Java 常用List集合使用场景分析
Java 常用List集合使用场景分析
过年前的最后一篇,本章通过介绍ArrayList,LinkedList,Vector,CopyOnWriteArrayList 底层实现原理和四个集合的区别。让你清楚明白,为什么工作中会常用ArrayList和CopyOnWriteArrayList?了解底层实现原理,我们可以学习到很多代码设计的思路,开阔自己的思维。本章通俗易懂,还在等什么,快来学习吧!
知识图解:
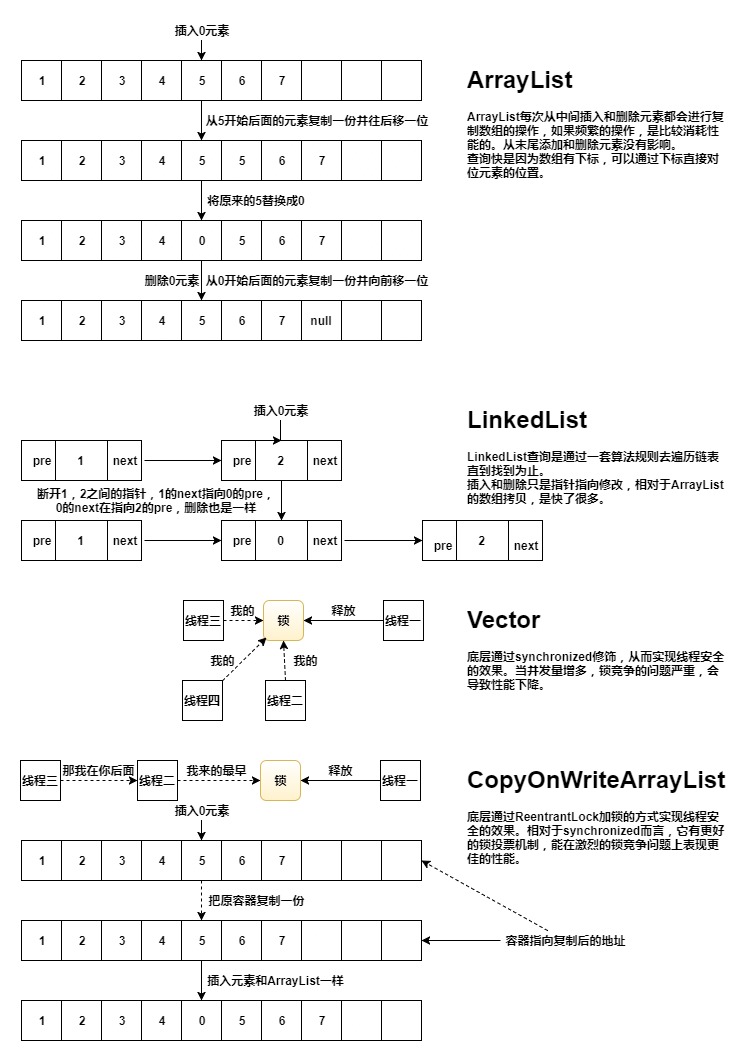
技术:ArrayList,LinkedList,Vector,CopyOnWriteArrayList
说明:本章基于jdk1.8,github上有ArrayList,LinkedList的简单源码代码
源码:https://github.com/ITDragonBlog/daydayup/tree/master/Java/collection-stu
知识预览
ArrayList : 基于数组实现的非线程安全的集合。查询元素快,插入,删除中间元素慢。
LinkedList : 基于链表实现的非线程安全的集合。查询元素慢,插入,删除中间元素快。
Vector : 基于数组实现的线程安全的集合。线程同步(方法被synchronized修饰),性能比ArrayList差。
CopyOnWriteArrayList : 基于数组实现的线程安全的写时复制集合。线程安全(ReentrantLock加锁),性能比Vector高,适合读多写少的场景。
ArrayList 和 LinkedList 读写快慢的本质
ArrayList : 查询数据快,是因为数组可以通过下标直接找到元素。 写数据慢有两个原因:一是数组复制过程需要时间,二是扩容需要实例化新数组也需要时间。
LinkedList : 查询数据慢,是因为链表需要遍历每个元素直到找到为止。 写数据快有一个原因:除了实例化对象需要时间外,只需要修改指针即可完成添加和删除元素。
本章会通过源码分析,验证上面的说法。
注:这里的块和慢是相对的。并不是LinkedList的插入和删除就一定比ArrayList快。明白其快慢的本质:ArrayList快在定位,慢在数组复制。LinkedList慢在定位,快在指针修改。
ArrayList
ArrayList 是基于动态数组实现的非线程安全的集合。当底层数组满的情况下还在继续添加的元素时,ArrayList则会执行扩容机制扩大其数组长度。ArrayList查询速度非常快,使得它在实际开发中被广泛使用。美中不足的是插入和删除元素较慢,同时它并不是线程安全的。
我们可以从源码中找到答案
// 查询元素
public E get(int index) {
rangeCheck(index); // 检查是否越界
return elementData(index);
}
// 顺序添加元素
public boolean add(E e) {
ensureCapacityInternal(size + 1); // 扩容机制
elementData[size++] = e;
return true;
}
// 从数组中间添加元素
public void add(int index, E element) {
rangeCheckForAdd(index); // 数组下标越界检查
ensureCapacityInternal(size + 1); // 扩容机制
System.arraycopy(elementData, index, elementData, index + 1, size - index); // 复制数组
elementData[index] = element; // 替换元素
size++;
}
// 从数组中删除元素
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index, numMoved);
elementData[--size] = null; // clear to let GC do its work
}
从源码中可以得知,
ArrayList在执行查询操作时:
第一步:先判断下标是否越界。
第二步:然后在直接通过下标从数组中返回元素。
ArrayList在执行顺序添加操作时:
第一步:通过扩容机制判断原数组是否还有空间,若没有则重新实例化一个空间更大的新数组,把旧数组的数据拷贝到新数组中。
第二步:在新数组的最后一位元素添加值。
