Java高并发网络编程(三)NIO
从Java 1.4开始,Java提供了新的非阻塞IO操作API,用意是替代Java IO和Java Networking相关的API。
NIO中有三个核心组件:
- Buffer缓冲区
- Channel通道
- Selector选择器
一、Buffer缓冲区
缓冲区本质上是一个可以写入数据的内存块(类似数组),然后可以再次读取。此内存块包含在NIO Buffer对象中,该对象提供了一组方法,可以更轻松地使用内存块。
相比较直接对数组的操作,BufferAPI更容易操作和管理。
使用Buffer进行数据写入与读取的四个步骤:
- 将数据写入缓冲区
- 调用buffer.flip(),转换为读取模式
- 缓冲区读取数据
- 调用buffer.clear()或buffer.compact()清除缓冲区
Buffer工作原理
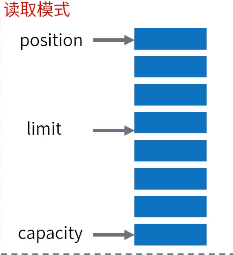
Buffer三个重要属性:
capacity容量:作为一个内存块,Buffer具有一定的固定大小,称为“容量”。
position位置:写入模式时代表写数据的位置。读取模式时代表读取数据的位置。
limit限制:写入模式,限制等于buffer的容量。读取模式下,limit等于写入的数据量。


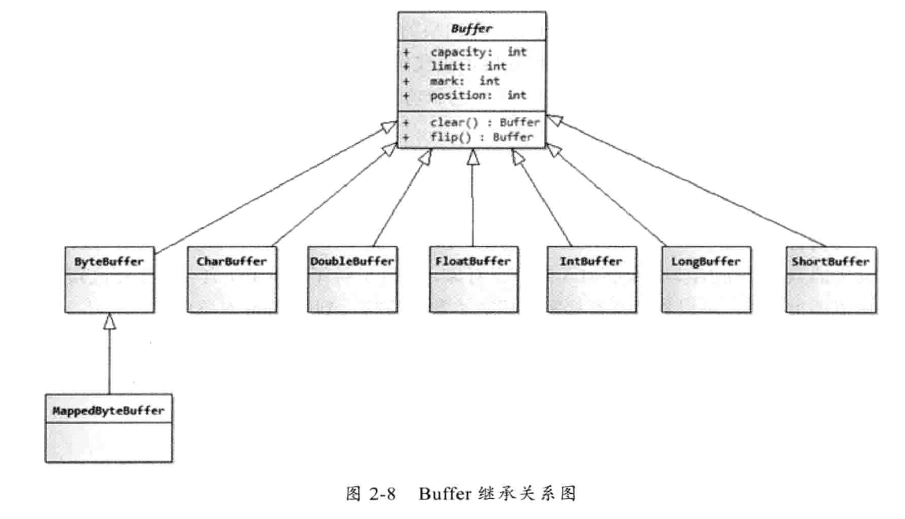
Buffer的API
一个示例
public class BufferDemo {
public static void main(String[] args) {
// 构建一个byte字节缓冲区,容量是4
ByteBuffer byteBuffer = ByteBuffer.allocate(4);
// 默认写入模式,查看三个重要的指标
System.out.println(String.format("初始化:capacity容量:%s, position位置:%s, limit限制:%s", byteBuffer.capacity(),
byteBuffer.position(), byteBuffer.limit()));
// 写入3字节的数据
byteBuffer.put((byte) 1);
byteBuffer.put((byte) 2);
byteBuffer.put((byte) 3);
// 再看数据
System.out.println(String.format("写入3字节后,capacity容量:%s, position位置:%s, limit限制:%s", byteBuffer.capacity(),
byteBuffer.position(), byteBuffer.limit()));
// 转换为读取模式(不调用flip方法,也是可以读取数据的,但是position记录读取的位置不对)
System.out.println("#######开始读取");
byteBuffer.flip();
byte a = byteBuffer.get();
System.out.println(a);
byte b = byteBuffer.get();
System.out.println(b);
System.out.println(String.format("读取2字节数据后,capacity容量:%s, position位置:%s, limit限制:%s", byteBuffer.capacity(),
byteBuffer.position(), byteBuffer.limit()));
// 继续写入3字节,此时读模式下,limit=3,position=2.继续写入只能覆盖写入一条数据
// clear()方法清除整个缓冲区。compact()方法仅清除已阅读的数据。转为写入模式
byteBuffer.compact(); // buffer内部还残留1个数据,还可以写3个数据
byteBuffer.put((byte) 3);
byteBuffer.put((byte) 4);
byteBuffer.put((byte) 5);
System.out.println(String.format("最终的情况,capacity容量:%s, position位置:%s, limit限制:%s", byteBuffer.capacity(),
byteBuffer.position(), byteBuffer.limit()));
// rewind() 重置position为0
// mark() 标记position的位置
// reset() 重置position为上次mark()标记的位置
}
}
打印的结果:
初始化:capacity容量:4, position位置:0, limit限制:4
写入3字节后,capacity容量:4, position位置:3, limit限制:4
#######开始读取
1
2
读取2字节数据后,capacity容量:4, position位置:2, limit限制:3
最终的情况,capacity容量:4, position位置:4, limit限制:4
从上面可知,与数组相比,数组写入或读取的时候,写到哪,读到哪,我们是不知道的,而buffer则可以方便的知道
ByteBuffer内存类型
ByteBuffer为性能关键型代码提供了直接内存(direct堆外)和非直接内存(heap堆)两种实现。
堆外内存获取的方式:ByteBuffer directByteBuffer=ByteBuffer.allocateDirect(noBytes);
堆内内存生成的是数组
堆外内存的好处:
- 进行网络IO或者文件IO时比heapBuffer少拷贝一次。(file/socket---OS memory---jvm heap)GC会移动对象内存,在写file或socket的过程中,JVM的实现中,会先把数据复制到堆外,再进行写入。
