Rest_framework Serializer 序列化 (含源码浅解序列化过程)
Rest_framework Serializer 序列化
序列化与反序列化中不得不说的感情纠葛
Yo!Yo! 为什么说到感情呢?因为在restframe_work中,序列化与反序列化中有太多令人感到纠结,易乱,不好分清界限的地方。就像感情一样。
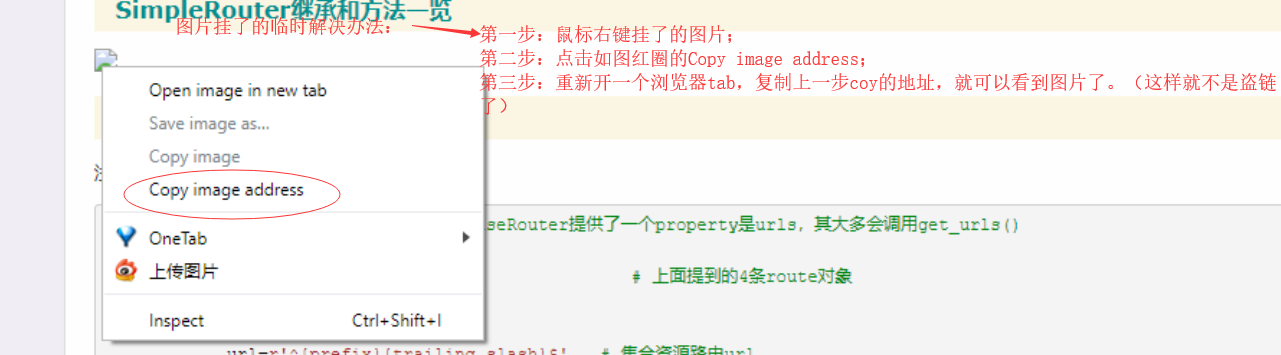
博文图片挂了临时解决办法
三角恋之 save/update/create
对于普通序列化类,作用的是普通python 对象,一般不需要反序列化得到一个对象,我们只需要得到一个序列化后的数据字典,然后自己再来根据python普通对象的类进行实例化出对象。所以一般序列化类是用不到save和update还有create方法的。
然而, 对于特殊的序列化类,ModelSerializer/ListSerializer都会提供save/update/create三种方法,目的是直接通过使用反序列化得到的validated_data进行创建一个新对象或者更新一个已有对象。
根据实例化序列化类时,是否提供instance参数,来判定在save调用时,是进行update还是create,一般instance参数是默认None,所以默认调用save就是调用create方法,而create方法是需要serializer类实现的,从而使用序列化数据创建一个想要的对象来。
如果提供了instance, 那么save会调用的时update方法,进行更新操作。这里的更新操作只会当前对象的,且支持全量更新和部分更新。因为时依据validated_data中有的属性进行更新。如果在序列化时提供了partail=True,那么在validated_data就是部分数据,就是部分更新。
save源代码,从源代码可以看出,无论序列化类目的是序列化还是反序列化,只要提供了instance,都会影响到save操作:

四角恋之 序列化参数instance/data/many/partial
以下描述来自BaseSerializer源码注释
In particular,
if a `data=` argument is passed then:
.is_valid() - Available.
.initial_data - Available.
.validated_data - Only available after calling `is_valid()`
.errors - Only available after calling `is_valid()`
.data - Only available after calling `is_valid()`
If a `data=` argument is not passed then:
.is_valid() - Not available.
.initial_data - Not available.
.validated_data - Not available.
.errors - Not available.
.data - Available.
instance/data/many/partial 影响序列化对象行为的四个关键参数。
- 如果没有data参数,只有instance,那么就不存在反序列化校验一说,只有序列化对象instance。
- 如果有data,没有instance,那么需要进行校验data,然后将data进行反序列化,得到validated_data,此时再通过序列化对象获取data,这个data和初始化提供的data可不一样,这个序列化validated_data后的data,比起初始化data,可能减少了无效的字段(序列化没有定义的字段)。
- 如果又提供了instance 又提供了data, 那么只要有data或者部分data,那么data都要进行验证才能进行下面的save等操作,如果不经过is_valid过程,那么后面的获取序列化数据或者反序列化数据都会无效。
- many参数将直接影响序列化类的类型,如果是many=False,那么直接使用当前序列化类。如果many=True,将实例化一个ListSerializer类来序列化或者反序列化类。(这也是看源码是漏掉的地方,一直奇怪普通Serialiszer类怎么没看到对多对象序列化的特殊处理。查看BaseSerializer.__new__方法)或者class Meta:中定义了list_serializer_class指定的多对象序列化类。
- 终于弄懂了,partial用于部分更新,为啥子要伴随instance,因为要指明给save用,在save操作时给那个instance部分更新。逻辑这回走到下面源码中的get_initial()获取要进行更新instance的字段数据。
@property
def data(self):
if hasattr(self, 'initial_data') and not hasattr(self, '_validated_data'):
msg = (
'When a serializer is passed a `data` keyword argument you '
'must call `.is_valid()` before attempting to access the '
'serialized `.data` representation.\n'
'You should either call `.is_valid()` first, '
'or access `.initial_data` instead.'
)
raise AssertionError(msg)
if not hasattr(self, '_data'):
if self.instance is not None and not getattr(self, '_errors', None):
self._data = self.to_representation(self.instance)
elif hasattr(self, '_validated_data') and not getattr(self, '_errors', None):
self._data = self.to_representation(self.validated_data)
else:
self._data = self.get_initial()
return self._data
小结: instance影响save行为;data是影响后续的所有行为,有data必须进行校验动作(.is_valid)。
三角恋之 初始化参数data和序列化对象的data属性,validated_data
前两者也是比较迷惑人的。都叫data,前者是Serializer(data={'a':1,'b':2}) ,后者是序列化后的数据。后者是前者依靠序列化定义的字段过滤校验后的。
而validated_data这是反序列化的目的对象的数据。
两个many=True
- BaseSerializer(many=True) 和 RelatedField(many=True)
- 一个是将对象列表进行序列化;一个是将关联字段对了的queryset进行序列化。都会序列化返回一个列表。
- 前者会变为一个ListSerializer类;后者将是一个ManyRelatedField类。
- 两者的child属性都是源类。
- 两者其实非常相似。
多对象的序列化与反序列化
首先要知道,由于序列化主要对应的是查询动作,如list,retrieve两个。而destrory动作不涉及序列化类。update和partial_update,create动作则涉及反序列化。明确这些后,看下面:
所有的序列化类都继承自BaseSerializer类,这个类重写了__new__ 方法,会根据实例化时的参数many的布尔值。默认是False,则使用当前类作为单对象序列化的类。如果是True,那么__new__会返回一个ListSerializer类对象作为序列化对象,与此同时这个对象的一个child属性将会存放当前这个类的一个实例为后续提供多对象中单个对象的处理功能。
源码:

多对象序列化的不同之处
- 在序列化时,提供的对象列表或者数据列表,many=True要显示设置
- 序列化得到的serializer.data 是一个嵌套字典的列表
- 反序列化的validated_data 是一个嵌套字典的列表
- 使用自定义的序列化类
class CustomSerializer(serializers.Serializer):
...
class Meta:
list_serializer_class = CustomListSerializer # 使用自定义的序列化类
- 自定义多对象的update行为,官网例子:
class BookListSerializer(serializers.ListSerializer):
def update(self, instance, validated_data):
# Maps for id->instance and id->data item.
book_mapping = {book.id: book for book in instance}
data_mapping = {item['id']: item for item in validated_data}
# Perform creations and updates.
ret = []
for book_id, data in data_mapping.items():
book = book_mapping.get(book_id, None)
if book is None:
ret.append(self.child.create(data))
else:
ret.append(self.child.update(book, data))
# Perform deletions.
for book_id, book in book_mapping.items():
if book_id not in data_mapping:
book.delete()
return ret
class BookSerializer(serializers.Serializer):
# We need to identify elements in the list using their primary key,
# so use a writable field here, rather than the default which would be read-only.
id = serializers.IntegerField()
...
class Meta:
list_serializer_class = BookListSerializer
多对象的反序列化只支持create操作,不支持更新update和部分更新partial_update,因为更新操作需要提供说要更新的目的对象,而要获得更新操作的目的对象,(一般是一个model对象)所以需要pk,然而我们的pk都是放在url中进行存放,通过lookup_url_kwarg来获取pk,不肯能将多个对象pk放入url中,所以更新操作是不支持批量反序列化。只有通过上面提到的自定义更新。
嵌套子序列化
如果对象的属性还是一个对象,这时候的对象序列化就要用到子序列化了。
- 即使是BaseSerializer也是继承之Field类的,所以Serializer类也可以作为一另一个序列化类的字段的序列化对象。
序列化源码解析
部分源码解析
很多时候不知道怎么让serializer对象和 instance 匹配序列化上的,只有通过看源码了。里面封装了来达到序列化和反序列化的方法。如 以下源码截图,就是一步一步得到的.
也可以通过源码看出instance参数和data参数的关系
- 获取序列化数据

