python 数据分析 Numpy(Numerical Python Basic)
# 导入numpy 模块
1 import numpy as np a = np.random.random((2,4))
a
Out[5]:
array([[0.20974732, 0.73822026, 0.82760722, 0.050551 ],
[0.77337155, 0.06521922, 0.55524187, 0.59209907]]) # 求矩阵所有数据的和,最小值,最大值
np.sum(a)
Out[7]: 3.812057513268513
np.min(a)
Out[8]: 0.05055099733013646
np.max(a)
Out[9]: 0.8276072194278252
print("a=",a)
a= [[0.20974732 0.73822026 0.82760722 0.050551 ]
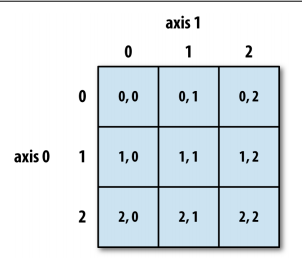
[0.77337155 0.06521922 0.55524187 0.59209907]] # axis=0 代表列, axis=1代表行
print("min",np.min(a))
min 0.05055099733013646
#求每列当中的最小值
print("lmin:",np.min(a,axis=0))
lmin: [0.20974732 0.06521922 0.55524187 0.050551 ]
print("lmin:",np.min(a,axis=1))
lmin: [0.050551 0.06521922]
print("sum:",np.sum(a,axis=1))
sum: [1.8261258 1.98593171]
# reshape 数据, 3行4列
A = np.arange(2,14).reshape(3,4)
A
Out[16]:
array([[ 2, 3, 4, 5],
[ 6, 7, 8, 9],
[10, 11, 12, 13]])
# ndarray中最小值,最大值的序号
print(np.argmin(A))
0
print(np.argmax(A))
11
print(np.mean(A))
7.5
print(np.average(A))
7.5
print(A.mean())
7.5
# cumsum 迭代相加
A
Out[24]:
array([[ 2, 3, 4, 5],
[ 6, 7, 8, 9],
[10, 11, 12, 13]])
print(A.cumsum())
[ 2 5 9 14 20 27 35 44 54 65 77 90]
A
Out[27]:
array([[ 2, 3, 4, 5],
[ 6, 7, 8, 9],
[10, 11, 12, 13]])
# clip(a, a_min, a_max) 将ndarray中的数据进行判断,小于a_min的值都赋值为a_min, 大于a_max的都赋值a_max,在这之间的值不变。
print(np.clip(A,5,8))
[[5 5 5 5]
[6 7 8 8]
[8 8 8 8]]
# 判断ndarray阶数,几维向量
A.ndim
Out[30]: 2
A
Out[31]:
array([[ 2, 3, 4, 5],
[ 6, 7, 8, 9],
[10, 11, 12, 13]])
A.ndim
Out[32]: 2
a
Out[33]:
array([[0.20974732, 0.73822026, 0.82760722, 0.050551 ],
[0.77337155, 0.06521922, 0.55524187, 0.59209907]])
a.ndim
Out[34]: 2
A
Out[35]:
array([[ 2, 3, 4, 5],
[ 6, 7, 8, 9],
[10, 11, 12, 13]])
names = np.array(['Bob', 'Joe', 'Will', 'Bob', 'Will', 'Joe', 'Joe'])
names
Out[37]: array(['Bob', 'Joe', 'Will', 'Bob', 'Will', 'Joe', 'Joe'], dtype='<U4')
# 中间出了一些错误调用random的时候需要俩括号,(7,4)作为一个tuple变量传入random
data = np.random.random((7,4))
data
Out[43]:
array([[0.89497078, 0.61138776, 0.69472434, 0.27105599],
[0.23114404, 0.1423609 , 0.06016109, 0.56939826],
[0.84711124, 0.00776355, 0.24954255, 0.96157959],
[0.34937375, 0.6013533 , 0.66481223, 0.18210067],
[0.82706912, 0.64240956, 0.95575726, 0.40232292],
[0.57225917, 0.0958916 , 0.969577 , 0.47824937],
[0.52181664, 0.59962513, 0.19175081, 0.92442871]])
# 注意random 和 randn的区别,numpy.random.randn(d0, d1, …, dn)是从标准正态分布中返回一个或多个样本值,numpy.random.rand(d0, d1, …, dn)的随机样本位于[0, 1)中。
data = np.random.randn(7,4)
data
Out[45]:
array([[-0.41118699, -0.55989348, -1.03263407, 0.06053961],
[ 0.91135901, -0.90451748, -1.12549659, 1.69668984],
[ 0.54079498, 1.23213331, 0.86787185, 2.33957776],
