TensorFlow-谷歌深度学习库 体验一二三
一个TensorFlow的运算可以看作是一个数据流图。
一个图呢则由一组操作和数据集组成。
- 操作(operation)代表运算单元
- 数据(tensor) 代表在各运算单元流动的数据单元
要想使用一个数据流图,必须把它注册为默认的图。
注意:图这个class并不是线程安全的,它所有的方法也不是。
将一个图设为默认的图的方法:
g = tf.Graph()
with g.as_default(): # 将图设为默认
# define operations and tensors in g
c = tf.constant(30.0)
as_default(self)
返回一个将Graph设为默认的context manager。如果你想要在一个进程中创建多个图考虑使用。如果你不显示调用,一个全局默认图将被提供。
默认图所属当前线程,如果你创建了一个新的线程,你必须在那个线程中显示调用as_default方法。
创建常量tensor
constant(value, dtype=None, shape=None, name='Const', verify_shape=False)
'''
Args:
value: A constant value (or list) of output type `dtype`.
dtype: The type of the elements of the resulting tensor.
shape: Optional dimensions of resulting tensor.
name: Optional name for the tensor.
verify_shape: Boolean that enables verification of a shape of values.
Returns:
A Constant Tensor.
Raises:
TypeError: if shape is incorrectly specified or unsupported.
'''
传入value创建常量tensor。value可以是一个常量值或常量列表。 参数shape是可选的,如果不提供默认为传入value的shape。
同理,dtype也是可选的,不提供则默认为传入value的dtype。
```python
# Constant 1-D Tensor populated with value list.
tensor = tf.constant([1, 2, 3, 4, 5, 6, 7]) => [1 2 3 4 5 6 7]
# Constant 2-D tensor populated with scalar value -1.
tensor = tf.constant(-1.0, shape=[2, 3]) => [[-1. -1. -1.]
[-1. -1. -1.]]
```
创建变量tensor
w = tf.Variable(<initial-value>, name=<optional-name>)
一个变量维持图的状态。 变量在定义的时候要声明它的类型和shape, 在创建之后虽然值是可以改变的, 但类型和shape是固定的。
和其他tensor一样,被创建的变量可以被图中的操作当作输入使用。
当你启用已经定义好的图时,所有变量必须显示的被初始化,之后你才可以运行操作使用他们的值。你也可以从文件中读取完成初始化步骤。
创建placeholder
placeholder(dtype, shape=None, name=None)
给一个tensor插入placeholder,并且会在之后补充进去。
通过`Session.run()`的备选参数`feed_dict` 将之前的placeholder的值补进去, 如果你没有喂进任何数据就运行会话对象将报错。
```python
x = tf.placeholder(tf.float32, shape=(1024, 1024))
y = tf.matmul(x, x)
with tf.Session() as sess:
print(sess.run(y)) # ERROR: will fail because x was not fed.
rand_array = np.random.rand(1024, 1024)
print(sess.run(y, feed_dict={x: rand_array})) # Will succeed.
```
计算logits tensor
logits = tf.matmul(tf_train_dataset, weights) + biases
计算softmax cross entropy,loss tensor
loss = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(labels=tf_train_labels, logits=logits))
softmax_cross_entropy_with_logits_v2(_sentinel=None, labels=None, logits=None, dim=-1, name=None)
Args:
_sentinel: Used to prevent positional parameters. Internal, do not use.
labels: Each row `labels[i]` must be a valid probability distribution.
logits: Unscaled log probabilities.
dim: The class dimension. Defaulted to -1 which is the last dimension.
name: A name for the operation (optional).
Returns:
A 1-D `Tensor` of length `batch_size` of the same type as `logits` with the
softmax cross entropy loss.
