Apriori算法思想和其python实现
第十一章 使用Apriori算法进行关联分析
一.导语
“啤酒和尿布”问题属于经典的关联分析。在零售业,医药业等我们经常需要是要关联分析。我们之所以要使用关联分析,其目的是为了从大量的数据中找到一些有趣的关系。这些有趣的关系将对我们的工作和生活提供指导作用。
二.关联分析的基本概念
所谓的关联分析就是从海量的数据中找到一些有趣的关系。关联分析它有两个目标,一个是发现频繁项集,另一个是发现关联规则。
关联分析常用到的四个概念是:频繁项集,关联规则,置信度,支持度。频繁项集指的是频繁同时出现的数据子集,这里的频繁是一般是根据支持度来确定的(当然你也可以根据其他的度量标准)。支持度指的是该项集最所有数据中出现的概率。关联规则指的是两个个体之间的关联性, 它一般用置信度来进行衡量。置信度指的是该项集出现的条件概率,这里的条件概率的条件也就是我们关联规则中的条件。比如 尿布->啤酒,那么此时的条件就是尿布。
三.Apriori原理
Apriori,顾名思义它是利用先验的知识,对未知的知识进行判断。
我们知道如果一个项集是频繁项集,那么它的子集必定也是频繁项集。比如{啤酒,尿布}是频繁项集,那么{尿布}和{啤酒}必定也是频繁项集。如果反向的思考的话,也就是说一个项集它不是频繁项集,那么它的超集就不会是频繁项集。Apriori算法正是利用了这个特点,对关联分析求解频繁项集的复杂度进行了很大程度的降低。
四.Apriori算法
如果直接的求解所有可能的频繁项集,那么它的复杂度太高,是无法忍受的,因此为了降低问题的复杂度,我们基于Apriori原理,提出了Apriori算法。换句话说Apriori算法是一种简便的求解频繁项集的方法。
Apriori算法的特点:
它的优点是:算法简单,容易实现
它的缺点是:不适用于大数据集
它的适用类型是:标称型数据
Apriori算法的过程是:首先生成单个商品的项集,然后根据最小支持度来去除不符合条件的项集,然后将剩下的商品进行两两组合,再根据最小支持度对不符合条件的项集进行删除,以此类推,直到所有不符合最小支持度的项集都被去掉。
以下是实现Apriori算法的python代码:
1.获取数据:

2.生成单个商品的项集:
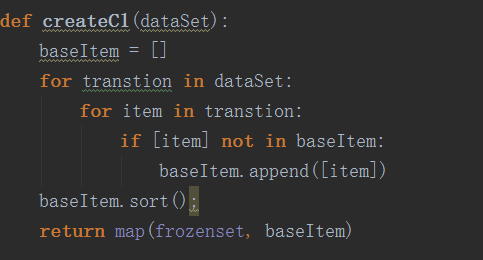
3.根据最支持度去除不符合条件的项集:
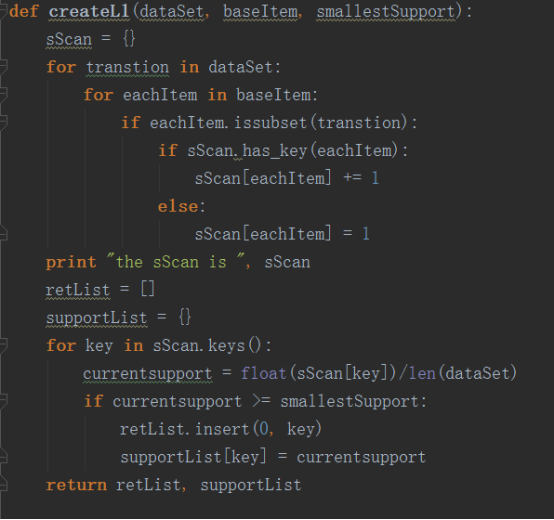
4.写一个函数用来获取包含k个item的项集

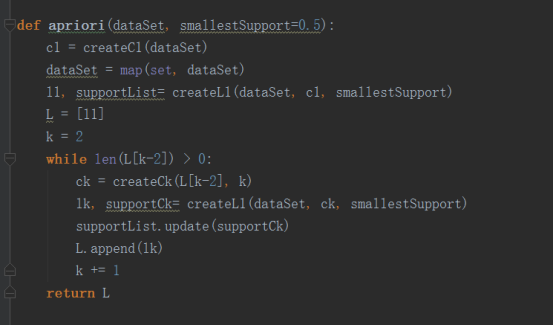
5.Apriori算法
五.从频繁项集中挖掘关联规则
