并发系列(2)之 ThreadLocal 详解
本文将主要结合源码讲述 ThreadLocal 的使用场景和内部结构,以及 ThreadLocalMap 的内部结构;另外在阅读文本之前只好先了解一下引用和 HashMap 的相关知识,可以参考 Reference 框架概览、Reference 完全解读、HashMap 相关;
一、使用场景
通常情况下避免多线程问题有三种方法:
- 不使用共享状态变量;
- 状态变量为不可变的;
- 访问共享变量时使用同步;
而 ThreadLocal 则是通过每个线程独享状态变量的方式,即不使用共享状态变量,来消除多线程问题的,例如:
@Slf4j public class TestThreadlocal {
private static ThreadLocal<String> local = ThreadLocal.withInitial(() -> "init");
public static void main(String[] args) throws InterruptedException {
Runnable r = new TT();
new Thread(r, "thread1").start();
Thread.sleep(2000);
new Thread(r, "thread2").start();
log.info("exit");
}
private static class TT implements Runnable {
@Override
public void run() {
log.info(local.get());
local.set(Thread.currentThread().getName());
log.info("set local name and get: {}", local.get());
}
}
}
// 打印:
[14 19:27:39,818 INFO ] [thread1] TestThreadlocal - init
[14 19:27:39,819 INFO ] [thread1] TestThreadlocal - set local name and get: thread1
[14 19:27:41,818 INFO ] [main] TestThreadlocal - exit
[14 19:27:41,819 INFO ] [thread2] TestThreadlocal - init
[14 19:27:41,819 INFO ] [thread2] TestThreadlocal - set local name and get: thread2
可以看到线程1和线程2虽然使用的是同一个 ThreadLocal 变量,但是他们之间却没有互相影响;其原因就是每个使用 ThreadLocal 变量的线程都会在各自的线程中保存一份 独立 的副本,所以各个线程之间没有相互影响;
二、ThreadLocal 结构概述
ThreadLocal 的大体结构如图所示:
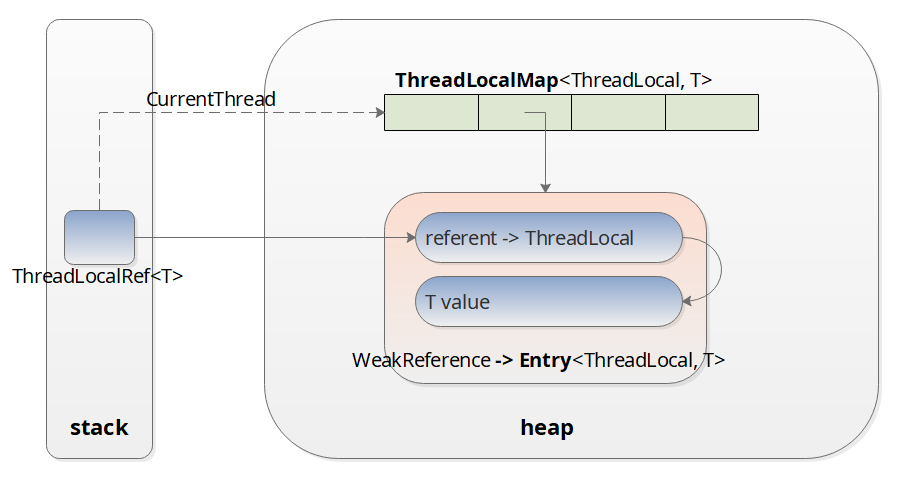
如图所示:
- 在使用 ThreadLocal 的时候,是首先获得当前线程;
- 然后取到线程的成员变量 ThreadLocalMap(暂时可以理解为和WeakHashMap相似,后面会详细讲到);
- 然后以当前的 ThreadLocal 变量作为 Key,取到 Entry;
- 最后返回 Entry 中的 value;
其源代码如下:
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
ThreadLocalMap.Entry:
另外还需要注意这里的 Entry,
static class ThreadLocalMap {
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
...