ArrayList在执行中间插入操作时:
第一步:先判断下标是否越界。
第二步:扩容。
第三步:若插入的下标为i,则通过复制数组的方式将i后面的所有元素,往后移一位。
第四步:新数据替换下标为i的旧元素。
删除也是一样:只是数组往前移了一位,最后一个元素设置为null,等待JVM垃圾回收。
从上面的源码分析,我们可以得到一个结论和一个疑问。
结论是:ArrayList快在下标定位,慢在数组复制。
疑问是:能否将每次扩容的长度设置大点,减少扩容的次数,从而提高效率?其实每次扩容的长度大小是很有讲究的。若扩容的长度太大,会造成大量的闲置空间;若扩容的长度太小,会造成频发的扩容(数组复制),效率更低。
LinkedList
LinkedList 是基于双向链表实现的非线程安全的集合,它是一个链表结构,不能像数组一样随机访问,必须是每个元素依次遍历直到找到元素为止。其结构的特殊性导致它查询数据慢。
我们可以从源码中找到答案
// 查询元素
public E get(int index) {
checkElementIndex(index); // 检查是否越界
return node(index).item;
}
Node<E> node(int index) {
if (index < (size >> 1)) { // 类似二分法
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
// 插入元素
public void add(int index, E element) {
checkPositionIndex(index); // 检查是否越界
if (index == size) // 在链表末尾添加
linkLast(element);
else // 在链表中间添加
linkBefore(element, node(index));
}
void linkBefore(E e, Node<E> succ) {
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
从源码中可以得知,
LinkedList在执行查询操作时:
第一步:先判断元素是靠近头部,还是靠近尾部。
第二步:若靠近头部,则从头部开始依次查询判断。和ArrayList的elementData(index)相比当然是慢了很多。
LinkedList在插入元素的思路:
第一步:判断插入元素的位置是链表的尾部,还是中间。
第二步:若在链表尾部添加元素,直接将尾节点的下一个指针指向新增节点。
第三步:若在链表中间添加元素,先判断插入的位置是否为首节点,是则将首节点的上一个指针指向新增节点。否则先获取当前节点的上一个节点(简称A),并将A节点的下一个指针指向新增节点,然后新增节点的下一个指针指向当前节点。
Vector
Vector 的数据结构和使用方法与ArrayList差不多。最大的不同就是Vector是线程安全的。从下面的源码可以看出,几乎所有的对数据操作的方法都被synchronized关键字修饰。synchronized是线程同步的,当一个线程已经获得Vector对象的锁时,其他线程必须等待直到该锁被释放。从这里就可以得知Vector的性能要比ArrayList低。
若想要一个高性能,又是线程安全的ArrayList,可以使用Collections.synchronizedList(list);方法或者使用CopyOnWriteArrayList集合
public synchronized E get(int index) {
if (index >= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
return elementData(index);
}
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
public synchronized boolean removeElement(Object obj) {
modCount++;
int i = indexOf(obj);
if (i >= 0) {
removeElementAt(i);
return true;
}
return false;
}
CopyOnWriteArrayList
