PowerBI 第九篇:修改查询
在PowerBI的查询编辑器(Query Editor)中,用户可以使用M语言修改Query,或修改Query字段的类型,或向Query中添加数据列(Column),对Query进行修改会导致PowerBI相应地更新数据模型(Data Model),这跟使用DAX表达式修改Data Model有本质的区别:前者是修改数据表,后者是修改数据视图。PowerBI通过查询编辑器来修改数据模型,对Query的每一次修改都是一个step,用户可以根据需要增加或删除step,调整step的顺序,并可以迭代引用先前创建的step,应用这些操作对数据进行再次加工和处理,以满足数据分析的需求。
我的PowerBI开发系列的文章目录:PowerBI开发
一,修改数据类型
每一个Query都是由一系列的列和行构成的数据表,每一列都有特定的数据类型,PowerBI为每个数据类型显示特定的图标,最常用的数据类型是number和text,例如:

123表示当前列是数字类型,ABC表示当前列是字符类型。有时,从外部数据源导入数据之后,PowerBI不能确定数据的类型,此时,它会在列前方同时标记为123和ABC,用户可以通过”Change Type“把该列转换为合适的数据类型。
二,添加数据列
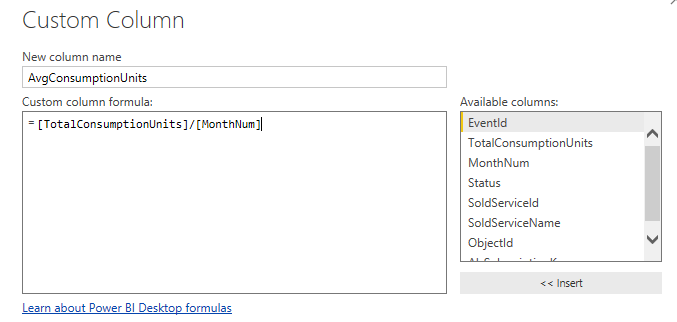
用户可以添加计算列,从主菜单中切换到”Add Column“面板,点击”Custom Column“,基于M公式创建新的数据列。

从左侧可用的列中,添加列和公式,PowerBI基于用户输入的表达式创建新的计算列,并添加到数据模型(Data Model)中:
三,添加排序列
在对数据进行排序时,有时不能使用DAX表达式,此时必须使用M公式,例如,对班级(Class)进行排序,使用DAX的IF函数,按照班级(Class)名称新建一个字段(Class Ordinal),
Class Ordinal = IF(Schools[Class]="一年级",1,IF(Schools[Class]="二年级",2,3))
设置Class按照Class Ordinal排序,PowerBI会抛出错误:
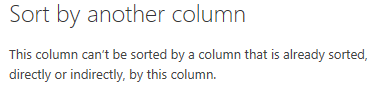
在这种情况下,必须使用M公式,在Schools Query中新增字段:
= Table.AddColumn(KustoQuery, "Class Ordinal",
each if [Class]="一年级" then
else if [Class]="二年级" then
else if [Class]="三年级" then
else )
四,查询组合
查询的组合(Combine),用于在Query级别对数据进行修改,PowerBI支持Merge和Append,你使用Merge操作连接数据,或使用Append操作追加数据。
1,数据的连接
把查询连接到一起,可以使用Home菜单中”Merge Queries as New“,通过连接操作(Join)把两个Query合并,生成新的Query。
PowerBI在进行Merge时,只支持等值条件的连接操作,等相应字段的值相等时,匹配成功。
例如,选择 EventSoldService 作为其中一个Query,点击EventId,作为连接的条件,第一个表称作左表,第二标称作右表:
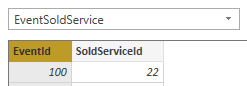
也可以选择多个数据列作为连接条件,摁住Ctrl,连续点击EventId,SoldServiceId,就可以把这个字段作为连接:
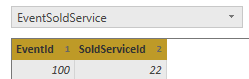
在进行Merge操作时,PowerBI提供多种连接的类型,如下:
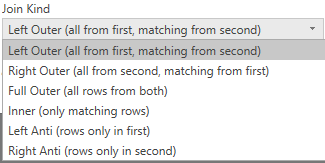
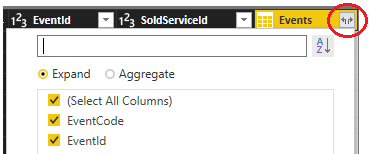
在创建Merge查询之后,默认情况下,PowerBI会把连接的右表显示在左表字段的末尾,字段名为右表名,而字段值为"Table",如下图:

用户可以点击该列上方的图标, 对右表进行扩展(Expand)或聚合(Aggregate)操作,扩展操作是指在最终的查询中显示右表的字段,聚合操作是对右表的相应字段进行聚合操作,返回聚合值。
2,数据的追加
对于一个Query,使用PowerBI可以追加数据,把另一个Query的数据追加到当前Query之中,这相当于集合的Union操作。
选中当前Query,点击“Append Queries”,可以追加一个Query,或多个Query。
而用于追加的Query,可以不显示在Report视图中,使这些Query仅仅用于提供数据。
五,转换操作
在查询编辑器中,可以对数据做变换操作(Transform),例如,分组、字符的拆分、透视、逆透视、去重和替换值等。
1,分组
Group By用于按照特定的列对现有的查询进行分组聚合,产生新的Query。
2,拆分字符
把一个字符类型Column按照分隔符,或者特定数量的字符,分割成多个数据列。
3,透视和逆透视
Pivot Column 用于对数据进行透视操作,Unpivot Column 用于对数据进行逆透视操作,完成数据的行列转换。