频繁项集的度量指标是支持度,关联规则的度量指标是置信度。当一个规则的置信度满足一定的值时,我们就说这个规则是关联规则。关联规则具有和频繁项集类似的性质。当一规则不满足最小置信度的时候那么这个规则的子集也不满足最小置信度,换言之,如果可以从后件大小为1的规则出发,不断的产生新的规则。(这里所谓的后件,相当于结论,比如 尿布->啤酒, 这里的尿布是前件, 啤酒是后件)。
从求解关联规则的算法上看,他和apriori算法异曲同工,不过它有一个新的名字称之为分级算法。它就是先产生后件大小为1的规则,然后删除不满足置信度的规则,然后再利用剩下的规则,生出后件大小为2的规则,然后删除不满足置信度的规则,以此类推。
以下是python代码:
1.首先我们创建主函数
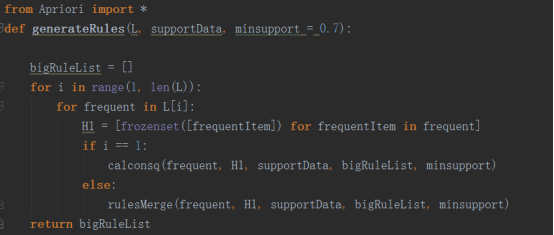
2.其次我们根据最小置信度来获取规则
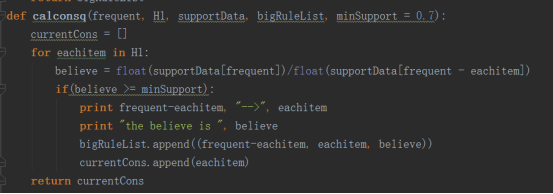
3.我们创建规则
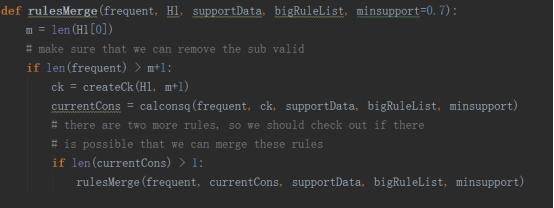
六.总结
关联分析的目的是为了寻找数据中有趣的关系,这里的有趣的关系有两层含义,一种是经常同时出现的项,也就是我们常说的寻找频繁项集;另一种是满足如果那么这种导出关系的项,也就是我们常说的寻找关联规则。频繁项集是由支持度来进行度量的,关联规则是由置信度进行度量的。
我们在进行关联分析的时候需要对结果进行组合,但是我们知道组合是很耗时的,为了简化计算,降低解空间,我们采用了Apriori算法。该算法的基本思想就是一个非频繁项集的超集也是非频繁项集。这个概念也可以拓展到关联规则,此时变为,一个规则不是关联规则那么它的超集也不是关联规则,该算法称之为分级算法。
虽然Apriori算法能够在一定的程度上减少计算量,但是因为它在每次频繁项集改变的时候都需要重新遍历一次数据库,不适用于大型数据,为了解决这个问题人们又提出了FP-growth算法。FP-growth算法和Apriori算法相比只需要遍历两次数据库,速度有了很大的提升。
Apriori算法思想和其python实现的更多相关文章
- Apriori算法的原理与python 实现。
前言:这是一个老故事, 但每次看总是能从中想到点什么.在一家超市里,有一个有趣的现象:尿布和啤酒赫然摆在一起出售.但是这个奇怪的举措却使尿布和啤酒的销量双双增加了.这不是一个笑话,而是发生在美国沃尔玛 ...
- FP-growth算法思想和其python实现
第十二章 使用FP-growth算法高效的发现频繁项集 一.导语 FP-growth算法是用于发现频繁项集的算法,它不能够用于发现关联规则.FP-growth算法的特殊之处在于它是通过构建一棵Fp树, ...
- Apriori算法原理总结
Apriori算法是常用的用于挖掘出数据关联规则的算法,它用来找出数据值中频繁出现的数据集合,找出这些集合的模式有助于我们做一些决策.比如在常见的超市购物数据集,或者电商的网购数据集中,如果我们找到了 ...