计算probability errors。 对于每一个想要预测的内容, 它必须有且只有一个标签。
参数为logits和labels,这个函数内部会自动处理soft max。

softmax: 将score转化成probability
def softmax(x):
"""Compute softmax values for each sets of scores in x."""
return np.exp(x) / np.sum(np.exp(x), axis = 0)
one-hot-encoding: 正确的label标为1,其他均为0. 比如有a,b,c三个label,a为正确的label标为1,b和c标为0
cross-entropy(用来衡量performance):

计算所有样本的综合loss:
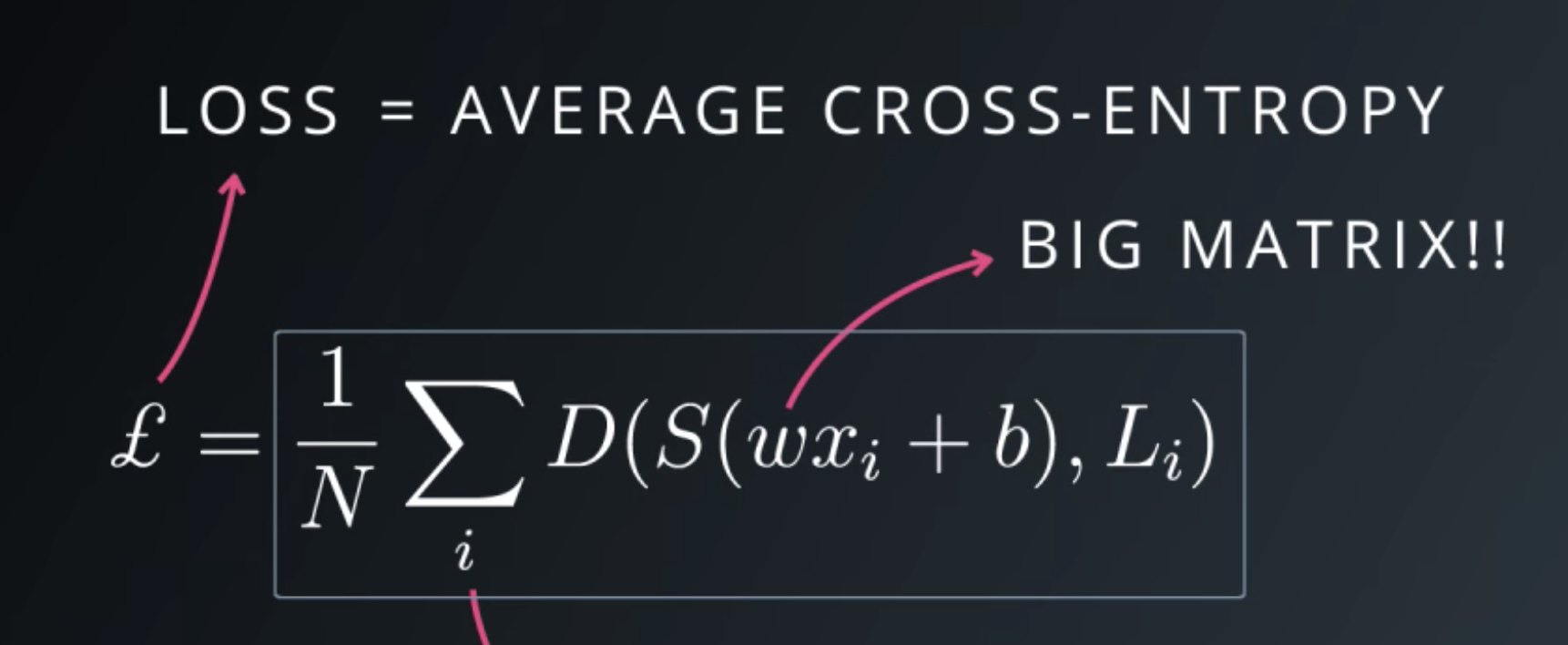
优化处理Optimizer: Gradient Descent Optimizer, 定义operation
使用梯度下降法找到最小的loss。 这个operation会更新涉及到的tensor的值。
class GradientDescentOptimizer(tensorflow.python.training.optimizer.Optimizer)
__init__(self, learning_rate, use_locking=False, name='GradientDescent')
Construct a new gradient descent optimizer.
