Scrapy-简单介绍
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了 页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。
编写一个Scrapy项目需要以下几个简单的流程:
创建一个Scrapy项目
scrapy startproject projectName
cd projectName
scrapy genspider baidu baidu.com
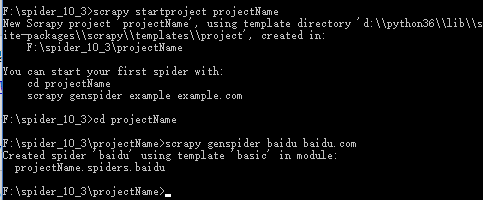
然后就会在你的集成化工具上出现创建的项目:
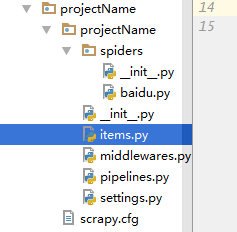
定义提取的Item(你需要爬取的数据的容器)
import scrapy
class DmozItem(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
import scrapy
class BaiduSpider(scrapy.Spider):
name = 'baidu'
allowed_domains = ['baidu.com']
start_urls = ['http://baidu.com/']
def parse(self, response):
#主要爬取代码编写区
pass
编写 Item Pipeline 来存储提取到的Item(即数据)
class ProjectnamePipeline(object):
def process_item(self, item, spider):
#对爬取到的数据进行处理
return item
运行项目
方法一:cmd命令行输入运行 Scrapy 项目
scrapy crawl baidu #这里的baidu是spider的名字不是项目名,是唯一的
方法二:.py文件运行 Scrapy 项目
创建 runBaidu.py 文件
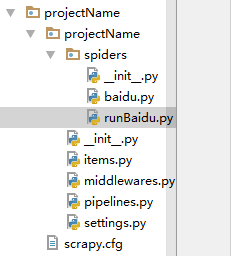
from scrapy import cmdline
cmdline.execute("scrapy crawl baidu".split())
Scrapy-简单介绍的更多相关文章
- Learning Scrapy笔记(一)- Scrapy简单介绍
Scrapy简述 Scrapy十一个健壮的,用来从互联网上抓取数据的web框架,Scrapy只需要一个配置文件就能组合各种组件和配置选项,并且Scrapy是基于事件(event-based)的架构,使 ...
- Python -- Scrapy 框架简单介绍(Scrapy 安装及项目创建)
Python -- Scrapy 框架简单介绍 最近在学习python 爬虫,先后了解学习urllib.urllib2.requests等,后来发现爬虫也有很多框架,而推荐学习最多就是Scrapy框架 ...
- scrapy爬虫学习系列二:scrapy简单爬虫样例学习
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- scrapy -->CrawlSpider 介绍
scrapy -->CrawlSpider 介绍 1.首先,通过crawl 模板新建爬虫: scrapy genspider -t crawl lagou www.lagou.com 创建出来的 ...
- Python常用的库简单介绍一下
Python常用的库简单介绍一下fuzzywuzzy ,字符串模糊匹配. esmre ,正则表达式的加速器. colorama 主要用来给文本添加各种颜色,并且非常简单易用. Prettytable ...
- selenium模块使用详解、打码平台使用、xpath使用、使用selenium爬取京东商品信息、scrapy框架介绍与安装
今日内容概要 selenium的使用 打码平台使用 xpath使用 爬取京东商品信息 scrapy 介绍和安装 内容详细 1.selenium模块的使用 # 之前咱们学requests,可以发送htt ...
- [原创]关于mybatis中一级缓存和二级缓存的简单介绍
关于mybatis中一级缓存和二级缓存的简单介绍 mybatis的一级缓存: MyBatis会在表示会话的SqlSession对象中建立一个简单的缓存,将每次查询到的结果结果缓存起来,当下次查询的时候 ...
- 利用Python进行数据分析(7) pandas基础: Series和DataFrame的简单介绍
一.pandas 是什么 pandas 是基于 NumPy 的一个 Python 数据分析包,主要目的是为了数据分析.它提供了大量高级的数据结构和对数据处理的方法. pandas 有两个主要的数据结构 ...
- 利用Python进行数据分析(4) NumPy基础: ndarray简单介绍
一.NumPy 是什么 NumPy 是 Python 科学计算的基础包,它专为进行严格的数字处理而产生.在之前的随笔里已有更加详细的介绍,这里不再赘述. 利用 Python 进行数据分析(一)简单介绍 ...
- yii2的权限管理系统RBAC简单介绍
这里有几个概念 权限: 指用户是否可以执行哪些操作,如:编辑.发布.查看回帖 角色 比如:VIP用户组, 高级会员组,中级会员组,初级会员组 VIP用户组:发帖.回帖.删帖.浏览权限 高级会员组:发帖 ...
随机推荐
- [SinGuLaRiTy] Nescafe 24杯模拟赛
[SinGularLaRiTy-1044] Copyright (c) SinGuLaRiTy 2017. All Rights Reserved. 小水塘(lagoon) 题目描述 忘川沧月的小水塘 ...
- 新版Azure Automation Account 浅析(二) --- 更新Powershell模块和创建Runbook
前篇我们讲了怎样创建一个自动化账户以及创建时候"Run As Account"选项背后的奥秘.这一篇针对在Azure自动化账户中使用Powershell Runbook的用户讲一下 ...
- Oracle问题之literal does not match format string
问题: oerr ora 186101861, 00000, "literal does not match format string"// *Cause: Literals i ...
- 强大的Cmder
why 漂亮,包装并美化了各个shell 带task功能,能记忆,能执行脚本 配合win10的bash,能实现类似xshell的功能 注意点 需要注意的一点,Cmder来源于另外一个项目ConEmu, ...
- ASP.NET没有魔法——ASP.NET MVC 模型绑定
在My Blog中已经有了文章管理功能,可以发布和修改文章,但是对于文章内容来说,这里缺少最重要的排版功能,如果没有排版的博客很大程度上是无法阅读的,由于文章是通过浏览器查看的,所以文章的排版其实与网 ...
- linux_NFS
NFS是什么? 网络文件系统,又叫共享存储,通过网络连接让不同主机之间实现共享存储. 应用于存放图片.附件.视频等用户上传文件 相关同类应用:大型网站nfs有压力,使用moosefs(mfs),Ghu ...
- java利用poi生成/读取excel表格
1.引入jar包依赖 <dependency> <groupId>org.apache.poi</groupId> <artifactId>poi< ...
- git fetch, git pull 剖析
真正理解 git fetch, git pull 要讲清楚git fetch,git pull,必须要附加讲清楚git remote,git merge .远程repo, branch . commi ...
- Linux指令--traceroute,netstat,ss
通过traceroute我们可以知道信息从你的计算机到互联网另一端的主机是走的什么路径.当然每次数据包由某一同样的出发点(source)到达某一同样的目的地(destination)走的路径可能会不一 ...
- Linux make nginx 的时候报错
报错如下: `conf/koi-win' and `/usr/local/nginx/conf/koi-win' are the same file 原因: 可能在编译 nginx 的时候步骤不对 ...