- 根据instance参数决定序列化对象是instance还是valid_data(序列化检验不会报错才进入流程)

- 这里走序列化instance路线

- 获取可读的field对象,不同类型的field类对象可读性已实际而定,需查看每个类的源码或者官方文档说明。

- 所有定义个fields的来源,和存放fields的一个BindingDict


7. 定义的所有fields中包含的属性名与对应field对象映射的由来

8. 来源于元类

9. 所有field类的父类,定义初始化时都是默认可读可写

回到序列化函数to_representation,看到序列化instances时,依靠循环所有序列化类定义的字段,在带入instance

如果实例化字段对象时,带入了source参数,那么将通过source定义的方式拿取数据,instance中的数据。

从实例获取对应的source的值,这里算法是一个属性一个属性的循环获取,对于函数直接调用获取值。

source_attrs实在bind时发生的

最后,从source或者额外的method

最后就到了每个种Field类自己的序列化函数to_presentation()了,最后返回序列化结果对于ModelSerializer 继承了Serializer, 但是其fields定义的字段的字典{‘fieldname': field_object} ,是通过重写了get_fields()方法。重写的方法逻辑如下截图:


各种类型数据对象对应的Field对象
FIeld对象抽象出来的共同特征
或者说是,他们所展现出来的多态性,只不过各自的内部逻辑实现根据各自的特征不同而已。
- get_attribute(self, instance) 获取instance符合当前field代表的字段类型的属性值。如可以来源于field指定的source,或者通过方法从instance中获取,又或者是model对象的一个关联字段获取pk值等等。
- to_representation(attribute) 将字段获取到的需要序列化的value进行序列化。可以查看上面源码分析过程理解。
- to_internal_value() 这个是反序列化,可以另行查看源码。
只要大体了解,那么我们既可以对各种需要序列化的对象进行大致分类。虽然这些对象都千差万别,但是最终都有会根据其不同目的,实现了满足对应需求的序列化方式。这种设计模式值得思考和借鉴,能够将那么多的数据类型并且这么细化的分类实现,分类解耦,应对各种序列化需求,能够清晰做出选择,几乎不用重造轮子。
不同的获取数据方式,不同的序列化方式,可读写的选择,等等,为了满足需求,有太多的已实现的字段类可供选择。只要我们清楚以下几种类型他们实例化或者使用上的区别就可以了。
这里只看分类,具体参见 官档:
- https://www.django-rest-framework.org/api-guide/serializers/
- https://www.django-rest-framework.org/api-guide/fields/
- https://www.django-rest-framework.org/api-guide/relations/
第一类普同字段
int/string等。
第二类choice类,数字标号有映射的值
ChoiceField/MultipleChoiceField
第三类文件对象
FileField/ImageField
第四类复合数据类,列表/字典/,需要再指定里面元素的值的类型
ListField/DictField/HStoreField/JSONField
第五类方法类型
SerializerMethodField
第六类针对model关系字段的类型字段,而且将不同的序列化方式细分有linked,Slug.而关系类型上GenericForeignKey都能满足
StringRelatedField/PrimaryKeyRelatedField/HyperlinkedRelatedField
第七类其他
ReadOnlyField/HiddenField/ModelField
ModelSerializer
提供了Model字段与Serializer字段的映射,也提供对关系字段的映射,包括稍微复杂的GenericForeignKey关系。
- Meta class 中必须有model指定
- Meta class 中fields必须指定
- Meta class 中必须包含添加的序列化字段,如果和model同名,那么添加的加覆盖model同名字段
- 自添加override model的字段,要注意其读写设置,不然会影响modelserializer的save行为,因为如果是只读,那么在validated_data中将没有这个字段,在save时就可能缺少字段,从而save失败。这是在自添加字段需要注意的。
当前 partial_update 部分更新时,ModelSerializer的处理
对于部分更新,在实例化ModelSerializer时,时需要提供partial=True的,不然校验会失败,拿不到校验后的数据来进行部分更新。可以查看ModelSerializer的校验源码,对部分校验的支持。
跳过逻辑分析:
- 首先校验数据时会进入到以下方法:

- 进入到运行校验,由于有数据,所以进入to_internal_value校验data中的数据

- 可以看到to_internal_data开时校验每一个字段,通过field.get_value(data) 拿取字段对应数据,如果没有则返回空。

- 然后进入校验的验证是否为空,如果时空,但是又是partial=True,那么抛出SkipField

- 回到了to_internal_value,接受到异常后,捕获异常,如果时SkipField会继续循环,最终得到ret校验后的有效数据集:

- 然后回到run_validation,然后运行run_validators进行全局校验,不过单字段的value我们已经得到了。

可以看到,对于partial_update,ModelSerializersave()的处理逻辑。
总结
- 序列化是可嵌套的
- 序列化初始化的参数对后续序列化对象影响是非常大的。
- 序列化字段分readable和writable,即对应可serialize和deserialized的。
- 有关model序列化,除了普通字段,还有关联字段,关联字段只会处理其对应的数据是多个还是单个都是用PrimaryKeyRelatedField。记住,字段可设置数据来源source等来定义单个字段的序列化出来的行为,毕竟序列化和反序列化接口都是要带入对应对象参与序列化的。
- 序列化大致流程:data->serializer.to_representation->field.get_attribute(instance)->field.to_representation
- 三方法:get_attribute/to_representation/to_internal_value 对序列化和序列化结果的影响。
- HyperlinkedRelatedField 主要反解view url 的正确反解。注意事项见《Rest_framework 回顾记忆集》
实例代码
class CourseModelSerializer(serializers.ModelSerializer):
level = serializers.CharField(source='get_level_display') # 利用source参数 在choice字段上
recommend_courses = serializers.SerializerMethodField() # manytomany 自定义序列化
chapters = serializers.SerializerMethodField()
image = serializers.SerializerMethodField()
class Meta:
model = Course
fields = ['id', 'title', 'image', 'level', 'recommend_courses', 'chapters']
def get_recommend_courses(self, obj):
qs = obj.re_course.all()
return [{'id': i.course.id, 're_course_title': i.course.title} for i in qs]
def get_chapters(self, obj):
if isinstance(self, ListSerializer):
return ''
qs = obj.chapters_set.all()
return [{'id': j.id, 'chapter_name': j.title} for j in qs]
def get_image(self, obj):
rel_path = obj.image
rely_on_path = settings.STATIC_URL
return rely_on_path + rel_path
# 主课程分类
class CourseCategoryModelSerializer(serializers.ModelSerializer):
subcategory_url = serializers.HyperlinkedRelatedField(source='coursesubcategory_set',
view_name='luffyapi:coursesubcategory-detail',
read_only=True, # 设置为只读
many=True) # 对于多对象
class Meta:
model = CourseCategory
fields = ['id', 'name', 'subcategory_url']
# 子课程分类
class CourseSubCategoryModelSerializer(serializers.ModelSerializer):
"""
子课程分类 序列化
"""
category_url = serializers.HyperlinkedRelatedField(source='category', view_name='luffyapi:coursecategory-detail',
lookup_field='pk',
lookup_url_kwarg='pk', read_only=True)
courses_url = serializers.HyperlinkedIdentityField(
view_name='luffyapi:coursesubcategory-get-courses',
read_only=True)
class Meta:
model = CourseSubCategory
fields = ['id', 'name', 'category', 'category_url', 'courses_url']
Rest_framework Serializer 序列化 (含源码浅解序列化过程)的更多相关文章