Args:
learning_rate: A Tensor or a floating point value. The learning rate to use.
minimize(self, loss, global_step=None, var_list=None, gate_gradients=1,
aggregation_method=None, colocate_gradients_with_ops=False, name=None,
grad_loss=None)
Add operations to minimize `loss` by updating `var_list`.
This method simply combines calls `compute_gradients()` and `apply_gradients()`.
If you want to process the gradient before applying them call `compute_gradients()` and `apply_gradients()` explicitly instead of using this function. Args:
loss: A `Tensor` containing the value to minimize.
global_step: Optional `Variable` to increment by one after the variables have been updated. Returns:
An Operation that updates the variables in `var_list`. If `global_step` was not `None`, that operation also increments `global_step`. Raises:
ValueError: If some of the variables are not `Variable` objects.
什么是梯度下降?
误差方程 (Cost Function). 用来计算预测出来的和我们实际中的值有多大差别. 在预测数值的问题中. W是我们神经网络中的参数, 假设我们初始化的 W 在一个位置. 而这个位置的斜率也就是梯度下降中的梯度. loss误差最小的时候正是这条曲线最低的地方, 不过 W 却不知道这件事情, 他目前所知道的就是梯度线为自己在这个位置指出的一个下降方向, 我们就要朝着这个梯度的方向下降一点点. 在做一条切线, 发现我还能下降, 那我就朝着梯度的方向继续下降, 这时, 再展示出现在的梯度, 因为梯度线已经躺平了, 我们已经指不出哪边是下降的方向了, 所以这时我们就找到了 W 参数的最理想值. 简而言之, 就是找到梯度线躺平的点.