[-0.56646272, 0.87848794, -1.29842767, 0.65293394],
[ 0.96861489, 1.5155331 , 0.328894 , 0.25768648],
[-0.53991665, 0.3098865 , 2.18921935, 0.83933456],
[-1.21083646, -0.30640711, 0.36142124, 0.9664484 ]]) names = np.array(['Bob', 'Joe', 'Will', 'Bob', 'Will', 'Joe', 'Joe'])
# 通过判断重新生成array
names == 'Bob'
Out[50]: array([ True, False, False, True, False, False, False])
data
Out[51]:
array([[-0.41118699, -0.55989348, -1.03263407, 0.06053961],
[ 0.91135901, -0.90451748, -1.12549659, 1.69668984],
[ 0.54079498, 1.23213331, 0.86787185, 2.33957776],
[-0.56646272, 0.87848794, -1.29842767, 0.65293394],
[ 0.96861489, 1.5155331 , 0.328894 , 0.25768648],
[-0.53991665, 0.3098865 , 2.18921935, 0.83933456],
[-1.21083646, -0.30640711, 0.36142124, 0.9664484 ]])
#高级用法,根据names判断生成的array再进行一次迭代选择, 和切片还有区别
data[names == 'Bob']
Out[52]:
array([[-0.41118699, -0.55989348, -1.03263407, 0.06053961],
[-0.56646272, 0.87848794, -1.29842767, 0.65293394]])
# 切片的选择
data[names == 'Bob', 2:]
Out[53]:
array([[-1.03263407, 0.06053961],
[-1.29842767, 0.65293394]])
data[names == 'Bob', 3]
Out[54]: array([0.06053961, 0.65293394])
names
Out[55]: array(['Bob', 'Joe', 'Will', 'Bob', 'Will', 'Joe', 'Joe'], dtype='<U4')
names == 'Joe'
Out[56]: array([False, True, False, False, False, True, True])
names != 'Bob'
Out[57]: array([False, True, True, False, True, True, True]) #这一例程没成功,待调查。。。
data[-(names == 'Bob')]
Traceback (most recent call last):
File "E:\Software\Software\Anaconda2.5.01\envs\intro_dl\lib\site-packages\IPython\core\interactiveshell.py", line 2963, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "<ipython-input-58-1242c1c7d3ed>", line 1, in <module>
data[-(names == 'Bob')]
TypeError: The numpy boolean negative, the `-` operator, is not supported, use the `~` operator or the logical_not function instead.
data
Out[59]:
array([[-0.41118699, -0.55989348, -1.03263407, 0.06053961],
[ 0.91135901, -0.90451748, -1.12549659, 1.69668984],
[ 0.54079498, 1.23213331, 0.86787185, 2.33957776],
[-0.56646272, 0.87848794, -1.29842767, 0.65293394],
[ 0.96861489, 1.5155331 , 0.328894 , 0.25768648],
[-0.53991665, 0.3098865 , 2.18921935, 0.83933456],
[-1.21083646, -0.30640711, 0.36142124, 0.9664484 ]])
data[-(names == 'Bob')]
Traceback (most recent call last):
File "E:\Software\Software\Anaconda2.5.01\envs\intro_dl\lib\site-packages\IPython\core\interactiveshell.py", line 2963, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "<ipython-input-60-1242c1c7d3ed>", line 1, in <module>
data[-(names == 'Bob')]
TypeError: The numpy boolean negative, the `-` operator, is not supported, use the `~` operator or the logical_not function instead.
