阿里架构师带你深入浅出jvm
本文跟大家聊聊JVM的内部结构,从组件中的多线程处理,JVM系统线程,局部变量数组等方面进行解析
JVM = 类加载器(classloader) + 执行引擎(execution engine) + 运行时数据区域(runtime data area)
下面这幅图展示了一个典型的JVM(符合JVM Specification Java SE 7 Edition)所具备的关键内部组件。
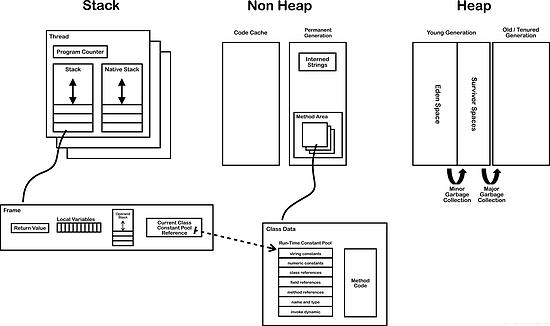
组件中的多线程处理
多线程处理”或“自由线程处理”指的是一个程序同时执行多个操作线程的能力。 作为多线程应用程序的一个示例,某个程序在一个线程上接收用户输入,在另一个线程上执行多种复杂的计算,并在第三个线程上更新数据库。 在单线程应用程序中,用户可能会花费时间等待计算或数据库更新完成。 而在多线程应用程序中,这些进程可以在后台进行,因此不会浪费用户时间。 多线程处理可以是组件编程中的一个非常强大的工具。通过编写多线程组件,您可以创建在后台执行复杂计算的组件,它们允许用户界面 (UI) 在计算的过程中自由地响应用户输入。 虽然多线程处理是一个强大的工具,但是要将其正确应用却比较困难。 未能正确实现的多线程代码可能降低应用程序性能,或甚至导致应用程序冻结。 下列主题将向您介绍多线程编程的一些注意事项和最佳做法。.NET Framework 提供几个在组件中进行多线程处理的选项。 System.Threading 命名空间中的功能是一个选项。 基于事件的异步模式是另一个选项。 BackgroundWorker 组件是对异步模式的实现;它提供封装在组件中以便于使用的高级功能。
JVM系统线程
如果你用jconsole或者任何其他的debug工具查看,可能会看到有许多线程在后台运行。这些运行着的后台线程不包含主线程,主线程是基于执行publicstatic void main(String[]) 的需要而被创建的。而这些后台线程都是被主线程所创建。在HotspotJVM中主要的后台系统线程,见下表:
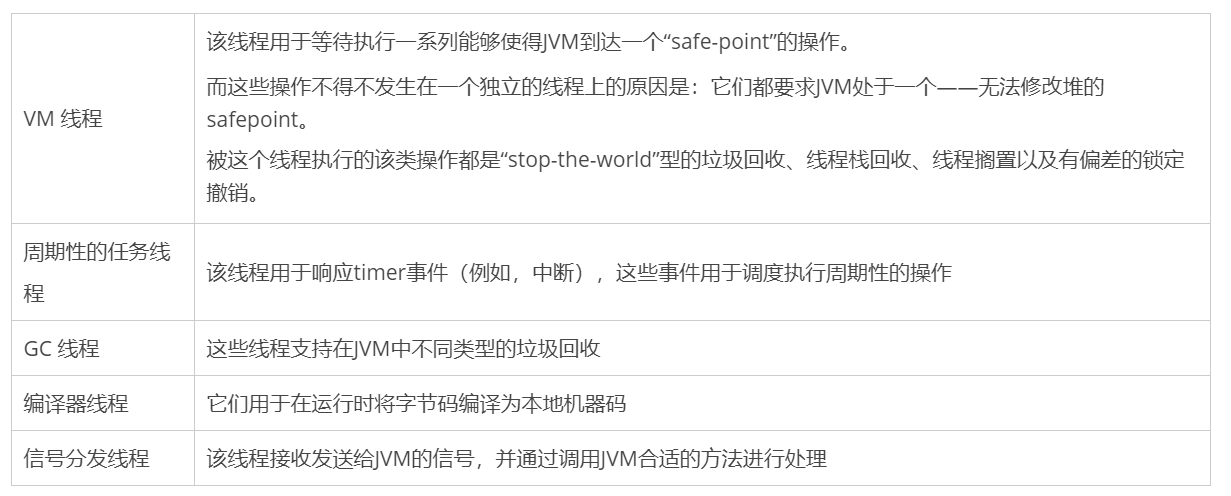
单个线程
每个线程的一次执行都包含如下的组件
程序计数器(PC)
除非当前指令或者操作码是原生的,否则当前指令或操作码的地址都需要依赖于PC来寻址。如果当前方法是原生的,那么该PC即为undefined。所有的CPU都有一个PC,通常PC在每个指令执行后被增加以指向即将执行的下一条指令的地址。JVM使用PC来跟踪正在执行的指令的位置。事实上,PC被用来指向methodarea的一个内存地址。
原生栈
