深入研究Spark SQL的Catalyst优化器(原创翻译)
树
- Literal(值:Int):常数值
- Attribute(名称:String):输入行的属性,例如“x”
- Add(左:TreeNode,右:TreeNode):两个表达式的总和。
Add(Attribute(x), Add(Literal(1), Literal(2)))


规则
tree.transform {
case Add(Literal(c1), Literal(c2)) => Literal(c1+c2)
}
将此应用于x +(1 + 2)的树会产生新的树x + 3。这里关键是使用了Scala的标准模式匹配语法,它可用于匹配对象的类型和为提取的值(这里为c1和c2)提供名称。
tree.transform {
case Add(Literal(c1), Literal(c2)) => Literal(c1+c2)
case Add(left, Literal(0)) => left
case Add(Literal(0), right) => right
}
实际上,规则可能需要多次执行才能完全转换树。Catalyst将规则形成批处理,并执行每个批处理至固定点,该固定点是树应用其规则后不发生改变。虽然规则运行到固定点意味着每个规则是简单且自包含,但这些规则仍会对树上产生较大的全局效果。在上面的例子中,重复的应用规则会持续折叠较大的树,比如(x + 0)+(3 + 3)。另一个例子,第一个批处理可以分析所有属性指定类型的表达式,而第二批处理可使用这些类型来进行常量折叠。在每批处理完毕后,开发人员还可以对新树进行规范性检查(例如,查看所有属性为指定类型),这些检查一般使用递归匹配来编写。
在Spark SQL中使用Catalyst
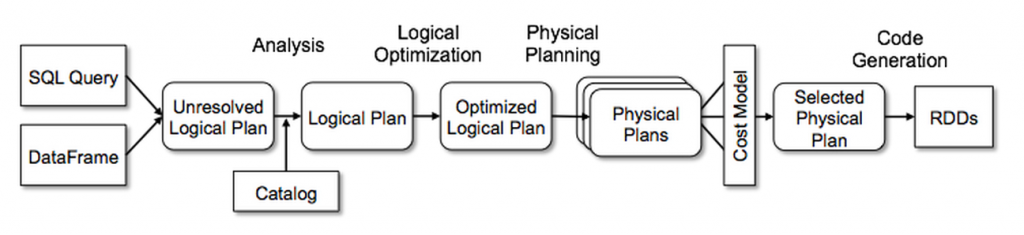

解析
逻辑计划优化
object DecimalAggregates extends Rule[LogicalPlan] {
/** Maximum number of decimal digits in a Long */
val MAX_LONG_DIGITS = 18
def apply(plan: LogicalPlan): LogicalPlan = {
plan transformAllExpressions {
case Sum(e @ DecimalType.Expression(prec, scale))
if prec + 10 <= MAX_LONG_DIGITS =>
MakeDecimal(Sum(UnscaledValue(e)), prec + 10, scale) }
}
再举一个例子,一个12行代码的规则通过简单的正则表达式将LIKE表达式优化为String.startsWith或String.contains调用。在规则中使用任意Scala代码使得这些优化易于表达,而这些规则超越了子树结构的模式匹配。
物理计划
代码生成
def compile(node: Node): AST = node match {
case Literal(value) => q"$value"
case Attribute(name) => q"row.get($name)"
case Add(left, right) => q"${compile(left)} + ${compile(right)}"
}
以q开头的字符串是quasiquotes,虽然它们看起来像字符串,但它们在编译时由Scala编译器解析,并代表其代码的AST。 Quasiquotes用$符号表示法将变量或其他AST拼接到它们中。例如,文字(1)将成为1的Scala表达式的AST,而属性(“x”)变为row.get(“x”)。最后,类似Add(Literal(1),Attribute(“x”))的树成为像1 + row.get(“x”)这样的Scala表达式的AST。

