Elastic Stack-Elasticsearch使用介绍(二)
一、前言
写博客,更要努力写博客!
二、Mapping介绍
Mapping类似于数据库中的表结构的定义:这里我们试想一下表结构定义需要那些:
1.字段和字段类型,在Elasticsearch中的体现就是索引的结构,定义索引的字段Field Name和字段类型,上一篇有简单介绍一下字段有那些类型;
2.索引,在数据库中我们可以定义字段索引,在Elasticsearch中就是相当于是否分词,按照分词器分词;
先来用我们的神器先自定义一个Mapping:
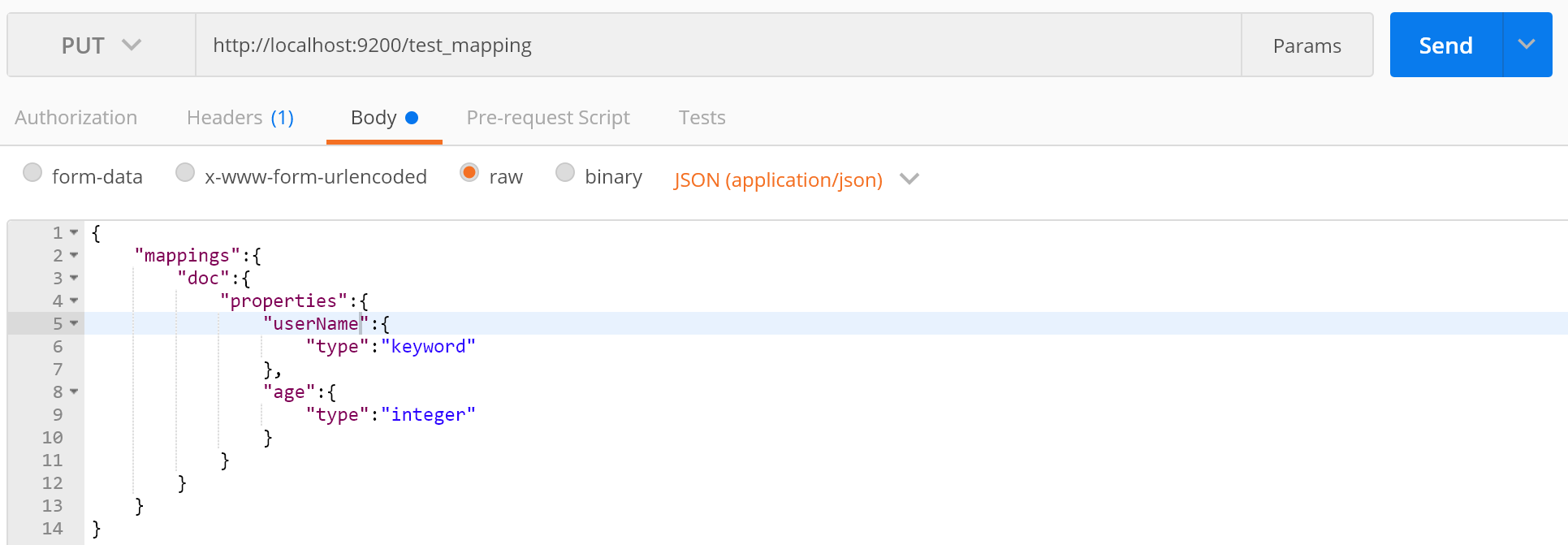
接下来在在查询下Mapping的结构:

三、Mapping常用参数介绍
type:指定参数的类型;
analyzer:指定分词器;
boost:指定字段的权重,
copy_to:指定某几个字段合并;
dynamic:字段动态添加 ,有3种取值:
true:无限制;
false:数据可写入但该字段不保留;
strict:无法写入抛异常;
format:"yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis" ,格式化 此参数代表可接受的时间格式 3种都接受;
ignore_options:这个选项用于控制倒排索引记录的内容,有4种配置:
docs:只记录文档号;
freqs:文档号 + 词频;
postions:文档号 + 词频 + 位置;
offsets:文档号 + 词频 + 位置 + 偏移量;
index:指定某字段是否被索引;
fileds:可以对一个字段提供多种索引模式;
null_value:当字段遇到null值时候的处理机制,默认为null空值,此时es会忽略该值,可以通过设定该值设定该字段的默认值来改变null不显示成空值:
properties:嵌套属性;
search_analyzer:查询分词器;
similarity:用于指定文档评分模型,有2种配置:
default:Elasticsearch和Lucene使用的默认TF / IDF算法;
BM25:Okapi BM25算法;
基本上常用就是这些,有没有介绍到的大家可以参考官方文档;
四、字段的数据类型
上上篇介绍过一些简单的数据类型在官方称为核心数据类型,这里不做过多的介绍了,这里主要介绍一下复杂的数据类型、地理数据类型、专用数据类型这3种;
复杂的数据类型
1.数组数据类型(Array datatype)
Elasticsearch中没有专门的数组类型,默认情况下每个字段都可以存储0个或者多个值,但是这些值得类型必须是一样的;
2.对象数据类型(Object datatype)
提交文档的时候是Json文档,内部的字段可以嵌套Json对象;
3.嵌套数据类型(Nested datatype)
嵌套数据类型就是1+2的组合,数组里面放Json;
地理数据类型
1.地理数据类型(Geo-point datatype)
对经纬度的查询搜索;
2.形状数据类型(Geo-Shape datatype)
对多边形的的形状的查询;
专用数据类型
1.IP数据类型
2.完整的数据类型
提供search-as-you-type的搜索,这个还是比较有用的大家可以参考下官方文档;
剩下的也使用不多,大家可以参考下官方文档,这里就不做过多介绍;
五、Search API介绍
Search API实现了对Elasticsearch中存储的数据进行查询分析,通过_search方式去查询,基本上有以下4种情况:

1.不指定索引的情况下查询的是Elasticsearch中所有的数据;
2.指定index就是对单个的index查询;
3.另外还可以指定多个索引;
4.还可以通过通配符的形式去匹配索引;
Search API查询的方式主要有两种:URL Search和Request Body Search,分别对以下两种情况进行下介绍:
URL Search:
通过URL的形式指定Query参数实现搜索,我们先来一个demo,然后介绍下常用下参数:
首先先添加些数据:

接下来进行下查询
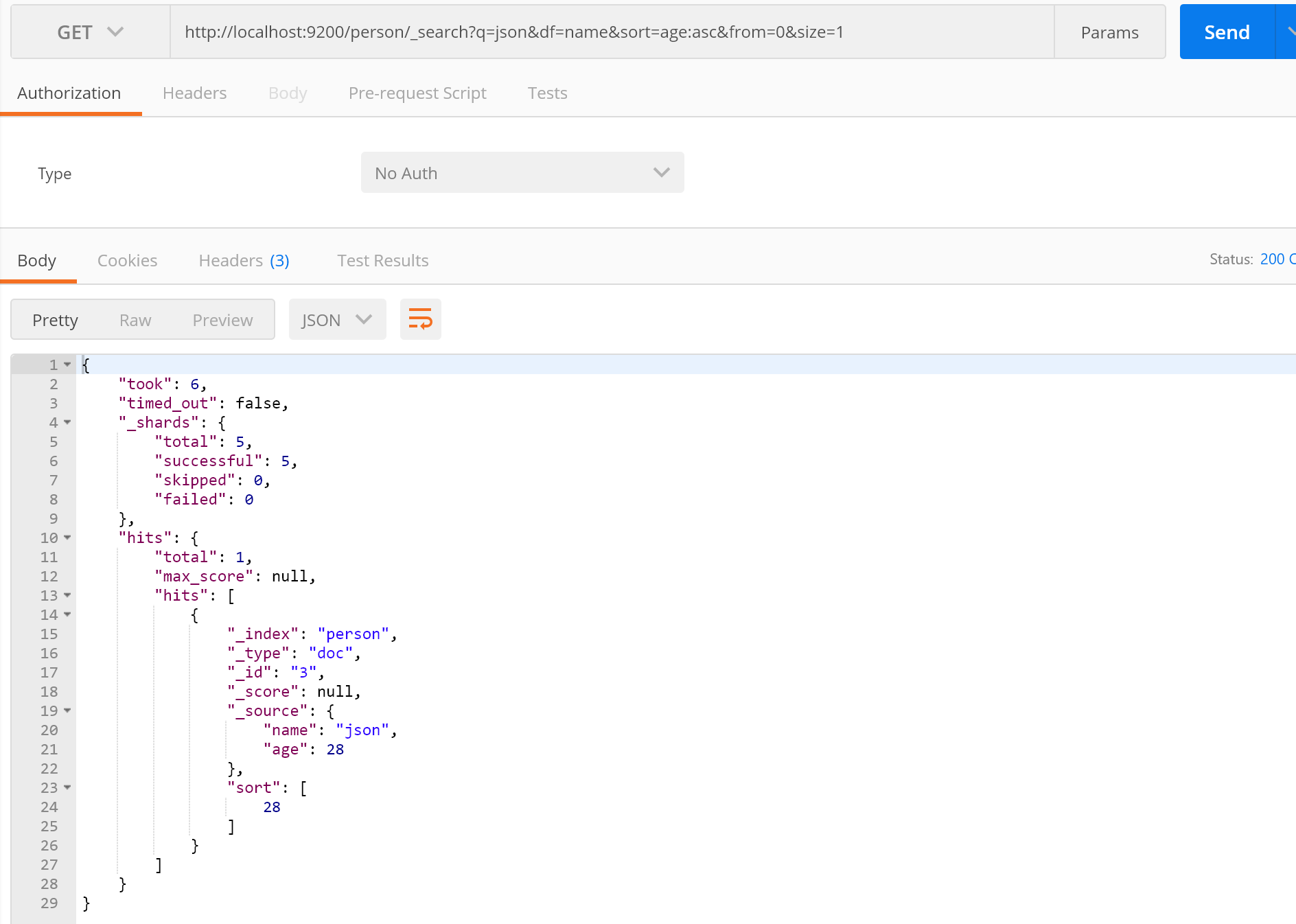
这样就完成了ES查询,接下来我们说说常用参数:
q:指定查询的参数,也就是我们要搜索的文档的内容;
df:指定我们查询文档指定的字段;
sort:指定排序的字段;
form:第几条开始;
size:一页几条;
剩下大家可以查看下官方文档,
Request Body Search
这个是主要介绍的,也是我们经常使用的。主要是通过http requset body发送json请求去对Elasticsearch中存储的数据进行查询分析,有个比较专业的名词Query DSL;主要有两种类型字段查询和复合查询,接下来我们介绍这两种查询的方式:
字段查询:
字段查询又可以分成两类:全文匹配和单词匹配;
全文匹配:
主要对text类型的字段进行全文检索,对查询的语句先进行分词,例如match、match_pharse等;
match Query
这个是我们经常使用的,接下来我们使用我们神器给大家展示以下怎么使用;
首先看下person中有哪些字段:
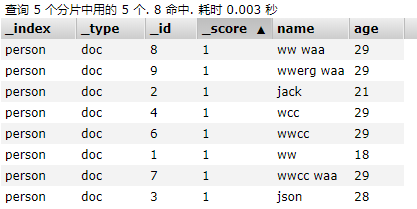
接下来看下使用的方式:

再看下匹配以后的类型,因为匹配到太多,我们用展示代码的方式来展示:
{
"took": 12,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {//匹配文档的总数
"total": 4,//总数
"max_score": 0.80259144,//最匹配的得分
"hits": [//返回文档的总数
{
"_index": "person",
"_type": "doc",
"_id": "1",
"_score": 0.80259144,//文档得分
"_source": {
"name": "ww",
"age": 18
}
},
{
"_index": "person",
"_type": "doc",
"_id": "7",
"_score": 0.5377023,
"_source": {
"name": "wwcc waa",
"age": 29
}
},
{
"_index": "person",
"_type": "doc",
"_id": "8",
"_score": 0.32716757,
"_source": {
"name": "ww waa",
"age": 29
}
},
{
"_index": "person",
"_type": "doc",
"_id": "9",
"_score": 0.32716757,
"_source": {
"name": "ww waa",
"age": 29
}
}
]
}
}
看完上面返回的文档以后,可做如下推测查询的过程就是将我们查询的内容进行分词然后在文档中查询匹配的分词,因为文档中不存在name等于waa这种情况,所以没出现,如果不相信可以补一下这个文档再看下返回结果,过程如下图:

可以通过设置operator参数来控制分词间的匹配关系,默认是or,可以设置为and,当and的时候文档种必须同时出现查询的分词;
还可以通过minimum_should_match参数设置需要匹配参数的个数;
另外我们还有一个关注的选项就是得分,上面我们说过文档评分的模型有2种:TF/IDF和BM25,但是在介绍这个之前我们还需要知道4个概念:
1.Term Frequency(TF):词频,这个应该不陌生在上篇介绍倒排索引原理的时候介绍过这个概念;
2.Document Frequency(DF):文档频率,单词在文档中出现的频率;
3.Inverse Document Frequency(IDF):逆向文档频率,与文档频率相反,可理解为1/DF。即单词出现的文档数越少,相关度越高。
4.Field-length Norm:文档越短,相关度越高;
TF/IDF模型:
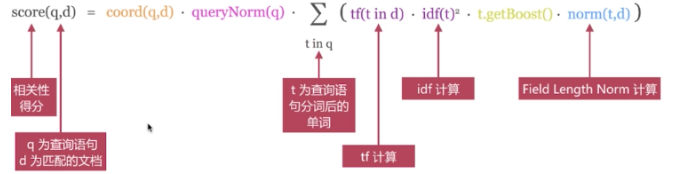
BM25模型

推荐大家看下tf/idf评分算法,另外可以通过explain参数来查看得分的计算方法;
match_phrase Query
必须包含查询的字段,并且顺序不能乱;
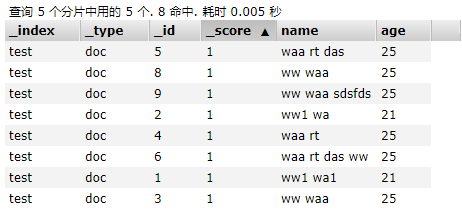
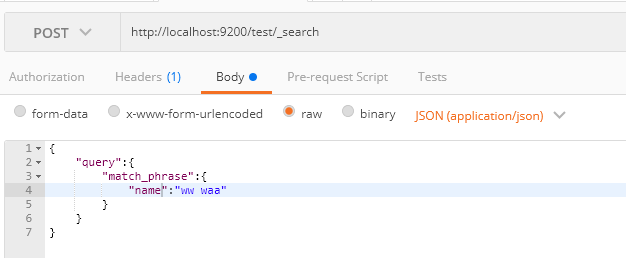
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 0.6135754,
"hits": [
{
"_index": "test",
"_type": "doc",
"_id": "8",
"_score": 0.6135754,
"_source": {
"name": "ww waa",
"age": 25
}
},
{
"_index": "test",
"_type": "doc",
"_id": "3",
"_score": 0.51623213,
"_source": {
"name": "ww waa",
"age": 25
}
},
{
"_index": "test",
"_type": "doc",
"_id": "9",
"_score": 0.50104797,
"_source": {
"name": "ww waa sdsfds",
"age": 25
}
}
]
}
}
query_string Query
query_string与Lucene查询语句的语法结合非常严谨,允许在查询中使用多个特殊条件关键字对多个字段进行查询,简单的看下用法:
默认可以指定一个列:

指定多个列查询

simple_string Query
simple_query_string查询永远不会抛出异常,并丢弃查询的无效部分,使用+、|、-来代替AND、OR、NOT等等;