在这里我们先简单了解一下CopyOnWrite容器。它是一个写时复制的容器。当我们往一个容器添加元素的时候,不是直接往当前容器添加,而是先将当前容器进行copy一份,复制出一个新的容器,然后对新容器里面操作元素,最后将原容器的引用指向新的容器。所以CopyOnWrite容器是一种读写分离的思想,读和写不同的容器。
应用场景:适合高并发的读操作(读多写少)。若写的操作非常多,会频繁复制容器,从而影响性能。
CopyOnWriteArrayList 写时复制的集合,在执行写操作(如:add,set,remove等)时,都会将原数组拷贝一份,然后在新数组上做修改操作。最后集合的引用指向新数组。
CopyOnWriteArrayList 和Vector都是线程安全的,不同的是:前者使用ReentrantLock类,后者使用synchronized关键字。ReentrantLock提供了更多的锁投票机制,在锁竞争的情况下能表现更佳的性能。就是它让JVM能更快的调度线程,才有更多的时间去执行线程。这就是为什么CopyOnWriteArrayList的性能在大并发量的情况下优于Vector的原因。
private E get(Object[] a, int index) {
return (E) a[index];
}
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
private boolean remove(Object o, Object[] snapshot, int index) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] current = getArray();
int len = current.length;
......
Object[] newElements = new Object[len - 1];
System.arraycopy(current, 0, newElements, 0, index);
System.arraycopy(current, index + 1, newElements, index, len - index - 1);
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
总结
看到这里,如果面试官问你ArrayList和LinkedList有什么区别时
如果你回答:ArrayList查询快,写数据慢;LinkedList查询慢,写数据快。面试官只能算你勉强合格。
如果你回答:ArrayList查询快是因为底层是由数组实现,通过下标定位数据快。写数据慢是因为复制数组耗时。LinkedList底层是双向链表,查询数据依次遍历慢。写数据只需修改指针引用。
如果你继续回答:ArrayList和LinkedList都不是线程安全的,小并发量的情况下可以使用Vector,若并发量很多,且读多写少可以考虑使用CopyOnWriteArrayList。
因为CopyOnWriteArrayList底层使用ReentrantLock锁,比使用synchronized关键字的Vector能更好的处理锁竞争的问题。
面试官会认为你是一个基础扎实,内功深厚的人才!!!
到这里Java 常用List集合使用场景分析就结束了。过年前的最后一篇博客,有点浮躁,可能身在职场,心在老家!最后祝大家新年快乐!!!狗年吉祥!!!大富大贵!!!可能都没人看博客了 ⊙﹏⊙‖∣ 哈哈哈哈(ಡωಡ)hiahiahia
Java 常用List集合使用场景分析的更多相关文章
- Java 常用Set集合和常用Map集合
目录 常用Set集合 Set集合的特点 HashSet 创建对象 常用方法 遍历 常用Map集合 Map集合的概述 HashMap 创建对象 常用方法 遍历 HashMap的key去重原理 常用Set ...
- JAVA常用的集合转换
在Java应用中进行集合对象间的转换是非常常见的事情,有时候在处理某些任务时选择一种好的数据结构往往会起到事半功倍的作用,因此熟悉每种数据结构并知道其特点对于程序员来说是非常重要的,而只知道这些是不够 ...
- Java开发实践 集合框架 全面分析
http://www.open-open.com/lib/view/open1474167415464.html
- java基础之集合:List Set Map的概述以及使用场景
本文的整体思路以及部分文字来源:来源一 和 来源二 Java集合类的基本概念: 首先大家要明白集合为什么会出现: 在编程中,常常需要集中存放多个数据.从传统意义上讲,数组是我们的一个很好的选择,前提是 ...
