[LTR] 信息检索评价指标(RP/MAP/DCG/NDCG/RR/ERR)
一、RP
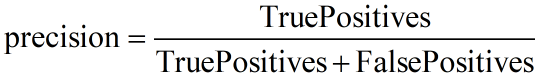
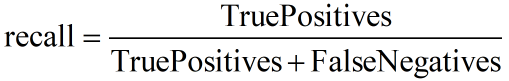
和 precision
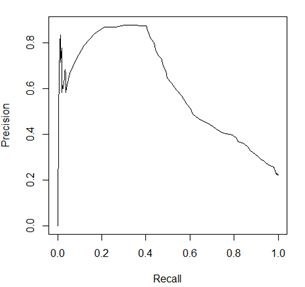
反映了模型性能的两个方面,单一依靠某个指标并不能较为全面的评价一个模型的性能。
recall 和 precision 的影响,较为全面的评价一个模型。
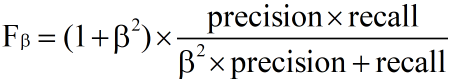
表示召回率比准确率重要一倍;F0.5-Score 表示准确率比召回率重要一倍。
二、MAP
Precision),即
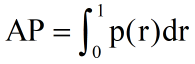
的计算是对排序位置敏感的,相关文档排序的位置越靠前,检索出相关的文档越多,AP 值越大。
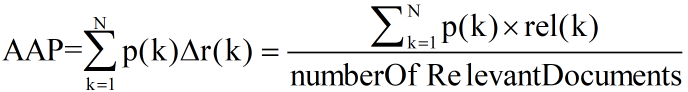
其中,N 代表所有相关文档的总数,p(k) 表示能检索出 k 个相关文档时的 precision 值,而
△r(k) 则表示检索相关文档个数从 k-1 变化到 k 时(通过调整阈值)recall 值的变化情况。
个文档是否相关,若相关则为1,否则为0,则可以简化公式为:
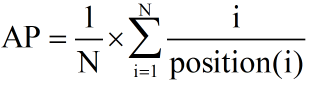
表示相关文档总数,position(i) 表示第 i 个相关文档在检索结果列表中的位置。
Precision)即多个查询的平均正确率(AP)的均值,从整体上反映模型的检索性能。
对应总共有5个相关文档。当通过模型执行查询1、2时,分别检索出4个相关文档(Rank=1、2、4、7)和3个相关文档(Rank=1、3、5)。
MAP=(0.83+0.45)/2=0.64。
三、NDCG
1、CG(Cumulative Gain)累计效益
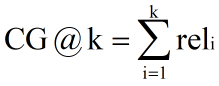
k 表示 k 个文档组成的集合,rel 表示第 i 个文档的相关度,例如相关度分为以下几个等级:
| Relevance Rating | Value |
| Perfect | 5 |
| Excellent | 4 |
| Good | 3 |
| Fair | 2 |
| Simple | 1 |
| Bad | 0 |
2、DCG(Discounted Cumulative Gain)
CG 的计算公式得出的排名是相同的,但是显然前者的排序好一些。
1/log2(i+1),其中
log2(i+1)
为折扣因子;
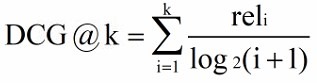
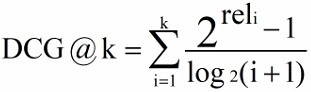
3、IDCG(ideal DCG)
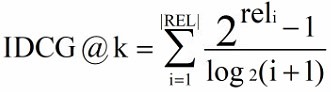
4、NDCG(Normalized
DCG)
的计算结果。所以不能简单的对不同查询的 DCG 结果进行平均,需要先归一化处理。
相差多大:
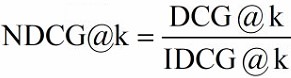
NDCG。
5、例子
List,当假设用户的选择与排序结果无关,则根据相关度生成的累计增益如下图所示:
| URL | rel | Gain(2reli-1) | Cumulative Gain | |
| #1 | http://abc.go.com | 5 | 31 | 31 |
| #2 | http://www.abctech.com | 2 | 3 | 34=31+3 |
| #3 | http://abcnews.go.com/sections/ | 4 | 15 | 49=31+3+15 |
| #4 | http://www.abc.net.au/ | 4 | 15 | 64=31+3+15+15 |
| #5 | http://abcnews.com/ | 4 | 15 | 79=31+3+15+15+15 |
| #6 | ... | ... | ... | ... |
factor):1/(log(i+1)/log2) = log2/log(i+1)。
| URL | rel | Gain(2reli-1) | Cumulative Gain |
DCG | |
| #1 | http://abc.go.com | 5 | 31 | 31 | 31=31×1 |
| #2 | http://www.abctech.com | 2 | 3 | 34=31+3 | 32.9=31+3×0.63 |
