Python网络爬虫笔记(五):下载、分析京东P20销售数据
(一) 分析网页
下载下面这个链接的销售数据
https://item.jd.com/6733026.html#comment
1、 翻页的时候,谷歌F12的Network页签可以看到下面的请求。(这里的翻页指商品评价中1、2、3页等)
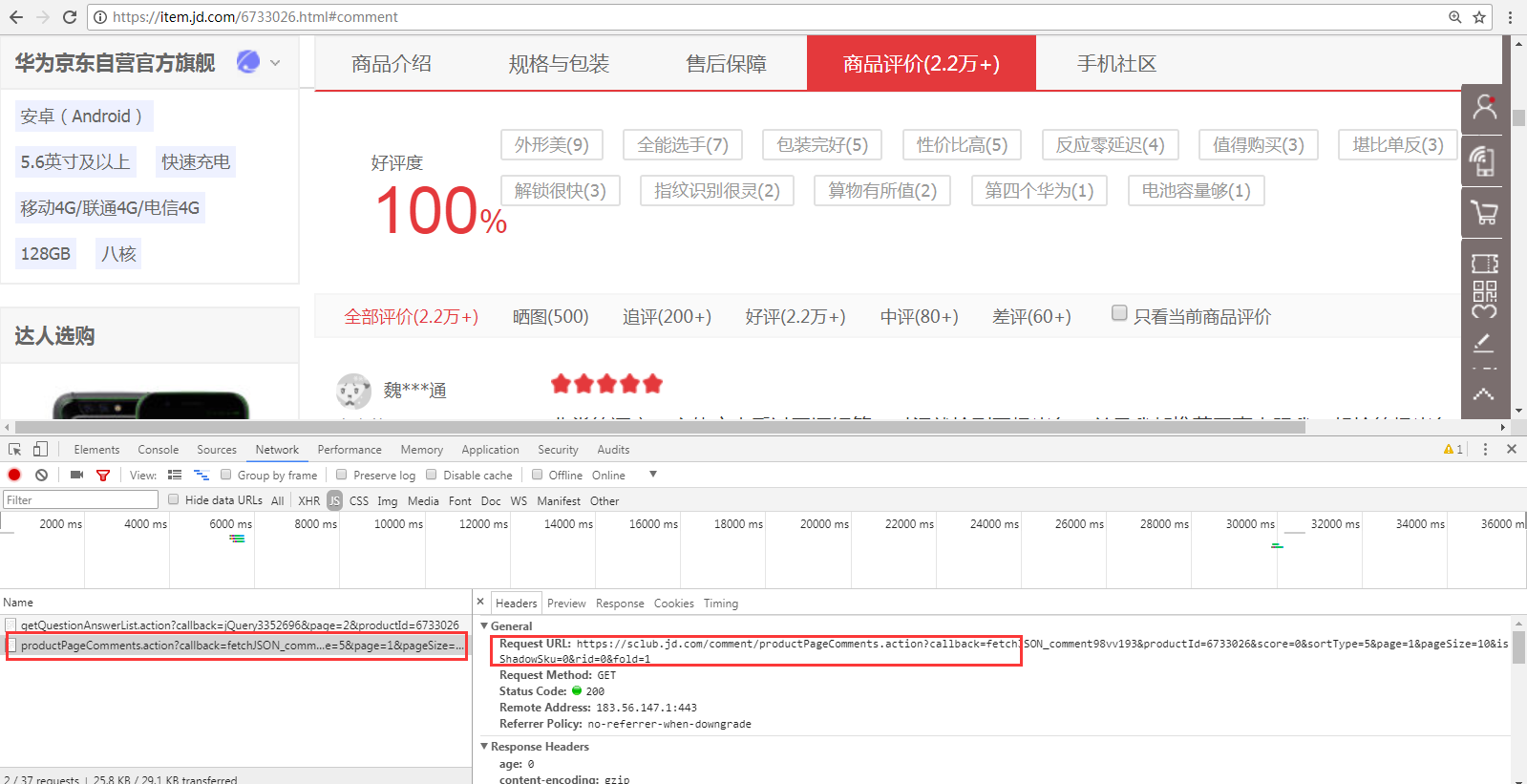
从Preview页签可以看出,这个请求是获取评论信息的
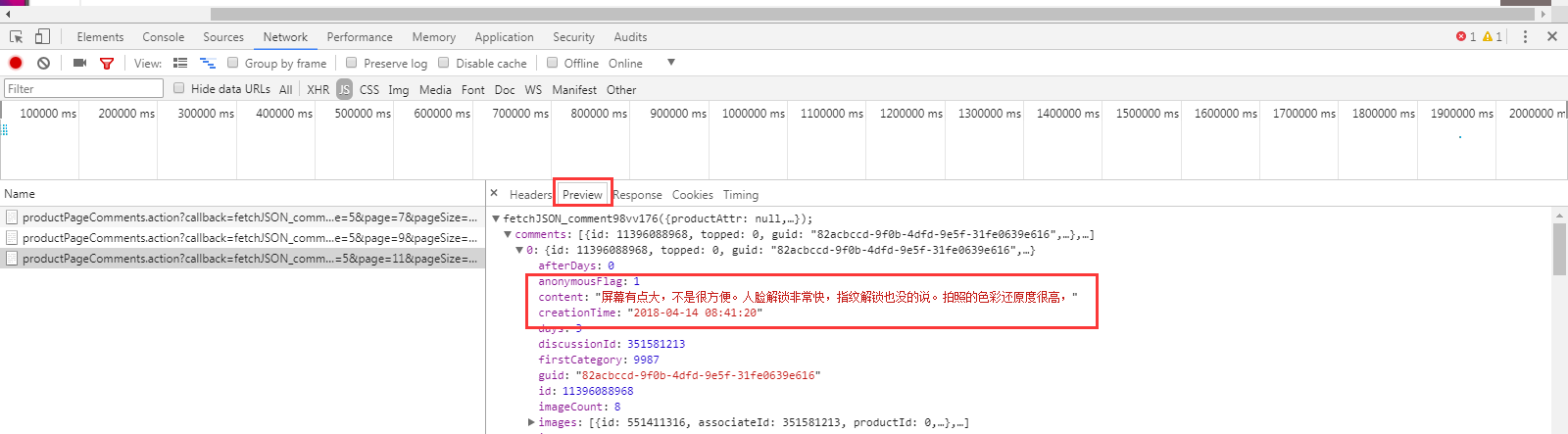
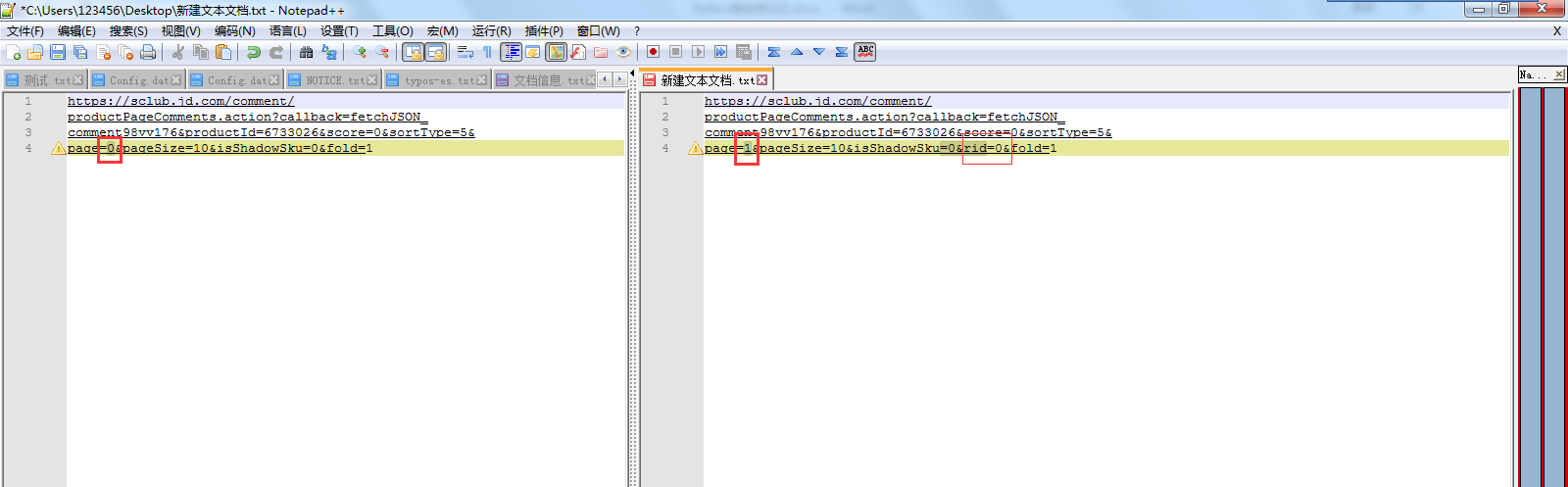
2、 对比第一页、第二页、第三页…请求URL的区别
可以发现 page=0、page=1,0和1指的应该是页数。
第一页的 request url:没有这个rid=0& 。 第二、三页…的request url:多了这个rid=0&
除了上面这2个地方,其他内容都是一样的。
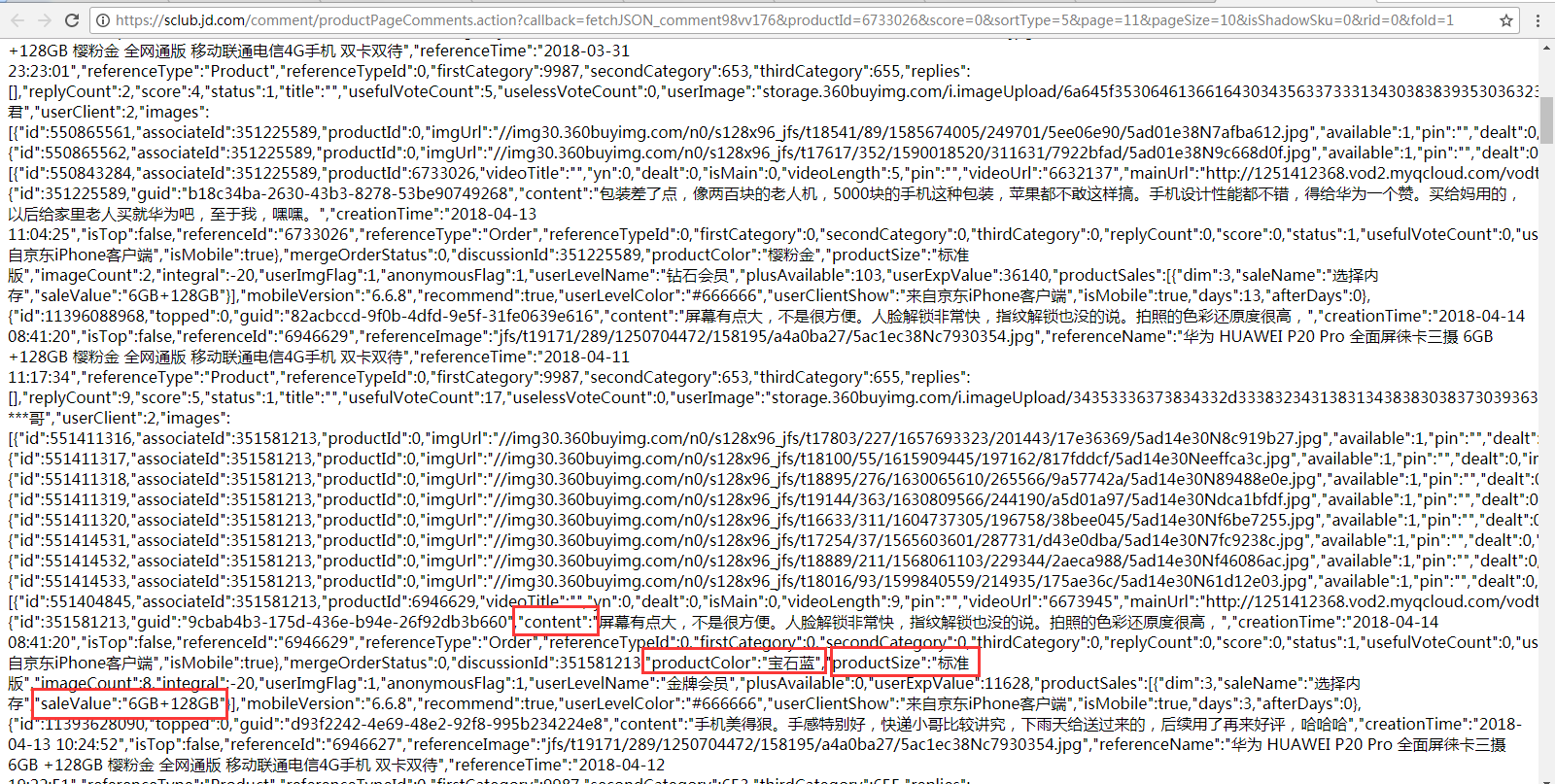
3、 直接在浏览器输入 复制出来的request url,可以看到评论、颜色、版本、内存信息,代码将根据这些信息来写正则表达式进行匹配。