- 文件或网络读写的时候,比如java要写一个a,这个a有内存地址1,调用操作系统的api进行写入,写入的过程中把内存地址传递过去,java在操作此写入过程时,会先把数据从堆内存中复制一份到堆外去,复制到内存地址z,再进行写入。因为java中的垃圾回收机制,会移动对象内存,经过这么移动之后,堆内的a的地址很可能就发生了变化,变为地址2,这时候去地址1找a是找不到的。所以为了防止GC的这种后果,在JVM中会先复制一份到堆外。
- 因此,如果我们直接使用堆外内存,一开始就在堆外申请内存,就会少一次拷贝的过程。因为堆外内存不受GC的管理。GC不管理,堆外内存依然可以回收,下一条正好说的是这件事。
- GC范围之外,降低GC压力,但实现了自动管理。DirectByteBuffer中有一个Cleaner对象(PhantomReference,虚引用),Cleaner被GC前会执行clean方法,触发DirectByteBuffer中定义的回收函数Deallocator,清除堆外内存对象所管理的区域。DirectByteBuffer这个对象是受GC管理的,只是申请的内存不管理而已,定义了个方法,在回收DirectByteBuffer对象的时候,触发回收内存的函数。
建议:
- 性能确实可观的时候才去使用;分配给大型、长寿命;(网络传输、文件读写场景)
- 通过虚拟机参数MaxDirectMemorySize限制大小,防止耗尽整个机器的内存。堆之外的内存不受GC管理,很多监控工具没法监控。
修改上面代码,堆外缓冲区的写法:
public class DirectBufferDemo {
public static void main(String[] args) {
// 构建一个byte字节缓冲区,容量是4
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(4);
// 默认写入模式,查看三个重要的指标
System.out.println(String.format("初始化:capacity容量:%s, position位置:%s, limit限制:%s", byteBuffer.capacity(),
byteBuffer.position(), byteBuffer.limit()));
// 写入2字节的数据
byteBuffer.put((byte) 1);
byteBuffer.put((byte) 2);
byteBuffer.put((byte) 3);
// 再看数据
System.out.println(String.format("写入3字节后,capacity容量:%s, position位置:%s, limit限制:%s", byteBuffer.capacity(),
byteBuffer.position(), byteBuffer.limit()));
// 转换为读取模式(不调用flip方法,也是可以读取数据的,但是position记录读取的位置不对)
System.out.println("#######开始读取");
byteBuffer.flip();
byte a = byteBuffer.get();
System.out.println(a);
byte b = byteBuffer.get();
System.out.println(b);
System.out.println(String.format("读取2字节数据后,capacity容量:%s, position位置:%s, limit限制:%s", byteBuffer.capacity(),
byteBuffer.position(), byteBuffer.limit()));
// 继续写入3字节,此时读模式下,limit=3,position=2.继续写入只能覆盖写入一条数据
// clear()方法清除整个缓冲区。compact()方法仅清除已阅读的数据。转为写入模式
byteBuffer.compact();
byteBuffer.put((byte) 3);
byteBuffer.put((byte) 4);
byteBuffer.put((byte) 5);
System.out.println(String.format("最终的情况,capacity容量:%s, position位置:%s, limit限制:%s", byteBuffer.capacity(),
byteBuffer.position(), byteBuffer.limit()));
byteBuffer.array();
// rewind() 重置position为0
// mark() 标记position的位置
// reset() 重置position为上次mark()标记的位置
}
}
二、Channel通道
Buffer是给通道用的

上面是BIO,网络操作通过outputStream和inputStream两个对象来实现的,即Socket和IO的API组合使用,来实现网络数据的交互。需要io包和net包。

而在NIO中,提供了新的API,只需要使用nio包。
提供了channel,channel的API包含了UDP/TCP网络相关的操作和文件IO操作
channel可以同时建立网络连接并传输数据,BIO中需要socket和stream两组API,NIO合二为一
channel:
- FileChannel
- DataGramChannel
- SocketChannel
- ServerSocketChannel
和标准IO Stream操作的区别:
- 在一个通道内进行读取和写入,而stream通常是单向的(input或output)
- 可以非阻塞读取和写入通道,通道始终读取或写入缓冲区
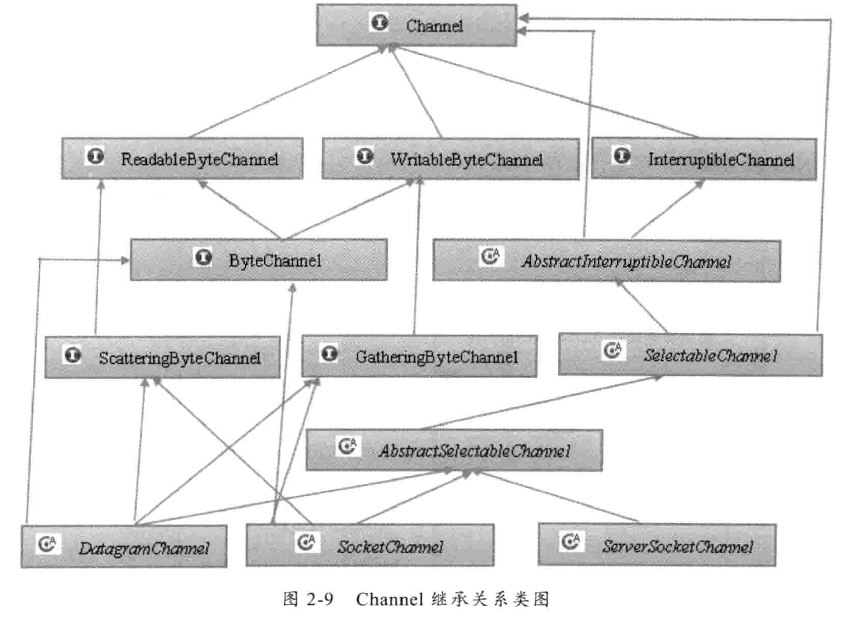
下面介绍API
1.SocketChannel