不是所有的JVM都支持原生方法,但那些支持该特性的JVM通常会对每个线程创建一个原生方法栈。如果对JVM的JNI(JavaNative Invocation)采用c链接模型的实现,那么原生栈也将是一个C实现的栈。在这个例子中,原生栈中参数的顺序 、返回值都将跟通常的C程序相同。一个原生方法通常会对JVM产生一个回调(这依赖于JVM的实现)并执行一个Java方法。这样一个原生到Java的调用发生在栈上(通常在Java栈),与此同时线程也将离开原生栈,通常在Java栈上创建一个新的frame。
栈
每个线程都有属于它自己的栈,用于存储在线程上执行的每个方法的frame。栈是一个后进先出的数据结构,这可以使得当前正在执行的方法位于栈的顶部。对于每个方法的执行,都会有一个新的frame被创建并被入栈到栈的顶部。当方法正常的返回或在方法执行的过程中遇到未捕获的异常时frame会被出栈。栈不会被直接进行操作,除了push/ pop frame 对象。因此可以看出,frame对象可能会被分配在堆上,并且内存也没必要是连续的地址空间(请注意区分frame的指针跟frame对象)。
栈的限制
一个栈可以是动态的或者是有合适大小的。如果一个线程要求更大的栈,那么将抛出StackOverflowError异常;如果一个线程要求新创建一个frame,又没有足够的内存空间来分配,将会抛出OutOfMemoryError异常。
Frame
对于每一个方法的执行,一个新frame会被创建并被入栈到栈顶。当方法正常返回或在方法执行的过程中遇到未捕获的异常,frame会被出栈。
局部变量数组
局部变量数组包含了在方法执行期间所用到的所有的变量。包含一个对this的引用,所有的方法参数,以及其他局部定义的变量。对于类方法(比如静态方法),方法参数的存储索引从0开始;而对于实例方法,索引为0的槽都为存储this指针而保留。
操作数栈
操作数栈在字节码指令被执行的过程中使用。它跟原生CPU使用的通用目的的寄存器类似。大部分的字节码都把时间花费在跟操作数栈打交道上,通过入栈、出栈、复制、交换或者执行那些生产/消费值的操作。对字节码而言,那些在局部变量数组和操作数栈之间移动值的指令是非常频繁的。
动态链接
每个frame都包含一个对运行时常量池的引用。该引用指向将要被执行的方法所属的类的常量池。该引用也用于辅助动态链接。
当一个Java类被编译时,所有对存储在类的常量池中的变量以及方法的引用都被当做符号引用。一个符号引用仅仅只是一个逻辑引用而不是最终指向物理内存地址的引用。JVM的实现可以选择解析符号引用的时机,该时机可以发生在当类文件被验证后、被加载后,这称之eager或静态分析;不同的是它也可以发生在当符号引用被首次使用的时候,称之为lazy或延迟分析。但JVM必须保证:解析发生在每个引用被首次使用前,同时在该时间点,如果遇到分析错误能够抛出异常。绑定是一个处理过程,它将被符号引用标识的字段、方法或类替换为一个直接引用。这个处理过程只发生一次,因为符号引用需要被完全替换。如果一个符号引用关联着一个类,而该类还没有被解析,那么该类也会被立即加载。每个直接引用都被以偏移的方式存储,该存储结构关联着变量或方法的运行时位置。
线程之间共享
堆