}
Reference(T referent) {
this(referent, null);
}
可以看到 Entry 继承了 WeakReference,并且没有传入 ReferenceQueue;关于 Reference 的部分下面我简单介绍,具体的可以参考我上面提到了两个博客;
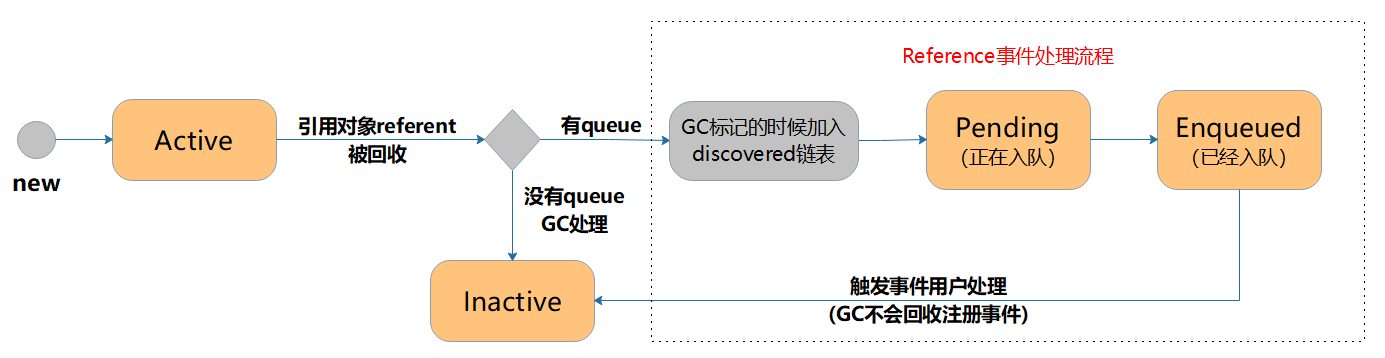
WeakReference 表示当传入的 referent(这里就是 ThreadLocal 自身),变成弱引用的时候(即没有强引用指向他的时候);下一次 GC 将自动回收弱引用;这里没有传入 ReferenceQueue,也就代表不能集中监测回收已弃用的 Entry,而需要再次访问到对应的位置时才能检测到,具体内容下面还有讲到,注意这也是和 WeakHashMap 最大的两个区别之一;
注意如果没有手动移除 ThreadLocal,而他有一直以强引用状态存活,就会导致 value 无法回收,至最终 OOM;所以在使用 ThreadLocal 的时候,最后一定要手动移除;
三、ThreadLocalMap 结构概述
1. set 方法
ThreadLocalMap 看名字大致可以知道是类似于 HashMap的数据结构;但是有一个重要的区别是,HashMap 使用拉链法解决哈希冲突,而 ThreadLocalMap 是使用线性探测法解决哈希冲突;具体结构如图所示:
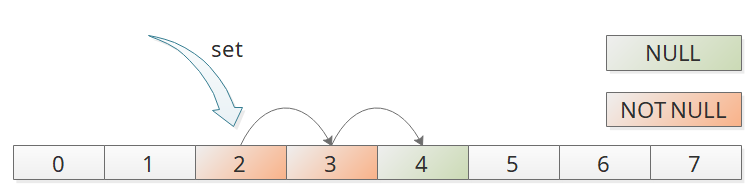
如图所示,ThreadLocalMap 里面没有链表的结构,当使用 threadLocalHashCode & (len - 1); 定位到哈希槽时,如果该位置为空则直接插入,如果不为空则检查下一个位置,直到遇到空的哈希槽;
另外它和我们通常见到的线性探测有点区别,在插入或删除的时候,会有哈希槽的移动;
源码如下:
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value); // 延迟初始化
}
private void set(ThreadLocal<?> key, Object value) {
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1); // 定位哈希槽
// 如果原本的位置不为空,则依次向后查找
for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
// 如果 threadLocal 已经存在,则直接用新值替代旧值
if (k == key) {
e.value = value;
return;
}
// 如果向后找到一个已经弃用的哈希槽,则将其替换
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
// 如果定位的哈希槽为空,则直接插入新值
tab[i] = new Entry(key, value);
int sz = ++size;
// 最后扫描其他弃用的哈希槽,如果最终超过阈值则扩容
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
}
private void replaceStaleEntry(ThreadLocal<?> key, Object value, int staleSlot) {
Entry[] tab = table;
int len = tab.length;
Entry e;
int slotToExpunge = staleSlot;
// 以 staleSlot 为基础,向前查找到最前面一个弃用的哈希槽,并确立清除开始位置
for (int i = prevIndex(staleSlot, len); (e = tab[i]) != null; i = prevIndex(i, len))
if (e.get() == null) slotToExpunge = i;
// 以 staleSlot 为基础,向后查找已经存在的 ThreadLocal
for (int i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
// 如果向后还有目标 ThreadLocal,则交换位置
if (k == key) {
e.value = value;
tab[i] = tab[staleSlot];
tab[staleSlot] = e;
// 刚交换的位置如果等于清除开始位置,则将其指向目标位置之后
if (slotToExpunge == staleSlot) slotToExpunge = i;
// 从开始清除位置开始扫描全表,并清除
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
return;
}
// 如果在目标位置后面未找到目标 ThreadLocal,则 staleSlot 仍然是目标位置,并将开始清除位置指向后面
if (k == null && slotToExpunge == staleSlot)
