沉淀,再出发——手把手教你使用VirtualBox搭建含有三个虚拟节点的Hadoop集群
手把手教你使用VirtualBox搭建含有三个虚拟节点的Hadoop集群
一、准备,再出发
在项目启动之前,让我们看一下前面所做的工作。首先我们掌握了一些Linux的基本命令和重要的文件,其次我们学会了对vim,ssh,java,hadoop等工具的使用。在很多情况下,我们完成了单机/伪分布式集群就可以了,这样我们就可以开发程序了,但是我们和现实还有一步之遥,还可以做得更好。按照我们上面的操作,还不算是真正的分布式集群,将namenode,dataNode放到一起失去了真正集群的意义,一台电脑上的计算能力是有限的,我们还是没能彻底吃透hadoop集群。所以在下面的操作中,我们开始专注于真正Hadoop集群的搭建!
1.1、怎么搭建,如何搭建?
搭建的方式是多种多样的,具体的如下:
A、最真实的集群,使用三台电脑来搭建。NameNode至少要占用一台机器(master),DataNode也至少占用一台机器(slave),这样是可以工作的,可是考虑到集群的容错能力和备份能力,我们至少需要两台DataNode机器才算是真正的有了备份的能力。目前只有两台电脑并且没有交换器去将两台电脑联系在一起(当然我们可以使用WiFi来连接,可是这种连接并不是真正的集群环境,最好的办法是用导线将两台电脑连接到一起并且将接口放到交换机上,进行相应的配置),难度比较大;
B、退而求其次,可不可以用一台电脑来完成搭建呢?!答案还是有的,那就是虚拟机!
B.1、在Linux上安装虚拟机,在虚拟机上安装三个Linux系统来运行;
B.2、在windows上安装虚拟机,在虚拟机上安装三个Linux系统来运行;
B.3、使用Docker来安装,这个工具我目前还处在学习阶段;
我首先选择了前者,可是在Linux上安装虚拟机非常的困难,无论是VMware Workstation 还是VirtualBox安装起来都不是那样的顺心如意,在这上面投入精力有点不值,于是我选择了B.2,在windows10的系统上下载VirtualBox,并且在VirtualBox上面安装了一个Linux16.04.4的OS。具体的步骤非常简单了,和在VMware Workstation下安装差不多,选择VirtualBox的原因是该虚拟机比较轻量级,便于我们之后多开几个节点。另外,虚拟机还有一个非常方便的地方,那就是“复制”,或者说是“克隆”,我们可以将我们在一台虚拟机上布置好的内容原封不动的复制出来第二个这样的机器,并且保证IP和MAC完全不同,这点对我们非常有用。
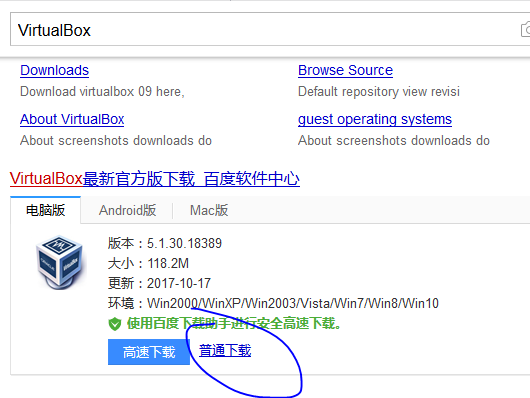
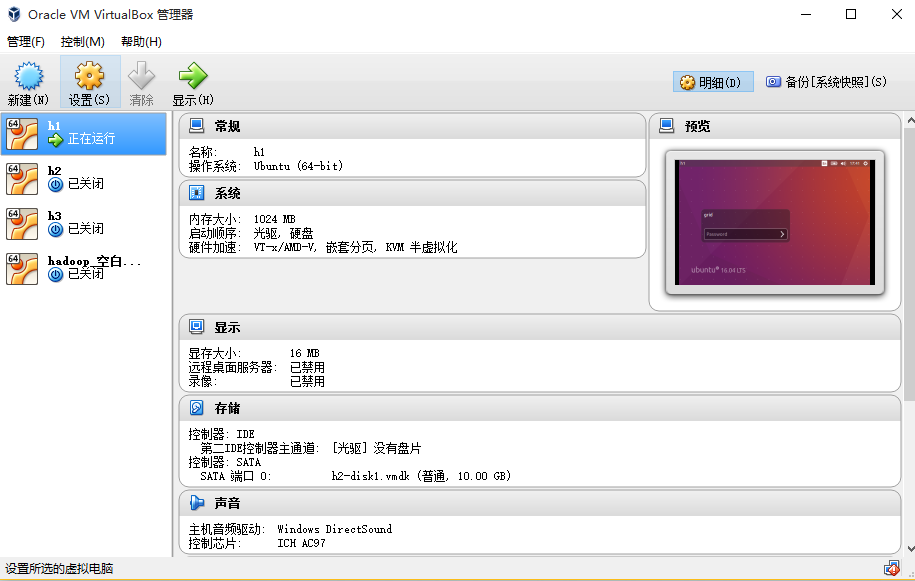
图.下载和安装VirtualBox
1.2、如何使得三台虚拟机构成一个局域网,并且能够连接到外网?
这个问题困惑了我很长时间,网上的文章大多都是一掠而过,而对于我们新学者来说无疑是非常困难的,好在我最后总算是找到了解决办法,首先我们要理解VirtualBox提供给我们的网卡设置是什么意思。明白了这些,我们还是不能配置好我们需要的局域网,无论是使用NAT、桥接还是Host Only我们不知道具体的配置方法,在卡了很长时间,我总算明白了其中的道理,我们的电脑一般是通过拨号上网的,我们的IP地址是不断变化的,一般有一个租用期限,使用的是DHCP协议,那么我们想要首先使得虚拟机和物理主机连通(比如下载一些安装包),就需要使用NAT网络地址转换协议,这样才能通过隧道协议将外网的包传递过来,其次,我们还需要使得三个虚拟机互相连通,那么我们必须保证这些主机是处在同一网段的,这样可以构成局域网,再加上这些虚拟主机最终都是通过网卡来收发信息的所以我们可以将网卡看做交换机,至少说是集线器hub吧。

图. 虚拟机的网络配置
具体的步骤如下,打开全局设定:
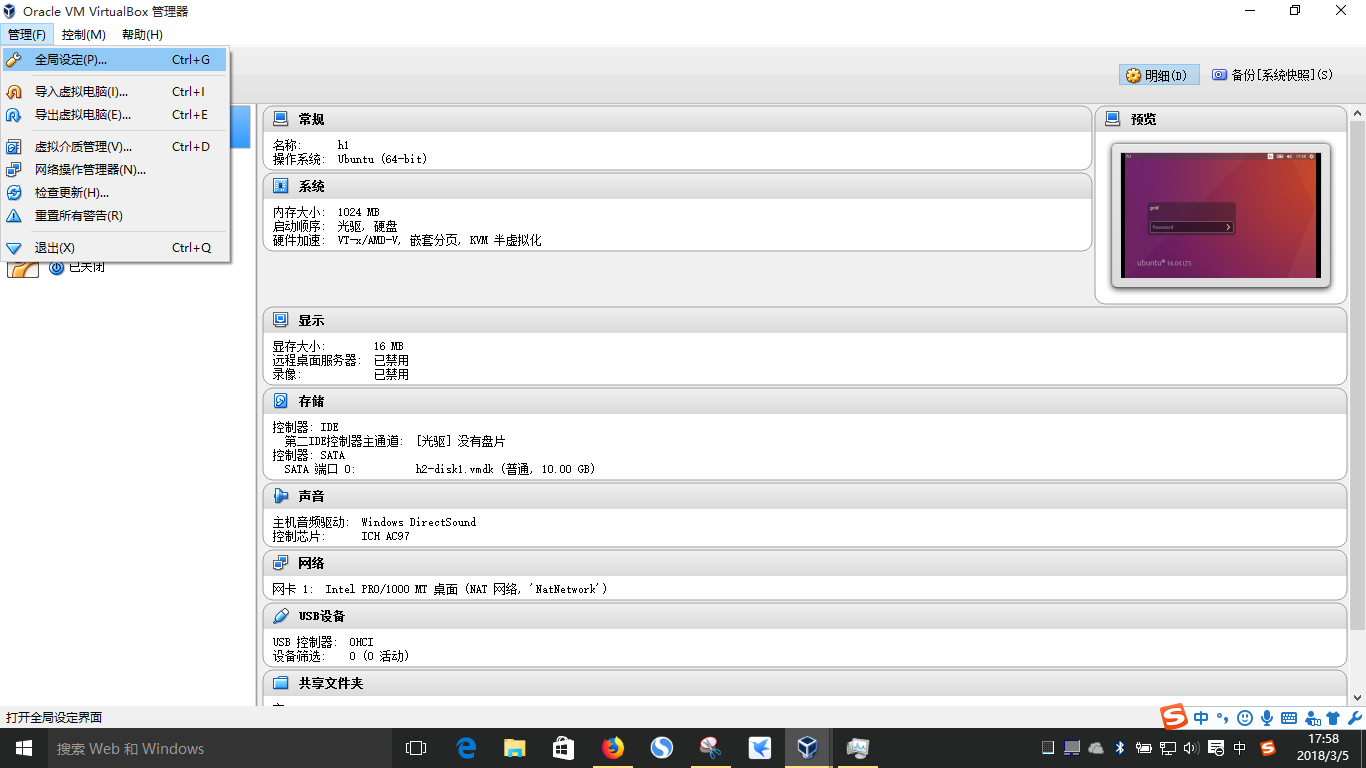
新建一个NAT网络,并且对其进行修改。
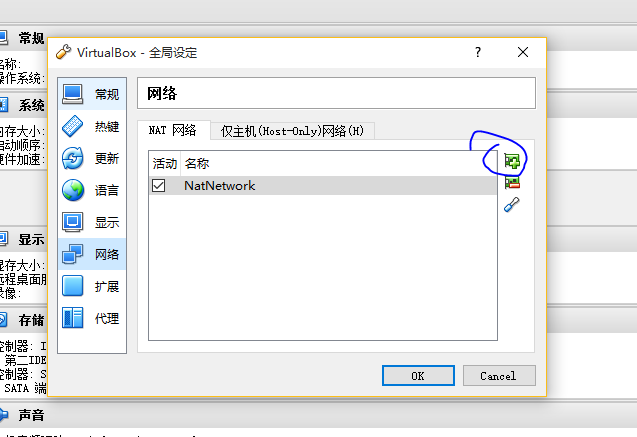
如果是下图的格式则保存。
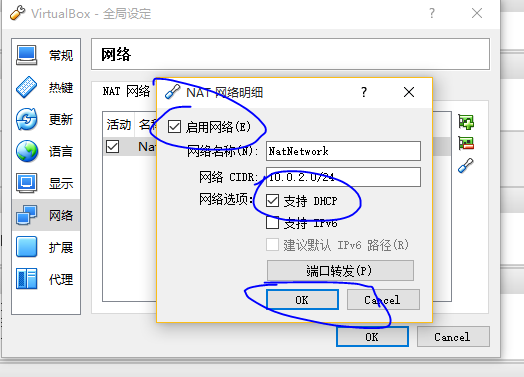
然后对每一台虚拟机进行“设置”,只启动一个网卡,nat模式,一定要注意勾选“允许虚拟电脑”,“接入网线”。
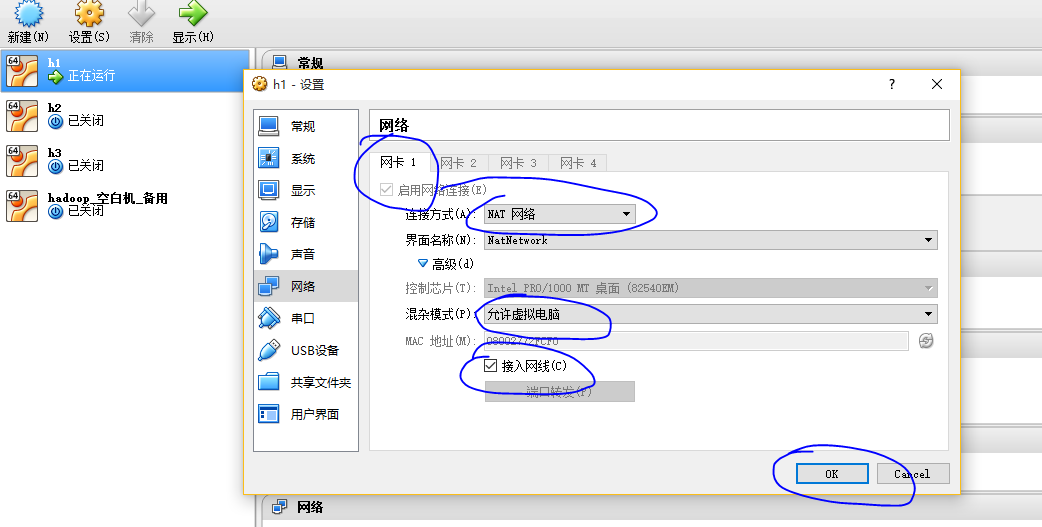
经过这样的操作我们设置好了网络,保证了每个虚拟主机和物理主机的连通,可以访问外部网络;所有虚拟主机可以相互ping通。
二、一步一步搭建hadoop集群
在对虚拟机进行复制之前,我们先对一台虚拟主机进行配置,使得这台虚拟机可以完成大部分三台电脑都需要完成的工作,之后,我们再进行复制,和适当的修改,这样才是最正确的选择,大大地减少了我们的工作量。
2.1、配置hosts文件
/etc/hosts文件是我们主机定义自己的名字的文件,比如我们定义主机名为“zyr”,那么我们使用ping zyr,就等同于ping localhost/127.0.0.1;在这里我们为了命名的统一和方便,对该文件进行配置。
2.1.1.ifconfig,通过该命令来知道当前主机的IP
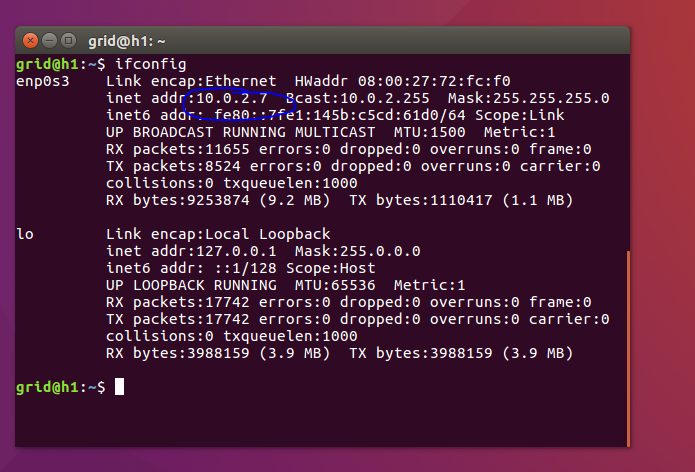
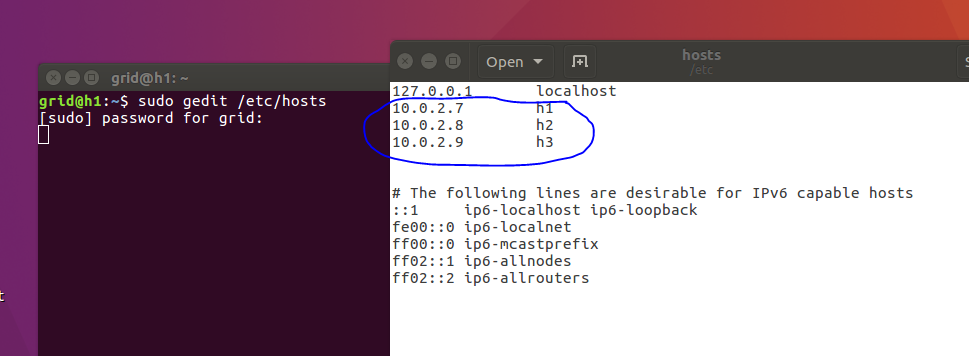
2.1.2、编辑hosts文件
sudo gedit /etc/hosts
注意,一定要按照下图的文本格式来写,要记得下面的网址不是凭空而来的,而是通过ifconfig得到的,起初我们只有一台主机,肯定不可能得到所有的IP,这个时候,我们可以稍微变动一下,保证IP不重复即可,在后面我们再来统一修改。在我们的项目中,h1作为Master,h2,h3作为slaver。
2.2、修改主机名
我们可以看到,h1,h2,h3不一定是我们最初的主机名字,这个时候我们可以通过修改配置文件/etc/hostname来永久性的改变主机名,但是修改之后,需要重启才能生效,在我们复制了之后要记得修改相应OS的名字,使得我们的配置一一对应。
sudo gedit /etc/hostname

2.3、创建用户和用户组
在这里我们要规范我们的命名和权限,因此有必要创建新的用户组和用户,创建之后,我们需要为用户进行授权。在Linux的shell命名中,我们经常可以看到“用户名@主机名”这样的字样,通过这个提示我们就能定位我们的位置,一个主机可以对应多个用户。
#创建hadoop用户组
sudo groupadd hadoop
#创建grid用户属于该组
sudo useradd -s /bin/bash -d /home/grid -m grid -g hadoop
#设置grid的密码并且登录
sudo passwd grid
#为/etc/sudoers添加写权限(默认已有)
chmod u+w /etc/sudoers
<权限范围>+<权限设置>:开启权限范围的文件或目录的该选项权限设置;
<权限范围>-<权限设置>:关闭权限范围的文件或目录的该选项权限设置;
<权限范围>=<权限设置>:指定权限范围的文件或目录的该选项权限设置;
其中权限范围为:
u: User,即文件或目录的拥有者;
g: Group,即文件或目录的所属群组;
o: Other,除了文件或目录拥有者或所属群组之外,其他用户皆属于这个范围;
a: All,即全部的用户,包含拥有者,所属群组以及其他用户;
其中权限设置为:
r: 读取权限,数字代号为“4”;
w: 写入权限,数字代号为“2”;
x: 执行或切换权限,数字代号为“1”;
-: 不具任何权限,数字代号为“0”;
s: 特殊功能说明:变更文件或目录的权限。
不指明权限范围时默认为All所有人.