堆中某个节点的值总是不大于或不小于其父节点的值;
堆总是一棵完全二叉树。
将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。常见的堆有二叉堆、斐波那契堆等。
堆的定义如下:n个元素的序列{k1,k2,ki,…,kn}当且仅当满足下关系时,称之为堆。
(ki <= k2i,ki <= k2i+1)或者(ki >= k2i,ki >= k2i+1), (i = 1,2,3,4...n/2)
若将和此次序列对应的一维数组(即以一维数组作此序列的存储结构)看成是一个完全二叉树,则堆的含义表明,完全二叉树中所有非终端结点的值均不大于(或不小于)其左、右孩子结点的值。由此,若序列{k1,k2,…,kn}是堆,则堆顶元素(或完全二叉树的根)必为序列中n个元素的最小值(或最大值)
非堆式内存
有些对象并不会创建在堆中,这些对象在逻辑上被认为是JVM机制的一部分。
非堆式的内存包括:
永久代中包含:
方法区
内部字符串
代码缓存:用于编译以及存储方法,这些方法已经被JIT编译成本地代码
内存管理
对象和数组永远都不会被显式释放,因此只能依靠垃圾回收器来自动地回收它们。
通常,以如下的步骤进行:
新对象和数组被创建在年轻代
次垃圾回收器将在年轻代上执行。那些仍然存活着的对象,将被从eden区移动到survivor区
主垃圾回收器将会把对象在代与代之间进行移动,主垃圾回收器通常会导致应用程序的线程暂停。那些仍然存活着的对象将被从年轻代移动到老年代
永久代会在每次老年代被回收的时候同时进行,它们在两者中其一满了之后都会被回收
JIT编译
JIT具体的做法是这样的:当载入一个类型时,CLR为该类型创建一个内部数据结构和相应的函数,当函数第一被调用时,JIT将该函数编译成机器语言.当再次遇到该函数时则直接从cache中执行已编译好的机器语言.
方法区
所有的线程共享相同的方法区。所以,对于方法区数据的访问以及对动态链接的处理必须是线程安全的。如果两个线程企图访问一个还没有被载入的类(该类必须只能被加载一次)的字段或者方法,直到该类被加载完成,这两个线程才能继续执行。
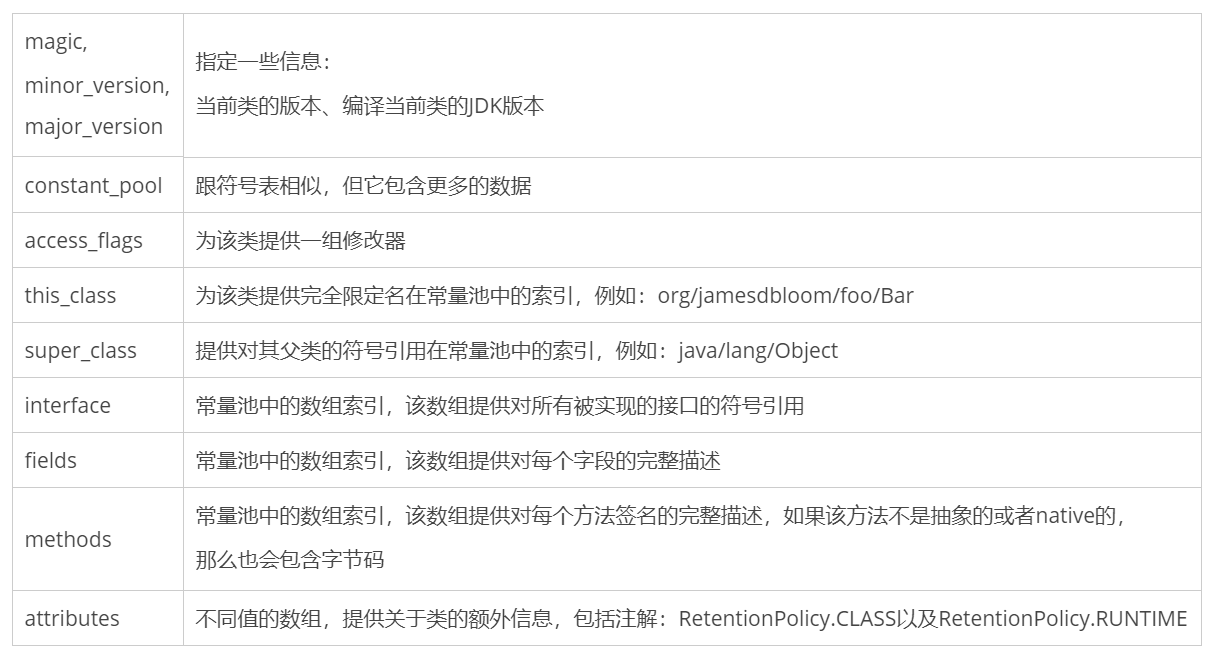
类的文件结构
一个被编译过的类文件包含如下的结构:
ClassFile
{ u4magic; u2minor_version; u2major_version; u2constant_pool_count;
cp_infocontant_pool[constant_pool_count – 1]; u2access_flags;
u2this_class; u2super_class; u2interfaces_count;
u2interfaces[interfaces_count]; u2fields_count;
field_infofields[fields_count]; u2methods_count;
