FileOutputFormat
- TextOutputFormat<K,V> 默认输出字符串输出格式;
- SequenceFileOutputFormat<K,V> 序列化文件输出;
- MultipleOutputs<K,V> 可以把输出数据输送到不同的目录;
下面我们以分析FileOutputFormat为例,得到一些启迪,来满足我们的某些需要,
如修改keyvalue的分隔符,或者是修改写入文件的行分隔符 或是 重命名文件的输出名称等需求。
FileOutputFormat里面的主要方法是
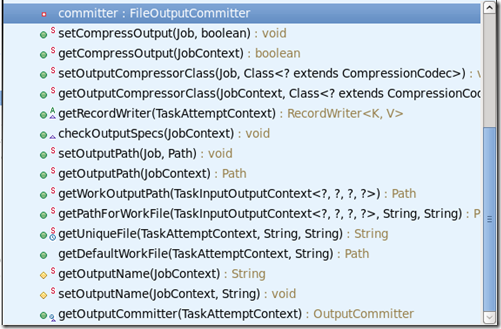
最重要的方法是getRecordWriter,recordwriter 对象用于写数据。
默认名件输出来自于方法getDefaultWorkFile(),而这个方法又调用了getUniqueFile().所以重写这些方法可以实现自己想要的文件名字。
TextOutputFormat中的
private static final byte[] newline = new byte[]{'\002'}; //可用于自定义自己的new line ,例如我使用\002来做新行的标志
import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;
这个类也可以在一定程度上实现改输出的文件名的功能。但它的主要功能是其名字所表达的。
它可以同时支持多种文件类型的输出,你可以把你的输出内容分目录输出,分文件输出,文件名前缀可以自己指定。
经实验,part-r-0000可能还存在,但是已经是空的,数据已经进入到你指定的文件中去了。
使用方法其实类本身中带的usage示例已经非常清楚地说明 。
驱动类中简单写下如下的代码即可:
* // Defines additional single text based output 'text' for the job
* MultipleOutputs.addNamedOutput(job, "text", TextOutputFormat.class,
* LongWritable.class, Text.class);
*
* // Defines additional sequence-file based output 'sequence' for the job
* MultipleOutputs.addNamedOutput(job, "seq",
* SequenceFileOutputFormat.class,
* LongWritable.class, Text.class);
然后就是需要在你的mapper类或者是reducer类中,一般是reducer类中,如果你的项目没有reduce阶段,则需要写到mapper类中。
写法如下:
private MultipleOutputs mos;
* public void setup(Context context) {
* ...
* mos = new MultipleOutputs(context);
* }
*
* public void reduce(WritableComparable key, Iterator<Writable> values,
* Context context)
* throws IOException {
* ...
* mos.write("text", , key, new Text("Hello"));
* mos.write("seq", LongWritable(1), new Text("Bye"), "seq_a");
* mos.write("seq", LongWritable(2), key, new Text("Chau"), "seq_b");
* mos.write(key, new Text("value"), generateFileName(key, new Text("value")));
* ...
* }
*
* public void cleanup(Context) throws IOException {
* mos.close();
* ...
* }
需要注意的是TextInput(output)format ,MultipleOutputs 等类在新旧api中都有实现,即mapred.lib.output和mapreduce.lib.output,你在项目中引用的时候,一定要注意,需要保持一致,否则会报错。
FileOutputFormat的更多相关文章
- Haoop Mapreduce 中的FileOutputFormat类
FileOutputFormat类继承OutputFormat,需要提供所有基于文件的OutputFormat实现的公共功能,主要有以下两点: (1)实现checkOutputSpecs方法 chec ...
- Mapreduce的文件和hbase共同输入
Mapreduce的文件和hbase共同输入 package duogemap; import java.io.IOException; import org.apache.hadoop.co ...
- mapreduce多文件输出的两方法
mapreduce多文件输出的两方法 package duogemap; import java.io.IOException; import org.apache.hadoop.conf ...
