点,非常好,在94页. hive里的扩展接口,主要包括CLI(控制命令行接口).Beeline和JDBC等方式访问Hive. CLI和B ...
- Hadoop Hive概念学习系列之hive里如何显示当前数据库及传参(十九)
这个小知识点,看似简单,用处极大. $ hive --hiveconf hive.cli.print.current.db=true $ hive --hiveconf hive.cli.print. ...
- Hadoop Hive概念学习系列之hive三种方式区别和搭建、HiveServer2环境搭建、HWI环境搭建和beeline环境搭建(五)
说在前面的话 以下三种情况,最好是在3台集群里做,比如,master.slave1.slave2的master和slave1都安装了hive,将master作为服务端,将slave1作为服务端. 以 ...
- Hadoop Hive概念学习系列之hive里的优化和高级功能(十四)
在一些特定的业务场景下,使用hive默认的配置对数据进行分析,虽然默认的配置能够实现业务需求,但是分析效率可能会很低. Hive有针对性地对不同的查询进行了优化.在Hive里可以通过修改配置的方式进行 ...
- Hadoop Hive概念学习系列之hive里的分区(九)
为了对表进行合理的管理以及提高查询效率,Hive可以将表组织成“分区”. 分区是表的部分列的集合,可以为频繁使用的数据建立分区,这样查找分区中的数据时就不需要扫描全表,这对于提高查找效率很有帮助. 分 ...
- Hadoop Hive概念学习系列之hive里的用户定义函数UDF(十七)
Hive可以通过实现用户定义函数(User-Defined Functions,UDF)进行扩展(事实上,大多数Hive功能都是通过扩展UDF实现的).想要开发UDF程序,需要继承org.apache ...
- Hadoop Hive概念学习系列之hive里的视图(十二)
不多说,直接上干货! 可以先,从MySQL里的视图概念理解入手 视图是由从数据库的基本表中选取出来的数据组成的逻辑窗口,与基本表不同,它是一个虚表.在数据库中,存放的只是视图的定义,而不存放视图包含的 ...
随机推荐
- java抽象类和普通类的区别
1.抽象类不能被实例化. 2.抽象类可以有构造函数,被继承时子类必须继承父类一个构造方法,抽象方法不能被声明为静态. 3.抽象方法只需申明,而无需实现,抽象类中可以允许普通方法有主体 4.含有抽象方法 ...
- [转载]AMD 的 CommonJS wrapping
https://www.imququ.com/post/amd-simplified-commonjs-wrapping.html 它是什么? 为了复用已有的 CommonJS 模块,AMD 规定了 ...
- CodeVS4416 FFF 团卧底的后宫
题目描述 Description 你在某日收到了 FFF 团卧底的求助,在他某日旅游回来,他的后宫们出现了一些不可调和的矛盾,如果 FFF 团卧底把自己的宝贝分给 a 号妹子,那么 b 号妹子至少要在 ...
- 【leetcode 简单】 第六十四题 翻转二叉树
翻转一棵二叉树. 示例: 输入: 4 / \ 2 7 / \ / \ 1 3 6 9 输出: 4 / \ 7 2 / \ / \ 9 6 3 1 备注: 这个问题是受到 Max Howell的 原问题 ...
- 假·最大子段和 (sdutoj 4359 首尾相连)(思维)
题目链接:http://acm.sdut.edu.cn/onlinejudge2/index.php/Home/Contest/contestproblem/cid/2736/pid/4359 具体思 ...
- 利用thrift rpc进行C++与Go的通信
一:什么是rpc rpc通俗来理解就是远程调用函数,相对于本地调用来说,只需要在主调函数中调用被掉函数即可,代码如下: void fun(int i) { cout << "fu ...
- Oracle中varchar2(XX)和varchar2(XX byte)区别
这两个相不相同是由参数NLS_LENGTH_SEMANTICS决定的,有两个单位,char(字符)或者字节(byte),该参数默认值为BYTE. alter session set nls_lengt ...
- 【逆向知识】PE ASLR
1.知识点 微软从windows vista/windows server 2008(kernel version 6.0)开始采用ASLR技术,主要目的是为了防止缓冲区溢出 ASLR技术会使PE文件 ...
- mysql5.7半自动同步设置【转】
mysql的主从复制主要有3种模式: a..主从同步复制:数据完整性好,但是性能消耗高 b.主从异步复制:性能消耗低,但是容易出现主从数据唯一性问题 c.主从半自动复制:介于上面两种之间.既能很好的保 ...
- Python模块:Random(未完待续)
本文基于Python 3.6.5的官文random编写. random模块简介 random为各种数学分布算法(distributions)实现了伪随机数生成器. 对于整数,是从一个范围中均匀选择(u ...