method_infomethods[methods_count]; u2attributes_count;
attribute_infoattributes[attributes_count];}
可以使用javap命令查看被编译后的java类的字节码。
下面列出了在该类文件中,使用到的操作码:

就像在其他通用的字节码中那样,以上这些操作码主要用于跟本地变量、操作数栈以及运行时常量池打交道。
构造器有两个指令,第一个将“this”压入到操作数栈,接下来该构造器的父构造器被执行,这一操作将导致this被“消费”,因此this将从操作数栈出栈。
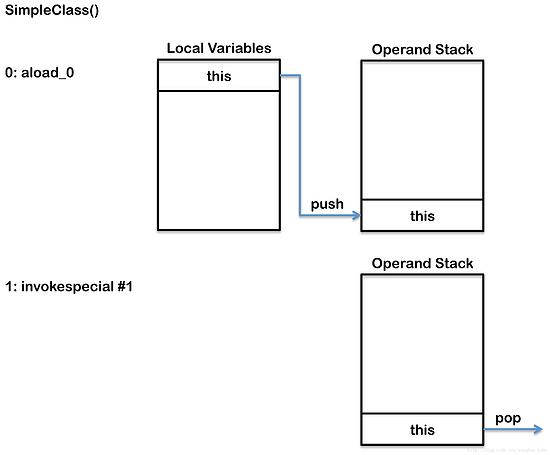
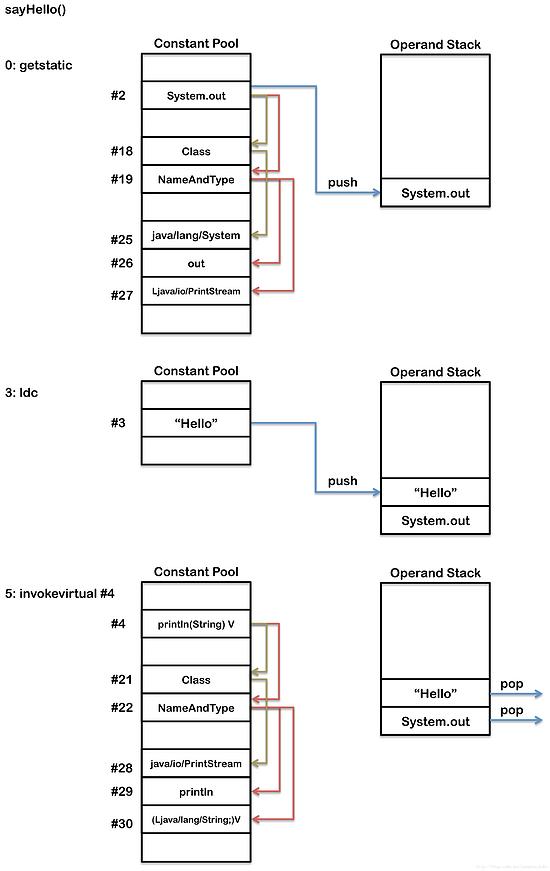
而对于sayHello()方法,它的执行将更为复杂。因为它不得不通过运行时常量池,解析符号引用到真实的引用。第一个操作数getstatic,用来入栈一个指向System类的静态字段out的引用到操作数栈。接下来的操作数ldc,入栈一个字符串字面量“Hello”到操作数栈。最后,invokevirtual操作数,执行System.out的println方法,这将使得“Hello”作为一个参数从操作数栈出栈,并为当前线程创建一个新的frame。
类加载器
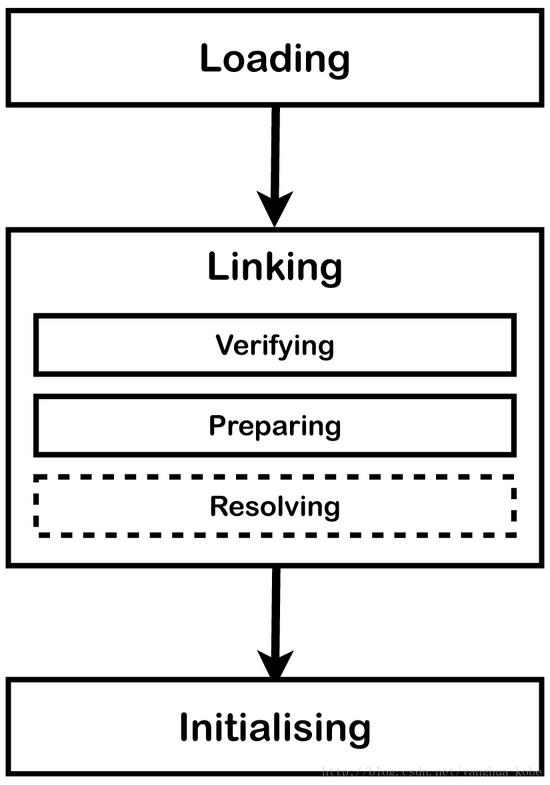
JVM的启动是通过bootstrap类加载器来加载一个用于初始化的类。在publicstatic void main(String[])被执行前,该类会被链接以及实例化。main方法的执行,将顺序经历加载,链接,以及对额外必要的类跟接口的初始化。
加载: 加载是这样一个过程:查找表示该类或接口类型的类文件,并把它读到一个字节数组中。接着,这些字节会被解析以确认它们是否表示一个Class对象以及是否有正确的主、次版本号。任何被当做直接superclass的类或接口也一同被加载。一旦这些工作完成,一个类或接口对象将会从二进制表示中创建。
链接: 链接包含了对该类或接口的验证,准备类型以及该类的直接父类跟父接口。简而言之,链接包含三个步骤:验证、准备以及解析(optional)
验证:该阶段会确认类以及接口的表示形式在结构上的正确性,同时满足Java编程语言以及JVM语义上的要求。
在验证阶段执行这些检查意味着在运行时可以免去在链接阶段进行这些动作,虽然拖慢了类的加载速度,然而它避免了在执行字节码的时候执行这些检查。
准备:包含了对静态存储的内存分配以及JVM所使用的任何数据结构(比如方法表)。静态字段都被创建以及实例化为它们的默认值。然而,没有任何实例化器或代码在这个阶段被执行,因为这些任务将会发生在实例化阶段。
解析:是一个可选的阶段。该阶段通过加载引用的类或接口来检查符号引用是否正确。如果在这个点这些检查没发生,那么对符号引用的解析会被推迟到直到它们被字节码指令使用之前。