- Rest_framework Router 路由器(含SimplyRouter源码浅解)
目录 Rest_framework Router 路由器 ViewSet结合Router,自动生成url. 将ViewSet注册到Router中,需要三个要素: 关于路由规则,细分有四类: rest_ ...
- C++ JsonCpp 使用(含源码下载)
C++ JsonCpp 使用(含源码下载) 前言 JSON是一个轻量级的数据定义格式,比起XML易学易用,而扩展功能不比XML差多少,用之进行数据交换是一个很好的选择JSON的全称为:JavaScri ...
- 微信公众平台开发-OAuth2.0网页授权(含源码)
微信公众平台开发-OAuth2.0网页授权接口.网页授权接口详解(含源码)作者: 孟祥磊-<微信公众平台开发实例教程> 在微信开发的高级应用中,几乎都会使用到该接口,因为通过该接口,可以获 ...
- 条件随机场之CRF++源码详解-预测
这篇文章主要讲解CRF++实现预测的过程,预测的算法以及代码实现相对来说比较简单,所以这篇文章理解起来也会比上一篇条件随机场训练的内容要容易. 预测 上一篇条件随机场训练的源码详解中,有一个地方并没有 ...
- RestFramework之序列化器源码解析
一.源码解析之序列化: 1.当视图类进行实例化序列化类做了如下操作: #ModelSerializer继承Serializer再继承BaseSerializer(此类定义实例化方法) #在BaseSe ...
- Spark Streaming揭秘 Day25 StreamingContext和JobScheduler启动源码详解
Spark Streaming揭秘 Day25 StreamingContext和JobScheduler启动源码详解 今天主要理一下StreamingContext的启动过程,其中最为重要的就是Jo ...
- 微信公众平台开发-access_token获取及应用(含源码)
微信公众平台开发-access_token获取及应用(含源码)作者: 孟祥磊-<微信公众平台开发实例教程> 很多系统中都有access_token参数,对于微信公众平台的access_to ...
- 微信公众平台开发-微信服务器IP接口实例(含源码)
微信公众平台开发-access_token获取及应用(含源码)作者: 孟祥磊-<微信公众平台开发实例教程> 学习了access_token的获取及应用后,正式的使用access_token ...
- jQuery使用():Deferred有状态的回调列表(含源码)
deferred的功能及其使用 deferred的实现原理及模拟源码 一.deferred的功能及其使用 deferred的底层是基于callbacks实现的,建议再熟悉callbacks的内部机制前 ...
随机推荐
- vue.js常见的报错信息及其解决方法的记录
1.Vue packages version mismatch 翻译:vue包版本匹配错误 报错样例: 报错原因:通常出现于一些依赖库的更新或者安装新的依赖库之后(可以认为npm update已经成为 ...
- python new和init知识点
__new__ 方法是什么?如果将类比喻为工厂,那么__init__()方法则是该工厂的生产工人,__init__()方法接受的初始化参 数则是生产所需原料,__init__()方法会按照方法中的语句 ...
- day12 EL 表达式和国际化开发
day12 EL 表达式和国际化开发 1. EL(Expression Language) 表达式简介 1.1 执行运算 1.2 获取web开发常用对象(el 中定义了11个隐式对象) 1.3 使用 ...
- C# 插入、删除Excel分页符
引言 对Excel表格设置分页对我们预览.打印文档时是很方便的,特别是一些包含很多复杂数据的.不规则的表格,为保证打印时每一页的排版美观性或者数据的前后连接的完整性,此时的分页符就发挥了极大的作用.因 ...
- PAT1077: Kuchiguse
1077. Kuchiguse (20) 时间限制 100 ms 内存限制 65536 kB 代码长度限制 16000 B 判题程序 Standard 作者 HOU, Qiming The Japan ...
- PAT1009:Product of Polynomials
1009. Product of Polynomials (25) 时间限制 400 ms 内存限制 65536 kB 代码长度限制 16000 B 判题程序 Standard 作者 CHEN, Yu ...
- linux简单内核链表排序
#include <stdio.h> #include <stdlib.h> #define container_of(ptr, type, mem)(type *)((uns ...
- safari浏览器模拟ipone,ipad以及其他浏览器版本
1.打开safari浏览器中的偏好设置 2.在偏好设置中,选择高级,勾选在菜单栏中显示开发菜单 3.打开开发,进入响应式设计模式 4.可以选择iphone 或ipad.浏览器等不同模式,进行模拟 5. ...
- DOM元素的Attribute(特性)和Property(属性) 【转载】
1.介绍: 上篇js便签笔记http://www.cnblogs.com/wangfupeng1988/p/3626300.html最后提到了dom元素的Attribute和Property,本文简单 ...
- 解决mongodb的安装mongod命令不是内部或外部命令
1:安装 去mongodb的官网http://www.mongodb.org/downloads下载32bit的包 解压后会出现以下文件 在安装的盘C:下建立mongodb文件夹,拷贝bin文件夹到该 ...