我们常用的就是match和match_phrase,剩下的我感觉我是用的不多,大家可以看自己;
单词匹配:
查询语句作为整个单词不进行分词,主要有term、terms、range、prefix等;
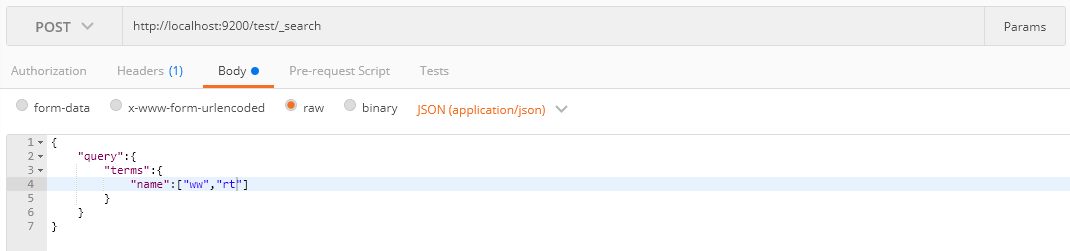
term和terms query
单个单词进行查询:

一次可以传入多个单词进行查询
range query
主要是用来匹配某一范围的值,比如日期、数值类型等等,我们上面有个age类型我们来根据这个查询下20-30岁的人:

prefix query
查询某个字段中以给定字前缀开始的文档,比如我们想要查询以ki开始的用户字段;

比较常用的基本上就是这几种,剩下可以查阅官方文档;
复合查询(Compound queries):
复合查询就是组合多个查询在一起或改变查询行为,比较常用就是Constant Score Query和bool Query,剩下的大家可以查看官方文档,根据自己需求去选择自己想要的;
constant_score Query
在内部包装一个查询,将返回结果中每个文档设置一个相同的得分;
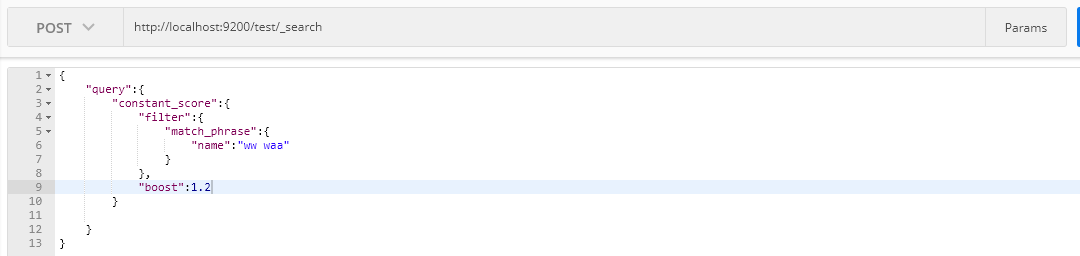
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 1.2,
"hits": [
{
"_index": "test",
"_type": "doc",
"_id": "8",
"_score": 1.2,
"_source": {
"name": "ww waa",
"age": 25
}
},
{
"_index": "test",
"_type": "doc",
"_id": "9",
"_score": 1.2,
"_source": {
"name": "ww waa sdsfds",
"age": 25
}
},
{
"_index": "test",