实例化 类或接口,包含执行类或接口的实例化方法:<clinit>
在JVM中存在多个不同职责的类加载器。每一个类加载器都代理其已被加载的父加载器(除了bootstrap类加载器,因为它是根加载器)。
Bootstrap类加载器:当java程序运行时,java虚拟机需要装载java类,这个过程需要一个类装载器来完成。而类装载器本身也是一个java类,这就出现了类似人类的第一位母亲是如何产生出来的问题。
其实,java虚拟机中内嵌了一个称为Bootstrap的类装载器,它是用特定于操作系统的本地代码实现的,属于java虚拟机的内核,这个Bootstrap类装载器不用专门的类装载器去装载。Bootstrap类装载器负责加载java核心包中的类。
Extension 类加载器:从标准的Java扩展API中加载类。例如,安全的扩展功能集。
System 类加载器:这是应用程序默认的类加载器。它从classpath中加载应用程序类。
用户定义的类加载器:可以额外得定义类加载器来加载应用程序类。用户定义的类加载器可用于一些特殊的场景,比如:在运行时重新加载类或将一些特殊的类隔离为多个不同的分组(通常web服务器中都会有这样的需求,比如Tomcat)。
更快的类加载
一个称之为类数据共享(CDS)的特性自HotspotJVM 5.0开始被引进。在安装JVM期间,安装器加载一系列的Java核心类(如rt.jar)到一个经过映射过的内存区进行共享存档。CDS减少了加载这些类的时间从而提升了JVM的启动速度,同时允许这些类在不同的JVM实例之间共享。这大大减少了内存碎片。
方法区的位置
JVM Specification Java SE 7 Edition清楚地声明:尽管方法区是堆的一个逻辑组成部分,但最简单的实现可能是既不对它进行垃圾回收也不压缩它。然而矛盾的是利用jconsole查看Oracle的JVM的方法区(以及CodeCache)是非堆形式的。OpenJDK代码显示CodeCache相对ObjectHeap而言是VM中一个独立的域。
类加载器引用
类通常是按需加载,即第一次使用该类时才加载。由于有了类加载器,Java运行时系统不需要知道文件与文件系统。
运行时常量池
JVM对每个类型维护着一个常量池,它是一个跟符号表相似的运行时数据结构,但它包含了更多的数据。Java的字节码需要一些数据,通常这些数据会因为太大而难以直接存储在字节码中。取而代之的一种做法是将其存储在常量池中,字节码包含一个对常量池的引用。运行时常量池主要用来进行动态链接。
几种类型的数据会存储在常量池中,它们是:
数值字面量
字符串字面量
类的引用
字段的引用
方法的引用
如果你编译下面的这个简单的类:
package org.jvminternals;public class SimpleClass { public void sayHello() {System.out.println("Hello");}}