SocketChannel拥有建立TCP网络连接,类似java.net.Socket。有两种创建socketChannel的形式:
- 客户端的。客户端主动发起和服务器的连接
- 服务端的。服务端获取的新连接
// 客户端主动发起连接的方式
SocketChannel socketChannel = SocketChannel.open();
socketChannel.configureBlocking(false); // 设置为非阻塞模式
socketChannel.connect(new InetSocketAddress("http://163.com", 80));
socketChannel.write(buffer); // 发送请求数据-向通道写入数据
int bytesRead = socketChannel.read(buffer); // 读取服务端返回-读取缓存区的数据
socketChannel.close(); // 关闭连接
channel里传入的是Buffer
write写:write()在尚未写入任何内容时就可能返回了。需要在循环中调用write()。
read读:read()方法可能直接返回而根本不读取任何数据,根据返回的int值判断读取了多少字节。
2.ServerSocketChannel
可以建通新建的TCP连接通道,类似ServerSocket。
// 创建网络服务端
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
serverSocketChannel.configureBlocking(false); // 设置为非阻塞模式
serverSocketChannel.socket().bind(new InetSocketAddress(8080)); // 绑定端口
while (true) {
SocketChannel socketChannel = serverSocketChannel.accept(); // 获取新tcp连接通道
if (socketChannl != null) {
// tcp请求 读取/响应
}
}
serverSocketChannel.accept():如果该通道处于非阻塞模式,那么如果没有挂起的连接,该方法将立即返回null。必须检查返回的SocketChannel是否为null。
server
/**
* 直接基于非阻塞的写法
*/
public class NIOServer { public static void main(String[] args) throws Exception {
// 创建网络服务端
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
serverSocketChannel.configureBlocking(false); // 设置为非阻塞模式
serverSocketChannel.socket().bind(new InetSocketAddress(8080)); // 绑定端口
System.out.println("启动成功");
while (true) {
SocketChannel socketChannel = serverSocketChannel.accept(); // 获取新tcp连接通道
// tcp请求 读取/响应
if (socketChannel != null) {
System.out.println("收到新连接 : " + socketChannel.getRemoteAddress());
socketChannel.configureBlocking(false); // 默认是阻塞的,一定要设置为非阻塞
try {
ByteBuffer requestBuffer = ByteBuffer.allocate(1024);
while (socketChannel.isOpen() && socketChannel.read(requestBuffer) != -1) {
// 长连接情况下,需要手动判断数据有没有读取结束 (此处做一个简单的判断: 超过0字节就认为请求结束了)
if (requestBuffer.position() > 0)
break;
}
if (requestBuffer.position() == 0)
continue; // 如果没数据了, 则不继续后面的处理
requestBuffer.flip();
byte[] content = new byte[requestBuffer.limit()];
requestBuffer.get(content);
System.out.println(new String(content));
System.out.println("收到数据,来自:" + socketChannel.getRemoteAddress()); // 响应结果 200
String response = "HTTP/1.1 200 OK\r\n" + "Content-Length: 11\r\n\r\n" + "Hello World";
ByteBuffer buffer = ByteBuffer.wrap(response.getBytes());
while (buffer.hasRemaining()) {
socketChannel.write(buffer);// 非阻塞
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
// 用到了非阻塞的API, 在设计上,和BIO可以有很大的不同.继续改进
}
}
client
public class NIOClient {
public static void main(String[] args) throws Exception {