data
Out[61]:
array([[-0.41118699, -0.55989348, -1.03263407, 0.06053961],
[ 0.91135901, -0.90451748, -1.12549659, 1.69668984],
[ 0.54079498, 1.23213331, 0.86787185, 2.33957776],
[-0.56646272, 0.87848794, -1.29842767, 0.65293394],
[ 0.96861489, 1.5155331 , 0.328894 , 0.25768648],
[-0.53991665, 0.3098865 , 2.18921935, 0.83933456],
[-1.21083646, -0.30640711, 0.36142124, 0.9664484 ]])
-data
Out[62]:
array([[ 0.41118699, 0.55989348, 1.03263407, -0.06053961],
[-0.91135901, 0.90451748, 1.12549659, -1.69668984],
[-0.54079498, -1.23213331, -0.86787185, -2.33957776],
[ 0.56646272, -0.87848794, 1.29842767, -0.65293394],
[-0.96861489, -1.5155331 , -0.328894 , -0.25768648],
[ 0.53991665, -0.3098865 , -2.18921935, -0.83933456],
[ 1.21083646, 0.30640711, -0.36142124, -0.9664484 ]])
-data[names == 'Bob']
Out[63]:
array([[ 0.41118699, 0.55989348, 1.03263407, -0.06053961],
[ 0.56646272, -0.87848794, 1.29842767, -0.65293394]])
data[names != 'Bob']
Out[64]:
array([[ 0.91135901, -0.90451748, -1.12549659, 1.69668984],
[ 0.54079498, 1.23213331, 0.86787185, 2.33957776],
[ 0.96861489, 1.5155331 , 0.328894 , 0.25768648],
[-0.53991665, 0.3098865 , 2.18921935, 0.83933456],
[-1.21083646, -0.30640711, 0.36142124, 0.9664484 ]])
data[-names != 'Bob']
Traceback (most recent call last):
File "E:\Software\Software\Anaconda2.5.01\envs\intro_dl\lib\site-packages\IPython\core\interactiveshell.py", line 2963, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "<ipython-input-65-5976a92eae9b>", line 1, in <module>
data[-names != 'Bob']
TypeError: ufunc 'negative' did not contain a loop with signature matching types dtype('<U4') dtype('<U4') #组合选择
msk = (names == 'Bob') | (names == 'Will')
msk
Out[67]: array([ True, False, True, True, True, False, False])
data[msk]
Out[68]:
array([[-0.41118699, -0.55989348, -1.03263407, 0.06053961],
[ 0.54079498, 1.23213331, 0.86787185, 2.33957776],
[-0.56646272, 0.87848794, -1.29842767, 0.65293394],
[ 0.96861489, 1.5155331 , 0.328894 , 0.25768648]]) #根据判断冲洗赋值
data[data < 0] = 0
data
Out[70]:
array([[0. , 0. , 0. , 0.06053961],
[0.91135901, 0. , 0. , 1.69668984],
[0.54079498, 1.23213331, 0.86787185, 2.33957776],
[0. , 0.87848794, 0. , 0.65293394],
[0.96861489, 1.5155331 , 0.328894 , 0.25768648],
[0. , 0.3098865 , 2.18921935, 0.83933456],
[0. , 0. , 0.36142124, 0.9664484 ]])
arr = np.empty((8,4))
arr
Out[72]:
array([[6.23042070e-307, 4.22795269e-307, 2.04722549e-306,
6.23054972e-307],
[1.78019761e-306, 9.34608432e-307, 7.56599807e-307,
8.90104239e-307],
[1.16820282e-307, 6.23037317e-307, 1.69121639e-306,
1.78020848e-306],
[8.90094053e-307, 1.11261027e-306, 1.11261502e-306,
1.42410839e-306],
[7.56597770e-307, 6.23059726e-307, 1.42419530e-306,
1.37961302e-306],
[1.29060531e-306, 1.11261570e-306, 7.56602523e-307,
9.34609790e-307],
[8.34451504e-308, 1.22383391e-307, 1.33511562e-306,
8.90103560e-307],
[1.42410974e-306, 1.00132228e-307, 1.33511969e-306,
2.18568966e-312]])
for i in range(8):
a[i] = i Traceback (most recent call last):
File "E:\Software\Software\Anaconda2.5.01\envs\intro_dl\lib\site-packages\IPython\core\interactiveshell.py", line 2963, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "<ipython-input-73-077106ef35e3>", line 2, in <module>
a[i] = i
IndexError: index 2 is out of bounds for axis 0 with size 2 # arr[i]是行的地址,给行地址指针赋值相当于改写了整块内存的值, 整行赋值, 不知道理解的对不对
for i in range(8):
arr[i] = i arr
Out[75]:
array([[0., 0., 0., 0.],
[1., 1., 1., 1.],
[2., 2., 2., 2.],
[3., 3., 3., 3.],
[4., 4., 4., 4.],
[5., 5., 5., 5.],
[6., 6., 6., 6.],
[7., 7., 7., 7.]])
