【Python】利用豆瓣短评数据生成词云
在之前的文章中,我们获得了豆瓣爬取的短评内容,汇总到了一个文件中,但是,没有被利用起来的数据是没有意义的。
前文提到,有一篇微信推文的关于词云制作的一个实践记录,准备照此试验一下。
思路分析
读文件
利用with open() as...将文件读进来。这里需要注意文件内容的大小。
分词
由于获取的是大量的短评文字,而制作词云需要的是各种词语,有了词,才能谈词云,所以目前第一步需求的就是讲短评内容拆分成一个个的中文词汇。
这里就用到了我所听过的一个库jieba,可以将中文语句拆解成一个个的词汇。这里是用的是lcut()方法,能将中文字符串拆解成一个列表,每项都是一个词。
清洗非中文
但是,我们在分析中,需要的就是中文文字,所以需要将非中文字符彻底清理,这里使用了正则表达式。短小精悍的一个模式[\u4e00-\u9fa5]+即可匹配。
使用正则表达式,我的习惯是现在网上的一些在线正则表达式工具上直接测试。其中oschina的不错,还给提供了一些例子。
这里是oschina的工具网站,做的很好。
处理停词
由于这些词汇中,有很多词是没有实际分析价值的,所以我们需要利用一个停词文件来将不必要的词处理掉。
参考文章中,是利用pandas库汇总的方法read_csv()来处理停词文件。,利用一个isin()方法实现了停词。
聚合
词分开了,基本也处理干净了。接下来应该考虑制作词云的问题。
我们这里想要重点突出在所有评论中的重要的核心观点,为了实现这样的目的,我们使用了分词。
这似乎是一种有些“断章取义”的思路。借助词频的分布实现重点突出高词频内容的方式,来展现我们的词云。
所以现在我们需要做的事,就是处理词汇的聚合问题,统计词频而已。
参考文种中利用了类DataFrame的分组方法group()和聚合方法agg()。
关于这里,参考文章中在agg()中使用了一个显式的字典(可见文末参考文章),调用了numpy.size,但是似乎是这种用法将来会被移除,查了一些文章,说是可以这样用,就是不能自己定制字典了。
FutureWarning: using a dict on a Series for aggregation is deprecated and will be removed in a future version
词云
这里使用了第三方库wordcloud。这个库在安装的时候,直接pip install wordcloud时,我出了问题,提示微软开发工具的问题,折腾了半天,最后还是直接在一个极为丰富的第三方库的集合站点上下载使用pip insatll了它的whl文件。
这下可以正常使用了。
同时,这里为了能够显示处理图片,使用了matplotlib.pyplot&numpy来进行处理。
掩膜设置
由wordcloud项目主页README 了解,可以使用二值图像来设定掩膜(mask)。
出于提升数据的表现力,也出于学习的目的,这里使用了直接编写的rgb2gray()&gray2bw()函数来实现真彩图像转换为二值图像的过程。获得了最终的二值图像掩膜。
这里开始我并不知道需要怎样的图像,看了给的示例代码,用的图片的是二值图像,才明白,白白浪费了好多时间。
而且,我的理解,由彩色转为二值图像,是必要经过灰度图像这个过程的。
关于matplotlib.pyplot的使用,网上都说,和matlab的语法很类似,以前了解过一点,所以看着例子中的imshow(),很自然的就想出了imread(),实现了图片的读取。
在查阅文档的过程中发现了一个有意思的地方。
Return value is a numpy.array. For grayscale images, the return array is MxN. For RGB images, the return value is MxNx3. For RGBA images the return value is MxNx4.
matplotlib can only read PNGs natively, but if PIL is installed, it will use it to load the image and return an array (if possible) which can be used with imshow(). Note, URL strings may not be compatible with PIL. Check the PIL documentation for more information.