SocketChannel socketChannel = SocketChannel.open();
socketChannel.configureBlocking(false);
socketChannel.connect(new InetSocketAddress("127.0.0.1", 8080));
while (!socketChannel.finishConnect()) {
// 没连接上,则一直等待
Thread.yield();
}
Scanner scanner = new Scanner(System.in);
System.out.println("请输入:");
// 发送内容
String msg = scanner.nextLine();
ByteBuffer buffer = ByteBuffer.wrap(msg.getBytes());
while (buffer.hasRemaining()) {
socketChannel.write(buffer);
}
// 读取响应
System.out.println("收到服务端响应:");
ByteBuffer requestBuffer = ByteBuffer.allocate(1024);
while (socketChannel.isOpen() && socketChannel.read(requestBuffer) != -1) {
// 长连接情况下,需要手动判断数据有没有读取结束 (此处做一个简单的判断: 超过0字节就认为请求结束了)
if (requestBuffer.position() > 0)
break;
}
requestBuffer.flip();
byte[] content = new byte[requestBuffer.limit()];
requestBuffer.get(content);
System.out.println(new String(content));
scanner.close();
socketChannel.close();
}
}
启动两个客户端,只能收到一个新连接

由于server使用while循环不断判断,只有第一个客户端输入后,才能与第二个客户端建立连接,和之前BIO出现了一样的现象,当然BIO那里是因为阻塞,这里是因为while

改进
BIO当时通过多线程进行解决的,我们这里是非阻塞的,没必要使用多线程
升级一
/**
* 直接基于非阻塞的写法,一个线程处理轮询所有请求
*/
public class NIOServer1 { /**
* 已经建立连接的集合
*/
private static ArrayList<SocketChannel> channels = new ArrayList<>(); public static void main(String[] args) throws Exception {
// 创建网络服务端
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
serverSocketChannel.configureBlocking(false); // 设置为非阻塞模式
serverSocketChannel.socket().bind(new InetSocketAddress(8080)); // 绑定端口
System.out.println("启动成功");
while (true) {
SocketChannel socketChannel = serverSocketChannel.accept(); // 获取新tcp连接通道
// tcp请求 读取/响应
if (socketChannel != null) {
System.out.println("收到新连接 : " + socketChannel.getRemoteAddress());
socketChannel.configureBlocking(false); // 默认是阻塞的,一定要设置为非阻塞
channels.add(socketChannel);
} else {
// 没有新连接的情况下,就去处理现有连接的数据,处理完的就删除掉
Iterator<SocketChannel> iterator = channels.iterator();
while (iterator.hasNext()) {
SocketChannel ch = iterator.next();
try {
ByteBuffer requestBuffer = ByteBuffer.allocate(1024);
// 如果通道里没有数据,就没必要再继续下面的循环读取了
if (ch.read(requestBuffer) == 0) {
// 等于0,代表这个通道没有数据需要处理,那就待会再处理
continue;
}
while (ch.isOpen() && ch.read(requestBuffer) != -1) {
// 长连接情况下,需要手动判断数据有没有读取结束 (此处做一个简单的判断: 超过0字节就认为请求结束了)
if (requestBuffer.position() > 0)
break;
}
if (requestBuffer.position() == 0)
continue; // 如果没数据了, 则不继续后面的处理
requestBuffer.flip();
byte[] content = new byte[requestBuffer.limit()];
requestBuffer.get(content);
System.out.println(new String(content));
System.out.println("收到数据,来自:" + ch.getRemoteAddress()); // 响应结果 200