arr[0] = 9
arr
Out[77]:
array([[9., 9., 9., 9.],
[1., 1., 1., 1.],
[2., 2., 2., 2.],
[3., 3., 3., 3.],
[4., 4., 4., 4.],
[5., 5., 5., 5.],
[6., 6., 6., 6.],
[7., 7., 7., 7.]])
arr[[4,3,0,6]]
Out[78]:
array([[4., 4., 4., 4.],
[3., 3., 3., 3.],
[9., 9., 9., 9.],
[6., 6., 6., 6.]])
arr = np.arange(15).reshape((3,5))
arr
Out[80]:
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]]) # .T转置矩阵
arr.T
Out[81]:
array([[ 0, 5, 10],
[ 1, 6, 11],
[ 2, 7, 12],
[ 3, 8, 13],
[ 4, 9, 14]]) #np.dot 矩阵相乘
np.dot(arr.T, arr)
Out[82]:
array([[125, 140, 155, 170, 185],
[140, 158, 176, 194, 212],
[155, 176, 197, 218, 239],
[170, 194, 218, 242, 266],
[185, 212, 239, 266, 293]])
arr
Out[83]:
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
arr.T
Out[84]:
array([[ 0, 5, 10],
[ 1, 6, 11],
[ 2, 7, 12],
[ 3, 8, 13],
[ 4, 9, 14]])
np.dot(arr.T, arr)
Out[85]:
array([[125, 140, 155, 170, 185],
[140, 158, 176, 194, 212],
[155, 176, 197, 218, 239],
[170, 194, 218, 242, 266],
[185, 212, 239, 266, 293]])
np.dot(arr, arr.T)
Out[86]:
array([[ 30, 80, 130],
[ 80, 255, 430],
[130, 430, 730]])
arr = np.arange(10) #矩阵开方
np.sqrt(arr)
Out[88]:
array([0. , 1. , 1.41421356, 1.73205081, 2. ,
2.23606798, 2.44948974, 2.64575131, 2.82842712, 3. ])
np.exp(arr)
Out[89]:
array([1.00000000e+00, 2.71828183e+00, 7.38905610e+00, 2.00855369e+01,
5.45981500e+01, 1.48413159e+02, 4.03428793e+02, 1.09663316e+03,
2.98095799e+03, 8.10308393e+03])
x = np.random.randn(8)
y = np.random.randn(8)
x
Out[92]:
array([-0.80864713, -1.10307828, 0.39407346, -1.51956716, -0.69376606,
-0.5599136 , 0.37168709, -0.3947183 ])
y
Out[93]:
array([ 1.49291073, -0.30018043, -0.1632179 , -0.53365993, 2.48673945,
-0.72669644, -0.18439522, 2.03956463])
#俩矩阵相比较
np.maximum(x, y)
Out[95]:
array([ 1.49291073, -0.30018043, 0.39407346, -0.53365993, 2.48673945,
-0.5599136 , 0.37168709, 2.03956463])
arr = np.random.randn(7) #矩阵相乘
arr*5
Out[97]:
array([-9.09778567, -1.2577255 , 2.85527111, -1.10915396, -3.61125732,
4.83669313, 0.49764244])
arr
Out[98]:
array([-1.81955713, -0.2515451 , 0.57105422, -0.22183079, -0.72225146,
0.96733863, 0.09952849])
arr = np.random.randn(7) * 5
arr
Out[100]:
array([ 2.02351861, 6.79384776, -5.29035855, 4.15965833, 7.93557854,
-1.93563595, 1.45949827])
#np.modf是个神奇的函数, 分别显示生辰改动连个不同矩阵
np.modf(arr)
Out[101]:
(array([ 0.02351861, 0.79384776, -0.29035855, 0.15965833, 0.93557854,
-0.93563595, 0.45949827]), array([ 2., 6., -5., 4., 7., -1., 1.])) points = np.arange(-5, 5, 0.01)
xs, ys = np.meshgrid(points, points)
xs
Out[105]:
array([[-5. , -4.99, -4.98, ..., 4.97, 4.98, 4.99],
[-5. , -4.99, -4.98, ..., 4.97, 4.98, 4.99],
[-5. , -4.99, -4.98, ..., 4.97, 4.98, 4.99],
...,
[-5. , -4.99, -4.98, ..., 4.97, 4.98, 4.99],
[-5. , -4.99, -4.98, ..., 4.97, 4.98, 4.99],
[-5. , -4.99, -4.98, ..., 4.97, 4.98, 4.99]])
ys
Out[106]:
array([[-5. , -5. , -5. , ..., -5. , -5. , -5. ],
[-4.99, -4.99, -4.99, ..., -4.99, -4.99, -4.99],
[-4.98, -4.98, -4.98, ..., -4.98, -4.98, -4.98],
...,
[ 4.97, 4.97, 4.97, ..., 4.97, 4.97, 4.97],
[ 4.98, 4.98, 4.98, ..., 4.98, 4.98, 4.98],
[ 4.99, 4.99, 4.99, ..., 4.99, 4.99, 4.99]])
import matplotlib.pyplot as plt
Backend TkAgg is interactive backend. Turning interactive mode on.