我文中使用的是JPG图像,可见是调用了PIL处理。
而这里对于二值图像的获取,开始经历了一个误区。由于在网上搜索的时候,搜到的大多是利用PIL库的Image模块的open()&convert()方法的处理,附加参数1,可以实现二值图像的转化,但是在这里使用,后面在使用词云的时候,会提示缺少属性,可见这里不适合这样处理。
词云设定
词云支持自定义字体,背景颜色,掩膜设置等等,可以直接在IDE中跳至源文件中查看。都有相关的介绍。
文末代码是一些参数的摘录。
词频选择
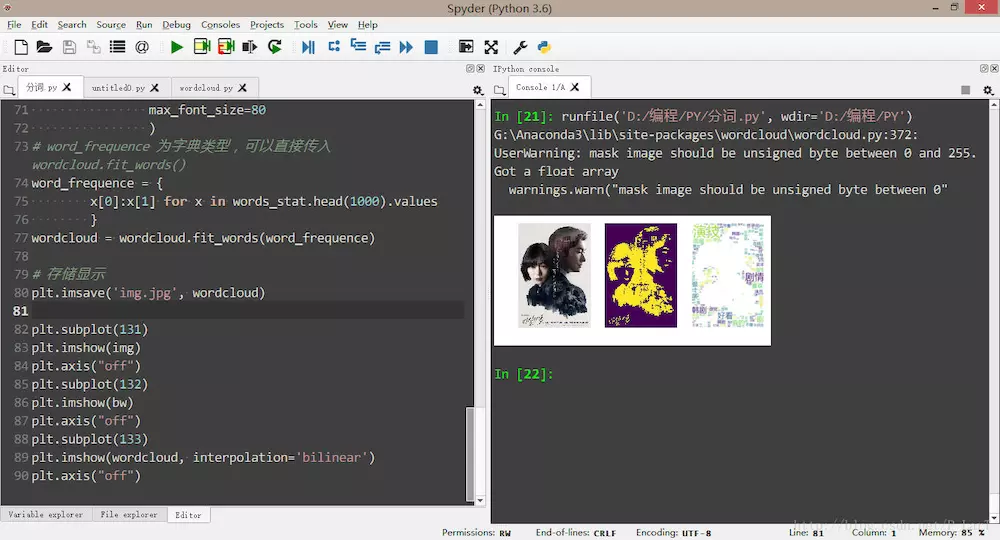
这里使用了刚才聚合排序好的数据,选择了前1000个词进行展示,并组合成字典,传入了词云的实例对象的方法fit_words()生成了词云。
词云展示
这里使用了matplotlib.pyplot的的几个函数,实现了图像的保存,显示,以及坐标轴的隐藏。
这里倒是有个小异或,有点分不清楚imshow()与show()了。两者从文档我也没看出个所以然来。不过他们有个最明显的区别就是后者依赖图形窗口,但是前者似乎不需要。
要是有明白的,还请大家留言或者发邮件给我。
完整代码
# -*- coding: utf-8 -*-
"""
Created on Thu Aug 17 16:31:35 2017
@note: 为了便于阅读,将模块的引用就近安置了
@author: lart
"""
# 读取事先爬取好的文件,由于文件较小,直接一次性读入。若文件较大,则最好分体积读入。
with open('秘密森林的短评.txt', 'r', encoding='utf-8') as file:
comments = file.readlines()
comment = ''.join(comments)
# 摘取中文字符,没有在下载时处理,正好保留原始数据。
import re
pattern = re.compile(r'[\u4e00-\u9fa5]+')
data = pattern.findall(comment)
filted_comment = ''.join(data)
# 分词
import jieba
word = jieba.lcut(filted_comment)
# 整理
import pandas as pd
words_df = pd.DataFrame({'words': word})
#停词相关设置。参数 quoting=3 全不引用
stopwords = pd.read_csv(
"stopwords.txt",
index_col=False,
quoting=3,
sep="\t",
names=['stopword'],
encoding='utf-8'
)
words_df = words_df[~words_df.words.isin(stopwords.stopword)]
# 聚合
words_stat = words_df.groupby('words')['words'].agg({'size'})
words_stat = words_stat.reset_index().sort_values("size", ascending=False)
# 词云设置
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import numpy as np
def rgb2gray(rgb):
return np.dot(rgb[...,:3], [0.299, 0.587, 0.114])
def gray2bw(gray):
for raw in range(len(gray)):
for col in range(len(gray[raw])):
gray[raw][col] = (0 if gray[raw][col]>50 else 255)
return gray
img = plt.imread('4.jpg')
mask = rgb2gray(img)
bw = gray2bw(mask)
wordcloud = WordCloud(
font_path="YaHei Consolas Hybrid.ttf",
background_color="white",
mask=bw,
max_font_size=80
)
# word_frequence 为字典类型,可以直接传入wordcloud.fit_words()
word_frequence = {
x[0]:x[1] for x in words_stat.head(1000).values
}
wordcloud = wordcloud.fit_words(word_frequence)
# 存储显示
plt.imsave('img.jpg', wordcloud)
plt.subplot(131)
plt.imshow(img)
plt.axis("off")
plt.subplot(132)
plt.imshow(bw)
plt.axis("off")
plt.subplot(133)
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
结果文件
使用的掩膜原图片:
- 秘密森林剧照

- 输出图片

- IDE输出结果
停词文件
Parameters
----------
font_path : string
Font path to the font that will be used (OTF or TTF).