vi /etc/sudoers
#找到 root ALL=(ALL) ALL,在该行下面添加
[用户名,比如grid] ALL=(ALL) ALL
#登录该用户
su grid
2.4、更新系统软件包,安装vim,ssh
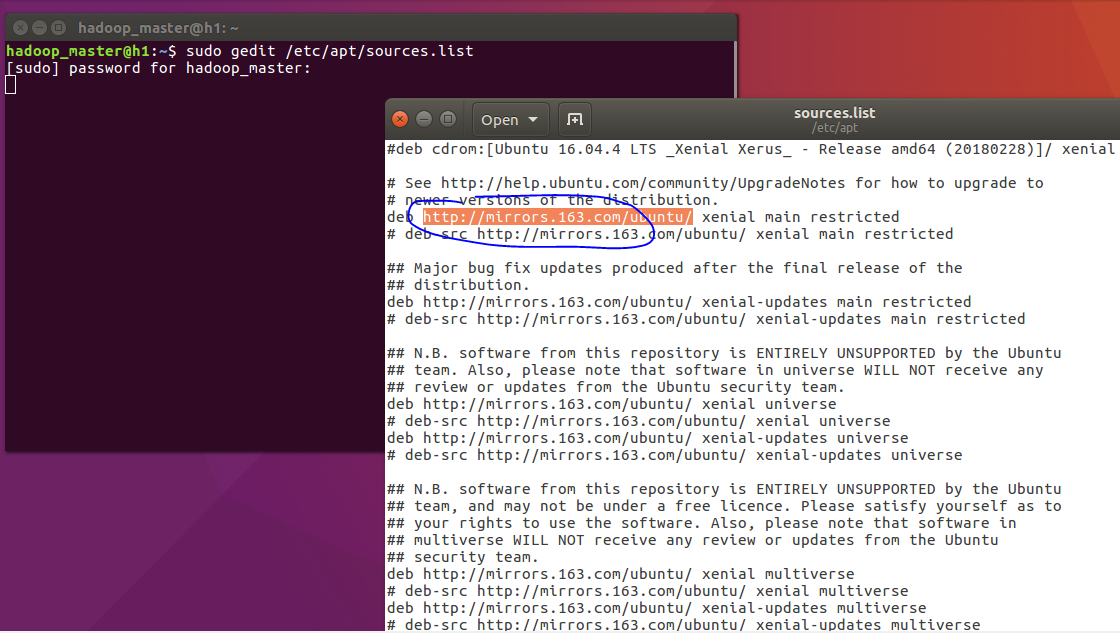
这个方法,和我的上一篇文章相同,在此就不赘述了,在更新之后,我们安装vim,ssh。在这里要提一下的是,我使用真机安装的Ubuntu16.04进行更新和软件包的安装没有问题,下载的源,即source list是来自国外的,可是将Ubuntu16.04装到虚拟机中,竟然不能下载了,一直卡在了连接的地方,而系统可以连接到外网,并且速度很快,这个问题我也不知道原因,不过解决办法还是一样的,我打开/etc/apt/source.list将其中的网址替换成了163的镜像,这样就好了,由此可以看出,应该是在虚拟主机中访问不了源中的网址,将网址放到浏览器上,果然如此。
2.5、安装JAVA
hadoop是用java写的,需要jvm来解析和执行。在这里,我们使用openjdk来安装,或者oracle来安装都可以,使用前者,请看我的《在Ubuntu Kylin15.04中配置Hadoop单机/伪分布式系统经验分享》,后者请看《在Ubuntu16.04.4上安装jdk》。这里主要说一下版本的问题,我们的hadoop使用的是稳定的2.9.0版本,这点在上篇文章(这里不加说明,指的是《在Ubuntu Kylin15.04中配置Hadoop单机/伪分布式系统经验分享》)已经描述得很详细,而我们上次是用的是openjdk7,其实对于hadoop2.9.0,我们使用openjdk8也是可以的(此处笔者使用),甚至我们使用oracle官方的1.7和1.8都是没问题的,笔者亲测有用。具体的安装步骤和方法在这里不再赘述,安装之后记得检验是否安装成功。
2.6、安装Hadoop
这里的安装方法和上一篇一样,主要是配置的问题,当我们将hadoop解压之后就可以直接使用了,修改hadoop目录权限,最好配置一下hadoop的环境变量,这种方式是单机模式,在这里我们将hadoop安装到用户的目录之下,并且重命名为hadoop,修改该文件的权限,属于我们上面定义的用户和组,这样权限就很明确。这里解释一下用户的目录,当我们新建一个用户的时候,都会产生一个目录,这里面有相应的文档、图片等目录,我们直接在这里面存放hadoop文件夹。非人为情况下,看/home文件下的文件夹就可以知道用多少个用户。比如在这里,我应该放在/home/grid目录之下,登录到grid用户中,使用pwd命令也可以看到~对应的确实是该目录。

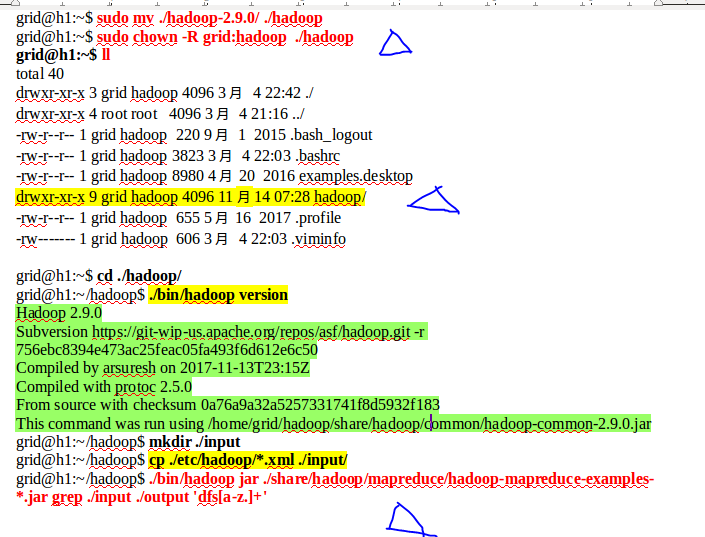
在单机模式下我们测试一下运行的结果,从而判断程序是否正常工作,java和hadoop的版本是否兼容。
接下来是具体的配置了,一共需要配置五个文件(都在hadoop目录下的./etc/hadoop/下面,slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml ),这样可以构成yarn的环境,如果配置三个,则为以前的MapReduce环境,我们一步一步来:
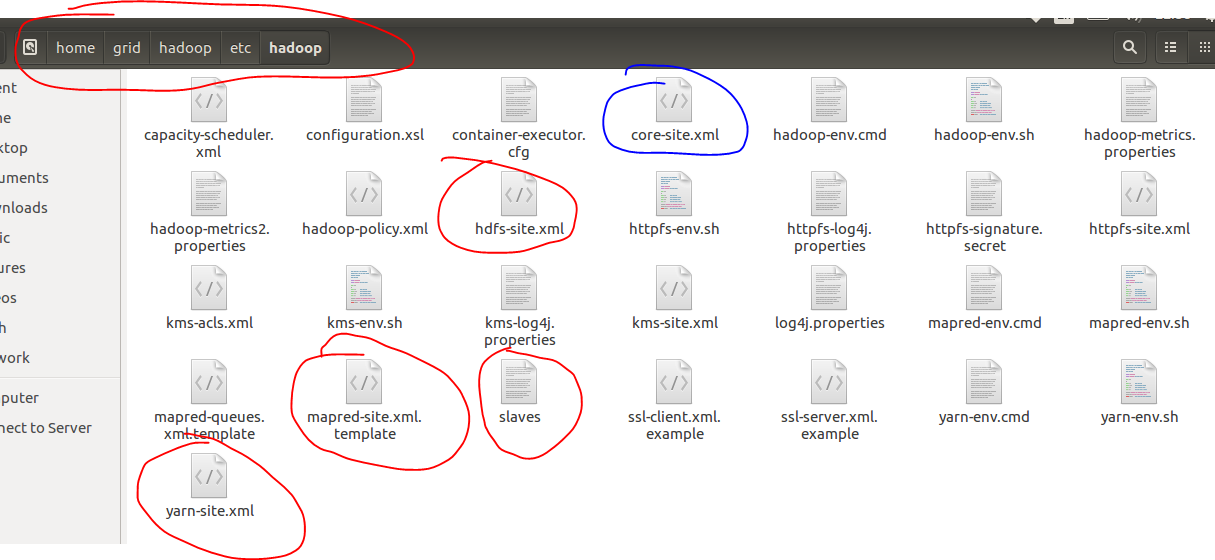
2.6.1、配置slaves文件
按行将作为slave的执行DataNode任务的主机写进去,这样hadoop就会自动查询了,通过我们上面配置的hosts就能找到。我们在这里填入h2和h3,如下图所示。
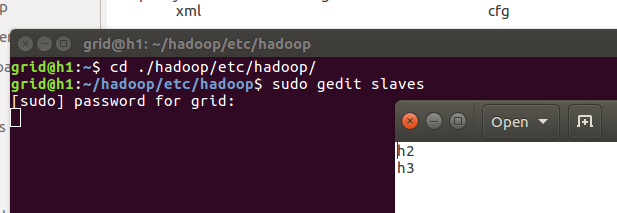
2.6.2、配置core-site.xml文件
在配置文件中加入如下字段,注意修改成相应的主机名和安装文件名。
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://h1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/grid/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>
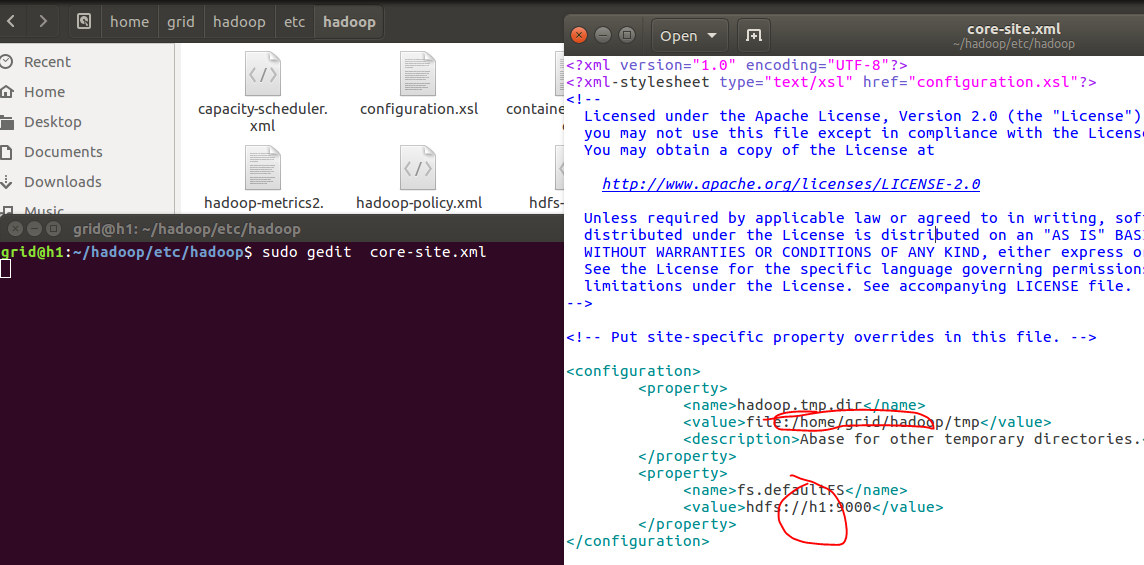
2.6.3、配置hdfs-site.xml文件
注意修改主机名和安装目录,在这里我们使用两台slave机器运行DataNode,因此dfs.replication为2.