- java 常用集合list与Set、Map区别及适用场景总结
转载请备注出自于:http://blog.csdn.net/qq_22118507/article/details/51576319 list与Set.Map区别及 ...
- JAVA常用数据结构及原理分析
JAVA常用数据结构及原理分析 http://www.2cto.com/kf/201506/412305.html 前不久面试官让我说一下怎么理解java数据结构框架,之前也看过部分源码,balaba ...
- JAVA常用集合源码解析系列-ArrayList源码解析(基于JDK8)
文章系作者原创,如有转载请注明出处,如有雷同,那就雷同吧~(who care!) 一.写在前面 这是源码分析计划的第一篇,博主准备把一些常用的集合源码过一遍,比如:ArrayList.HashMap及 ...
- (6)Java数据结构-- 转:JAVA常用数据结构及原理分析
JAVA常用数据结构及原理分析 http://www.2cto.com/kf/201506/412305.html 前不久面试官让我说一下怎么理解java数据结构框架,之前也看过部分源码,balab ...
- java集合源码分析(三):ArrayList
概述 在前文:java集合源码分析(二):List与AbstractList 和 java集合源码分析(一):Collection 与 AbstractCollection 中,我们大致了解了从 Co ...
随机推荐
- VUE之随笔小总结1
VUE 它是一个构建用户界面的JavaScript框架vue指令: 是带有v-前缀的特殊属性,通过属性来操作元素 v-text:在元素当中插入文本 eg:属性值会覆盖自己插入的值 //插入一段文本&l ...
- 从零开始学习前端开发 — 17、CSS3背景与渐变
一.css3背景切割: background-clip:border-box|padding-box|content-box; 作用: 用来设置背景的可见区域 a) border-box 默认值,背景 ...
- SSM手把手整合教程&测试事务
自打来了博客园就一直在看帖,学到了很多知识,打算开始记录的学习到的知识点 今天我来写个整合SpringMVC4 spring4 mybatis3&测试spring事务的教程,如果有误之处,还请 ...
- 一步一步创建ASP.NET MVC5程序[Repository+Autofac+Automapper+SqlSugar](六)
前言 大家好,我是Rector 又是星期五,很兴奋,很高兴,很high...啦啦啦... Rector在图享网又和大家见面啦!!!上一篇<一步一步创建ASP.NET MVC5程序[Reposit ...
- redis学习笔记(14)---redis基本命令总结
http://doc.redisfans.com/ 网页,对所有redis命令的用法与示例进行了详细的描述 概述 Redis的键值可以使用物种数据类型:字符串,散列表,列表,集合,有序集合.本文详细介 ...
- SDK是什么?什么是SDK
从 SDK导航 看到的 应该比较专业! SDK的英文全名是:software development kit,翻译成中文的意思就是"软件开发工具包" 通俗一点的理解,是指由第三方服 ...
- Java反射(Reflection)
基本概念 在Java运行时环境中,对于任意一个类,能否知道这个类有哪些属性和方法?对于任意一个对象,能否调用它的任意一个方法? 答案是肯定的. 这种动态获取类的信息以及动态调用对象的方法的功能来自于J ...
- 通读cheerio API ——NodeJs中的jquery
通读cheerio API ——NodeJs中的jquery 所谓工欲善其事,必先利其器,所以通读了cheerio的API,顺便翻译了一遍,有些地方因为知道的比较少,不知道什么意思,保留了英文,希望各 ...
- Jpa 本地方式实现数据的持久化【千锋】
Jpa本身支持多种方式的对象持久化,比如数据库方式,还有一种方式就是本地文件的方式,本文来讲解以本地方式实现的数据持久化,具体的资源大家可以参阅一下网站:http://www.objectdb.com ...
- MySQL 多版本并发控制(MVCC)
可以认为MVCC是行级锁的一个变种,但是它在很多情况下避免了加锁的操作,因此开销会很低.主要实现的是非阻塞的读操作,写操作也只是锁定必要的行.MVCC的实现是通过保存数据在某个时间点的快照来实现的,也 ...