生成的类文件的常量池,看起来会像下图所示:
Constant pool: #1 = Methodref #6.#17 // java/lang/Object."":()V#2 = Fieldref #18.#19 // java/lang/System.out:Ljava/io/PrintStream;#3 = String #20 // "Hello"#4 = Methodref #21.#22 // java/io/PrintStream.println:(Ljava/lang/String;)V#5 = Class #23 // org/jvminternals/SimpleClass#6 = Class #24 // java/lang/Object#7 = Utf8 #8 = Utf8 ()V #9 = Utf8 Code #10 = Utf8 LineNumberTable #11 = Utf8 LocalVariableTable #12 = Utf8 this #13 = Utf8 Lorg/jvminternals/SimpleClass; #14 = Utf8 sayHello #15 = Utf8 SourceFile #16 = Utf8 SimpleClass.java #17 = NameAndType #7:#8 // "":()V#18 = Class #25 // java/lang/System#19 = NameAndType #26:#27 // out:Ljava/io/PrintStream;#20 = Utf8 Hello #21 = Class #28 // java/io/PrintStream#22 = NameAndType #29:#30 // println:(Ljava/lang/String;)V#23 = Utf8 org/jvminternals/SimpleClass #24 = Utf8 java/lang/Object#25 = Utf8 java/lang/System #26 = Utf8 out#27 = Utf8 Ljava/io/PrintStream; #28 = Utf8 java/io/PrintStream #29 = Utf8 println #30 = Utf8 (Ljava/lang/String;)V
常量池中包含了下面的这些类型:

异常表
异常表存储了每个异常处理器的信息:
起始点
终止点
处理代码的PC偏移量
被捕获的异常类的常量池索引
如果一个方法定义了try-catch或try-finally异常处理器,那么一个异常表将会被创建。它包含了每个异常处理器的信息或者finally块以及正在被处理的异常类型跟处理器代码的位置。
当一个异常被抛出,JVM会为当前方法寻找一个匹配的处理器。如果没有找到,那么该方法最终会唐突地出栈当前stackframe而异常会被重新抛出到调用链(新的frame)。如果在所有的frame都出栈之前还是没有找到异常处理器,那么当前线程将会被终止。当然这也可能会导致JVM被终止,如果异常被抛出到最后一个非后台线程的话,比如该线程就是主线程。