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>h1:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/grid/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/grid/hadoop/tmp/dfs/data</value>
</property>
</configuration>
2.7、暂时运行一下集群hadoop
2.7.1、复制出两台新的虚拟机
到这里我们先告一段落,因为下面的配置已经涉及到了yarn的配置了,我们先测试一下我们的程序再说。至今为止,我们一直使用的是一台虚拟机来配制的,下面我们已经完成了基本的配置,可以进行复制了。在复制之前,我们需要清理一下我们的/home/grid/hadoop/tmp目录和/home/grid/hadoop/logs,因为我们之前运行过程序,这里面已经有文件了,如果不清理,有可能运行出错。
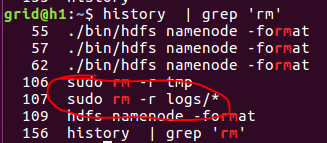
开始复制虚拟机,首先关闭我们要复制的机器,然后右键(ctrl+o)点击复制,选择重新生成IP,完全复制。接下来我们等复制完成即可。进行两次复制,我们就有了两台新的虚拟机。
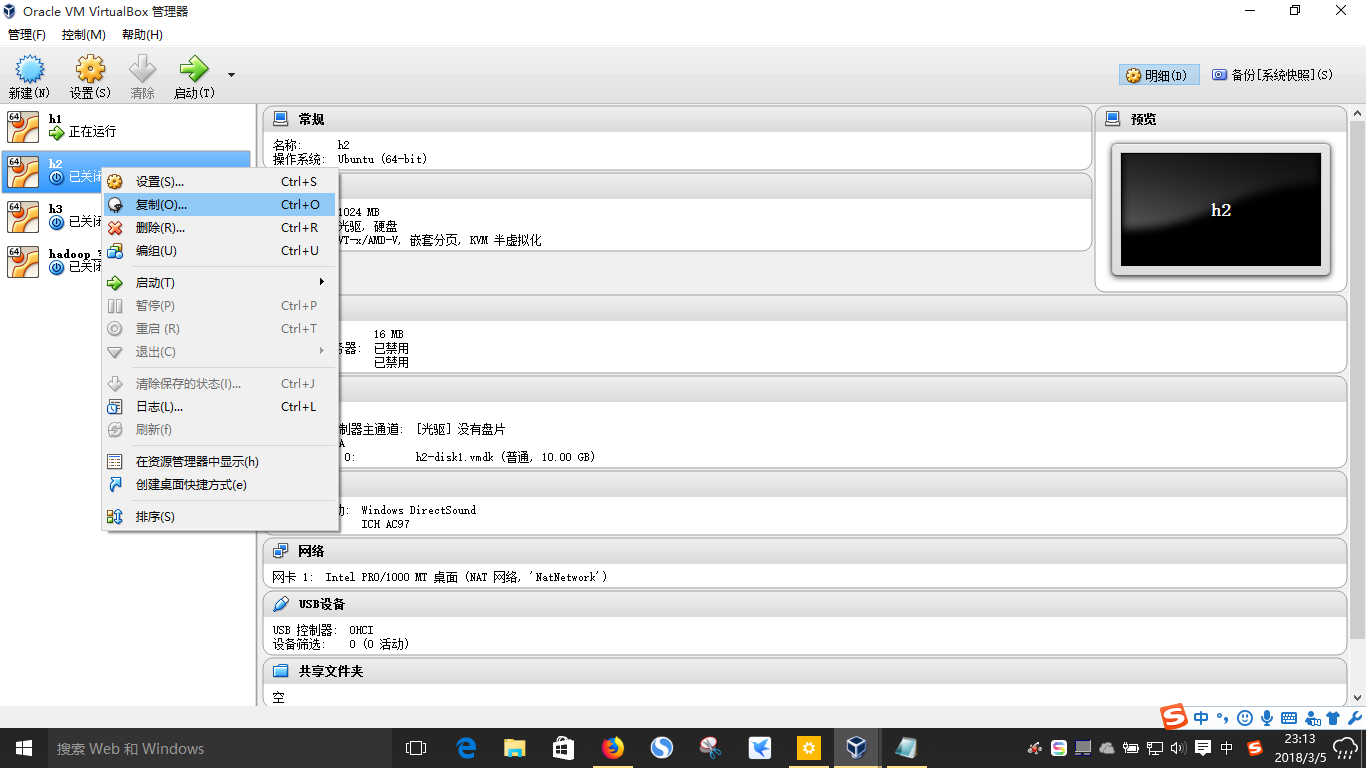
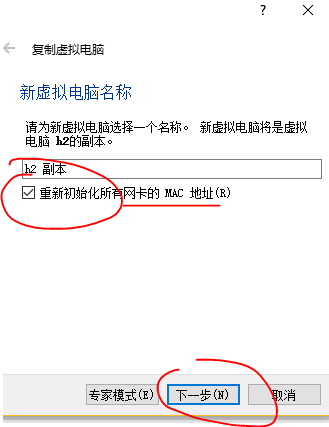
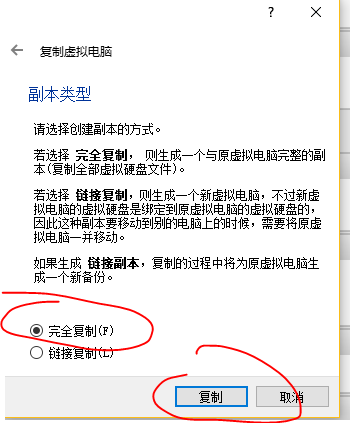
2.7.2、三台虚拟机进行SSH配置
2.7.2.1、修改hosts和hostname文件
现在进行SSH配置是最合适的了,我们已经有了三台虚拟机,并且知道了各自的IP,但是因为复制的原因,我们需要修改复制出的两台主机的主机名,这个也很简单,对/etc/hostname进行修改,之后重启即可,另外我们查看两台新的虚拟机的IP,将/etc/hosts文件进行修改,改成真正的IP地址,然后重启新的两台虚拟机。
2.7.2.2、进行SSH配置
重启之后,三台主机的名字分别为grid@h1,grid@h2,grid@h3,并且/etc/hosts文件修改的内容是一致的,然后我们测试使用ping命令,在h1中,ping h2看是否畅通,理论上三台主机已经可以互相ping通了。
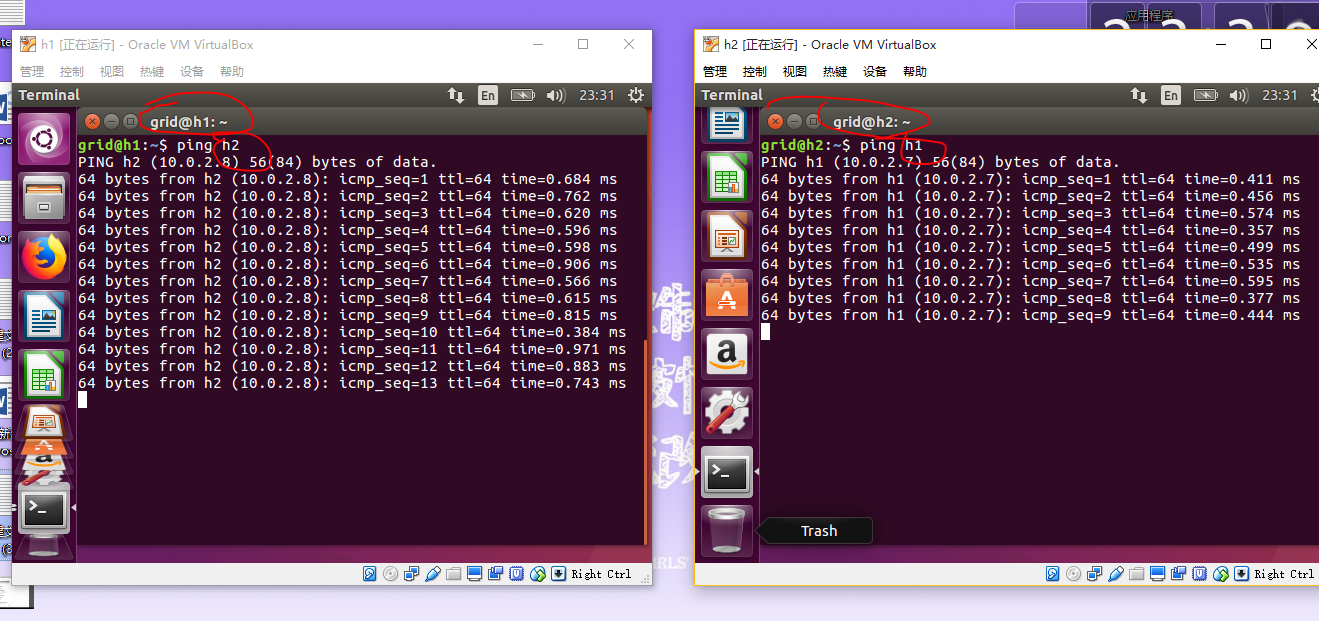
之后我们对h1进行配置,这里也可以用dsa算法。
###########h1################# sudo apt-get install ssh cd ~/.ssh/ ssh-keygen -t rsa cat ./id_rsa.pub >> ./authorized_keys ssh localhost
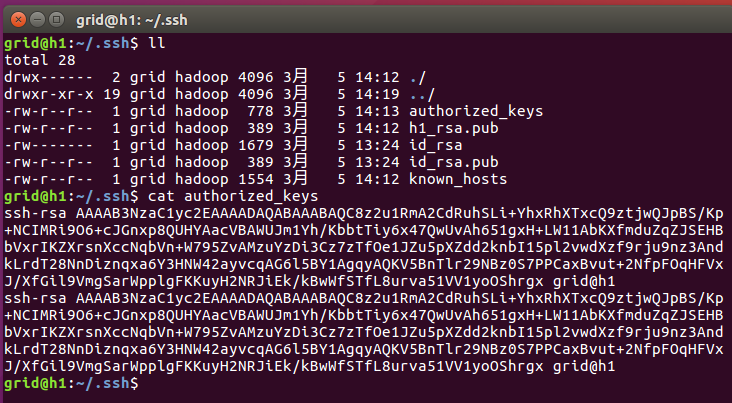
对h2进行配置,这里要特别注意后面两句,这里是通过SCP命令将h1中的公钥传递到h2中,然后让h2信任h1,之后再进入h1中使用ssh h2,就可以发现不用输入密码就可以登录了,这点非常重要,可以使得hadoop在各个集群中互相信任,协同工作。
###########h2################# sudo apt-get install ssh cd ~/.ssh/ ssh-keygen -t rsa cat ./id_rsa.pub >> ./authorized_keys ssh localhost scp grid@h1:~/.ssh/id_rsa.pub ~/.ssh/h1_rsa.pub cat ~/.ssh/h1_rsa.pub >> ~/.ssh/authorized_keys