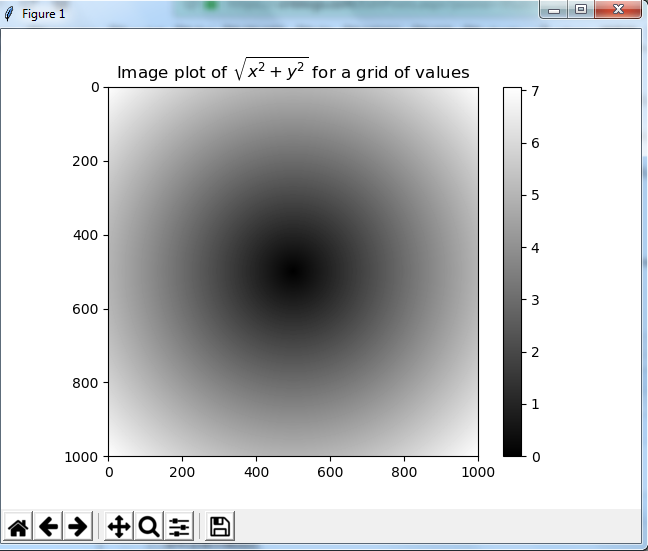
z = np.sqrt(xs**2 + ys**2)
z
Out[109]:
array([[7.07106781, 7.06400028, 7.05693985, ..., 7.04988652, 7.05693985,
7.06400028],
[7.06400028, 7.05692568, 7.04985815, ..., 7.04279774, 7.04985815,
7.05692568],
[7.05693985, 7.04985815, 7.04278354, ..., 7.03571603, 7.04278354,
7.04985815],
...,
[7.04988652, 7.04279774, 7.03571603, ..., 7.0286414 , 7.03571603,
7.04279774],
[7.05693985, 7.04985815, 7.04278354, ..., 7.03571603, 7.04278354,
7.04985815],
[7.06400028, 7.05692568, 7.04985815, ..., 7.04279774, 7.04985815,
7.05692568]]) #plt 的两个图像是进行叠加显示的。
plt.imshow(z, cmap=plt.cm.gray); plt.colorbar()
Out[110]: <matplotlib.colorbar.Colorbar at 0x8a3ccc0>
plt.title("Image plot of $\sqrt{x^2 + y^2}$ for a grid of values")
Out[111]: Text(0.5,1,'Image plot of $\\sqrt{x^2 + y^2}$ for a grid of values')
plt.imshow(z, cmap=plt.cm.gray); plt.colorbar()
Out[112]: <matplotlib.colorbar.Colorbar at 0xa894668>
python 数据分析 Numpy(Numerical Python Basic)的更多相关文章
- Python数据分析-Numpy数值计算
Numpy介绍: NumPy是高性能科学计算和数据分析的基础包.它是pandas等其他各种工具的基础. NumPy的主要功能: 1)ndarray,一个多维数组结构,高效且节省空间 2)无需循环对整组 ...
- python数据分析Numpy(二)
Numpy (Numerical Python) 高性能科学计算和数据分析的基础包: ndarray,多维数组(矩阵),具有矢量运算能力,快速.节省空间: 矩阵运算,无需循环,可以完成类似Matlab ...
