机器学习--kNN算法识别手写字母
本文主要是用kNN算法对字母图片进行特征提取,分类识别。内容如下:
- kNN算法及相关Python模块介绍
- 对字母图片进行特征提取
- kNN算法实现
- kNN算法分析
一、kNN算法介绍
K近邻(kNN,k-NearestNeighbor)分类算法是机器学习算法中最简单的方法之一。所谓K近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。我们将样本分为训练样本和测试样本。对一个测试样本 t 进行分类,kNN的做法是先计算样本 t 到所有训练样本的欧氏距离,然后从中找出k个距离最短的训练样本,用这k个训练样本中出现次数最多的类别表示样本 t 的类别。
欧式距离的计算公式:
假设每个样本有两个特征值,如 A :(a1,b1)B:(a2,b2) 则AB的欧式距离为
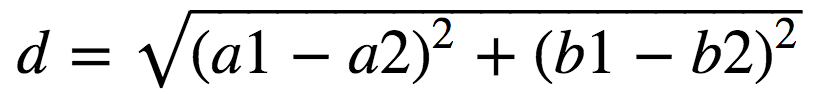
举个例子:根据下图前四位同学的成绩和等级,预测第五位小白同学的等级。
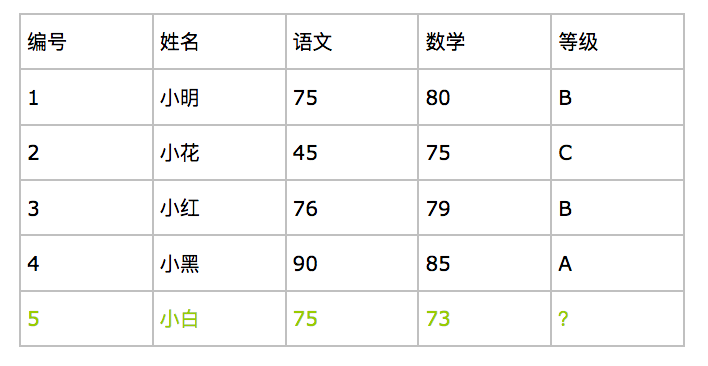
我们可以看出:语文和数学成绩是一个学生的特征,等级是一个学生的类别。
前四位同学是训练样本,第五位同学是测试样本。我们现在用kNN算法来预测第五位同学的等级,k取3。
按照上面欧式距离公式我们可以计算
d(5-1)=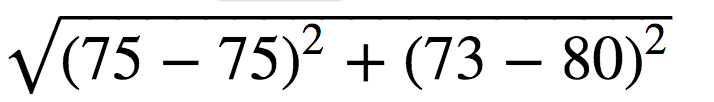 = 7 d(5-2)=
= 7 d(5-2)=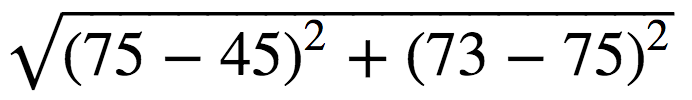 = 30
= 30
d(5-3)=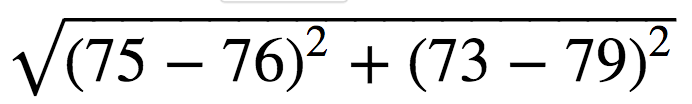 = 6 d(5-4)=
= 6 d(5-4)=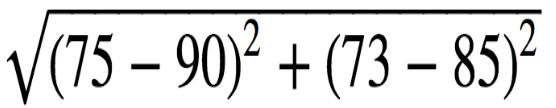 = 19.2
= 19.2
因为 k 取 3,所以我们寻找3个距离最近的样本,即编号为3,1,4的同学,他们的等级分别是 B,B,A。 这三个样本的分类中,出现了2次B,一次A,B出现次数最多,所以5号同学的等级可能为B
常用Python模块
NumPy:NumPy是Python的一种开源的数值计算扩展。这种工具可用来存储和处理大型矩阵,比Python自身的嵌套列表结构要高效的多。
PIL:Python Imaging Library,是Python平台事实上的图像处理标准库,功能非常强大,API也简单易用。但PIL包主要针对Python2,不兼容Python3,所以在Python3中使用Pillow,后者是大牛根据PIL移植过来的,两者用法相同。
上面两个Python库都可以通过pip进行安装。
pip3 install [name]
还有就是Python 自带标准库:shutil模块提供了大量的文件的高级操作,特别针对文件拷贝和删除,主要功能为目录和文件操作以及压缩操作。operator模块是Python 的运算符库,os 模块是Python的系统的和操作系统相关的函数库。
二、对图片进行特征提取
1、采集手写字母的图片素材
有许多提供机器学习数据集的网站,如知乎上的整理 https://www.zhihu.com/question/63383992/answer/222718972 我搜集到的手写字母图片资源如下 链接:https://pan.baidu.com/s/1pM329fl 密码:i725 其中by_class.zip 压缩包是已经分类好的图片样本,可以直接下载使用
2、提取图片素材的特征
最简单的做法是将图片转换为由0 和1 组成的txt 文件,如



转换代码如下:
import os
import shutil
from PIL import Image # image_file_prefix png图片所在的文件夹
# file_name png png图片的名字
# txt_path_prefix 转换后txt 文件所在的文件夹
def generate_txt_image(image_file_prefix, file_name, txt_path_prefix):
"""将图片处理成只有0 和 1 的txt 文件"""
# 将png图片转换成二值图并截取四周多余空白部分
image_path = os.path.join(image_file_prefix, file_name)
# convert('L') 将图片转为灰度图 convert('1') 将图片转为二值图
img = Image.open(image_path, 'r').convert('').crop((32, 32, 96, 96))
# 指定转换后的宽 高
width, height = 32, 32
img.thumbnail((width, height), Image.ANTIALIAS)
# 将二值图片转换为0 1,存储到二位数组arr中
arr = []
for i in range(width):
pixels = []
for j in range(height):
pixel = int(img.getpixel((j, i)))
pixel = 0 if pixel == 0 else 1
pixels.append(pixel)
arr.append(pixels) # 创建txt文件(mac下使用os.mknod()创建文件需要root权限,这里改用复制的方式)
text_image_file = os.path.join(txt_path_prefix, file_name.split('.')[0] + '.txt')
empty_txt_path = "/Users/beiyan/Downloads/empty.txt"
shutil.copyfile(empty_txt_path, text_image_file) # 写入文件
with open(text_image_file, 'w') as text_file_object:
for line in arr:
for e in line:
text_file_object.write(str(e))