| #3 | http://abcnews.go.com/sections/ | 4 | 15 | 49=31+3+15 | 40.4=32.9+15×0.50 |
| #4 | http://www.abc.net.au/ | 4 | 15 | 64=31+3+15+15 | 46.9=40.4+15×0.43 |
| #5 | http://abcnews.com/ | 4 | 15 | 79=31+3+15+15+15 | 52.7=46.9+15×0.39 |
| #6 | ... | ... | ... | ... | ... |
而理想的情况,根据相关度 rel 递减排序后计算 DCG:
| URL | rel | Gain(2reli-1) | IDCG(Max DCG) |
|
| #1 | http://abc.go.com | 5 | 31 | 31=31×1 |
| #3 | http://abcnews.go.com/sections/ | 4 | 15 | 40.5=31+15×0.63 |
| #4 | http://www.abc.net.au/ | 4 | 15 | 48.0=40.5+15×0.5 |
| #5 | http://abcnews.com/ | 4 | 15 | 54.5=48.0+15×0.43 |
| #7 | http://abc.org/ | 4 | 15 | 60.4=54.5+15×0.39 |
| #9 | ... | ... | ... | ... |
所以最终得出 NDCG 结果:
| URL | rel | Gain(2reli-1) | Cumulative Gain |
DCG | IDCG(Max DCG) | NDCG | |
| #1 | http://abc.go.com | 5 | 31 | 31 | 31=31×1 | 31=31×1 | 1=31/31 |
| #2 | http://www.abctech.com | 2 | 3 | 34=31+3 | 32.9=31+3×0.63 | 40.5=31+15×0.63 | 0.81=32.9/40.5 |
| #3 | http://abcnews.go.com/sections/ | 4 | 15 | 49=31+3+15 | 40.4=32.9+15×0.50 | 48.0=40.5+15×0.5 | 0.84=40.4/48.0 |
| #4 | http://www.abc.net.au/ | 4 | 15 | 64=31+3+15+15 | 46.9=40.4+15×0.43 | 54.5=48.0+15×0.43 | 0.86=46.9/54.5 |
| #5 | http://abcnews.com/ | 4 | 15 | 79=31+3+15+15+15 | 52.7=46.9+15×0.39 | 60.4=54.5+15×0.39 | 0.87=52.7/60.4 |
| #6 | ... | ... | ... | ... | ... | ... |
四、ERR
1、RR(reciprocal rank)
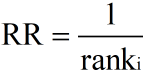
2、MRR(mean reciprocal
rank)
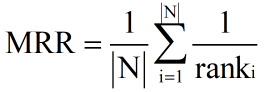
i 个查询的第一个相关文档的排名。
3、Cascade Model(瀑布模型)
i 个位置的文档项被点击的概率为:
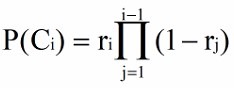
i 个文档被点击的概率,前 i-1 个文档则没有被点击,概率均为 1-rj;
4、ERR(Expected reciprocal rank)
计算第一个相关文档的位置倒数不同。
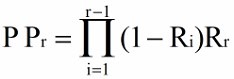
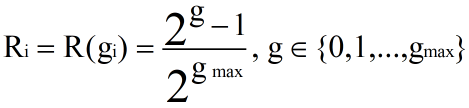
g 表示文档的相关度,参考 NDCG 中的 rel。
不一定是计算用户需求满足时停止的位置的倒数的期望,它可以是基于位置的函数 φ(r)
,只要满足 φ(0)=1,且随着 r→∞,φ(r)→0。
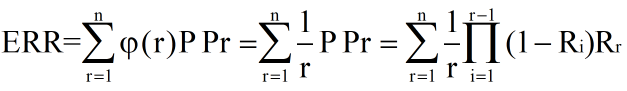
时就是 ERR,当 φ(r)=1/log2(r+1) 就是DCG。
参考链接:
[LTR] 信息检索评价指标(RP/MAP/DCG/NDCG/RR/ERR)的更多相关文章
- Kendall’s tau-b,pearson、spearman三种相关性的区别(有空整理信息检索评价指标)
同样可参考: http://blog.csdn.net/wsywl/article/details/5889419 http://wenku.baidu.com/link?url=pEBtVQFzTx ...