六,Query的其他操作
对Query分组,分组的目的是组织Query,便于查找。当Query的数量非常多时,可以按照功能或Page对不同的Query分组。
Query是否启用加载,是否包含在报表刷新中?
如果启用了“Enable load”,那么Query的数据会显示在Report View中;如果启用了”Include in report refresh“中,Query可以随着报表的刷新而自动刷新数据。
参考文档:
Add a custom column in Power BI Desktop
PowerBI 第九篇:修改查询的更多相关文章
- Neo4j 第九篇:查询数据(Match)
Cypher使用match子句查询数据,是Cypher最基本的查询子句.在查询数据时,使用Match子句指定搜索的模式,这是从Neo4j数据库查询数据的最主要的方法.match子句之后通常会跟着whe ...
- ElasticSearch入门 第九篇:实现正则表达式查询的思路
这是ElasticSearch 2.4 版本系列的第九篇: ElasticSearch入门 第一篇:Windows下安装ElasticSearch ElasticSearch入门 第二篇:集群配置 E ...
- Spring Cloud第九篇 | 分布式服务跟踪Sleuth
本文是Spring Cloud专栏的第九篇文章,了解前八篇文章内容有助于更好的理解本文: Spring Cloud第一篇 | Spring Cloud前言及其常用组件介绍概览 Spring Cl ...
- 第九篇 SQL Server代理了解作业和安全
本篇文章是SQL Server代理系列的第九篇,详细内容请参考原文 在这一系列的上一篇,学习了如何在SQL Server代理作业步骤启动外部程序.你可以使用过时的ActiveX系统,运行批处理命令脚本 ...
- 第九篇 Integration Services:控制流任务错误
本篇文章是Integration Services系列的第九篇,详细内容请参考原文. 简介在前面三篇文章,我们创建了一个新的SSIS包,学习了脚本任务和优先约束,并检查包的MaxConcurrentE ...
- 第九篇 Replication:复制监视器
本篇文章是SQL Server Replication系列的第九篇,详细内容请参考原文. 复制监视器允许你查看复制配置组件的健康状况.这一篇假设你遵循前八篇,并且你已经有一个合并发布和事务发布.启动复 ...
- 第九篇 SQL Server安全透明数据加密
本篇文章是SQL Server安全系列的第九篇,详细内容请参考原文. Relational databases are used in an amazing variety of applicatio ...
- Python之路【第九篇】:Python操作 RabbitMQ、Redis、Memcache、SQLAlchemy
Python之路[第九篇]:Python操作 RabbitMQ.Redis.Memcache.SQLAlchemy Memcached Memcached 是一个高性能的分布式内存对象缓存系统,用 ...
- [老老实实学WCF] 第九篇 消息通信模式(上) 请求应答与单向
老老实实学WCF 第九篇 消息通信模式(上) 请求应答与单向 通过前两篇的学习,我们了解了服务模型的一些特性如会话和实例化,今天我们来进一步学习服务模型的另一个重要特性:消息通信模式. WCF的服务端 ...
随机推荐
- Windows中添加自己的程序到开机启动中(添加服务,添加注册表)
在系统启动的时候启动自己想要启动的程序: 方法一:利用开机启动文件夹 将exe文件或exe文件的快捷方式复制到(启动)文件夹下 以win7为例:开始→所有程序→启动→鼠标右键打开 方法二:添加系统服务 ...
- Linq 连接运算符:Concat
//Concat()方法附加两个相同类型的序列,并返回一个新序列(集合)IList<string> strList = new List<string>() { "O ...
- js 过多 导致页面加载过慢
自己的代码检查了很久,才检查 出来 通常我们的网站里面会加载一些js代码,统计啊,google广告啊,百度同盟啊,阿里妈妈广告代码啊, 一堆,最后弄得页面加载速度很慢,很慢. 解决办法:换一个js包含 ...
- 1.phpStrom连接远程代码
1.选择一个新的文件 2.选择自己需要的传输方式 3.添加项目名+路径 4.填写连接基本信息 5.配置成功,下载完毕后,设计本地与远程代码同步修改 自此本地修改代码,同时修改远程服务器代码就设置完毕~ ...
- 用Jmeter实现SQLServer数据库的增删查改
1.添加线程组 Jmeter性能测试,最重要的就是线程组了,线程组相当于用户活动 2.添加JDBC Connection Configuration Database URL:jdbc:sqlserv ...
- django Form组件 上传文件
上传文件 注意:FORM表单提交文件要有一个参数enctype="multipart/form-data" 普通上传: urls: url(r'^f1/',views.f1), u ...
- 网络配置及shell基础
一:集群已做完 二:临时配置网络(ip,网关,dns)+永久配置 临时配置网络: ip: [root@localhost ~]# ifconfig [root@localhost ~]# ifc ...
- 浅析开源数据库MySQL架构
数据库是所有应用系统的核心,故保证数据库稳定.高效.安全地运行是所有企业日常工作的重中之重.数据库系统一旦出现问题无法提供服务,有可能导致整个系统都无法继续工作.所以,一个成功的数据库架构在高可用设计 ...
- html的语法注意事项
html的语法 1.html不区分大小写,但是编写网页的时候尽量使用小写 2.文档注释:<!-- 注释部分的内容 --> 3.空格键和回车键在网页中不会起到任何作用 4.注意缩进时保持严格 ...
- [转]Python UnicodeEncodeError: 'gbk' codec can't encode character 解决方法
使用Python写文件的时候,或者将网络数据流写入到本地文件的时候,大部分情况下会遇到:UnicodeEncodeError: 'gbk' codec can't encode character ' ...