Defaults to DroidSansMono path on a Linux machine. If you are on
another OS or don't have this font, you need to adjust this path.
width : int (default=400)
Width of the canvas.
height : int (default=200)
Height of the canvas.
prefer_horizontal : float (default=0.90)
The ratio of times to try horizontal fitting as opposed to vertical.
If prefer_horizontal < 1, the algorithm will try rotating the word
if it doesn't fit. (There is currently no built-in way to get only
vertical words.)
mask : nd-array or None (default=None)
If not None, gives a binary mask on where to draw words. If mask is not
None, width and height will be ignored and the shape of mask will be
used instead. All white (#FF or #FFFFFF) entries will be considerd
"masked out" while other entries will be free to draw on. [This
changed in the most recent version!]
scale : float (default=1)
Scaling between computation and drawing. For large word-cloud images,
using scale instead of larger canvas size is significantly faster, but
might lead to a coarser fit for the words.
min_font_size : int (default=4)
Smallest font size to use. Will stop when there is no more room in this
size.
font_step : int (default=1)
Step size for the font. font_step > 1 might speed up computation but
give a worse fit.
max_words : number (default=200)
The maximum number of words.
stopwords : set of strings or None
The words that will be eliminated. If None, the build-in STOPWORDS
list will be used.
background_color : color value (default="black")
Background color for the word cloud image.
max_font_size : int or None (default=None)
Maximum font size for the largest word. If None, height of the image is
used.
mode : string (default="RGB")
Transparent background will be generated when mode is "RGBA" and
background_color is None.
relative_scaling : float (default=.5)
Importance of relative word frequencies for font-size. With
relative_scaling=0, only word-ranks are considered. With
relative_scaling=1, a word that is twice as frequent will have twice
the size. If you want to consider the word frequencies and not only
their rank, relative_scaling around .5 often looks good.
.. versionchanged: 2.0
Default is now 0.5.
color_func : callable, default=None
Callable with parameters word, font_size, position, orientation,
font_path, random_state that returns a PIL color for each word.
Overwrites "colormap".
See colormap for specifying a matplotlib colormap instead.
regexp : string or None (optional)
Regular expression to split the input text into tokens in process_text.
If None is specified, ``r"\w[\w']+"`` is used.
collocations : bool, default=True
Whether to include collocations (bigrams) of two words.
.. versionadded: 2.0
colormap : string or matplotlib colormap, default="viridis"
Matplotlib colormap to randomly draw colors from for each word.
Ignored if "color_func" is specified.
.. versionadded: 2.0
normalize_plurals : bool, default=True
Whether to remove trailing 's' from words. If True and a word
appears with and without a trailing 's', the one with trailing 's'
is removed and its counts are added to the version without
trailing 's' -- unless the word ends with 'ss'.
【Python】利用豆瓣短评数据生成词云的更多相关文章
- python 基于 wordcloud + jieba + matplotlib 生成词云
词云 词云是啥?词云突出一个数据可视化,酷炫.以前以为很复杂,不想python已经有成熟的工具来做词云.而我们要做的就是准备关键词数据,挑一款字体,挑一张模板图片,非常非常无脑.准备好了吗,快跟我一起 ...