"_type": "doc",
"_id": "3",
"_score": 1.2,
"_source": {
"name": "ww waa",
"age": 25
}
}
]
}
}
bool Query
由一个或者多个布尔子句构成,主要包含以下4种类型:
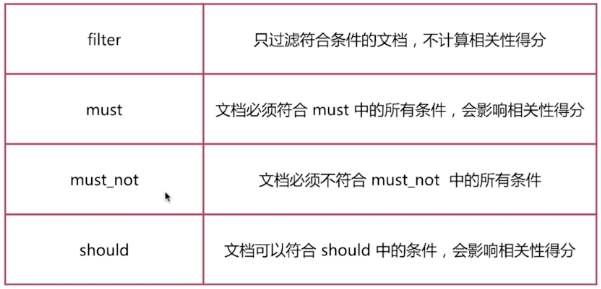
用法如下:
{
"took": 6,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 1.6135753,
"hits": [
{
"_index": "test",
"_type": "doc",
"_id": "8",
"_score": 1.6135753,
"_source": {
"name": "ww waa",
"age": 25
}
},
{
"_index": "test",
"_type": "doc",
"_id": "3",
"_score": 1.5162321,
"_source": {
"name": "ww waa",
"age": 25
}
},
{
"_index": "test",
"_type": "doc",
"_id": "9",
"_score": 1.501048,
"_source": {
"name": "ww waa sdsfds",
"age": 25
}
}
]
}
}
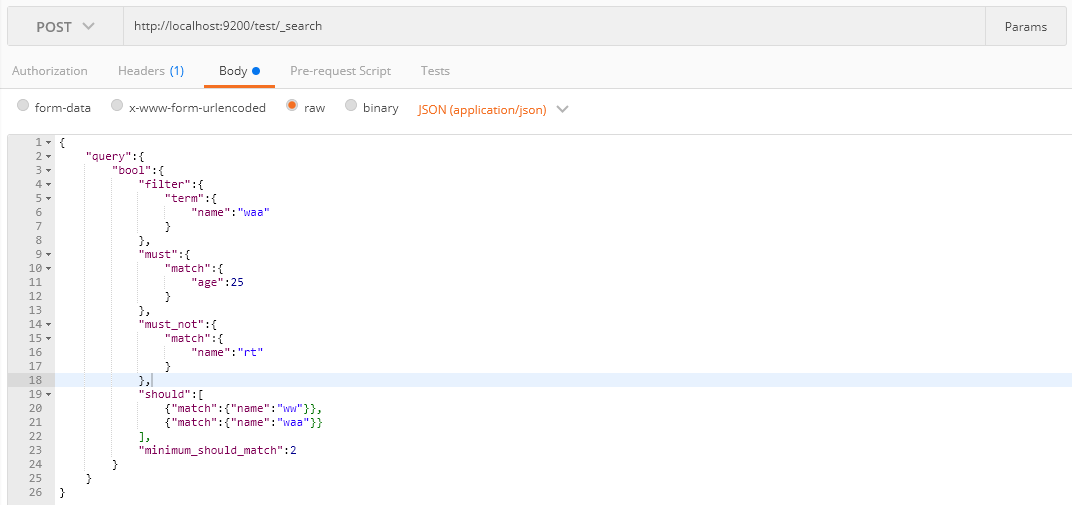
介绍minimum_should_match这个参数,当只有should,文档中参数必须要要满足条件的个数才会显示,同时包含should和must时,文档不满足should中的条件,但是如果满足条件会增加相关性得分:
在强调一点Filter查询只过滤复合条件的文档,不会进行相关性算分;
六、结尾
这篇文章写了好久,下一篇再来好好聊聊Search机制,欢迎大家加群438836709,欢迎大家关注我公众号:

Elastic Stack-Elasticsearch使用介绍(二)的更多相关文章
- Elastic Stack之ElasticSearch分布式集群二进制方式部署
Elastic Stack之ElasticSearch分布式集群二进制方式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 想必大家都知道ELK其实就是Elasticsearc ...
- ES 集中式日志分析平台 Elastic Stack(介绍)
一.ELK 介绍 ELK 构建在开源基础之上,让您能够安全可靠地获取任何来源.任何格式的数据,并且能够实时地对数据进行搜索.分析和可视化. 最近查看 ELK 官方网站,发现新一代的日志采集器 File ...
- 集中式日志分析平台 Elastic Stack(介绍)
一.ELK 介绍 二.ELK的几种常见架构 >>ELK 介绍<< ELK 构建在开源基础之上,让您能够安全可靠地获取任何来源.任何格式的数据,并且能够实时地对数据进行搜索.分析 ...
- Elastic Stack之ElasticSearch分布式集群yum方式搭建
Elastic Stack之ElasticSearch分布式集群yum方式搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.搜索引擎及Lucene基本概念 1>.什么 ...
- Elastic Stack核心产品介绍-Elasticsearch、Logstash和Kibana
Elastic Stack 是一系列开源产品的合集,包括 Elasticsearch.Kibana.Logstash 以及 Beats 等等,能够安全可靠地获取任何来源.任何格式的数据,并且能够实时地 ...
- 浅尝 Elastic Stack (一) Elasticsearch、Kibana、Beats 安装
Elastic Stack 包括 Elasticsearch.Kibana.Beats 和 Logstash,也称为 ELK Stack.能够安全可靠地获取任何来源.任何格式的数据,然后实时地对数据进 ...
- Elastic Stack(ElasticSearch 、 Kibana 和 Logstash) 实现日志的自动采集、搜索和分析
Elastic Stack 包括 Elasticsearch.Kibana.Beats 和 Logstash(也称为 ELK Stack).能够安全可靠地获取任何来源.任何格式的数据,然后实时地对数据 ...
- 使用 Elastic Stack 分析地理空间数据 (二)
文章转载自:https://blog.csdn.net/UbuntuTouch/article/details/106546064 在之前的文章 "Observability:使用 Elas ...
- ELK stack elasticsearch/logstash/kibana 关系和介绍
ELK stack elasticsearch 后续简称ES logstack 简称LS kibana 简称K 日志分析利器 elasticsearch 是索引集群系统 logstash 是日志归集集 ...
- Elastic Stack 笔记(八)Elasticsearch5.6 Java API
博客地址:http://www.moonxy.com 一.前言 Elasticsearch 底层依赖于 Lucene 库,而 Lucene 库完全是 Java 编写的,前面的文章都是发送的 RESTf ...
随机推荐
- 【死磕 Spring】----- IOC 之深入理解 Spring IoC
在一开始学习 Spring 的时候,我们就接触 IoC 了,作为 Spring 第一个最核心的概念,我们在解读它源码之前一定需要对其有深入的认识,本篇为[死磕 Spring]系列博客的第一篇博文,主要 ...
- 注解ConfigurationProperties注入yml配置文件中的数据
在使用SpringBoot开发中需要将一些配置参数放在yml文件中定义,再通过Java类来引入这些配置参数 SpringBoot提供了一些注解来实现这个功能 ConfigurationProperti ...
- 【自然语言处理篇】--以NLTK为基础讲解自然语⾔处理的原理和基础知识
一.前述 Python上著名的⾃然语⾔处理库⾃带语料库,词性分类库⾃带分类,分词,等等功能强⼤的社区⽀持,还有N多的简单版wrapper. 二.文本预处理 1.安装nltk pip install - ...
- GlideNewDemo【Glide4.7.1版本的简单使用以及圆角功能】
版权声明:本文为HaiyuKing原创文章,转载请注明出处! 前言 简单记录下Glide4.7.1版本的使用和实现圆角方案. 注意:关于详细使用请仔细阅读<官方指南>. 效果图 使用步骤 ...
- 原生js 遍历文件夹分析xml并保存
其实这种功能,网上相关的代码多的是,我也是因为今天正好要用到这个功能,所以临时写了下,放这里保存下,以便将来自己或者别人用的上吧. 当然我写的是一个hta文件.下面是完整js代码,都是调用active ...
- [翻译] 对正在使用EF6x开发人员的一些话
Entity Framework Core in Action Entityframework Core in action是 Jon P smith 所著的关于Entityframework Cor ...
- java内存溢出的情况解决方法
内存溢出虽然很棘手,但也有相应的解决办法,可以按照从易到难,一步步的解决. 第一步,就是修改JVM启动参数,直接增加内存.这一点看上去似乎很简单,但很容易被忽略.JVM默认可以使用的内存为64M,To ...
- 【我们一起写框架】MVVM的WPF框架(一)—序篇
前言 我想,有一部分程序员应该是在二三线城市的,虽然不知道占比,但想来应该不在少数. 我是这部分人群中的一份子. 我们这群人,面对的客户,大多是国内中小企业,或者政府的小部门.这类客户的特点是,资金有 ...
- C#语法——事件,逐渐边缘化的大哥。
事件是C#的基础之一,学好事件对于了解.NET框架大有好处. 事件最常见的比喻就是订阅,即,如果你订阅了我的博客,那么,当我发布新博客的时候,你就会得到通知. 而这个过程就是事件,或者说是事件运行的轨 ...
- Notepad++替换SQL Server Select窗口列名的中括号的小技巧
条件:“查找模式”那选中“扩展” 一.简单替换 查找目标(包括空格,各个SSMS版本可能不同): ]\r\n ,[ 替换为:, 二.替换为@ 查找目标(包括空格,各个SSMS版本可能不同): ]\r\ ...