String response = "HTTP/1.1 200 OK\r\n" + "Content-Length: 11\r\n\r\n" + "Hello World";
ByteBuffer buffer = ByteBuffer.wrap(response.getBytes());
while (buffer.hasRemaining()) {
ch.write(buffer);
}
iterator.remove();
} catch (IOException e) {
e.printStackTrace();
iterator.remove();
}
}
}
}
// 用到了非阻塞的API, 再设计上,和BIO可以有很大的不同
// 问题: 轮询通道的方式,低效,浪费CPU
}
}
三、Selector
循环检查不高效, NIO提供了更好的方法。
多路复用器Selector是一个Java NIO组件,是Java NIO编程的基础。可以检查一个或多个NIO通道,并确定哪些通道已经准备好进行读取或写入。实现单个线程可以管理多个通道,从而管理多个网络连接。
Selector会不断地轮询注册其上的Channel,如果某个Channel上面有新的TCP连接接入、读和写事件,这个Channel就处于就绪状态,会被Selector轮询出来,然后通过SelectorKey可以获取就绪Channel的集合,进行后续I/O操作。

实现一个线程处理多个通道的核心概念理解:事件驱动机制。
不是监听channel
非阻塞的网络通道下,开发者通过Selector注册对于通道感兴趣的事件类型,线程通过监听事件来触发相应的代码执行,比如accept、read、write等事件。(拓展:更底层是操作系统的多路复用机制)

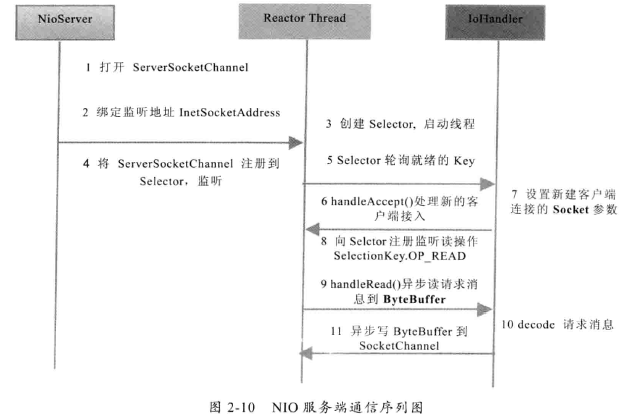
改进二
/**
* 结合Selector实现的非阻塞服务端(放弃对channel的轮询,借助消息通知机制)
*/
public class NIOServer2 { public static void main(String[] args) throws Exception {
// 1. 创建网络服务端ServerSocketChannel
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
serverSocketChannel.configureBlocking(false); // 设置为非阻塞模式 // 2. 构建一个Selector选择器,并且将channel注册上去
Selector selector = Selector.open();
SelectionKey selectionKey = serverSocketChannel.register(selector, 0, serverSocketChannel);// 将serverSocketChannel注册到selector
selectionKey.interestOps(SelectionKey.OP_ACCEPT); // 对serverSocketChannel上面的accept事件感兴趣(serverSocketChannel只能支持accept操作) // 3. 绑定端口
serverSocketChannel.socket().bind(new InetSocketAddress(8080)); System.out.println("启动成功"); while (true) {
// 不再轮询通道,改用下面轮询事件的方式.select方法有阻塞效果,直到有事件通知才会有返回
selector.select();
// 获取事件
Set<SelectionKey> selectionKeys = selector.selectedKeys();
// 遍历查询结果e
Iterator<SelectionKey> iter = selectionKeys.iterator();
while (iter.hasNext()) {
// 被封装的查询结果
SelectionKey key = iter.next();
iter.remove();
// 关注 Read 和 Accept两个事件
if (key.isAcceptable()) {
ServerSocketChannel server = (ServerSocketChannel) key.attachment();
// 将拿到的客户端连接通道,注册到selector上面
SocketChannel clientSocketChannel = server.accept(); // mainReactor 轮询accept
clientSocketChannel.configureBlocking(false);
clientSocketChannel.register(selector, SelectionKey.OP_READ, clientSocketChannel);
System.out.println("收到新连接 : " + clientSocketChannel.getRemoteAddress());
} if (key.isReadable()) {
SocketChannel socketChannel = (SocketChannel) key.attachment();
try {
ByteBuffer requestBuffer = ByteBuffer.allocate(1024);
while (socketChannel.isOpen() && socketChannel.read(requestBuffer) != -1) {
// 长连接情况下,需要手动判断数据有没有读取结束 (此处做一个简单的判断: 超过0字节就认为请求结束了)
if (requestBuffer.position() > 0) break;
}