(二) 实现代码
delayed.py的代码和我前面发的是一样的(Python网络爬虫笔记(二)),不限速的话把和这个模块相关的代码删除就行了
import urllib.request as ure
import urllib.parse
import openpyxl
import re
import os
from delayed import WaitFor
def download(url,user_agent='FireDrich',num=2,proxy=None):
print('下载:'+url)
#设置用户代理
headers = {'user_agent':user_agent}
request = ure.Request(url,headers=headers)
#支持代理
opener = ure.build_opener()
if proxy:
proxy_params = {urllib.parse.urlparse(url).scheme: proxy}
opener.add_handler(ure.ProxyHandler(proxy_params))
try:
#下载网页
# html = ure.urlopen(request).read()
html = opener.open(request).read()
except ure.URLError as e:
print('下载失败'+e.reason)
html=None
if num>0:
#遇到5XX错误时,递归调用自身重试下载,最多重复2次
if hasattr(e,'code') and 500<=e.code<600:
return download(url,num=num-1)
return html
def writeXls(sale_list):
#如果Excel不存在,创建Excel,否则直接打开已经存在文档
if 'P20销售情况.xlsx' not in os.listdir():
wb =openpyxl.Workbook()
else:
wb =openpyxl.load_workbook('P20销售情况.xlsx')
sheet = wb['Sheet']
sheet['A1'] = '颜色'
sheet['B1'] = '版本'
sheet['C1'] = '内存'
sheet['D1'] = '评论'
sheet['E1'] = '评论时间'
x = 2
#迭代所有销售信息(列表)
for s in sale_list:
#获取颜色等信息
content = s[0]
creationTime = s[1]
productColor = s[2]
productSize = s[3]
saleValue = s[4]
# 将颜色等信息添加到Excel
sheet['A' + str(x)] = productColor
sheet['B' + str(x)] = productSize
sheet['C' + str(x)] = saleValue
sheet['D' + str(x)] = content
sheet['E' + str(x)] = creationTime
x += 1
wb.save('P20销售情况.xlsx') page = 0
allSale =[]
waitFor = WaitFor(2)
#预编译匹配颜色、版本、内存等信息的正则表达式
regex = re.compile('"content":"(.*?)","creationTime":"(.*?)".*?"productColor":"(.*?)","productSize":"(.*?)".*?"saleValue":"(.*?)"')