- Python数据分析——numpy基础简介
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:基因学苑 NumPy(Numerical Python的简称)是高性 ...
- python数据分析 Numpy基础 数组和矢量计算
NumPy(Numerical Python的简称)是Python数值计算最重要的基础包.大多数提供科学计算的包都是用NumPy的数组作为构建基础. NumPy的部分功能如下: ndarray,一个具 ...
- Python数据分析 | Numpy与1维数组操作
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/33 本文地址:http://www.showmeai.tech/article-det ...
- 【Python数据分析案例】python数据分析老番茄B站数据(pandas常用基础数据分析代码)
一.爬取老番茄B站数据 前几天开发了一个python爬虫脚本,成功爬取了B站李子柒的视频数据,共142个视频,17个字段,含: 视频标题,视频地址,视频上传时间,视频时长,是否合作视频,视频分区,弹幕 ...
- Python数据分析numpy库
1.简介 Numpy库是进行数据分析的基础库,panda库就是基于Numpy库的,在计算多维数组与大型数组方面使用最广,还提供多个函数操作起来效率也高 2.Numpy库的安装 linux(Ubuntu ...
- python 数据分析----numpy
NumPy是高性能科学计算和数据分析的基础包.它是pandas等其他各种工具的基础. NumPy的主要功能: ndarray,一个多维数组结构,高效且节省空间 无需循环对整组数据进行快速运算的数学函数 ...
- Python数据分析--Numpy常用函数介绍(6)--Numpy中矩阵和通用函数
在NumPy中,矩阵是 ndarray 的子类,与数学概念中的矩阵一样,NumPy中的矩阵也是二维的,可以使用 mat . matrix 以及 bmat 函数来创建矩阵. 一.创建矩阵 mat 函数创 ...
随机推荐
- CF889E Mod Mod Mod
http://codeforces.com/problemset/problem/889/E 题解 首先我们观察到在每次取模的过程中一定会有一次的结果是\(a_i-1\),因为如果不是,我们可以调整, ...
- CG-CTF | 综合题
开场就是一个js混淆,直接丢到console里面 然后根据tip查头: 看到这个tip,一开始还以为要考注入了,用访问历史来进行注入,后来发现是我高估这题了,,,:
- 《Vue前端开发手册》
序言 为了统一前端的技术栈问题,技术开发二部规定开发技术必须以Vue为主. 为了更好的规范公司的前端框架,现以我前端架构师为主,编写以下开发规范,如有不当的地方,欢迎批评教育并慢慢改善该开发文档,谢谢 ...
- SQL的一对多,多对一,一对一,多对多什么意思?
1.一对多:比如说一个班级有很多学生,可是这个班级只有一个班主任.在这个班级中随便找一个人,就会知道他们的班主任是谁:知道了这个班主任就会知道有哪几个学生.这里班主任和学生的关系就是一对多. 2.多对 ...
- this._super()
https://learn.jquery.com/jquery-ui/widget-factory/extending-widgets/ https://api.jqueryui.com/jquery ...
- release,debug库互调用,32位,64位程序与库互调用
以下是基于visual studio 2015和cmake的实验 1,debug或release的应用程序都可以调用release的库2,win32和x64的应用和库无法互调用,在VS中链接时会有一堆 ...
- 解决IDEA输入法输入中文候选框不显示问题(亲测谷歌拼音完美解决问题)
解决方法:关掉idea,进入idea的安装目录找到jre64文件夹重命名为jre642(随便什么名字都行)如下图 然后找到jdk安装目录下的jre文件复制到上图idea的安装目录下并改名为jre64 ...
- Linux 下wdcp支持两种安装方式
wdcp支持两种安装方式1 源码编译 此安装比较麻烦和耗时,一般是20分钟至一个小时不等,具体视机器配置情况而定2 RPM包安装 简单快速,下载快的话,几分钟就可以完成源码安装(ssh登录服务器,执行 ...
- PEP8中文版 -- Python编码风格指南
Python部落组织翻译, 禁止转载 目录 缩进 制表符还是空格? 行的最大长度 空行 源文件编码 导入 无法忍受的 其 ...
- 001-spring boot概述与课程概要
一.Spring Boot介绍 Spring Boot的目的在于创建和启动新的基于spring框架的项目.Spring boot会选择最适合的Spring 子项目和第三方开源库进行整合.大部分Spri ...