JAVA线程池原理详解(1)
线程池的优点
1、线程是稀缺资源,使用线程池可以减少创建和销毁线程的次数,每个工作线程都可以重复使用。
2、可以根据系统的承受能力,调整线程池中工作线程的数量,防止因为消耗过多内存导致服务器崩溃。
线程池的创建
public ThreadPoolExecutor(
int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
RejectedExecutionHandler handler)corePoolSize:线程池核心线程数量
maximumPoolSize:线程池最大线程数量
keepAliverTime:当活跃线程数大于核心线程数时,空闲的多余线程最大存活时间
unit:存活时间的单位
workQueue:存放任务的队列
handler:超出线程范围和队列容量的任务的处理程序
线程池的实现原理
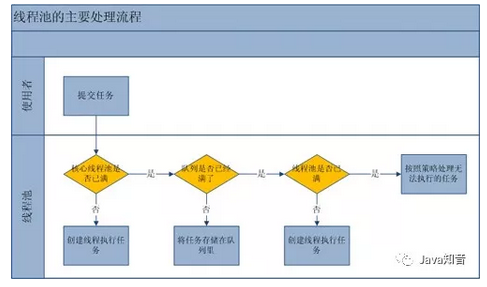
提交一个任务到线程池中,线程池的处理流程如下:
1、判断线程池里的核心线程是否都在执行任务,如果不是(核心线程空闲或者还有核心线程没有被创建)则创建一个新的工作线程来执行任务。如果核心线程都在执行任务,则进入下个流程。
2、线程池判断工作队列是否已满,如果工作队列没有满,则将新提交的任务存储在这个工作队列里。如果工作队列满了,则进入下个流程。
3、判断线程池里的线程是否都处于工作状态,如果没有,则创建一个新的工作线程来执行任务。如果已经满了,则交给饱和策略来处理这个任务。
线程池的源码解读
1、ThreadPoolExecutor的execute()方法
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
//如果线程数大于等于基本线程数或者线程创建失败,将任务加入队列
if (poolSize >= corePoolSize || !addIfUnderCorePoolSize(command)) {
//线程池处于运行状态并且加入队列成功
if (runState == RUNNING && workQueue.offer(command)) {
if (runState != RUNNING || poolSize == 0)
ensureQueuedTaskHandled(command);
}
//线程池不处于运行状态或者加入队列失败,则创建线程(创建的是非核心线程)
else if (!addIfUnderMaximumPoolSize(command))
//创建线程失败,则采取阻塞处理的方式
reject(command); // is shutdown or saturated
}
}2、创建线程的方法:addIfUnderCorePoolSize(command)
private boolean addIfUnderCorePoolSize(Runnable firstTask) {
Thread t = null;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
if (poolSize < corePoolSize && runState == RUNNING)
t = addThread(firstTask);
} finally {
mainLock.unlock();
}
if (t == null)
return false;
t.start();
return true;
}我们重点来看第7行:
private Thread addThread(Runnable firstTask) {
Worker w = new Worker(firstTask);
Thread t = threadFactory.newThread(w);
if (t != null) {
w.thread = t;
workers.add(w);
int nt = ++poolSize;
if (nt > largestPoolSize)
largestPoolSize = nt;
}
return t;
}这里将线程封装成工作线程worker,并放入工作线程组里,worker类的方法run方法:
public void run() {
try {
Runnable task = firstTask;
firstTask = null;
while (task != null || (task = getTask()) != null) {
runTask(task);
task = null;
}
} finally {
workerDone(this);
}
}worker在执行完任务后,还会通过getTask方法循环获取工作队里里的任务来执行。
我们通过一个程序来观察线程池的工作原理:
1、创建一个线程
public class ThreadPoolTest implements Runnable
{
@Override
public void run()
{
try
{
Thread.sleep(300);
}
catch (InterruptedException e)
{
e.printStackTrace();
}
}
}2、线程池循环运行16个线程:
public static void main(String[] args)
{
LinkedBlockingQueue<Runnable> queue =
new LinkedBlockingQueue<Runnable>(5);
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(5, 10, 60, TimeUnit.SECONDS, queue);
for (int i = 0; i < 16 ; i++)
{
threadPool.execute(
new Thread(new ThreadPoolTest(), "Thread".concat(i + "")));
System.out.println("线程池中活跃的线程数: " + threadPool.getPoolSize());
if (queue.size() > 0)
{
System.out.println("----------------队列中阻塞的线程数" + queue.size());
}
}
threadPool.shutdown();
}执行结果:
线程池中活跃的线程数: 1
线程池中活跃的线程数: 2
线程池中活跃的线程数: 3
线程池中活跃的线程数: 4
线程池中活跃的线程数: 5
线程池中活跃的线程数: 5
----------------队列中阻塞的线程数1
线程池中活跃的线程数: 5
----------------队列中阻塞的线程数2
线程池中活跃的线程数: 5