slotToExpunge = i;
}
// 在目标位置替换
tab[staleSlot].value = null;
tab[staleSlot] = new Entry(key, value);
// 如果开始清除的位置,不是目标位置,则扫描全表并清除
if (slotToExpunge != staleSlot)
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
}
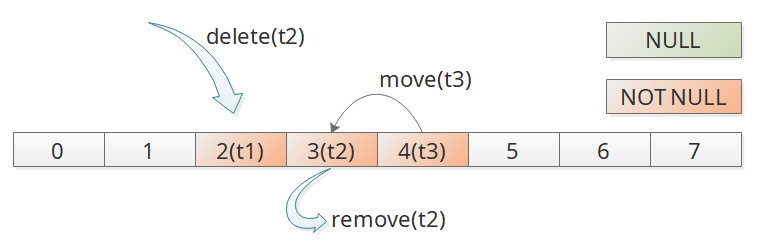
其中总体思路是:
- 如果目标位置为空,则直接插入;
- 如果不为空,则向后查询,看是否有目标key存在,如果存在则交换位置,并插入;
- 另外还需要确定一个跳跃扫描全表的起始位置,必须是弃用的哈希槽,如果目标位置前面有就找最前面的,如果没有就用后面的;
2. get 方法
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
private Entry getEntry(ThreadLocal<?> key) {
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
if (e != null && e.get() == key)
return e;
else
return getEntryAfterMiss(key, i, e);
}
private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) {
Entry[] tab = table;
int len = tab.length;
while (e != null) {
ThreadLocal<?> k = e.get();
if (k == key)
return e;
if (k == null)
expungeStaleEntry(i);
else
i = nextIndex(i, len);
e = tab[i];
}
return null;
}
从源码里面也可以看到上面讲的逻辑:
- 首先获取 ThreadLocalMap,如果 map 为空则初始化;也可以使用
Thread.withInitial(Supplier<? extends S> supplier);工厂方法创建以初始值的 ThreadLocal,或则直接覆盖Thread.initialValue()方法; - 然后用哈希定位哈希槽,如果命中则返回,未命中则向后一次查询;
- 如果最终未找到,则用
Thread.initialValue()方法返回初始值;
3. remove 方法
public void remove() {
ThreadLocalMap m = getMap(Thread.currentThread());
if (m != null) m.remove(this);
}
private void remove(ThreadLocal<?> key) {
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
if (e.get() == key) {
e.clear();
expungeStaleEntry(i);
return;
}
}
}
public void clear() {
this.referent = null;
}
移除的逻辑也可 HashMap 类似:
- 首先查找到目标哈希槽,然后清除;
- 注意这里的清除并非直接将 Entry 置为 null,而是先将 WeakReference 的 referent置为空,在扫描全表;其实是在模拟了 WeakReference 清除的过程,如果 ThreadLocal 变成弱引用,在访问一次 ThreadLocalMap,其清除的过程是一样的;
- 另外注意这里清除后和 HashMap 一样,容量是不会缩小的;
4. ThreadLocal 哈希计算
int index = key.threadLocalHashCode & (len-1);
private final int threadLocalHashCode = nextHashCode();
private static int nextHashCode() { return nextHashCode.getAndAdd(HASH_INCREMENT); }
private static AtomicInteger nextHashCode = new AtomicInteger();
private static final int HASH_INCREMENT = 0x61c88647;
这里哈希槽的定位仍然是使用的除留余数法,当容量是2的幂时,hash % length = hash & (length-1);但是 ThreadLocalMap 和 HashMap 有点区别的是,ThreadLocalMap 的 key 都是 ThreadLocal,如果这里使用通常意义的哈希计算方法,那肯定每个 key 都会发生哈希碰撞;所以需要用一种方法将相同的 key 区分开,并均匀的分布到 2的幂的数组中;