- [Scala] 实现 NDCG
一.关于 NDCG [LTR] 信息检索评价指标(RP/MAP/DCG/NDCG/RR/ERR) 二.代码实现 1.训练数据的加载解析 import scala.io.Source /* * 训练行数 ...
- Learning To Rank之LambdaMART前世今生
1. 前言 我们知道排序在非常多应用场景中属于一个非常核心的模块.最直接的应用就是搜索引擎.当用户提交一个query.搜索引擎会召回非常多文档,然后依据文档与query以及用户的相关程度对 ...
- [笔记]Learning to Rank算法介绍:RankNet,LambdaRank,LambdaMart
之前的博客:http://www.cnblogs.com/bentuwuying/p/6681943.html中简单介绍了Learning to Rank的基本原理,也讲到了Learning to R ...
- Learning to Rank算法介绍:RankNet,LambdaRank,LambdaMart
之前的博客:http://www.cnblogs.com/bentuwuying/p/6681943.html中简单介绍了Learning to Rank的基本原理,也讲到了Learning to R ...
- 推荐系统排序(Ranking)评价指标
一.准确率(Precision)和召回率(Recall) (令R(u)是根据用户在训练集上的行为给用户作出的推荐列表,而T(u)是用户在测试集上的行为列表.) 对用户u推荐N个物品(记为R(u) ...
- 百度Map调用
baiduMap API 根据地址查询经纬度 http://api.map.baidu.com/geocoder?address=要查询的地址&output=json&key=你的ke ...
- SPOJ - ADAFIELD ,Set+map,STL不会超时!
ADAFIELD - Ada and Field 这个题,如果用一个字来形容的话:-----------------------------------------------嗯! 题意:n*m的空白 ...
- go语言之进阶篇json解析到map
1.json解析到map(通过类型断言,找到值和value类型) 示例: package main import ( "encoding/json" "fmt" ...
随机推荐
- zTree实现删除树子节点
zTree实现删除树子节点 1.实现源码 <!DOCTYPE html> <html> <head> <title>zTree实现基本树</tit ...
- TypeError: Error #1034: 强制转换类型失败:无法将 "" 转换为 Array。
1.错误描述 TypeError: Error #1034: 强制转换类型失败:无法将 "" 转换为 Array. at mx.charts.series::LineSeries/ ...
- 小白——java基础之数据类型
PS:此文章为小白提供,大佬请绕道!!!! 首先特别感谢大才哥给我提供这个平台,未来我希望把java这个版块的内容补全. 今天要讲的是数据类型,最最最基础的内容~ java标识符.数据类型.关键字 开 ...
- iOS - MFi 认证
1.MFi 认证 1.1 什么是 MFi 认证 苹果 MFi 认证,是苹果公司(Apple Inc.)对其授权配件厂商生产的外置配件的一种标识使用许可,是 Apple 公司 "Made fo ...
- 简要分析javascript的选项卡和轮播图
选项卡 思路 1.按钮和展示的页面要对应:分别遍历,记住当前按钮的索引,让其成为展示页面的索引 2.只出现所对应的页面:所有的页面隐藏,只展示想要的页面 只展示js代码 for(var i=0;i&l ...
- 【CJOJ1793】【USACO 4.3.2】素数方阵
题面 Description 在下面的方格中,每行,每列,以及两条对角线上的数字可以看作是五位的素数.方格中的行按照从左到右的顺序组成一个素数,而列按照从上到下的顺序.两条对角线也是按照从左到右的顺序 ...
- haproxy实现会话保持(2):stick table
*/ .hljs { display: block; overflow-x: auto; padding: 0.5em; color: #333; background: #f8f8f8; } .hl ...
- CentOS7下安装MySQL的安装与配置(yum) (转)
原文链接:http://www.centoscn.com/mysql/2016/0626/7537.html 1.配置YUM源 在MySQL官网中下载YUM源rpm安装包:http://dev.mys ...
- 号称了解mesos双层调度的你,先来回答下面这五个问题!
一提mesos,很多人知道双层调度,但是大多数理解都在表面,不然试一下下面五个问题. 问题一:如果有两个framework,一万个节点,按说应该平均分配给两个framework,怎么个分法?一人一台这 ...
- 深度剖析HashMap的数据存储实现原理(看完必懂篇)
深度剖析HashMap的数据存储实现原理(看完必懂篇) 具体的原理分析可以参考一下两篇文章,有透彻的分析! 参考资料: 1. https://www.jianshu.com/p/17177c12f84 ...