最终异常处理器会匹配所有的异常类型并且无论什么时候该类型的异常被抛出总是会得到执行。在没有异常抛出的例子中,finally块仍然会在方法的最后被执行。一旦return语句被执行就会立即跳转到finally代码块继续执行。
字符比较
字符比较(character comparison)是指按照字典次序对单个字符或字符串进行比较大小的操作,一般都是以ASCII码值的大小作为字符比较的标准。
符号表
符号表在编译程序工作的过程中需要不断收集、记录和使用源程序中一些语法符号的类型和特征等相关信息。这些信息一般以表格形式存储于系统中。如常数表、变量名表、数组名表、过程名表、标号表等等,统称为符号表。对于符号表组织、构造和管理方法的好坏会直接影响编译系统的运行效率。
在JVM中,内部字符串被存储在字符串表中。字符串表是一个hashtable映射对象指针到符号(比如:Hashtable
当类被加载时,字符串字面量会被编译器自动“内部化”并且被加入到字符表。另外字符串类的实例可以通过调用String.intern()来明确地内部化。当String.intern()被调用,如果符号表里已经包含该字符串,那么指向该字符串的引用将被返回。如果该字符串没有包含在字符表,则会被加入到字符串表同时返回其引用。
文章来源:https://my.oschina.net/u/3833719/blog/1799881
相关内容推荐:http://www.roncoo.com/course/list.html?courseName=jvm
阿里架构师带你深入浅出jvm的更多相关文章
- 百度资深架构师带你深入浅出一致性Hash原理
一.前言 在解决分布式系统中负载均衡的问题时候可以使用Hash算法让固定的一部分请求落到同一台服务器上,这样每台服务器固定处理一部分请求(并维护这些请求的信息),起到负载均衡的作用. 但是普通的余数h ...
- java架构师视频教程 内含activemq+jvm+netty+dubbo
目录: 架构师视频教程包含activemq jvm netty dubbo 0分布式项目实战所有视频(分布式项目视频)互联网架构师第二期-视频部分互联网架构师第二期-资料部分1.Netty快速入门教程 ...
- 阿里架构师的这一份Spring boot使用心得:网友看到都收藏了
阿里架构师的这一份Spring boot使用心得: 这一份PDF将从Spring Boot的出现开始讲起,到基本的环境搭建,进而对Spring的IOC及AOP进行详细讲解.以此作为理论基础,接着进行数 ...
- 百度架构师带你进阶高级JAVA架构,让你快速从代码开发者成长为系统架构者
百度架构师带你进阶高级JAVA架构,让你快速从代码开发者成长为系统架构者 1.