所以就看到了上面的计算方法,ThreadLocal 的哈希值每次增加 0x61c88647;具体原因大家可以参见源码注释,其目的就是能使 key 均匀的分布到 2的幂的数组中;
5. 清除方法
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
private boolean cleanSomeSlots(int i, int n) {
boolean removed = false;
Entry[] tab = table;
int len = tab.length;
do {
i = nextIndex(i, len);
Entry e = tab[i];
if (e != null && e.get() == null) {
n = len;
removed = true;
i = expungeStaleEntry(i);
}
} while ( (n >>>= 1) != 0);
return removed;
}
private int expungeStaleEntry(int staleSlot) {
Entry[] tab = table;
int len = tab.length;
// expunge entry at staleSlot
tab[staleSlot].value = null;
tab[staleSlot] = null;
size--;
// Rehash until we encounter null
Entry e;
int i;
for (i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
if (k == null) {
e.value = null;
tab[i] = null;
size--;
} else {
int h = k.threadLocalHashCode & (len - 1);
if (h != i) {
tab[i] = null;
// Unlike Knuth 6.4 Algorithm R, we must scan until
// null because multiple entries could have been stale.
while (tab[h] != null)
h = nextIndex(h, len);
tab[h] = e;
}
}
}
return i;
}
expungeStaleEntry:
- 首先清除目标位置;
- 然后向后依次扫描,直到遇到空的哈希槽;
- 如果遇到已弃用的哈希槽则清除,如果遇到因哈希冲突后移的 ThreadLocal,则前移;
cleanSomeSlots 则是向后偏移调用 expungeStaleEntry 方法 log(n) 次,cleanSomeSlots(expungeStaleEntry(slotToExpunge), len); 连用就可以扫描全表清除已弃用的哈希槽;
6. 扩容方法
private void rehash() {
expungeStaleEntries();
// Use lower threshold for doubling to avoid hysteresis
if (size >= threshold - threshold / 4) resize();
}
private void expungeStaleEntries() {
Entry[] tab = table;
int len = tab.length;
for (int j = 0; j < len; j++) {
Entry e = tab[j];
if (e != null && e.get() == null) expungeStaleEntry(j);
}
}
private void resize() {
Entry[] oldTab = table;
int oldLen = oldTab.length;
int newLen = oldLen * 2;
Entry[] newTab = new Entry[newLen];
int count = 0;
for (int j = 0; j < oldLen; ++j) {
Entry e = oldTab[j];
if (e != null) {
ThreadLocal<?> k = e.get();
if (k == null) {
e.value = null; // Help the GC
} else {
int h = k.threadLocalHashCode & (newLen - 1);
while (newTab[h] != null)
h = nextIndex(h, newLen);
newTab[h] = e;
count++;
}
}
}
setThreshold(newLen);
size = count;
table = newTab;
}
扩容时:
- 首先扫描全表清除已弃用的哈希槽;
- 如果清除后仍然超过阈值,则扩容;
- 扩容时,容量增加 1 倍(初始容量为 16,所以容量一直是2的幂),然后将旧表中的值,依次插到新表;