text_file_object.write("\n")
将所有素材转换为 txt 后,分为两部分:训练样本 和 测试样本。
三、kNN算法实现
1、将txt文件转为一维数组的方法:
def img2vector(filename, width, height):
"""将txt文件转为一维数组"""
return_vector = np.zeros((1, width * height))
fr = open(filename)
for i in range(height):
line = fr.readline()
for j in range(width):
return_vector[0, height * i + j] = int(line[j])
return return_vector
2、对测试样本进行kNN分类,返回测试样本的类别:
import numpy as np
import os
import operator # test_set 单个测试样本
# train_set 训练样本二维数组
# labels 训练样本对应的分类
# k k值
def classify(test_set, train_set, labels, k):
"""对测试样本进行kNN分类,返回测试样本的类别"""
# 获取训练样本条数
train_size = train_set.shape[0] # 计算特征值的差值并求平方
# tile(A,(m,n)),功能是将数组A行重复m次 列重复n次
diff_mat = np.tile(test_set, (train_size, 1)) - train_set
sq_diff_mat = diff_mat ** 2 # 计算欧式距离 存储到数组 distances
sq_distances = sq_diff_mat.sum(axis=1)
distances = sq_distances ** 0.5 # 按距离由小到大排序对索引进行排序
sorted_index = distances.argsort() # 求距离最短k个样本中 出现最多的分类
class_count = {}
for i in range(k):
near_label = labels[sorted_index[i]]
class_count[near_label] = class_count.get(near_label, 0) + 1
sorted_class_count = sorted(class_count.items(), key=operator.itemgetter(1), reverse=True)
return sorted_class_count[0][0]
3、统计分类错误率
# train_data_path 训练样本文件夹
# test_data_path 测试样本文件夹
# k k个最近邻居
def get_error_rate(train_data_path, test_data_path, k):
"""统计识别错误率"""
width, height = 32, 32
train_labels = [] training_file_list = os.listdir(train_data_path)
train_size = len(training_file_list) # 生成全为0的训练集数组
train_set = np.zeros((train_size, width * height)) # 读取训练样本
for i in range(train_size):
file = training_file_list[i]
file_name = file.split('.')[0]
label = str(file_name.split('_')[0])
train_labels.append(label)
train_set[i, :] = img2vector(os.path.join(train_data_path, training_file_list[i]), width, height) test_file_list = os.listdir(test_data_path)
# 识别错误的个数
error_count = 0.0
# 测试样本的个数
test_count = len(test_file_list) # 统计识别错误的个数
for i in range(test_count):
file = test_file_list[i]
true_label = file.split('.')[0].split('_')[0] test_set = img2vector(os.path.join(test_data_path, test_file_list[i]), width, height)
test_label = classify(test_set, train_set, train_labels, k)
print(true_label, test_label)
if test_label != true_label:
error_count += 1.0
percent = error_count / float(test_count)
print("识别错误率是:{}".format(str(percent)))
上述完整代码地址:https://gitee.com/beiyan/machine_learning/tree/master/knn
4、测试结果
训练样本: 0-9,a-z,A-Z 共62个字符,每个字符选取120个训练样本 , 一共有7440 个训练样本。每个字符选取20个测试样本,一共1200个测试样本。
尝试改变条件,测得识别正确率如下:

四、kNN算法分析
由上部分结果可知:knn算法对于手写字母的识别率并不理想。
原因可能有以下几个方面:
1、图片特征提取过于简单,图片边缘较多空白,且图片中字母的中心位置未必全部对应
2、因为英文有些字母大小写比较相似,容易识别错误
3、样本规模较小,每个字符最多只有300个训练样本,真正的训练需要海量数据
在后序的文章中尝试用其他学习算法提高分类识别率。各位道友有更好的意见也欢迎提出!