- Spark SQL and DataFrame Programming Guide from Apache Spark
- Data Source API in Spark presentation by Yin Huai
- Introducing DataFrames in Spark for Large Scale Data Science by Reynold Xin
- Beyond SQL: Speeding up Spark with DataFrames by Michael Armbrust
深入研究Spark SQL的Catalyst优化器(原创翻译)的更多相关文章
- SQL Server的优化器会缓存标量子查询结果集吗
在这篇博客"ORACLE当中自定义函数性优化浅析"中,我们介绍了通过标量子查询缓存来优化函数性能: 标量子查询缓存(scalar subquery caching)会通过缓存结果减 ...
- Deep Dive into Spark SQL’s Catalyst Optimizer(中英双语)
文章标题 Deep Dive into Spark SQL’s Catalyst Optimizer 作者介绍 Michael Armbrust, Yin Huai, Cheng Liang, Rey ...
- 有时间了解一下Spark SQL parser的解析器架构
1:了解大体架构 2:了解流程以及各个类的职责 3:尝试编写一个
- Spark SQL在100TB上的自适应执行实践(转载)
Spark SQL是Apache Spark最广泛使用的一个组件,它提供了非常友好的接口来分布式处理结构化数据,在很多应用领域都有成功的生产实践,但是在超大规模集群和数据集上,Spark SQL仍然遇 ...
- DataFrame编程模型初谈与Spark SQL
Spark SQL在Spark内核基础上提供了对结构化数据的处理,在Spark1.3版本中,Spark SQL不仅可以作为分布式的SQL查询引擎,还引入了新的DataFrame编程模型. 在Spark ...
- Spark SQL概念学习系列之Spark SQL 优化策略(五)
查询优化是传统数据库中最为重要的一环,这项技术在传统数据库中已经很成熟.除了查询优化, Spark SQL 在存储上也进行了优化,从以下几点查看 Spark SQL 的一些优化策略. (1)内存列式存 ...
- Spark SQL Catalyst源代码分析Optimizer
/** Spark SQL源代码分析系列*/ 前几篇文章介绍了Spark SQL的Catalyst的核心运行流程.SqlParser,和Analyzer 以及核心类库TreeNode,本文将具体解说S ...
- Apache Spark 2.2中基于成本的优化器(CBO)(转载)
Apache Spark 2.2最近引入了高级的基于成本的优化器框架用于收集并均衡不同的列数据的统计工作 (例如., 基(cardinality).唯一值的数量.空值.最大最小值.平均/最大长度,等等 ...
- 第五篇:Spark SQL Catalyst源码分析之Optimizer
/** Spark SQL源码分析系列文章*/ 前几篇文章介绍了Spark SQL的Catalyst的核心运行流程.SqlParser,和Analyzer 以及核心类库TreeNode,本文将详细讲解 ...
随机推荐
- java.lang.NoSuchMethodError: javax.wsdl.xml.WSDLReader.readWSDL(Ljavax/wsdl/xml/WSDLLocator;Lorg/w3c/dom/Element;)Ljavax/wsdl/Definition;
http://stackoverflow.com/questions/6066054/whats-wrong-with-my-apache-cxf-client You likely have a 1 ...
- 使用bat将优盘中的dig加到系统环境变量
第一次使用bat批处理,记录下,方便查阅. @echo off::当前盘符set curPath=%cd%set digPath ="%curPath%tool\dig"set P ...
- windows 防火墙拦截nginx的问题
今天在azure vm上安装了nginx并配置了代理设置,但域名访问始终无法中转,一开始怀疑是nginx的服务没起来,但在本地访问localhost看下如下界面,证明服务是没问题的. 本地访问没问题, ...
- {style}/index_article.htm {style}表示什么意思啊
LS有点安全意识好不好.... 在你的后台系统设置有个"模板默认风格:________ cfg_df_style " 默认是default也就是 {style}=模板路径+模板默 ...
- windows下如何创建没有名字的.htaccess文件
http://www.mdaima.com/jingyan/35.html WINDOWS下建立空名的.htaccess文件 ? 大家都知道,在windows环境下是不能直接建立没有名字的文件的,那我 ...
- 独立服务器 云主机、VPS以及虚拟主机三者之间的区别是什么?哪个更好?
https://www.zhihu.com/question/21442353#answer-2442764 云主机(如 EC2,[1] )和 VPS (如 Linode,[2])都是完整的操作系统( ...
- django下命令行工具
django-admin.py是Django的一个用户管理任务的命令行工具,manage.py是对django-admin.py的简单包装,每个Django Project里面都包含一个manage. ...
- Do you know how many stuff inside your Google Account?
My friend Sandy she wants me to do her a favor. She'd like to clear Hangouts chat history. I think s ...
- JQ滚动特效
<!DOCTYPE html> <html lang="zh"> <head> <meta charset="UTF-8&quo ...
- 我的Android手册
目录解释说明 assets文件说明 app_id:机智云 app id app_secret:机智云 app secret product_key:机智云 product key wifi_type_ ...