同样的h3同h2,依旧要信任h1,通过h1登录h3来验证。
###########h3################# sudo apt-get install ssh cd ~/.ssh/ ssh-keygen -t rsa cat ./id_rsa.pub >> ./authorized_keys ssh localhost scp grid@h1:~/.ssh/id_rsa.pub ~/.ssh/h1_rsa.pub cat ~/.ssh/h1_rsa.pub >> ~/.ssh/authorized_keys
完成了这些,还要进行最后的一步信任,那就是h1自己信任自己,其实是h1中的namenode信任jobtracker,理论上两者可以在不同的机器上运行,同样使用SCP来配置。
###########h1#################
scp grid@h1:~/.ssh/id_rsa.pub ~/.ssh/h1_rsa.pub cat ~/.ssh/h1_rsa.pub >> ~/.ssh/authorized_keys
经过了上面的配置,我们使得每一台虚拟机各自信任自己;主节点被所有从节点信任;主节点中的namenode信任jobtracker。大致的层次结构如下所示。
2.7.3、无YRAN时测试
经过上面的操作,我们确保了每台虚拟主机中的hadoop文件完全一致,每台主机的用户名一致,hadoop文件的存放一致,环境也一致,互相可以通信,无需秘钥,这样我们就可以测试了。
首先在h1节点上,我们执行namenode的格式化,这里我们已经配置了环境变量。
hdfs namenode -format
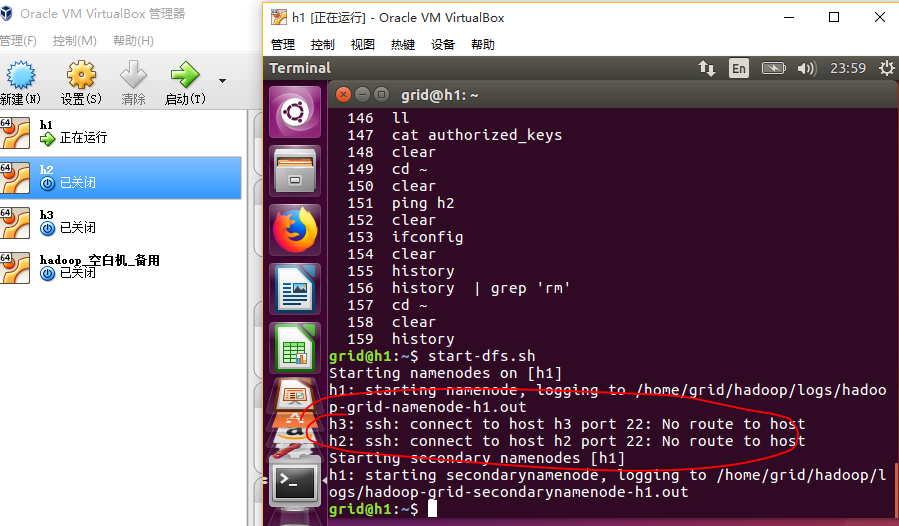
成功之后我们开启hdfs集群,下图是只打开一个虚拟机的效果,可以看到namenode和secondarynamenode在h1上就开启了,而h2,h3没打开所以没开启。
start-dfs.sh
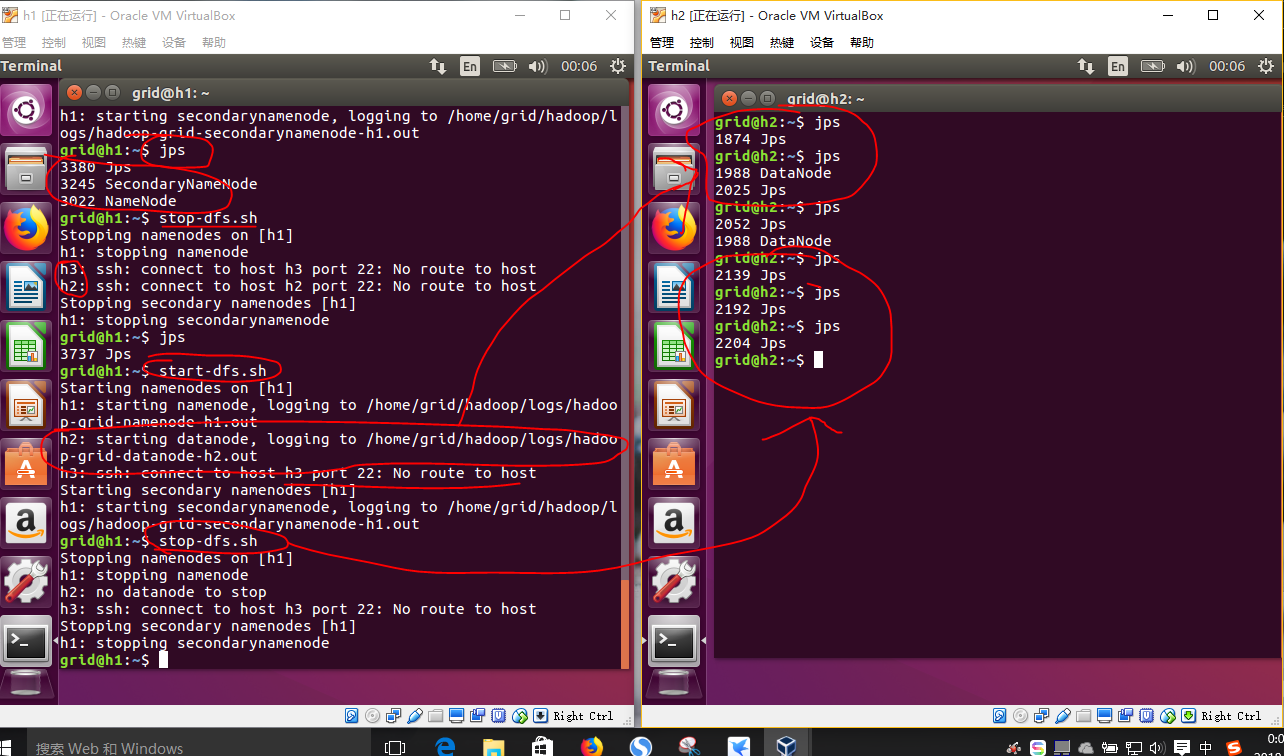
接着我们打开h2,关闭再运行一次,可以看到有意思的现象,当h2没打开时,h1找不到,当h2打开时,h1启动hdfs,找到了h2,就分配了DataNode,h3此时仍没打开,就不可达,当h1关闭dfs的时候,h2的DataNode也消失了,同时从日志里面也能看到。
接着,我们启动hdfs,并且运行一个任务。
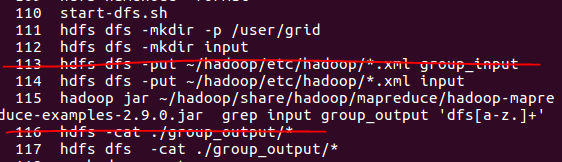
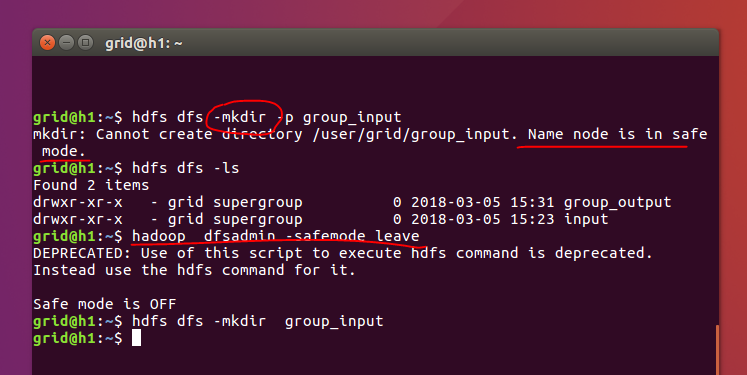
如果提示处在安全模式,我们使用下面的命令来离开。
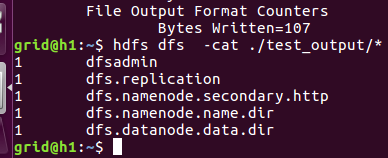
hadoop dfsadmin -safemode leave
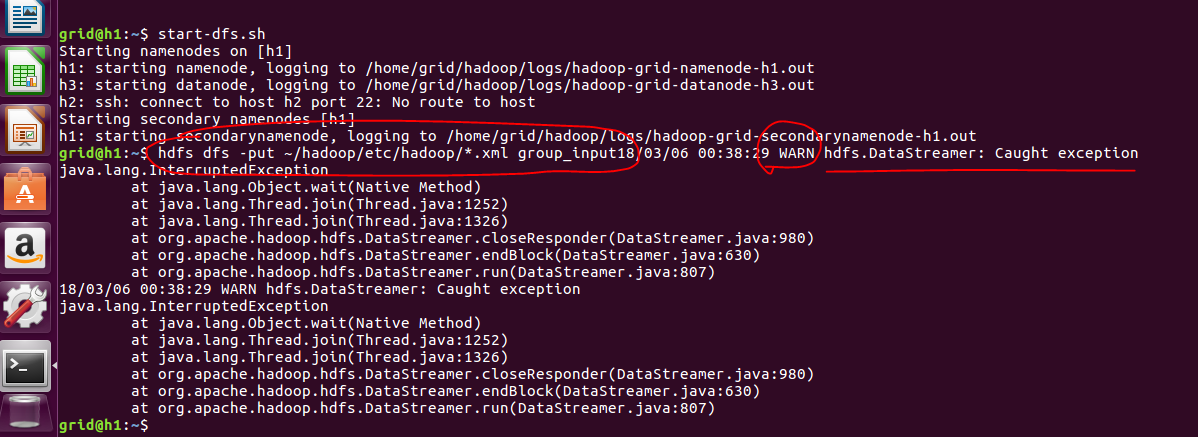
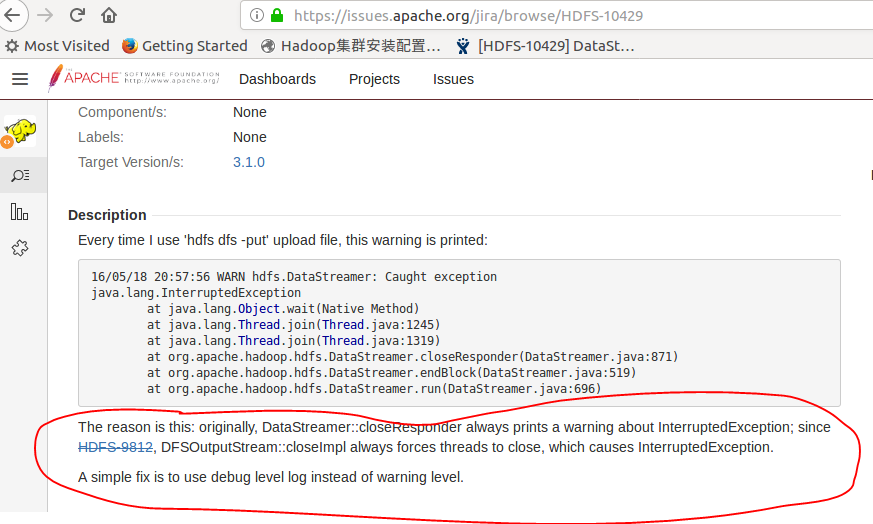
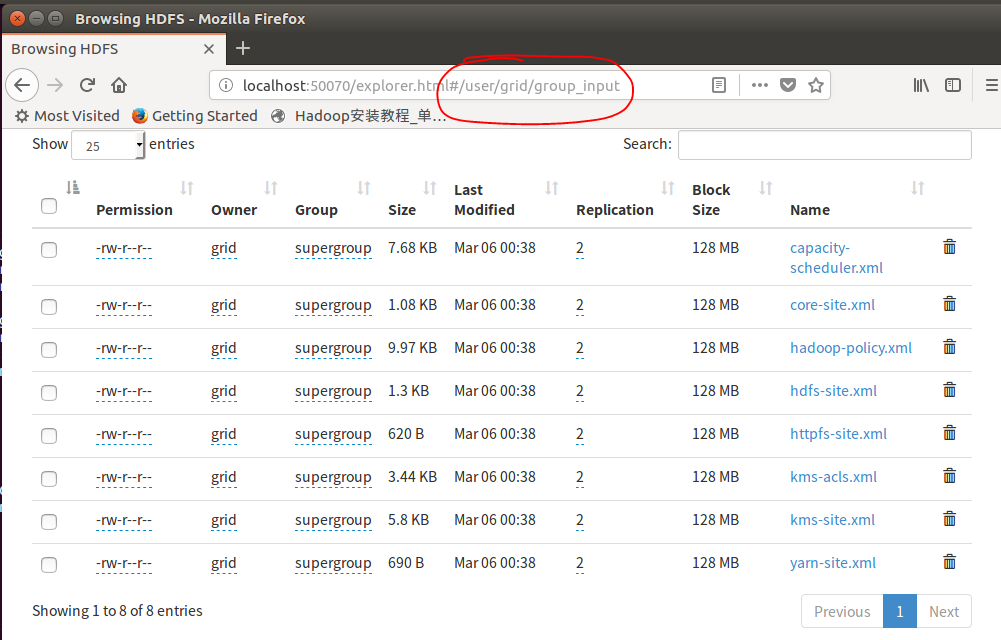
接着,我们将文件放上去,这个时候出现异常,提示有中断发生的警告,我们直接忽略即可,为了验证,我们打开网络localhost:50070发现文件已经上传成功,这个异常在网上可以找到详细的解释,再次不再赘述,最简单的方式是将警报级别调成错误级别的,这样就不会报出警告了。