机器学习--kNN算法识别手写字母的更多相关文章
- KNN算法识别手写数字
需求: 利用一个手写数字“先验数据”集,使用knn算法来实现对手写数字的自动识别: 先验数据(训练数据)集: ♦数据维度比较大,样本数比较多. ♦ 数据集包括数字0-9的手写体. ♦每个数字大约有20 ...
- 基于OpenCV的KNN算法实现手写数字识别
基于OpenCV的KNN算法实现手写数字识别 一.数据预处理 # 导入所需模块 import cv2 import numpy as np import matplotlib.pyplot as pl ...
- KNN (K近邻算法) - 识别手写数字
KNN项目实战——手写数字识别 1. 介绍 k近邻法(k-nearest neighbor, k-NN)是1967年由Cover T和Hart P提出的一种基本分类与回归方法.它的工作原理是:存在一个 ...
- Python实现KNN算法及手写程序识别
1.Python实现KNN算法 输入:inX:与现有数据集(1xN)进行比较的向量 dataSet:已知向量的大小m数据集(NxM) 个标签:数据集标签(1xM矢量) k:用于比较的邻居数 ...
- Python实现神经网络算法识别手写数字集
最近忙里偷闲学习了一点机器学习的知识,看到神经网络算法时我和阿Kun便想到要将它用Python代码实现.我们用了两种不同的方法来编写它.这里只放出我的代码. MNIST数据集基于美国国家标准与技术研究 ...
- KNN算法案例--手写数字识别
import numpy as np import matplotlib .pyplot as plt import pandas as pd from sklearn.neighbors impor ...
- KNN算法实现手写数字
from numpy import * import operator from os import listdir def classify0(inX, dataSet, labels, k): d ...
- KNN 算法-实战篇-如何识别手写数字
公号:码农充电站pro 主页:https://codeshellme.github.io 上篇文章介绍了KNN 算法的原理,今天来介绍如何使用KNN 算法识别手写数字? 1,手写数字数据集 手写数字数 ...
- 【Machine Learning in Action --2】K-近邻算法构造手写识别系统
为了简单起见,这里构造的系统只能识别数字0到9,需要识别的数字已经使用图形处理软件,处理成具有相同的色彩和大小:宽高是32像素的黑白图像.尽管采用文本格式存储图像不能有效地利用内存空间,但是为了方便理 ...
随机推荐
- from Require.js to Webpack(why)
写在前面: 本文主要参考 From Require.js to Webpack - Part 1 (the reasons),原文作者将项目从 require.js 转移到了 webpack 并详细说 ...
- AOP及spring AOP的使用
介绍 AOP是一种概念(思想),并没有设定具体语言的实现. AOP是对oop的一种补充,不是取而代之. 具体思想:定义一个切面,在切面的纵向定义处理方法,处理完成之后,回到横向业务流. 特征 散布于应 ...
- mysql 在B数据库下 创建一个与A数据库中一样的表
1.创建数据内容与结构一致(不会复制索引以及外键) create table B.test as select * from A.test; 2.把上面的步骤分开,先复制结构 create table ...
- React Native学习(三)—— 使用导航器Navigation跳转页面
本文基于React Native 0.52 参考文档https://reactnavigation.org/docs/navigators/navigation-prop 一.基础 1.三种类型 Ta ...
- 读书笔记-JavaScript面向对象编程(三)
第7章 浏览器环境 7.1 在HTML页面中引入JavaScript代码 7.2概述BOM与DOM(页面以外事物对象和当前页面对象) 7.3 BOM 7.3.1 window对象再探(所以JavaSc ...
- Django查询笔记1
models.Book.objects.filter(**kwargs): querySet [obj1,obj2] models.Book.objects.filter(**kwargs).valu ...
- HDU 2037 今年暑假不AC(贪心,区间更新,板子题)
今年暑假不AC Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Total Su ...
- [51nod1614]刷题计划
大赛将至,摆在你面前的是n道题目,第 i(1 ≤ i ≤ n) 道题目能提升 ai 点智力值,代码量为 bi KB,无聊值为 ci ,求至少提升m点智力值的情况下,所做题目代码量之和*无聊值之和最小为 ...
- c语言中标识符的作用域
1.代码块作用域(block scope) 位于一对花括号之间的所有语句称为一个代码块,在代码块的开始位置声明的标识符具有代码块作用域,表示它们可以被这个代码中的所有语句访问.函数定义的形式参数在函数 ...
- Windows下MYSQL读取文件为NULL
只记录解决问题的方法. mysql 版本: 5.7.18 问题: 在执行mysql 函数load_file时,该函数将加载指定文件的内容,存储至相应字段.如: SELECT LOAD_FILE(&qu ...