if(requestBuffer.position() == 0) continue; // 如果没数据了, 则不继续后面的处理
requestBuffer.flip();
byte[] content = new byte[requestBuffer.limit()];
requestBuffer.get(content);
System.out.println(new String(content));
System.out.println("收到数据,来自:" + socketChannel.getRemoteAddress());
// TODO 业务操作 数据库 接口调用等等 // 响应结果 200
String response = "HTTP/1.1 200 OK\r\n" +
"Content-Length: 11\r\n\r\n" +
"Hello World";
ByteBuffer buffer = ByteBuffer.wrap(response.getBytes());
while (buffer.hasRemaining()) {
socketChannel.write(buffer);
}
} catch (IOException e) {
// e.printStackTrace();
key.cancel(); // 取消事件订阅
}
}
}
selector.selectNow();
}
// 问题: 此处一个selector监听所有事件,一个线程处理所有请求事件. 会成为瓶颈! 要有多线程的运用
}
}
NIO对比BIO


如果程序需要支撑大量的连接,使用NIO是最好的方式。
Tomcat8中,已经完全移除了BIO相关的网络处理代码,默认采用NIO进行网络处理。
四、NIO与多线程结合的改进方案
上述的NIO是单线程的,会有性能瓶颈,且无法利用多核的优势。
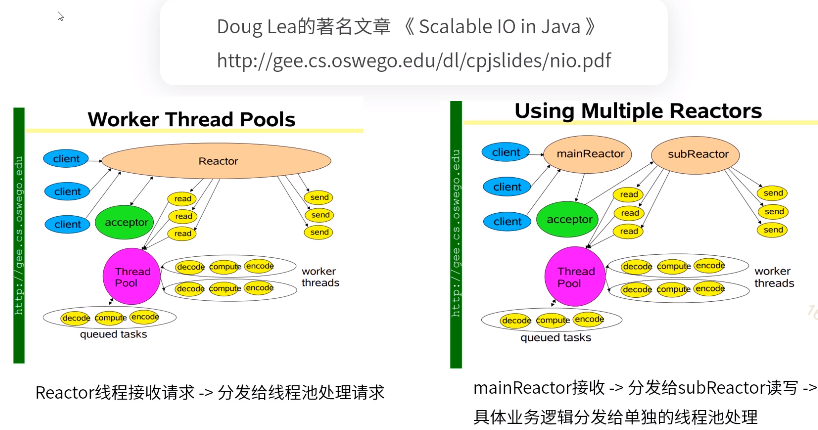
左:线程池,单Reactor。两种线程,一是Reactor线程,负责网络数据的接收和网络连接的处理。接收的数据进行什么处理,由单独的线程池进行处理。将底层的基础网络处理和应用层的逻辑处理进行了分离,两种线程进行处理。
右:多Reactor。将Reactor分为多种,处理网络连接的有mainReactor去做,处理数据读取由另外的subReactor做,其他和单Reactor相同。
/**
* NIO selector 多路复用reactor线程模型
*/
public class NIOServerV3 {
/** 处理业务操作的线程 */
private static ExecutorService workPool = Executors.newCachedThreadPool(); /**
* 封装了selector.select()等事件轮询的代码
*/
abstract class ReactorThread extends Thread { Selector selector;
LinkedBlockingQueue<Runnable> taskQueue = new LinkedBlockingQueue<>(); /**
* Selector监听到有事件后,调用这个方法
*/
public abstract void handler(SelectableChannel channel) throws Exception; private ReactorThread() throws IOException {
selector = Selector.open();
} volatile boolean running = false; @Override
public void run() {
// 轮询Selector事件
while (running) {
try {
// 执行队列中的任务
Runnable task;
while ((task = taskQueue.poll()) != null) {
task.run();
}
selector.select(1000); // 获取查询结果
Set<SelectionKey> selected = selector.selectedKeys();
// 遍历查询结果
Iterator<SelectionKey> iter = selected.iterator();
while (iter.hasNext()) {
// 被封装的查询结果
SelectionKey key = iter.next();
iter.remove();
int readyOps = key.readyOps();
// 关注 Read 和 Accept两个事件
if ((readyOps & (SelectionKey.OP_READ | SelectionKey.OP_ACCEPT)) != 0 || readyOps == 0) {
try {
SelectableChannel channel = (SelectableChannel) key.attachment();
channel.configureBlocking(false);
handler(channel);
if (!channel.isOpen()) {
key.cancel(); // 如果关闭了,就取消这个KEY的订阅
}
} catch (Exception ex) {
key.cancel(); // 如果有异常,就取消这个KEY的订阅
}
}
}
selector.selectNow();
} catch (IOException e) {
e.printStackTrace();
}
}
} private SelectionKey register(SelectableChannel channel) throws Exception {
// 为什么register要以任务提交的形式,让reactor线程去处理?