四、InheritableThreadLocal
InheritableThreadLocal 是可以被继承的 ThreaLocal;在 Thread 中有成员变量用来继承父类的 ThreadLocalMap ;ThreadLocal.ThreadLocalMap inheritableThreadLocals;比如:
@Slf4j public class TestThreadlocal {
private static InheritableThreadLocal<String> local = new InheritableThreadLocal();
public static void main(String[] args) throws InterruptedException {
Runnable r = new TT();
local.set("parent");
log.info("get: {}", local.get());
Thread.sleep(1000);
new Thread(r, "child").start();
log.info("exit");
}
private static class TT implements Runnable {
@Override
public void run() {
log.info(local.get());
local.set(Thread.currentThread().getName());
log.info("set local name and get: {}", local.get());
}
}
}
// 打印:
[15 10:58:29,878 INFO ] [main] TestThreadlocal - get: parent
[15 10:58:30,878 INFO ] [main] TestThreadlocal - exit
[15 10:58:30,878 INFO ] [child] TestThreadlocal - parent
[15 10:58:30,878 INFO ] [child] TestThreadlocal - set local name and get: child
总结
- ThreadLocal 通过线程独占的方式,也就是隔离的方式,避免了多线程问题;
- 在使用 ThreadLocal 的时候一定要手动移除,以避免内存泄漏;
并发系列(2)之 ThreadLocal 详解的更多相关文章
- 【Java并发系列03】ThreadLocal详解
img { border: solid 1px } 一.前言 ThreadLocal这个对象就是为多线程而生的,没有了多线程ThreadLocal就没有存在的必要了.可以将任何你想在每个线程独享的对象 ...
- 高并发架构系列:Redis并发竞争key的解决方案详解
https://blog.csdn.net/ChenRui_yz/article/details/85096418 https://blog.csdn.net/ChenRui_yz/article/l ...
- 深入解析ThreadLocal 详解、实现原理、使用场景方法以及内存泄漏防范 多线程中篇(十七)
简介 从名称看,ThreadLocal 也就是thread和local的组合,也就是一个thread有一个local的变量副本 ThreadLocal提供了线程的本地副本,也就是说每个线程将会拥有一个 ...
- C++11 并发指南三(std::mutex 详解)
上一篇<C++11 并发指南二(std::thread 详解)>中主要讲到了 std::thread 的一些用法,并给出了两个小例子,本文将介绍 std::mutex 的用法. Mutex ...
- ASP.NET MVC深入浅出系列(持续更新) ORM系列之Entity FrameWork详解(持续更新) 第十六节:语法总结(3)(C#6.0和C#7.0新语法) 第三节:深度剖析各类数据结构(Array、List、Queue、Stack)及线程安全问题和yeild关键字 各种通讯连接方式 设计模式篇 第十二节: 总结Quartz.Net几种部署模式(IIS、Exe、服务部署【借
ASP.NET MVC深入浅出系列(持续更新) 一. ASP.NET体系 从事.Net开发以来,最先接触的Web开发框架是Asp.Net WebForm,该框架高度封装,为了隐藏Http的无状态模 ...
- C++11 并发指南三(std::mutex 详解)(转)
转自:http://www.cnblogs.com/haippy/p/3237213.html 上一篇<C++11 并发指南二(std::thread 详解)>中主要讲到了 std::th ...
- 【C/C++开发】C++11 并发指南三(std::mutex 详解)
本系列文章主要介绍 C++11 并发编程,计划分为 9 章介绍 C++11 的并发和多线程编程,分别如下: C++11 并发指南一(C++11 多线程初探)(本章计划 1-2 篇,已完成 1 篇) C ...