- Apriori算法介绍(Python实现)
导读: 随着大数据概念的火热,啤酒与尿布的故事广为人知.我们如何发现买啤酒的人往往也会买尿布这一规律?数据挖掘中的用于挖掘频繁项集和关联规则的Apriori算法可以告诉我们.本文首先对Apriori算 ...
- 数据挖掘入门系列教程(五)之Apriori算法Python实现
数据挖掘入门系列教程(五)之Apriori算法Python实现 加载数据集 获得训练集 频繁项的生成 生成规则 获得support 获得confidence 获得Lift 进行验证 总结 参考 数据挖 ...
- Python两步实现关联规则Apriori算法,参考机器学习实战,包括频繁项集的构建以及关联规则的挖掘
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- Apriori 算法python实现
1. Apriori算法简介 Apriori算法是挖掘布尔关联规则频繁项集的算法.Apriori算法利用频繁项集性质的先验知识,通过逐层搜索的迭代方法,即将K-项集用于探察(k+1)项集,来穷尽数据集 ...
- 【机器学习】Apriori算法——原理及代码实现(Python版)
Apriopri算法 Apriori算法在数据挖掘中应用较为广泛,常用来挖掘属性与结果之间的相关程度.对于这种寻找数据内部关联关系的做法,我们称之为:关联分析或者关联规则学习.而Apriori算法就是 ...
- Python <算法思想集结>之初窥基础算法
1. 前言 数据结构和算法是程序的 2 大基础结构,如果说数据是程序的汽油,算法则就是程序的发动机. 什么是数据结构? 指数据在计算机中的存储方式,数据的存储方式会影响到获取数据的便利性. 现实生活中 ...
随机推荐
- Linux IPC实践(4) --System V消息队列(1)
消息队列概述 消息队列提供了一个从一个进程向另外一个进程发送一块数据的方法(仅局限于本机); 每个数据块都被认为是有一个类型,接收者进程接收的数据块可以有不同的类型值. 消息队列也有管道一样的不足: ...
- 主线程中也不绝对安全的 UI 操作
从最初开始学习 iOS 的时候,我们就被告知 UI 操作一定要放在主线程进行.这是因为 UIKit 的方法不是线程安全的,保证线程安全需要极大的开销.那么问题来了,在主线程中进行 UI 操作一定是安全 ...
- linux 下启动java jar包 shell
linux 下启动java jar包 shell #!/bin/sh JAVA_HOME=/usr/local/jdk1.6.0_34/bin/javaJAVA_OPTS="-Xmx256m ...
- CE6.0 下获得 SD 卡序列号的方法
经常在坛子里看到讨论软件加密的帖子,纯软件加密与读取硬件序列号加密是经常讨论到的. 两种方法各有优缺点. 在通过读取硬件序列号的方法来加密的方法,受硬件的限制. 一般来说,CPU和T-Flash可能存 ...
- MT6575 3G切换2G
因为了节省成本,需要从现在的3G方案切换置2G方案,做的修改,做个笔记. 一: 将MTK给过来的补丁编译出如下文件. 二:在mediatek/custom/common/modem/ 路径下增加一个 ...
- (视频) 《快速创建网站》 3.2 WordPress多站点及Azure在线编辑器 - 扔掉你的ftp工具吧,修改代码全部云端搞定
本文是<快速创建网站>系列的第6篇,如果你还没有看过之前的内容,建议你点击以下目录中的章节先阅读其他内容再回到本文. 1. 网站管理平台WordPress和云计算平台Azure简介 (6分 ...
- TCP中的MSS解读(转)
本文摘录自TCP中的MSS解读. MSS 是TCP选项中最经常出现,也是最早出现的选项.MSS选项占4byte.MSS是每一个TCP报文段中数据字段的最大长度,注意:只是数据部分的字段,不包括TCP的 ...
- tomcat中的线程问题
看这篇文章之前,请先阅读: how tomcat works 读书笔记 十一 StandWrapper 上 地址如下: http://blog.csdn.net/dlf123321/article/d ...
- 机器学习算法与Python实践之(五)k均值聚类(k-means)
机器学习算法与Python实践这个系列主要是参考<机器学习实战>这本书.因为自己想学习Python,然后也想对一些机器学习算法加深下了解,所以就想通过Python来实现几个比较常用的机器学 ...
- 关于electron的sqlite3报错,需重新编译的问题
你需要安装sqlite3的所有依赖项,例如vs.python等.或者简单的npm安装命令,它会安装windows下的所有依赖. npm install -g windows-build-tools 然 ...