----------------队列中阻塞的线程数3
线程池中活跃的线程数: 5
----------------队列中阻塞的线程数4
线程池中活跃的线程数: 5
----------------队列中阻塞的线程数5
线程池中活跃的线程数: 6
----------------队列中阻塞的线程数5
线程池中活跃的线程数: 7
----------------队列中阻塞的线程数5
线程池中活跃的线程数: 8
----------------队列中阻塞的线程数5
线程池中活跃的线程数: 9
----------------队列中阻塞的线程数5
线程池中活跃的线程数: 10
----------------队列中阻塞的线程数5
Exception in thread "main" java.util.concurrent.RejectedExecutionException: Task Thread[Thread15,5,main] rejected from java.util.concurrent.ThreadPoolExecutor@232204a1[Running, pool size = 10, active threads = 10, queued tasks = 5, completed tasks = 0]
at java.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(ThreadPoolExecutor.java:2047)
at java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:823)
at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1369)
at test.ThreadTest.main(ThreadTest.java:17)从结果可以观察出:
创建的线程池具体配置为:核心线程数量为5个;全部线程数量为10个;工作队列的长度为5。
我们通过queue.size()的方法来获取工作队列中的任务数。
运行原理:
刚开始都是在创建新的线程,达到核心线程数量5个后,新的任务进来后不再创建新的线程,而是将任务加入工作队列,任务队列到达上线5个后,新的任务又会创建新的普通线程,直到达到线程池最大的线程数量10个,后面的任务则根据配置的饱和策略来处理。我们这里没有具体配置,使用的是默认的配置AbortPolicy:直接抛出异常。
当然,为了达到我需要的效果,上述线程处理的任务都是利用休眠导致线程没有释放!!
RejectedExecutionHandler:饱和策略
当队列和线程池都满了,说明线程池处于饱和状态,那么必须对新提交的任务采用一种特殊的策略来进行处理。这个策略默认配置是AbortPolicy,表示无法处理新的任务而抛出异常。JAVA提供了4中策略:
AbortPolicy:直接抛出异常
CallerRunsPolicy:只用调用所在的线程运行任务
DiscardOldestPolicy:丢弃队列里最近的一个任务,并执行当前任务。
DiscardPolicy:不处理,丢弃掉。
我们现在用第四种策略来处理上面的程序:
public static void main(String[] args)
{
LinkedBlockingQueue<Runnable> queue =
new LinkedBlockingQueue<Runnable>(3);
RejectedExecutionHandler handler = new ThreadPoolExecutor.DiscardPolicy();
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(2, 5, 60, TimeUnit.SECONDS, queue,handler);
for (int i = 0; i < 9 ; i++)
{
threadPool.execute(
new Thread(new ThreadPoolTest(), "Thread".concat(i + "")));
System.out.println("线程池中活跃的线程数: " + threadPool.getPoolSize());
if (queue.size() > 0)
{
System.out.println("----------------队列中阻塞的线程数" + queue.size());
}
}
threadPool.shutdown();
}执行结果
线程池中活跃的线程数: 1
线程池中活跃的线程数: 2
线程池中活跃的线程数: 2
----------------队列中阻塞的线程数1
线程池中活跃的线程数: 2
----------------队列中阻塞的线程数2
线程池中活跃的线程数: 2
----------------队列中阻塞的线程数3
线程池中活跃的线程数: 3
----------------队列中阻塞的线程数3
线程池中活跃的线程数: 4
----------------队列中阻塞的线程数3
线程池中活跃的线程数: 5
----------------队列中阻塞的线程数3
线程池中活跃的线程数: 5
----------------队列中阻塞的线程数3这里采用了丢弃策略后,就没有再抛出异常,而是直接丢弃。在某些重要的场景下,可以采用记录日志或者存储到数据库中,而不应该直接丢弃。
设置策略有两种方式:
第一种:
RejectedExecutionHandler handler = new ThreadPoolExecutor.DiscardPolicy();
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(2, 5, 60, TimeUnit.SECONDS, queue,handler);第二种:
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(2, 5, 60, TimeUnit.SECONDS, queue);
threadPool.setRejectedExecutionHandler(new ThreadPoolExecutJAVA线程池原理详解(1)的更多相关文章
- JAVA线程池原理详解二
Executor框架的两级调度模型 在HotSpot VM的模型中,JAVA线程被一对一映射为本地操作系统线程.JAVA线程启动时会创建一个本地操作系统线程,当JAVA线程终止时,对应的操作系统线程也 ...
- JAVA线程池原理详解一
线程池的优点 1.线程是稀缺资源,使用线程池可以减少创建和销毁线程的次数,每个工作线程都可以重复使用. 2.可以根据系统的承受能力,调整线程池中工作线程的数量,防止因为消耗过多内存导致服务器崩溃. 线 ...