- 分布式-技术专区-Redis并发竞争key的解决方案详解
Redis缓存的高性能有目共睹,应用的场景也是非常广泛,但是在高并发的场景下,也会出现问题:缓存击穿.缓存雪崩.缓存和数据一致性,以及今天要谈到的缓存并发竞争.这里的并发指的是多个redis的clie ...
- C++11 并发指南六(atomic 类型详解四 C 风格原子操作介绍)
前面三篇文章<C++11 并发指南六(atomic 类型详解一 atomic_flag 介绍)>.<C++11 并发指南六( <atomic> 类型详解二 std::at ...
- C++11 并发指南六(atomic 类型详解三 std::atomic (续))
C++11 并发指南六( <atomic> 类型详解二 std::atomic ) 介绍了基本的原子类型 std::atomic 的用法,本节我会给大家介绍C++11 标准库中的 std: ...
随机推荐
- python struct.pack() 二进制文件,文件中打包二进制数据的存储与解析
学习Python的过程中,遇到一个问题,在<Python学习手册>(也就是<learning python>)中,元组.文件及其他章节里,关于处理二进制文件里,有这么一段代码的 ...
- linux学习笔记基础篇(一)
一.IP操作 1.临时修改IP ,执行命令 ifconfig 网卡名称 新ip :例如 ifconfg nescc 192.168.1.110 ,重启失效 2.重启网络 ,执行命令 syste ...
- 使用NOOBS给树莓派安装系统Raspbian
使用NOOBS给树莓派安装系统Raspbian --英文原版教程:https://www.raspberrypi.org/learning/software-guide/quickstart/ 1.原 ...
- appium 【已解决】Android,每次启动手机中都会安装Appium settings和Unclock的方法
环境介绍: 1.appium版本:1.4.16.1 2.真机运行 实现结果: 运行appium第一次运行则安装Appium settings和Unclock的apk,再次之后的运行则无需手动卸载,再次 ...
- 深入浅出Git教程(转载)
目录 一.版本控制概要 1.1.什么是版本控制 1.2.常用术语 1.3.常见的版本控制器 1.4.版本控制分类 1.4.1.本地版本控制 1.4.2.集中版本控制 1.4.3.分布式版本控制 1.5 ...
- UR机械臂运动学正逆解方法
最近几个月因为工作接触到了机械臂的项目,突然对机械臂运动方法产生了兴趣,也就是如何控制机械臂的位置和姿态.借用一张网上的图片,应该是ur5的尺寸.我用到的是ur3机械臂,除了尺寸不一样,各关节结构和初 ...
- kubernetes 微服务西游记(持续更新中...)
随着微服务架构的流行,迈向云原生的趋势,容器化微服务就成为了持续集成最好的手段,镜像成为了持续交付最好的产物,容器成为了镜像运行最好的环境,kubernetes成了部署容器最好的生态系统和规范.实践出 ...
- 重磅!!!微软发布ASP.NET Core 2.2,先睹为快。
我很高兴地宣布ASP.NET Core 2.2现在作为.NET Core 2.2的一部分提供! 如何获取? 您可以从.NET Core 2.2下载页面下载适用于您的开发机器和构建服务器的新.NET C ...
- ASP.NET Core 实战:使用 NLog 将日志信息记录到 MongoDB
一.前言 在项目开发中,日志系统是系统的一个重要组成模块,通过在程序中记录运行日志.错误日志,可以让我们对于系统的运行情况做到很好的掌控.同时,收集日志不仅仅可以用于诊断排查错误,由于日志同样也是大量 ...
- 关于JVM的垃圾回收(GC) 这可能是你想了解的
目录 1 JVM中Java对象的分类 2 JVM的GC类型及触发条件 2.1 Young GC 2.2 Full GC 3 Java对象生成时的内存申请过程 3 Oracle JDK中的垃圾收集器 3 ...