上传成功:
执行样例程序,在两台虚拟机上运行:

查看执行结果,程序运行成功!我们真正实现了一次几乎在真机上的运行效果。
这里要说明一点,因为我的计算机配置的问题,无法同时启动三台虚拟机,因此采用的两台机器测试的,当时我开的是h1,h3运行了格式化namenode的程序,结果因为没开h2,就导致了h2缺少了一些配置,结果我开h1,h2来运行的时候,就出现了错误,h2在打开之后马上DataNode就自动关闭了,非常的奇怪,究其原因就是没有同时和h1中的namenode进行格式化,缺少了tmp里面的一些文件,在这里我开h1,h3就没这个问题,更加证实了这点。
2.8、真正使用YARN运行hadoop集群
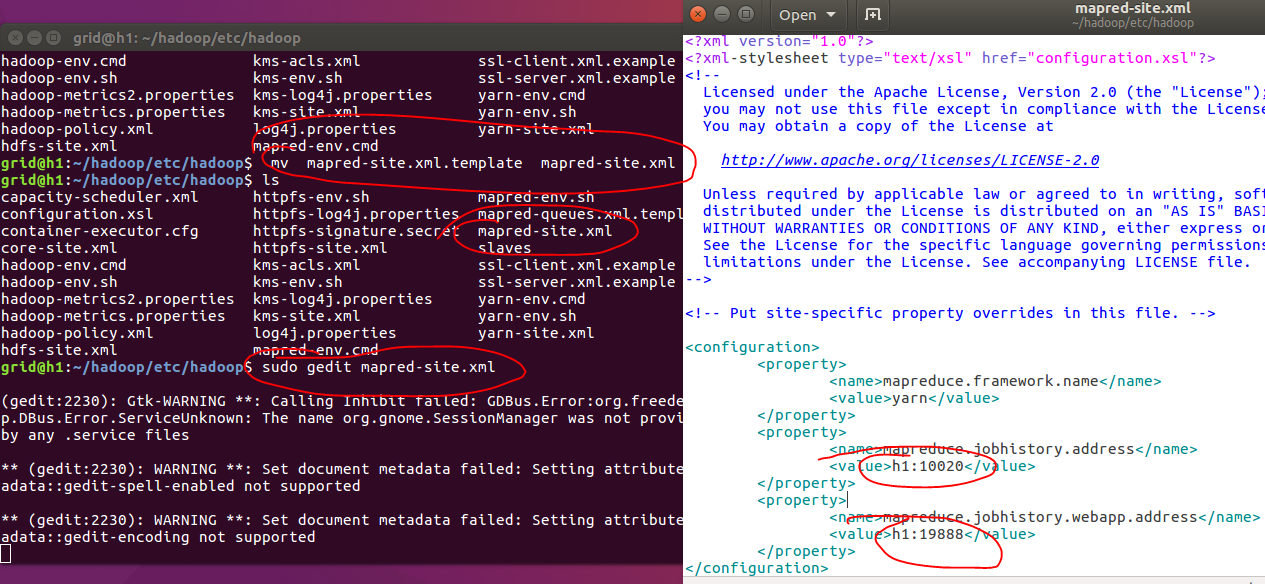
2.8.1、配置mapred-site.xml文件
我们继续进行配置,同样的在/home/grid/hadoop/etc/hadoop/文件夹下面找到并编辑文件mapred-site.xml.template,将该文件重命名为mapred-site.xml,这是因为一旦重命名为该文件,系统将检查并执行里面的属性,从而可以启动yarn。需要注意系统中最好不要同时存在mapred-site.xml.template和mapred-site.xml,不然可能出错。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>h1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>h1:19888</value>
</property>
</configuration>
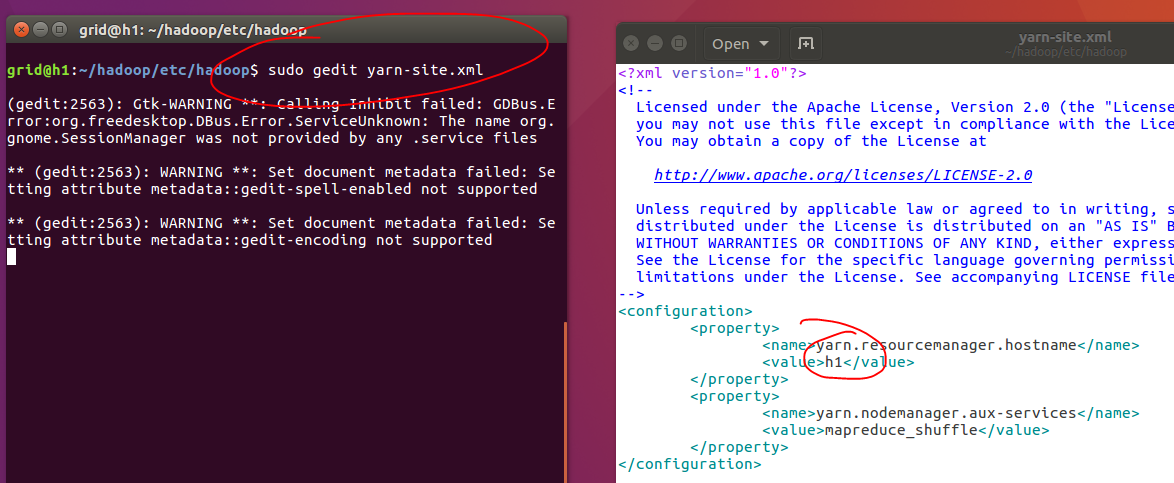
2.8.2、配置yarn-site.xml文件
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>h1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
之后我们需要将这两个修改的文件同时也在h2,h3上修改,或者我们也可以用SCP命令:
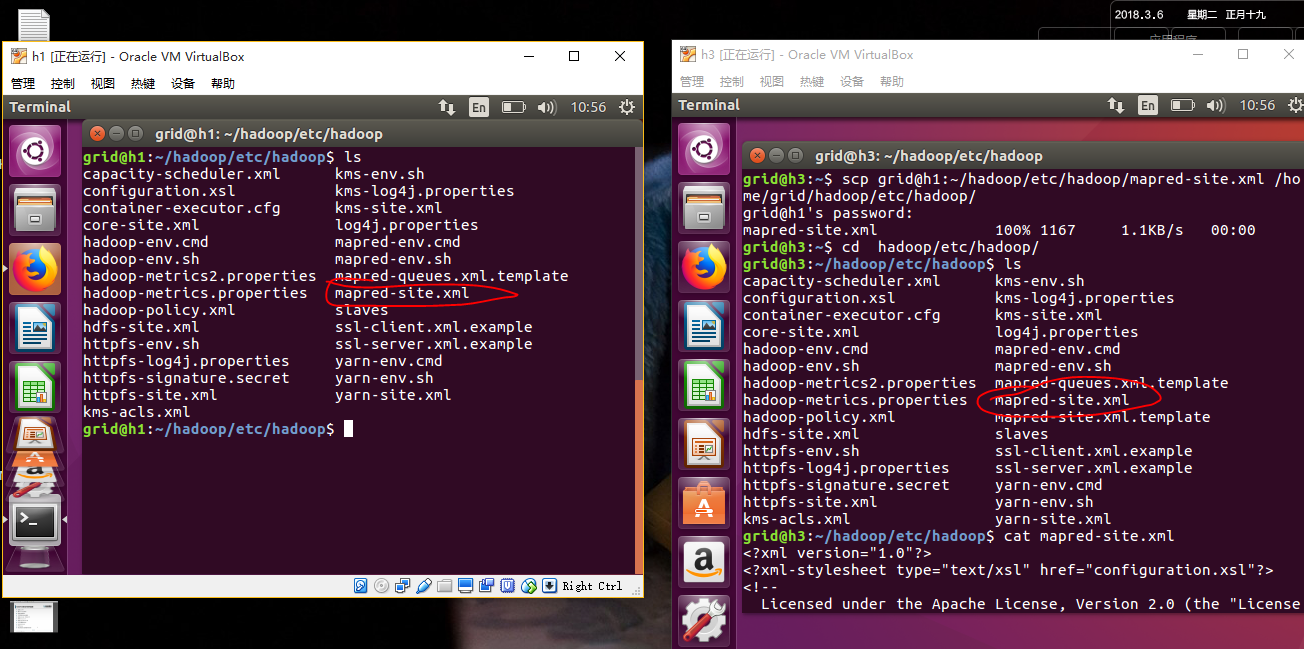
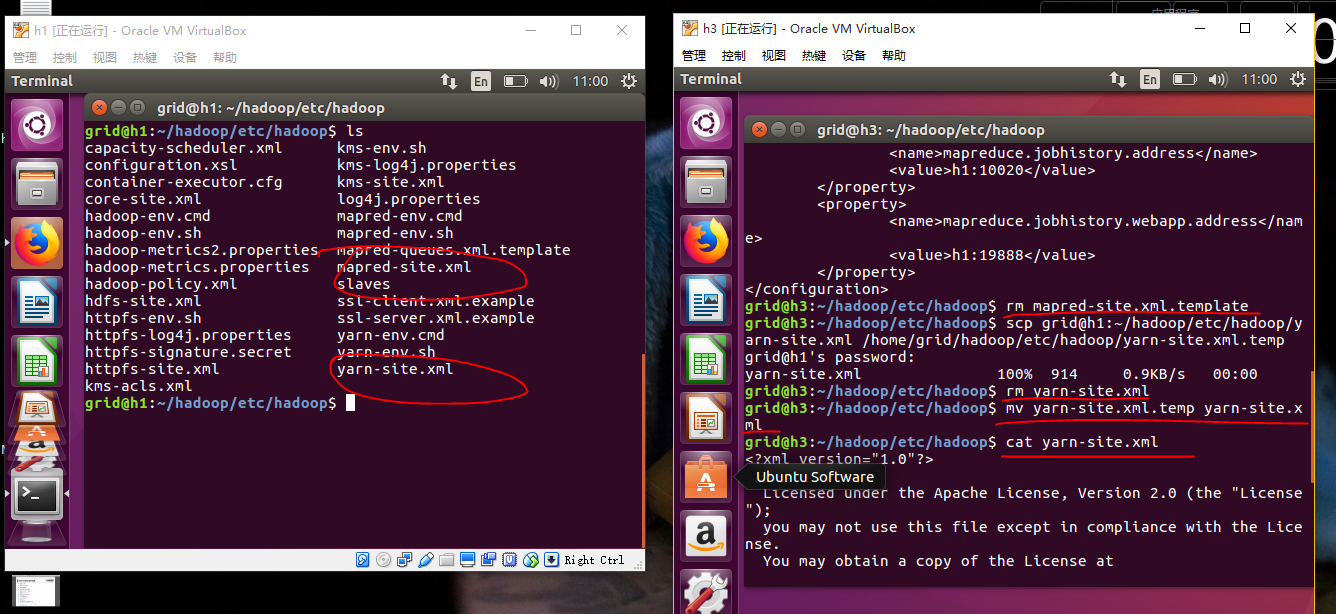
最终让我们开启dfs和yarn以及历史服务器,在h1上执行:
start-dfs.sh start-yarn.sh mr-jobhistory-daemon.sh start historyserver
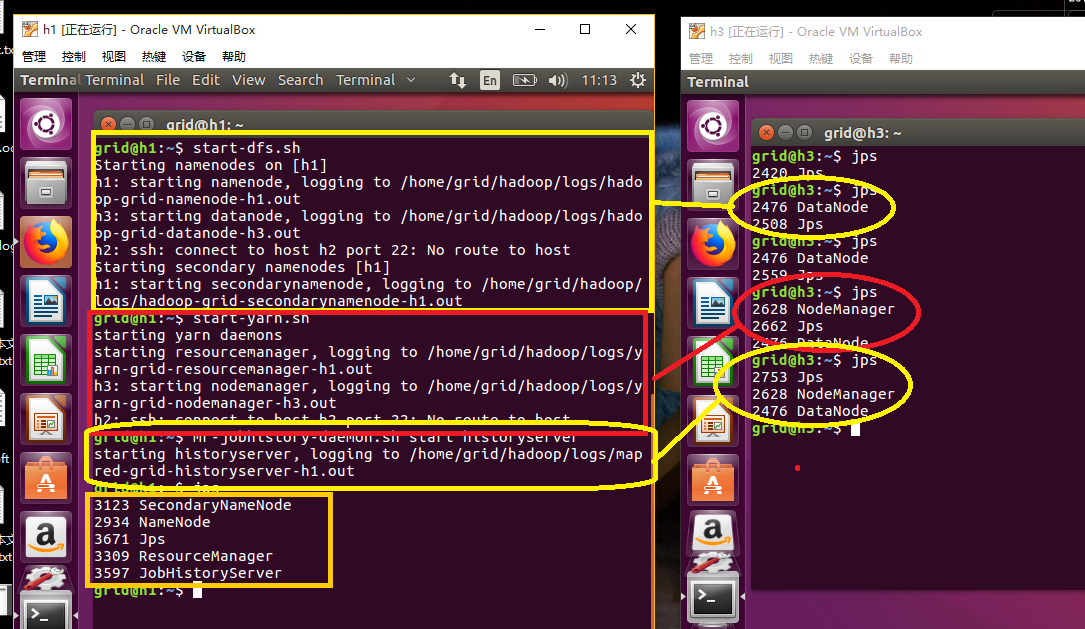
hadoop成功启动,同时带动h3启动,然后我们还是用grep正则表达式来验证yarn程序,这里因为hdfs中已经有文件了,我们直接使用input作为输入,输入自定义。
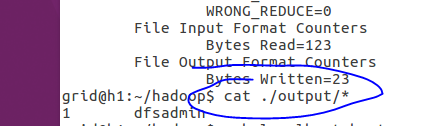
hadoop jar ~/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input yarn_output 'dfs[a-z.]+'
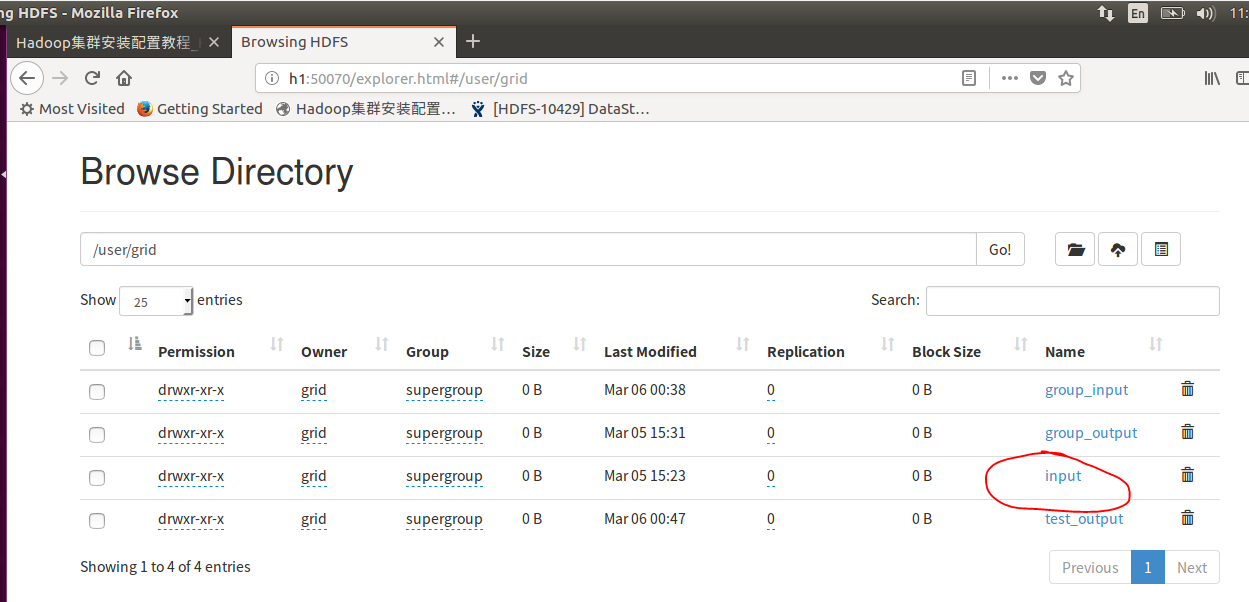

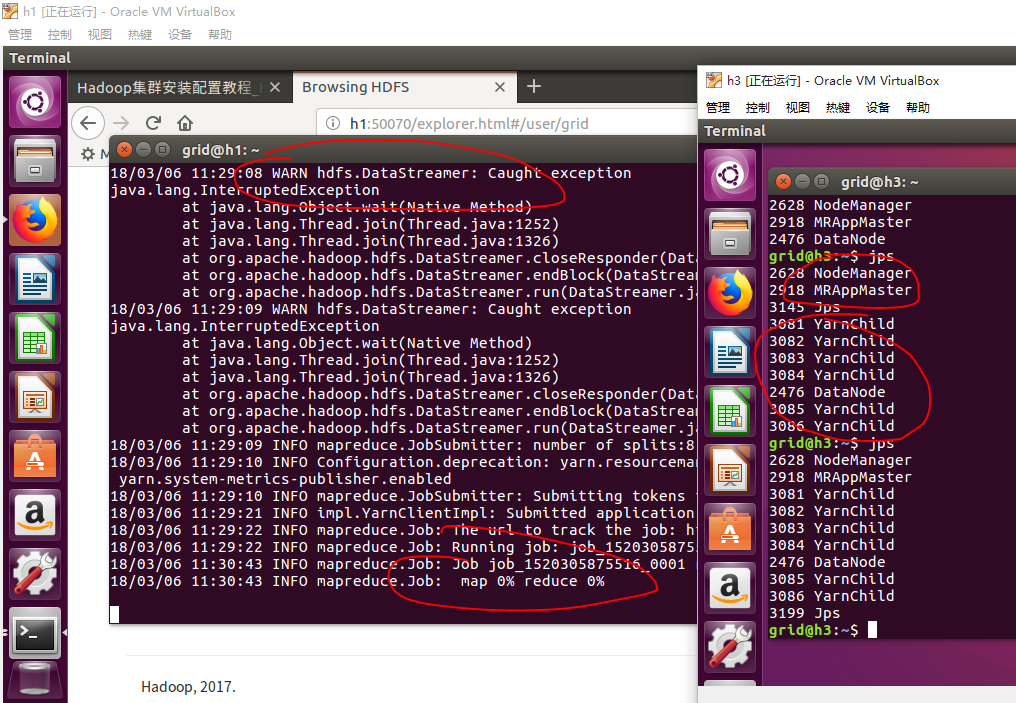
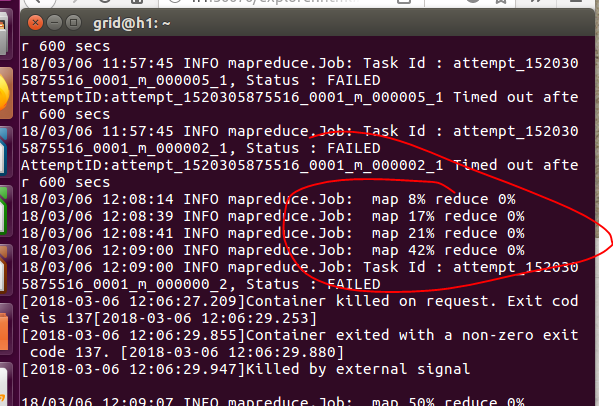