- Java—线程池ThreadPoolExecutor详解
引导 要求:线程资源必须通过线程池提供,不允许在应用自行显式创建线程: 说明:使用线程池的好处是减少在创建和销毁线程上所花的时间以及系统资源的开销,解决资源不足的问题.如果不使用线程池,有可能造成系统 ...
- Executor线程池原理详解
线程池 线程池的目的就是减少多线程创建的开销,减少资源的消耗,让系统更加的稳定.在web开发中,服务器会为了一个请求分配一个线程来处理,如果每次请求都创建一个线程,请求结束就销毁这个线程.那么在高并发 ...
- Java 线程池原理分析
1.简介 线程池可以简单看做是一组线程的集合,通过使用线程池,我们可以方便的复用线程,避免了频繁创建和销毁线程所带来的开销.在应用上,线程池可应用在后端相关服务中.比如 Web 服务器,数据库服务器等 ...
- java线程池原理
在什么情况下使用线程池? 1.单个任务处理的时间比较短 2.将需处理的任务的数量大 使用线程池的好处: 1.减少在创建和销毁线程上所花的时间以及系统资源的开销 ...
- Java线程池原理解读
引言 引用自<阿里巴巴JAVA开发手册> [强制]线程资源必须通过线程池提供,不允许在应用中自行显式创建线程. 说明:使用线程池的好处是减少在创建和销毁线程上所消耗的时间以及系统资源的开销 ...
- 含源码解析,深入Java 线程池原理
从池化技术到底层实现,一篇文章带你贯通线程池技术. 1.池化技术简介 在系统开发过程中,我们经常会用到池化技术来减少系统消耗,提升系统性能. 在编程领域,比较典型的池化技术有: 线程池.连接池.内存池 ...
- Java线程池原理及分析
线程池是很常用的并发框架,几乎所有需要异步和并发处理任务的程序都可用到线程池. 使用线程池的好处如下: 降低资源消耗:可重复利用已创建的线程池,降低创建和销毁带来的消耗: 提高响应速度:任务到达时,可 ...
随机推荐
- 【洛谷T7153】(考试) 中位数
题目描述 给定 n 个数 a1, a2, ..., an,求这 n 个数两两的差值(共 n(n−1) 2 个)的中位数. 输入格式: 第一行一个正整数 n,表示数的个数. 接下来一行 n 个正整数,分 ...
- equals与==号的区别?
equals与 == 的区别 初学Java的人(me),有很长一段时间对equals()这个方法感到很懊恼,实在是弄不明白到底何时比较的是地址,又什么时候比较内容呢?因为要找工作,要面试.本人通过查阅 ...
- canvas练手项目(二)——各种操作基础
想想应该在canvas上面作画了,那么就不得不提到事件了. (打着canvas的旗号,写着mouse事件.挂羊头卖狗肉!哈哈哈哈哈~) 先来看一看HTML事件属性,我们要用的就是Mouse事件,就先研 ...
- 【Chrome控制台】获取元素上绑定的事件信息以及监控事件
需求场景 在前端开发中,偶尔需要验证下某个元素上到底绑定了哪些事件,以及监控某个元素上的事件触发情况. 解决方案 普通操作 之前面对这种情况,一般采取的措施就是在各个事件里写console.info, ...
- iOS学习——UITableViewCell两种重用方法的区别
今天在开发过程中用到了UITableView,在对cell进行设置的时候,我发现对UITableViewCell的重用设置的方法有如下两种,刚开始我也不太清楚这两种之间有什么区别.直到我在使用方法二进 ...
- Hive数据仓库笔记(二)
分区和桶: 分区:可以提高查询的效率,只扫描固定范围数据,不用全部扫描 CREATE TABLE logs (ts BIGINT, lineSTRING) PARTITIONED BY (dt S ...
- Linux shell 脚本(一)
一.初识脚本 shell:一类介于系统内核与用户之间的解释程序.脚本:一类使用特定语言,按预设顺序执行的文件批处理.宏.解释型程序创建shell脚本:理清任务过程--整理执行语句--完善文件结构1.任 ...
- python DNS域名轮询业务监控
应用场景: 目前DNS支持一个域名对应多个IP的解析,优势是可以起到负载均衡的作用,最大的问题是目标主机不可用时无法自动剔除,因此必须在自己的业务端写好监控与发现,怎么样来做这样的监控,以python ...
- Unity如何管理住Android 6.0 调皮的权限
前天我们项目有这么个需求,台湾版本由于要上谷歌Play要求安卓系统6.0以上的动态申请权限,对于一个做Unity的来说,是不是有点懵逼,这我该何去何从呢?我想静静,静静的想一想,权限也不就那么点事吗? ...
- 通过Performance Log确定磁盘有性能问题?
一些比较重要的performance counter: Counter Description LogicalDisk\ % Free Space 报告磁盘空间中未被分配的空间占逻辑卷中总可用空间的百 ...