- 你真的了解微服务架构吗?听听八年阿里架构师怎样讲述Dubbo和Spring Cloud微服务架构
微服务架构是互联网很热门的话题,是互联网技术发展的必然结果.它提倡将单一应用程序划分成一组小的服务,服务之间互相协调.互相配合,为用户提供最终价值.虽然微服务架构没有公认的技术标准和规范或者草案,但业 ...
- 听听八年阿里架构师怎样讲述Dubbo和Spring Cloud微服务架构
转自:https://baijiahao.baidu.com/s?id=1600174787011483381&wfr=spider&for=pc 微服务架构是互联网很热门的话题,是互 ...
- 对JVM还有什么不懂的?一文章带你深入浅出JVM!
本文跟大家聊聊JVM的内部结构,从组件中的多线程处理,JVM系统线程,局部变量数组等方面进行解析 JVM JVM = 类加载器(classloader) + 执行引擎(execution engine ...
- 深入浅出!阿里P7架构师带你分析ArrayList集合源码,建议是先收藏再看!
ArrayList简介 ArrayList 是 Java 集合框架中比较常用的数据结构了.ArrayList是可以动态增长和缩减的索引序列,内部封装了一个动态再分配的Object[]数组 这里我们可以 ...
- “大话架构”阿里架构师分享的Java程序员需要突破的技术要点
一.源码分析 源码分析是一种临界知识,掌握了这种临界知识,能不变应万变,源码分析对于很多人来说很枯燥,生涩难懂. 源码阅读,我觉得最核心有三点:技术基础+强烈的求知欲+耐心. 我认为是阅读源码的最核心 ...
随机推荐
- 用Jmeter实现SQLServer数据库的增删查改
1.添加线程组 Jmeter性能测试,最重要的就是线程组了,线程组相当于用户活动 2.添加JDBC Connection Configuration Database URL:jdbc:sqlserv ...
- django关闭调试信息,打开内置错误视图
1 内置错误视图 Django内置处理HTTP错误的视图,主要错误及视图包括: 404错误:page not found视图 500错误:server error视图 400错误:bad reques ...
- JS笔记(一)
第一章: 编写JS流程: 1. 布局:HTML和CSS 2. 样式:修改页面元素样式,div的display样式 3. 事件:确定用户做什么操作,onclick(鼠标点击事件).onmouseo ...
- [转]使用awk批量杀进程的命令
1. ps -ef|grep aaa|grep -v grep 这是大家很熟悉的命令,这里就不再多说,就是从当前系统运行的进程的进程名中包含aaa关键字的进程. 2. 后面部分就是awk命令了,一般a ...
- in成员资格符
#in成员资格符 name='小树' '小'in name# 返回True '大树'in name#返回False
- html5的八大特性
HTML5是用于取代1999年所制定的 HTML 4.01 和 XHTML 1.0 标准的 HTML [1](标准通用标记语言下的一个应用)标准版本:现在仍处于发展阶段,但大部分浏览器已经支持某些 H ...
- 数据库性能优化(database tuning)性能优化绝不仅仅只是索引
一毕业就接触优化方面的问题,专业做优化也有至少5年之多的时间了,可现在还是经常听到很多人认为优化很简单,就是建索引的问题,这确实不能怪大家,做这行20多年的时间里,在职业生涯的每个阶段,几乎都能听到这 ...
- 在MySQL中使用子查询
子查询作为数据源 子查询生成的结果集包含行.列数据,因而非常适合将它与表一起包含在from子句的子查询里.例: SELECT d.dept_id, d.name, e_cnt.how_many num ...
- 如何在Shell读取文件并赋值
sys_info=$(cat /usr/local/sysconfig.txt)var=`echo $sys_info | awk -F ', ' '{print $0} ' ...
- 【转】如何使用slave_exec_mode优雅的跳过1032 1062的复制错误
今天线上的主从复制发生1062的错误,使用sql_slave_skip_counter跳过之后,由于后面的事务需要对刚刚的数据进行update,后续造成了新的1032的错误. 后来,无意中发现还有更好 ...