// 因为线程在执行channel注册到selector的过程中,会和调用selector.select()方法的线程争用同一把锁
// 而select()方法实在eventLoop中通过while循环调用的,争抢的可能性很高,为了让register能更快的执行,就放到同一个线程来处理
FutureTask<SelectionKey> futureTask = new FutureTask<>(() -> channel.register(selector, 0, channel));
taskQueue.add(futureTask);
return futureTask.get();
} private void doStart() {
if (!running) {
running = true;
start();
}
}
} private ServerSocketChannel serverSocketChannel;
// 1、创建多个线程 - accept处理reactor线程 (accept线程)
private ReactorThread[] mainReactorThreads = new ReactorThread[1];
// 2、创建多个线程 - io处理reactor线程 (I/O线程)
private ReactorThread[] subReactorThreads = new ReactorThread[8]; /**
* 初始化线程组
*/
private void newGroup() throws IOException {
// 创建IO线程,负责处理客户端连接以后socketChannel的IO读写
for (int i = 0; i < subReactorThreads.length; i++) {
subReactorThreads[i] = new ReactorThread() {
@Override
public void handler(SelectableChannel channel) throws IOException {
// work线程只负责处理IO处理,不处理accept事件
SocketChannel ch = (SocketChannel) channel;
ByteBuffer requestBuffer = ByteBuffer.allocate(1024);
while (ch.isOpen() && ch.read(requestBuffer) != -1) {
// 长连接情况下,需要手动判断数据有没有读取结束 (此处做一个简单的判断: 超过0字节就认为请求结束了)
if (requestBuffer.position() > 0) break;
}
if (requestBuffer.position() == 0) return; // 如果没数据了, 则不继续后面的处理
requestBuffer.flip();
byte[] content = new byte[requestBuffer.limit()];
requestBuffer.get(content);
System.out.println(new String(content));
System.out.println(Thread.currentThread().getName() + "收到数据,来自:" + ch.getRemoteAddress()); // TODO 业务操作 数据库、接口...
workPool.submit(() -> {
}); // 响应结果 200
String response = "HTTP/1.1 200 OK\r\n" +
"Content-Length: 11\r\n\r\n" +
"Hello World";
ByteBuffer buffer = ByteBuffer.wrap(response.getBytes());
while (buffer.hasRemaining()) {
ch.write(buffer);
}
}
};
} // 创建mainReactor线程, 只负责处理serverSocketChannel
for (int i = 0; i < mainReactorThreads.length; i++) {
mainReactorThreads[i] = new ReactorThread() {
AtomicInteger incr = new AtomicInteger(0); @Override
public void handler(SelectableChannel channel) throws Exception {
// 只做请求分发,不做具体的数据读取
ServerSocketChannel ch = (ServerSocketChannel) channel;
SocketChannel socketChannel = ch.accept();
socketChannel.configureBlocking(false);
// 收到连接建立的通知之后,分发给I/O线程继续去读取数据
int index = incr.getAndIncrement() % subReactorThreads.length;
ReactorThread workEventLoop = subReactorThreads[index];
workEventLoop.doStart();
SelectionKey selectionKey = workEventLoop.register(socketChannel);
selectionKey.interestOps(SelectionKey.OP_READ);
System.out.println(Thread.currentThread().getName() + "收到新连接 : " + socketChannel.getRemoteAddress());
}
};
} } /**
* 初始化channel,并且绑定一个eventLoop线程
*
* @throws IOException IO异常
*/
private void initAndRegister() throws Exception {
// 1、 创建ServerSocketChannel
serverSocketChannel = ServerSocketChannel.open();
serverSocketChannel.configureBlocking(false);
// 2、 将serverSocketChannel注册到selector
int index = new Random().nextInt(mainReactorThreads.length);
mainReactorThreads[index].doStart();
SelectionKey selectionKey = mainReactorThreads[index].register(serverSocketChannel);
selectionKey.interestOps(SelectionKey.OP_ACCEPT);
} /**
* 绑定端口
*
* @throws IOException IO异常
*/
private void bind() throws IOException {
// 1、 正式绑定端口,对外服务
serverSocketChannel.bind(new InetSocketAddress(8080));
System.out.println("启动完成,端口8080");
} public static void main(String[] args) throws Exception {
NIOServerV3 nioServerV3 = new NIOServerV3();
nioServerV3.newGroup(); // 1、 创建main和sub两组线程
nioServerV3.initAndRegister(); // 2、 创建serverSocketChannel,注册到mainReactor线程上的selector上
nioServerV3.bind(); // 3、 为serverSocketChannel绑定端口
}
}
Java高并发网络编程(三)NIO的更多相关文章
- Java高并发网络编程(四)Netty
在网络应用开发的过程中,直接使用JDK提供的NIO的API,比较繁琐,而且想要进行性能提升,还需要结合多线程技术. 由于网络编程本身的复杂性,以及JDK API开发的使用难度较高,所以在开源社区中,涌 ...