#这里只下载20页数据,可以设置大一些(因为就算没评论信息,也能下载到一些标签信息等,所以可以if 正则没匹配的话就结束循环,当然,下面没处理这个)
while page<20:
if page==0:
url = 'https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv176&productId=6733026&score=0&sortType=5&page=' + str(page) + '&pageSize=10&isShadowSku=0&fold=1'
else:
url = 'https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv176&productId=6733026&score=0&sortType=5&page=' + str(page) + '&pageSize=10&isShadowSku=0&rid=0&fold=1'
waitFor.wait(url)
html = download(url)
html = html.decode('GBK')
#以列表形式返回颜色、版本、内存等信息
sale = regex.findall(html)
#将颜色、版本、内存等信息添加到allSale中(扩展allSale列表)
allSale.extend(sale)
page += 1 writeXls(allSale)
(三) 数据分析
1、 下载后的数据如下图所示。

2、 生成图表。
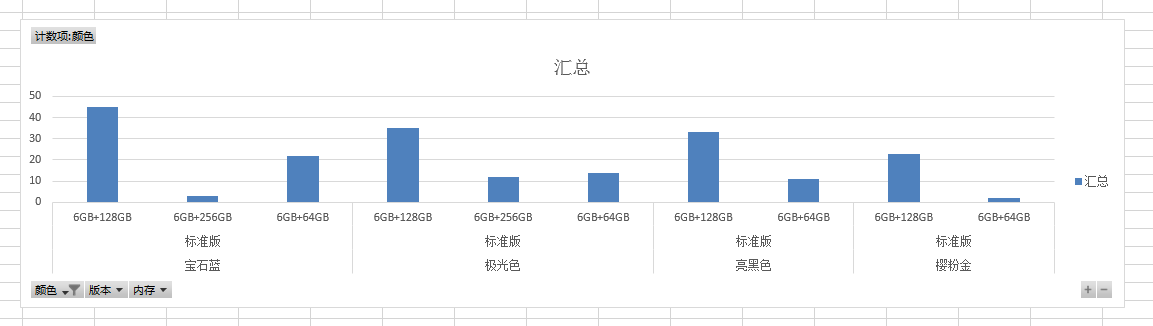
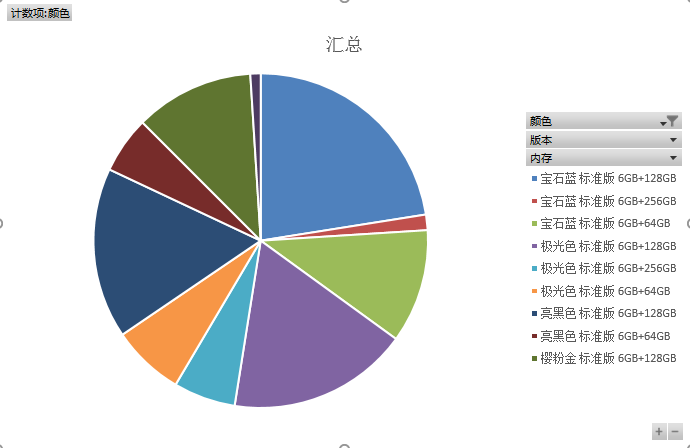
我的博客即将搬运同步至腾讯云+社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=3ff1njli6hwk0
Python网络爬虫笔记(五):下载、分析京东P20销售数据的更多相关文章
- Python网络爬虫实战(五)批量下载B站收藏夹视频
我们除了爬取文本信息,有的时候还需要爬媒体信息,比如视频图片音乐等.就拿B站来说,我的收藏夹内的视频可能随时会失效,所以把它们下载到本地是非常保险的一件事. 对于这种大量列表型的数据,可以猜测B站收藏 ...
- Python网络爬虫笔记(二):链接爬虫和下载限速
(一)代码1(link_crawler()和get_links()实现链接爬虫) import urllib.request as ure import re import urllib.parse ...
- python网络爬虫笔记(五)
一.python的类对象的继承 1.所有的父类都是object类,由于类可以起到模块的作用,因此,可以在创建实例的时候,巴西一些认为必须要绑定的属性填写上去,通过定义一个特殊的方法 __init__, ...
- Python网络爬虫笔记(四):使用selenium获取动态加载的内容
(一) 说明 上一篇只能下载一页的数据,第2.3.4....100页的数据没法获取,在上一篇的基础上修改了下,使用selenium去获取所有页的href属性值. 使用selenium去模拟浏览器有点 ...