运行过程中,我们可以看到系统启动yarn来执行,h3的jps进程也在不断地变化着,可是毕竟是一台电脑执行的,速度还是非常慢,不断地卡着,最重要的是yarn的执行方式是和计算机台数多达上千台的情况,在我们的电脑上还是没有最初始的MapReduce执行的快。在运行了一段时间之后,YARN竟然运行不下去了,两个虚拟机都给卡住了,我关闭一个虚拟机,才能看到h1的信息,看来除非是在真的集群上,不然的话,我们的yarn还是少用为好。
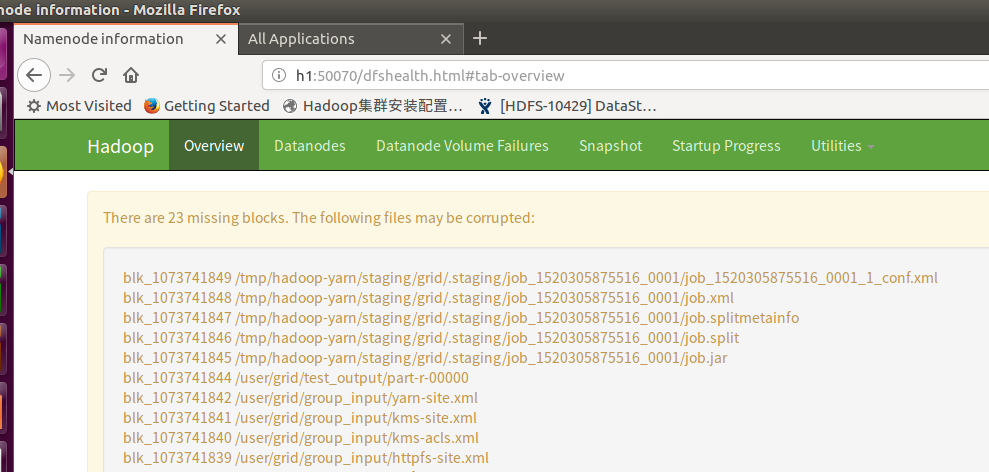
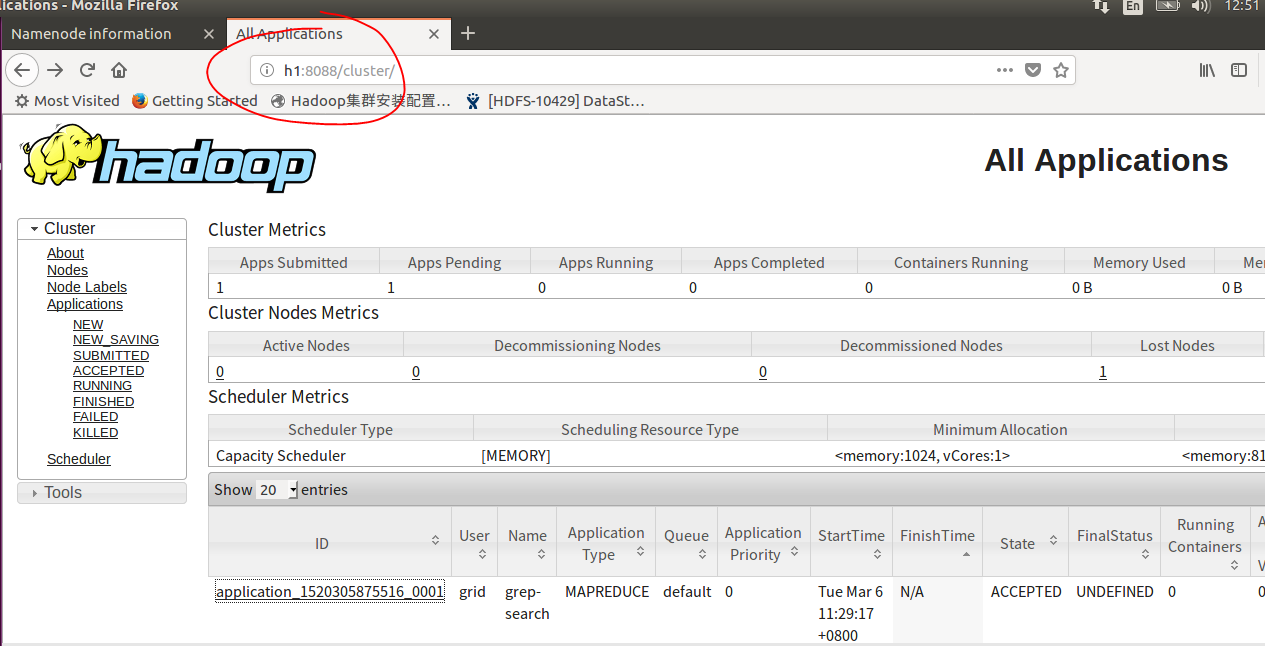
当然我们也可以使用h1:50070,或者h1:8088/cluster来查看运行的情况以及日志。
三、项目总结
至此,我们完成了hadoop集群的搭建和运行,其中的每一步,每一个细节我都做了很好的说明,相信大家按照我的做法肯定能够搭建自己的hadoop集群的,其实真正的明白了之后也没有什么难度的,最重要的是我们需要让这些主机相互通信,之后就是在单机上安装差不多的思想,后期如果有时间的话我可以写一下使用docker来搭建hadoop集群的方法,网络是一个资源共享,知识共建的平台,在不断地写出自己想写的文章的同时,我的思想、理解甚至是水平也在不断地加深着,进步着,希望大家能有所收益。
参考资料:
http://www.powerxing.com/install-hadoop-cluster/
http://blog.csdn.net/henni_719/article/details/77746317
您的支持,是我写出高质量博文的动力!
沉淀,再出发——手把手教你使用VirtualBox搭建含有三个虚拟节点的Hadoop集群的更多相关文章
- 沉淀,再出发——在Hadoop集群的基础上搭建Spark
在Hadoop集群的基础上搭建Spark 一.环境准备 在搭建Spark环境之前必须搭建Hadoop平台,尽管以前的一些博客上说在单机的环境下使用本地FS不用搭建Hadoop集群,可是在新版spark ...
- 沉淀再出发:mongodb的使用
沉淀再出发:mongodb的使用 一.前言 这是一篇很早就想写却一直到了现在才写的文章.作为NoSQL(not only sql)中出色的一种数据库,MongoDB的作用是非常大的,这种文档型数据库, ...
- 沉淀再出发:用python画各种图表
沉淀再出发:用python画各种图表 一.前言 最近需要用python来做一些统计和画图,因此做一些笔记. 二.python画各种图表 2.1.使用turtle来画图 import turtle as ...
- 沉淀再出发:在python3中导入自定义的包
沉淀再出发:在python3中导入自定义的包 一.前言 在python中如果要使用自己的定义的包,还是有一些需要注意的事项的,这里简单记录一下. 二.在python3中导入自定义的包 2.1.什么是模 ...
- 沉淀再出发:java中的equals()辨析
沉淀再出发:java中的equals()辨析 一.前言 关于java中的equals,我们可能非常奇怪,在Object中定义了这个函数,其他的很多类中都重载了它,导致了我们对于辨析其中的内涵有了混淆, ...
- 沉淀再出发:web服务器和应用服务器之间的区别和联系
沉淀再出发:web服务器和应用服务器之间的区别和联系 一.前言 关于后端,我们一般有三种服务器(当然还有文件服务器等),Web服务器,应用程序服务器和数据库服务器,其中前面两个的概念已经非常模糊了,但 ...
- 沉淀再出发:jetty的架构和本质