- Java高并发网络编程(一)
一.OSI网络七层模型 因特网是一个极为复杂的网络,分层有助于我们对网络的理解 .分层也是一种标准,为了使不同厂商的计算机能够互相通信,以便在更大范围内建立计算机网络,有必要建立一个国际范围的网络体系 ...
- Java高并发网络编程(五)Netty应用
推送系统 一.系统设计 二.拆包和粘包 粘包.拆包表现形式 现在假设客户端向服务端连续发送了两个数据包,用packet1和packet2来表示,那么服务端收到的数据可以分为三种,现列举如下: 第一种情 ...
- Java高并发网络编程(二)BIO
一.阻塞 服务器端 public class BIOServer { public static void main(String[] args) throws Exception { ServerS ...
- Linux下高并发网络编程
Linux下高并发网络编程 1.修改用户进程可打开文件数限制 在Linux平台上,无论编写客户端程序还是服务端程序,在进行高并发TCP连接处理时, 最高的并发数量都要受到系统对用户单一进程同时可打 ...
- 从菜鸟到大神:Java高并发核心编程(连载视频)
任何事情是有套路的,学习是如此, Java的学习,更是如此. 本文,为大家揭示 Java学习的套路 背景 Java高并发.分布式的中间件非常多,网上也有很多组件的源码视频.原理视频,汗牛塞屋了. 作为 ...
- Linux高并发网络编程开发——10-Linux系统编程-第10天(网络编程基础-socket)
在学习Linux高并发网络编程开发总结了笔记,并分享出来.有问题请及时联系博主:Alliswell_WP,转载请注明出处. 10-Linux系统编程-第10天(网络编程基础-socket) 在学习Li ...
- Java后端进阶-网络编程(NIO/BIO)
Socket编程 BIO网络编程 BIO Server package com.study.hc.net.bio; import java.io.BufferedReader; import java ...
- Java IO、网络编程、NIO、Netty、Hessian、RPC、RMI的学习路线
好久没看Java IO这块的内容,感觉都快忘得差不多了.平成编程也没有设计到太多的Java基础知识,所以这里希望可以抽点时间回顾一下,让艾宾浩斯记忆曲线不要下降的太快. 回顾这个主要还是以总结为主,能 ...
随机推荐
- 错误描述:fatal error C1010: 在查找预编译头时遇到意外的文件结尾。是否忘记了向源中添加“#include "stdafx.h"”?(转)
错误分析: 此错误发生的原因是编译器在寻找预编译指示头文件(默认#include "stdafx.h")时,文件未预期结束.没有找到预编译指示信息的头文件"stdafx. ...
- 理解Java主函数中的"String[] args"
public class Understand_String_args { public static void main(String[] args) { System.out.printf(&qu ...
- docker 运行springboot jar包
1.将jar包移至自定义的/usr/jar目录下; 2.在/usr/jar目录下创建Dockerfile文件 文件如下: #FROM命令定义构建镜像的基础镜像,该条必须是dockerfile的首个命令 ...
- 学习java web中的listener
web.xml里的顺序为:context-param->listener->filter->servlet 监听器是需要新建一个类,然后按监听的对象继承:ServletContext ...
- 工程师技术(五):Shell脚本的编写及测试、重定向输出的应用、使用特殊变量、编写一个判断脚本、编写一个批量添加用户脚本
一.Shell脚本的编写及测 目标: 本例要求两个简单的Shell脚本程序,任务目标如下: 1> 编写一个面世问候 /root/helloworld.sh 脚本,执行后显示出一段话“Hello ...
- delphi 运行时提升软件到管理员权限
//以管理员身份运行procedure RunAsAdmin(hWnd: HWND; aFile: string; aParameters: string);varsei: TShellExecute ...
- 经典的MySQL Duplicate entry报错注入
SQL注射取数据的方式有多种: 利用union select查询直接在页面上返回数据,这种最为常见,一个前提是攻击者能够构造闭合的查询. Oracle中利用监听UTL_HTTP.request发起的H ...
- client-go获取k8s集群内部连接,实现deployment的增删改查
一开始写了一个client-java版本的,但是java放在k8s集群上跑需要装jvm而且java的包比较大,client-go版本更适合主机端,下面是整个实现 说明:k8s官方维护的客户端库只有go ...
- 详解代理自动配置 PAC
转自知乎 最近一直在做跨域中华局域网的工作,了解了很多代理知识和基础概念,很零散,也很细碎.希望通过一段时间的学习,能够自由地穿梭在国际互联网和中华局域网之间.后续会写一系列文章记录我了解到的知识点, ...
- 基于nodejs的一个实时markdown转html工具小程序
1.版本一 - 1.1`npm install marked --save` 安装markdwon转html的包.- 1.2 使用watchFile监视 markdown文件 /** * Create ...