机器学习——k-近邻(K-Nearest Neighbor)
K-Nearest neighbor
(个人观点,仅供参考。)
k-近邻算法,第一个机器学习算法,非常有效且易掌握,本文将主要探讨k-近邻算法的基本理论和使用距离侧量的算法分类物品;最后通过k-近邻算法改进约会网站和手写数字识别系统。文章内容参考《机器学习实战》
K-近邻分类算法
简单的说,通过采用不同特征值之间的距离方法进行分类
优点:精度高,对异值不敏感,无数据输入假定。
缺点:计算复杂、需要大量的内存。
适用于:数值型和标称型数据。
工作原理: 在训练集中,每个样本都存在标签,即我们知道样本集中每一个数据与所属的分类的对应关系。当我们给一个没有标签的数据时,我们比较这份数据与现有的所有数据分别进行比较,然后算法从样本集中提取样本集中特征最相近似数据的分类标签。一般来说,我们只选择样本数据集中前K个相似的的数据,通常k不大于20;
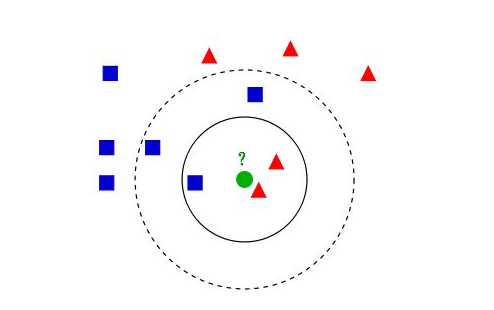
图来自wiki
例:区分电影的类型,人类可以工具自己对影片的理解来区分影片类型,但是机器则没有那么高级。但可以根据类型的特性来却别,例如爱情片打kiss的要多于动作片打Kiss的场景,动作片kick的场景要多与kiss。假设你无聊数了几部电影中kiss和kick的场景,数据如下图:

根据上表使用python画出散点图
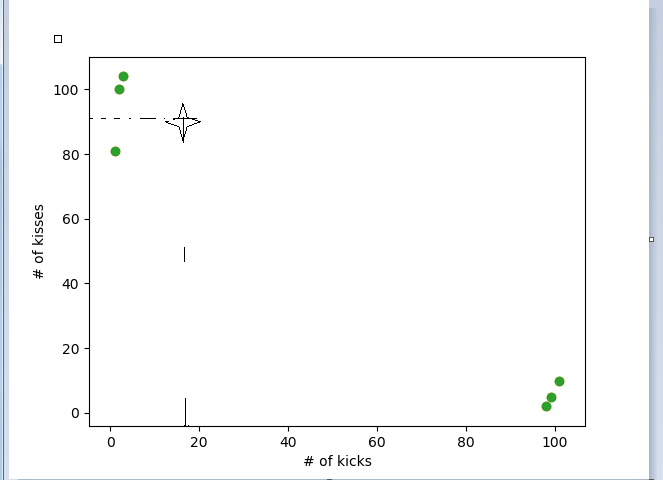
从图中可以很明了的看出未知类型的电影和哪一类电影更相近一些,假设这里的k取值三,这里靠近未知电影的的三部电影全部为爱情电影,所以我们判定未知电影为爱情片。
按照上一篇文章机器学习的基本步骤,将使用python完成一个简单的KNN算法的。
KNN算法的简单方法:
1.收集数据:任何方式
2.准备数据:计算距离所需要的数据,最好是结构化的数据
3.分析数据:
4.训练数据:KNN算法不需要
5.测试:计算误差
6.算法应用
from numpy import *import operatordef createDataSet():group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])labels = ['A','A','B','B']return group, labels
K-Nearest Neighbors 算法
从文本文件中解析和导入数据
# KNN Load data from files and translate to matrisdef file2matrix(filename):fr = open(filename, encoding='utf-8')# get number of lines in filesnumberOfLines = len(fr.readlines())# create Numpy matrix to return# create a matrix [0,0,0]returnMat = zeros((numberOfLines,3))classLabelVector = []fr = open(filename,encoding='utf-8')index = 0for line in fr.readlines():# strip() return a copy of the sequence with speciafied leading and trailing bytes removedline = line.strip()# split() split the binary sequence into subsequenceds of the same type, using sep as the delimiter stringlistFromLine = line.split('\t')# print (listFromLine)# 提取数据前三列 which generate a new matrix listFromLinereturnMat[index,:] = listFromLine[0:3]# print (returnMat)# print (listFromLine)# print (listFromLine[0:3])# according to the flag to classify# print (listFromLine)classLabelVector.append(int(listFromLine[-1]))index = index + 1return returnMat,classLabelVector
(原文中的代码有些问题。文件数据中的最后一列需要转化成为数字)
使用python创建扩散图
分别定义了三个绘制散点图的函数:
# 绘制不带标签的散点图def draw_scatter_noLabels(datingDataMat):fig = plt.figure()# 设置画布的布局ax = fig.add_subplot(111)ax.scatter(datingDataMat[:,1],datingDataMat[:,2])return (plt.show())# 绘制无标签数据def draw_Time_Icecream_scatter_withLabels(datingDataMat,datingLabels):fig = plt.figure()ax = fig.add_subplot(111)ax.scatter(datingDataMat[:,1],datingDataMat[:,2],15*array(datingLabels),15*array(datingLabels))ax.set_title('Hellen\'s data')ax.set_xlabel('percentage of Time Spent Playing Video Games')ax.set_ylabel('Liters of ice cream consumed per week')return (plt.show())# 绘制带有标签的Flyier MIles-Time spent on the video gamedef draw_Miles_Time_scatter_withLabels(datingDataMat,datingLabels):fig = plt.figure()ax = fig.add_subplot(111)# identify three class type1 不喜欢 type2 喜欢 type3很喜欢type1_x = []type1_y = []type2_x = []type2_y = []type3_x = []type3_y = []for i in range(len(datingLabels)):# print (datingLabels)if datingLabels[i] == 1:type1_x.append(datingDataMat[i][0])type1_y.append(datingDataMat[i][1])if datingLabels[i] == 2:type2_x.append(datingDataMat[i][0])type2_y.append(datingDataMat[i][1])if datingLabels[i] == 3:type3_x.append(datingDataMat[i][0])type3_y.append(datingDataMat[i][1])type1 = ax.scatter(type1_x,type1_y,s=20,c='r')type2 = ax.scatter(type2_x,type2_y,s=40,c='y')type3 = ax.scatter(type3_x,type3_y,s=60,c='b')# ax.scatter(datingDataMat[:,0],datingDataMat[:,1],15*array(datingLabels),15*array(datingLabels),label=datingLabels)ax.set_title('Hellen\'s data')ax.set_xlabel('Frequent Flyier Mils earned Per Year')ax.set_ylabel('percentage of time spentplaying video games')plt.legend((type1,type2,type3),("Did Not like ",'Like in small Does','liked in large Does'))return (plt.show())
归一化数值
···
http://docs.alerta.io/en/latest/index.html
http://alerta.io/
End Sub
机器学习——k-近邻(K-Nearest Neighbor)的更多相关文章
- 机器学习分类算法之K近邻(K-Nearest Neighbor)
一.概念 KNN主要用来解决分类问题,是监督分类算法,它通过判断最近K个点的类别来决定自身类别,所以K值对结果影响很大,虽然它实现比较简单,但在目标数据集比例分配不平衡时,会造成结果的不准确.而且KN ...
- K近邻(k-Nearest Neighbor,KNN)算法,一种基于实例的学习方法
1. 基于实例的学习算法 0x1:数据挖掘的一些相关知识脉络 本文是一篇介绍K近邻数据挖掘算法的文章,而所谓数据挖掘,就是讨论如何在数据中寻找模式的一门学科. 其实人类的科学技术发展的历史,就一直伴随 ...
- k近邻法( k-nearnest neighbor)
基本思想: 给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的k个实例,这k个实例的多数属于某个类,就把该输入实例分为这个类 距离度量: 特征空间中两个实例点的距离是两个实例点相似 ...
- k近邻法(k-nearest neighbor, k-NN)
一种基本分类与回归方法 工作原理是:1.训练样本集+对应标签 2.输入没有标签的新数据,将新的数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本最相似数据(最近邻)的分类标签. 3.一般 ...