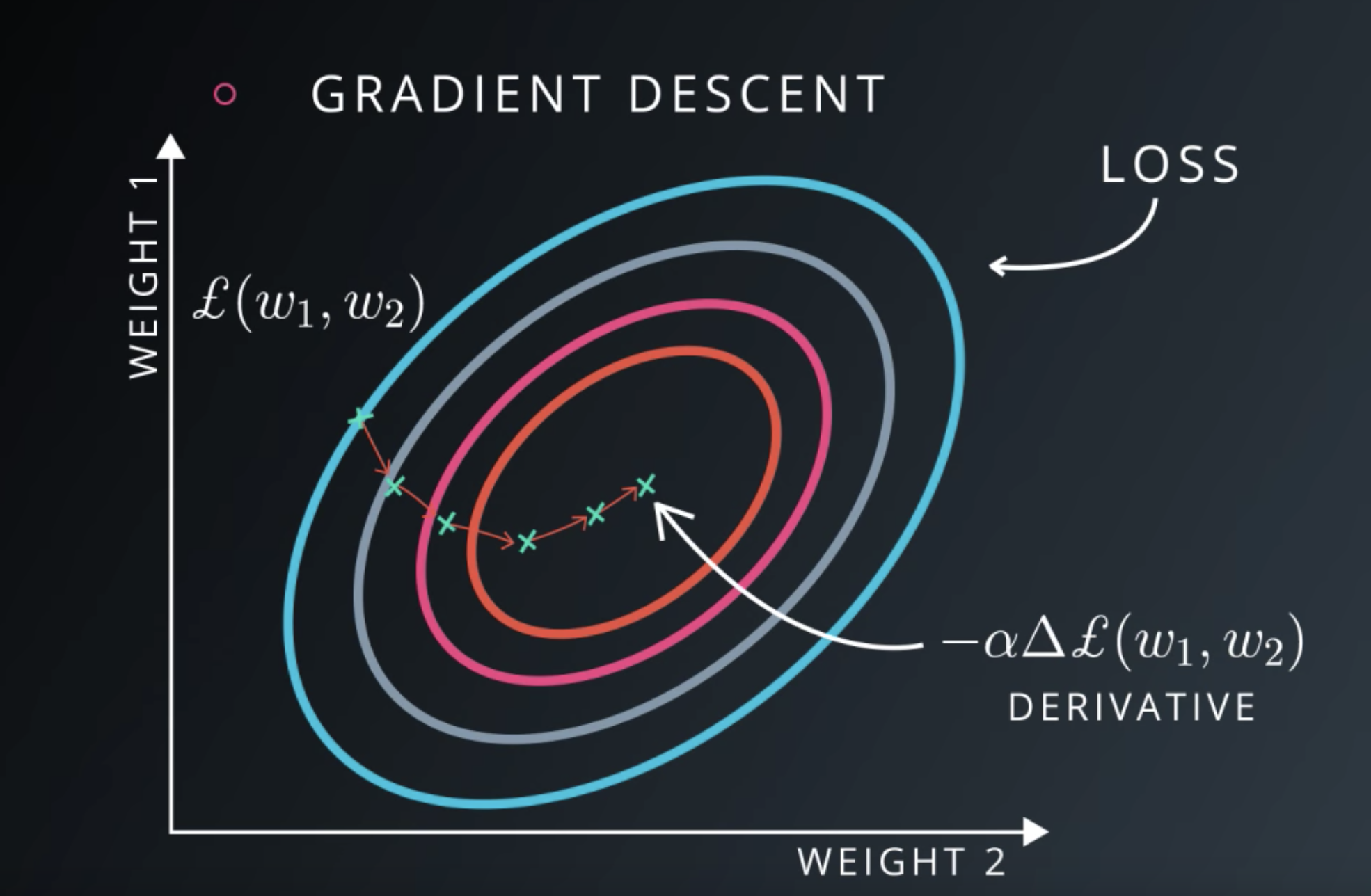
Session(会话)
用来运行tensorflow operation的类
会话对象封装了一个供ops类执行并且可以评估tensor的环境。
会话类会拥有自己的资源,为确保在使用后这些资源被释放,可以使用context manager
# Using the context manager.
with tf.Session() as sess:
sess.run(...)
在初始化创建一个会话对象的时候,如果没有指明图那么一个默认的图会被启用。如果你拥有多个图,那么你需要为每一个图初始化一个会话对象。
在会话类中,首先要初始化所有变量。使用global_variables_initializer()返回一个op并运行来初始化。
global_variables_initializer()
Returns an Op that initializes global variables.
Returns:
An Op that initializes global variables in the graph.
TensorFlow-谷歌深度学习库 体验一二三的更多相关文章
- Keras:基于Theano和TensorFlow的深度学习库
catalogue . 引言 . 一些基本概念 . Sequential模型 . 泛型模型 . 常用层 . 卷积层 . 池化层 . 递归层Recurrent . 嵌入层 Embedding 1. 引言 ...
- TensorFlow-谷歌深度学习库 手把手教你如何使用谷歌深度学习云平台
自己的电脑跑cnn, rnn太慢? 还在为自己电脑没有好的gpu而苦恼? 程序一跑一俩天连睡觉也要开着电脑训练? 如果你有这些烦恼何不考虑考虑使用谷歌的云平台呢?注册之后即送300美元噢-下面我就来介 ...
- windows下Anaconda3配置TensorFlow深度学习库
Anaconda3(python3.6)安装tensorflow Anaconda3中安装tensorflow3是非常简单的,仅需通过 pip install tensorflow 测试代码: imp ...
- 人工智能不过尔尔,基于Python3深度学习库Keras/TensorFlow打造属于自己的聊天机器人(ChatRobot)
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_178 聊天机器人(ChatRobot)的概念我们并不陌生,也许你曾经在百无聊赖之下和Siri打情骂俏过,亦或是闲暇之余与小爱同学谈 ...