- Python网络爬虫笔记(一):网页抓取方式和LXML示例
(一) 三种网页抓取方法 1. 正则表达式: 模块使用C语言编写,速度快,但是很脆弱,可能网页更新后就不能用了. 2. Beautiful Soup 模块使用Python编写,速度慢. ...
- [Python]网络爬虫(五):urllib2的使用细节与抓站技巧
转自:http://blog.csdn.net/pleasecallmewhy/article/details/8925978 前面说到了urllib2的简单入门,下面整理了一部分urllib2的使用 ...
- [Python]网络爬虫(五):urllib2的使用细节与抓站技巧(转)
1.Proxy 的设置 urllib2 默认会使用环境变量 http_proxy 来设置 HTTP Proxy. 如果想在程序中明确控制 Proxy 而不受环境变量的影响,可以使用代理. 新建test ...
- python网络爬虫笔记(九)
4.1.1 urllib2 和urllib是两个不一样的模块 urllib2最简单的就是使用urllie2.urlopen函数使用如下 urllib2.urlopen(url[,data[,timeo ...
- python网络爬虫笔记(八)
一.pthon 序列化json格式 1.将python内置对象转换成json 模块,dumps()方法返回的是一个str,内容是标准的JSON,dump()方法可以直接吧JSON写入一个file-li ...
随机推荐
- Python中的unittest和logging
今天使用Python的unittest模块写了些单元测试,现记录下要点: 使用unittest的基本格式如下: import unittest class Test(unittest.TestCase ...
- Git忽略规则.gitignore梳理
对于经常使用Git的朋友来说,.gitignore配置一定不会陌生.废话不说多了,接下来就来说说这个.gitignore的使用. 首先要强调一点,这个文件的完整文件名就是".gitignor ...
- C语言程序设计(基础)- 第0次作业
亲爱的同学们,恭喜你成为一名大学生,我也很荣幸能够带大家一起学习大学的第一门专业基础课.还在军训的你,肯定对大学生活和计算机专业有着美好的憧憬,那么大学生活是什么样子的那?计算机专业应该怎么学习那?请 ...
- 《团队-OldNote-项目总结》
我们小组做的是手机便签的app---OldNote 最开始我们想解决普通手机便签无法进行语音和照片的备忘这一问题,但是由于没有做过拍照和录音的经验怕由于技术原因无法达成目的,就没敢写在需求分析中.当完 ...
- C语言第三周作业---单层循环
一.PTA实验作业 题目1 1.实验代码 int N = 0,i; char sex; float a[9], height; scanf("%d\n", &N); for ...
- Spring邮件发送1
注意:邮件发送code中,邮件服务器的申请和配置是比较主要的一个环节,博主这里用的是QQ的邮件服务器.有需要的可以谷歌.百度查下如何开通. 今天看了下Spring的官方文档的邮件发送这一章节.在这里记 ...
- Class-Based-View(CBV)
我们都知道,Python是一个面向对象的编程语言,如果只用函数来开发,有很多面向对象的优点就错失了(继承.封装.多态).所以Django在后来加入了Class-Based-View.可以让我们用类写V ...
- VS 2008 开发WinCE程序 编译部署速度慢的解决办法
1.找到以下文件 C:\Windows\Microsoft.NET\Framework\v3.5\Microsoft.CompactFramework.Common.targets 2.用记事本打开该 ...
- 丢掉DDL,我用这招3分钟清空 MySQL 9亿记录数据表
摘要:最近由于福建开机广告生产环境的广告日志备份表主键(int类型)达到上限(21亿多),不能再写入数据,需要重新清空下该表并将主键重置,但由于表里有8亿多记录的数据量,使用重置命令及DDL命令执行地 ...
- MySql查询正在进行中的事务
用法 SELECT * FROM information_schema.INNODB_TRX 这个只能查询此刻正在进行中的事务,已经完成的是查不到的 表字段定义 The INFORMATION_SCH ...