沉淀再出发:jetty的架构和本质 一.前言 我们在使用Tomcat的时候,总是会想到jetty,这两者的合理选用是和我们项目的类型和大小息息相关的,Tomcat属于比较重量级的容器,通过很多的容器层 ...
- 沉淀再出发:dubbo的基本原理和应用实例
沉淀再出发:dubbo的基本原理和应用实例 一.前言 阿里开发的dubbo作为服务治理的工具,在分布式开发中有着重要的意义,这里我们主要专注于dubbo的架构,基本原理以及在Windows下面开发出来 ...
- 沉淀再出发:OpenStack初探
沉淀再出发:OpenStack初探 一.前言 OpenStack是IaaS的一种平台,通过各种虚拟化来提供服务.我们主要看一下OpenStack的基本概念和相应的使用方式. 二.OpenStack的框 ...
随机推荐
- jQuery事件 (jQuery实现图片轮播)
jQuery事件按执行时间,主要分为两种,第一种是在网页加载完执行,第二种绑定在元素中,由访问者某些行为触发. $(document).ready(function(){ //事件 }); $(&qu ...
- 嵌套for in循环组合cat方式文件中包含空格问题
关于循环嵌套使用for循环的空格问题 原创不易,转载请注明 需求: 现有两个功文件,需要将文件拼接 [root@localhost ~]# cat name 111 222 223 333 444 5 ...
- 常用Nagios配置命令
cd /usr/local/nagios/etc vim nagios.cfg /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios ...
- C# 类型基础(上)
C#类型都派生自System.Object 祖先的优良传统:Object的公共方法 Equals: 对象的同一性而非相等性 GetHashCode:返回对象的值的哈希码 ToString:默认返回类型 ...
- Tomcat修改端口号(7.0 version)
目的:有时端口号可能其他服务占用,就需要修改一下Tomcat的端口号,避免冲突. 自我总结,有什么需要改正的地方,请大家补充,感激不尽! 找到Tomcat的的配置文件server.xml 路径:%to ...
- 《.NET 设计规范》第 5 章:成员设计
<.NET 设计规范>第 5 章:成员设计 5.1 成员设计的通用规范 要尽量用描述性的参数名来说明在较短的重载中使用的默认值. 避免在重载中随意地改变参数的名字.如果两个重载中的某个参数 ...
- easyUI前后台分页代码实现
一.后台分页 (1)客户端代码: var dg = $('#table'); var opts = dg.datagrid('options'); var pager = dg.datagrid('g ...
- Hadoop学习笔记五
一.uber(u:ber)模式 MapReduce以Uber模式运行时,所有的map,reduce任务都在一个jvm中运行,对于小的mapreduce任务,uber模式的运行将更为高效. uber模式 ...
- WebService的学习
这篇文章不错,直接转了 http://blog.csdn.net/terryzero/article/details/5976638#comments
- CF798E. Mike and code of a permutation [拓扑排序 线段树]
CF798E. Mike and code of a permutation 题意: 排列p,编码了一个序列a.对于每个i,找到第一个\(p_j > p_i\)并且未被标记的j,标记这个j并\( ...