- 深度学习库 SynapseML for .NET 发布0.1 版本
2021年11月 微软开源一款简单的.多语言的.大规模并行的机器学习库 SynapseML(以前称为 MMLSpark),以帮助开发人员简化机器学习管道的创建.具体参见[1]微软深度学习库 Synap ...
- 30个深度学习库:按Python、C++、Java、JavaScript、R等10种语言分类
30个深度学习库:按Python.C++.Java.JavaScript.R等10种语言分类 包括 Python.C++.Java.JavaScript.R.Haskell等在内的一系列编程语言的深度 ...
- TensorFlow和深度学习入门教程(TensorFlow and deep learning without a PhD)【转】
本文转载自:https://blog.csdn.net/xummgg/article/details/69214366 前言 上月导师在组会上交我们用tensorflow写深度学习和卷积神经网络,并把 ...
- TensorFlow和深度学习新手教程(TensorFlow and deep learning without a PhD)
前言 上月导师在组会上交我们用tensorflow写深度学习和卷积神经网络.并把其PPT的參考学习资料给了我们, 这是codelabs上的教程:<TensorFlow and deep lear ...
- 64位Win7下安装并配置Python3的深度学习库:Theano
注:本文全原创,作者:Noah Zhang (http://www.cnblogs.com/noahzn/) 这两天在安装Python的深度学习库:Theano.尝试了好多遍,CMake.MinGW ...
随机推荐
- tcp/ip 卷一 读书笔记(2)物理层和链路层网络
物理层和链路层网络 术语 链路 是一对相邻结点间的物理线路,中间没有任何其他的交换结点. 数据链路 除了物理线路外,还必须有通信协议来控制这些数据的传输. 帧 数据链路层的协议数据单元(PDU) 串行 ...
- 老机器安装Centos
512M内存,80G硬盘 ubuntu-server没有压力,但是因为很多平台只支持centos服务器linux系统 内存要超过1G默认才能用图形界面安装.装好之后即使256M内存都可以跑起来.lin ...
- Java StringBuilder 和 StringBuffer 源码分析
简介 StringBuilder与StringBuffer是两个常用的操作字符串的类.大家都知道,StringBuilder是线程不安全的,而StringBuffer是线程安全的.前者是JDK1.5加 ...
- HI3531由DMA 发起PCIe 事务
Hi3531 PCIe 控制器内含DMA 控制器,DMA 控制器包含有两个DMA 通道(一个 DMA 读通道和一个DMA 写通道).PCIe 控制器内包含的DMA 控制器用于大数据量 的存储器读写事务 ...
- freemarker报错之十四
1.错误描述 <html> <head> <meta http-equiv="content-type" content="text/htm ...
- ATA接口寄存器描述
ATA接口寄存器描述 .ATA接口的三种数据传输方式 位. )MDMA(Multiword DMA)传输,用于数据传输.ATA主机控制器向ATA设备下达MDMA传输命令后,等待设备向主机发送DMARQ ...
- LINQ 按多个字段排序(orderby、thenby、Take)
LINQ 按多个字段排序(orderby.thenby.Take) orderby 子句解析为 OrderBy()方法,orderby descending 子句解析为OrderBy Descend ...
- Java Breakpoint
1.错误描述 Java Breakpoint Unable to install breakpoint in com.you.humb.web.commom.dao.impl.ExportDaoImp ...
- unix时间戳转换成标准时间(c#)
//---unix时间戳转换成标准时间(c#)---// /* string timeStamp = "1144821796"; DateTime dtSt ...
- asp.net+jQueryRotate开发幸运大转盘
在线抽奖程序在很多网站上很多,抽奖形式多种多样,Flash抽奖偏多,本文将给大家介绍jQuery转盘抽奖,结合代码实例将使用jQuery和asp.net来实现转盘抽奖程序,为了便于理解,文章贴出实现源 ...