- Python 情人节超强技能 导出微信聊天记录生成词云
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: Python实用宝典 PS:如有需要Python学习资料的小伙伴可 ...
- 用python爬取微博数据并生成词云
很早之前写过一篇怎么利用微博数据制作词云图片出来,之前的写得不完整,而且只能使用自己的数据,现在重新整理了一下,任何的微博数据都可以制作出来,放在今天应该比较应景. 一年一度的虐汪节,是继续蹲在角落默 ...
- python爬取豆瓣流浪地球影评,生成词云
代码很简单,一看就懂. (没有模拟点击,所以都是未展开的) 地址: https://movie.douban.com/subject/26266893/reviews?rating=&star ...
- python抓取数据构建词云
1.词云图 词云图,也叫文字云,是对文本中出现频率较高的"关键词"予以视觉化的展现,词云图过滤掉大量的低频低质的文本信息,使得浏览者只要一眼扫过文本就可领略文本的主旨. 先看几个词 ...
- 从CentOS安装完成到生成词云python学习日记
欢迎访问我的个人博客:原文链接 前言 人生苦短,我用python.学习python怎么能不搞一下词云呢是不是(ง •̀_•́)ง 于是便有了这篇边实践边记录的笔记. 环境:VMware 12pro + ...
- 用Python生成词云
词云以词语为基本单元,根据词语在文本中出现的频率设计不同大小的形状以形成视觉上的不同效果,从而使读者只要“一瞥“即可领略文本的主旨.以下是一个词云的简单示例: import jieba from wo ...
- 【python】itchat登录微信获取好友签名并生成词云
在知乎上看到一篇关于如何使用itchat统计微信好友男女比例并使用plt生成柱状图以及获取微信好友签名并生成词云的文章https://zhuanlan.zhihu.com/p/36361397,感觉挺 ...
- Python统计excel表格中文本的词频,生成词云图片
import xlrd import jieba import pymysql import matplotlib.pylab as plt from wordcloud import WordClo ...
随机推荐
- Linux下vim显示行数
在Linux环境下的编辑器有vi.vim.gedit等等.进入这些编辑器之后,为了方便我们需要编辑器显示出当前的行号,可偏偏编辑器默认是不会显示行号的.我们有二种办法可以解决: 第一种是,手动显示:在 ...
- [project X] tiny210(s5pv210)上电启动流程(BL0-BL2)(转)
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/ooonebook/article/det ...
- 在vue-cli中使用px2rem,配合lib-flexible使用
原文地址 附上github源码 看这里 1.下载lib-flexible npm安装 npm i lib-flexible --save 2.引入lib-flexible 在main.js中引入li ...
- linux常用基本命令不全
pwd 显示当前目录 ls -lh 显示文件列表,h表示会显示文件的大小 mkdir zhu 创建文件夹zhu rmdir zhu 移除文件夹zhu如果abc中含有其他文件,则不能删除 rm -r ...
- C#Regex中replace方法的替换自定义小数点后的内容
$1应该就是引用了这个组,不用这个会匹配不到 /// <summary> /// 截取 /// </summary> /// <param name="n&qu ...
- php大文件分片上传插件
PHP用超级全局变量数组$_FILES来记录文件上传相关信息的. 1.file_uploads=on/off 是否允许通过http方式上传文件 2.max_execution_time=30 允许脚本 ...
- VMWare虚拟机启动不了有个叉叉的解决办法
打开VMWare虚拟机提示有: This virtual machine appears to be in use. If this virtual machine is already in use ...
- UML——用例视图
用例视图中交互功能部分被称为用例. 参与者 作为外部用户与系统发生交互作用,这是参与者的特征. 在系统的实际运作中,一个实际用户可能对应系统的多个参与者.不同的用户也可以只对应于一个参与者,从 ...
- android 文件保存到应用和sd卡中
<span style="font-size:18px;">1.权限添加 <uses-permission android:name="android. ...
- 3D Computer Grapihcs Using OpenGL - 17 添加相机(旋转)
在11节我们说过,MVP矩阵中目前只应用了两个矩阵,World to View 矩阵被省略了,这就导致我们的画面没有办法转换视角. 本节我们将添加这一环节,让相机可以旋转. 为了实现这一目的,我们添加 ...