- k 近邻算法(k-Nearest Neighbor,简称kNN)
预约助教问题: 1.计算1-NN,k-nn和linear regression这三个算法训练和查询的时间复杂度和空间复杂度? 一. WHy 最简单最初级的分类器是将全部的训练数据所对应的类别都记录下来 ...
- 第三章 K近邻法(k-nearest neighbor)
书中存在的一些疑问 kd树的实现过程中,为何选择的切分坐标轴要不断变换?公式如:x(l)=j(modk)+1.有什么好处呢?优点在哪?还有的实现是通过选取方差最大的维度作为划分坐标轴,有何区别? 第一 ...
- 基本分类方法——KNN(K近邻)算法
在这篇文章 http://www.cnblogs.com/charlesblc/p/6193867.html 讲SVM的过程中,提到了KNN算法.有点熟悉,上网一查,居然就是K近邻算法,机器学习的入门 ...
- (数据挖掘-入门-6)十折交叉验证和K近邻
主要内容: 1.十折交叉验证 2.混淆矩阵 3.K近邻 4.python实现 一.十折交叉验证 前面提到了数据集分为训练集和测试集,训练集用来训练模型,而测试集用来测试模型的好坏,那么单一的测试是否就 ...
- K近邻算法小结
什么是K近邻? K近邻一种非参数学习的算法,可以用在分类问题上,也可以用在回归问题上. 什么是非参数学习? 一般而言,机器学习算法都有相应的参数要学习,比如线性回归模型中的权重参数和偏置参数,SVM的 ...
- 统计学习三:1.k近邻法
全文引用自<统计学习方法>(李航) K近邻算法(k-nearest neighbor, KNN) 是一种非常简单直观的基本分类和回归方法,于1968年由Cover和Hart提出.在本文中, ...
随机推荐
- vue项目-本机ip地址访问
修改 在 vue项目文件夹中的 package.json scripts >dev 添加 --host 0.0.0.0 "dev": "webpack-dev-se ...
- SQL Server数据库的软硬件性能瓶颈
在过去十年里,很多复杂的企业应用都是用Microsoft SQL Server进行开发和部署的.如今,SQL Server已经成为现代业务应用的基石,并且它还是很多大公司业务流程的核心.SQL Ser ...
- Python3解leetcode Reach a Number
问题描述: You are standing at position 0 on an infinite number line. There is a goal at position target. ...
- 20180708-Java变量类型
public class Test{ public void pupAge(){ int age = 0; age = age + 7; System.out.println("Puppy ...
- hdu 5511 Minimum Cut-Cut——分类讨论思想+线段树合并
题目:http://acm.hdu.edu.cn/showproblem.php?pid=5511 题意:割一些边使得无向图变成不连通的,并且恰好割了两条给定生成树上的边.满足非树边两段一定在给定生成 ...
- 整合ssm三大框架使用注解开发查询用户信息
整合ssm三大框架使用注解开发查询用户信息 一.基础知识准备之spring mvc工作原理 二.分析 第一步:发起请求到前端控制器(DispatcherServlet) 第二步:前端控制器请求Hand ...
- ERROR 1146 (42S02): Table 'mysql.servers' doesn't exist
MySQL版本:mysql5.7.21 修改用户权限,刷新权限表,报1146 mysql> flush privileges; ERROR 1146 (42S02): Table 'mysql. ...
- python 数字系列-无穷大与NaN
无穷大与NaN 问题 你想创建或测试正无穷.负无穷或NaN(非数字)的浮点数. 解决方案 Python并没有特殊的语法来表示这些特殊的浮点值,但是可以使用 float() 来创建它们.比如: > ...
- 1204C Anna, Svyatoslav and Maps
题目大意 给你一个有向图和一个路径 让你在给定路径中选出尽量少的点使得新路径的最短路长度和原路径相等 给定路径相邻两点间距离为1 分析 先floyd求出两点间最短路 之后每次对于点i找到所有跟它的最短 ...
- jenkins持续集成、插件以及凭据
Jenkins介绍 Jenkins是一个开源软件项目,是基于Java开发的一种持续集成工具,用于监控持续重复的工作,旨在提供一个开放易用的软件平台,使软件的持续集成变成可能. Jenkins功能包括: ...