- mapreduce中一个map多个输入路径
package duogemap; import java.io.IOException; import java.util.ArrayList; import java.util.List; imp ...
- hadoop2.7之Mapper/reducer源码分析
一切从示例程序开始: 示例程序 Hadoop2.7 提供的示例程序WordCount.java package org.apache.hadoop.examples; import java.io.I ...
- [Hadoop in Action] 第7章 细则手册
向任务传递定制参数 获取任务待定的信息 生成多个输出 与关系数据库交互 让输出做全局排序 1.向任务传递作业定制的参数 在编写Mapper和Reducer时,通常会想让一些地方可以配 ...
- [Hadoop in Action] 第6章 编程实践
Hadoop程序开发的独门绝技 在本地,伪分布和全分布模式下调试程序 程序输出的完整性检查和回归测试 日志和监控 性能调优 1.开发MapReduce程序 [本地模式] 本地模式 ...
- [Hadoop in Action] 第5章 高阶MapReduce
链接多个MapReduce作业 执行多个数据集的联结 生成Bloom filter 1.链接MapReduce作业 [顺序链接MapReduce作业] mapreduce-1 | mapr ...
- 使用mapreduce计算环比的实例
最近做了一个小的mapreduce程序,主要目的是计算环比值最高的前5名,本来打算使用spark计算,可是本人目前spark还只是简单看了下,因此就先改用mapreduce计算了,今天和大家分享下这个 ...
随机推荐
- myeclipse的实用快捷键
(1)Ctrl+M切换窗口的大小(2)Ctrl+Q跳到最后一次的编辑处(3)F2当鼠标放在一个标记处出现Tooltip时候按F2则把鼠标移开时Tooltip还会显示即Show Tooltip Desc ...
- HTML—one
1.我们做一个完整的网页,要做三个部分 前端部分:Html(是一种超文本标记语言,网页)+css(网页外观)+js(执行动作,特效) 数据库:sqlserver 动态部分:.net(平台),c#(语言 ...
- .NET转JAVA之拼音组件
PS:做了4年,自我感觉.NET到瓶颈了,而且公司并没有深入运用.NET技术的项目,自我学习感觉也没太大动力(请骂我懒T_T).再加上技术年限越往上走,了解到的.NET职业提升环境就越来越艰难(个人理 ...
- 最小生成树Kruskal算法(邻接矩阵和邻接表)
最小生成树,克鲁斯卡尔算法. 算法简述: 将每个顶点看成一个图. 在所有图中找权值最小的边.将这条边的两个图连成一个图, 重复上一步.直到只剩一个图. 注:将abcdef每个顶点看成一个图.将最小权值 ...
- 树的统计Count---树链剖分
NEFU专项训练十和十一——树链剖分 Description 一棵树上有n个节点,编号分别为1到n,每个节点都有一个权值w.我们将以下面的形式来要求你对这棵树完成一些操作: I. CHANGE u t ...
- 如果一个游戏上面加一个透明层,js能不能实现 点击透明层的任意点 而正常玩游戏
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- SharePoint 服务器端对象模型操作用户组(创建/添加/删除)
摘要:几个操作SharePoint用户组的方法,已经测试通过,但是没有提升权限,如果没有权限的人操作,需要提升权限(提权代码附后).大家需要的话,可以参考下,写在这里也给自己留个备份~~ //创建用户 ...
- SharePoint Tricks - Survey
1. SharePoint 2010中,在Survey的问题框中输入HTML代码可以用于插入图片或者链接,具体方法为: 1.1 在问题框中输入html, 1.2 在New Form和Edit Form ...
- Redis介绍及常用命令
一 Redis介绍 Redis是一个开源的使用ANSI C语言编写.支持网络.可基于内存亦可持久化的日志型.Key-Value数据库,并提供多种语言的API.从2010年3月15日起,Redis的开发 ...
- 消除 activity 启动时白屏、黑屏问题
默认情况下 activity 启动的时候先把屏幕刷成白色,再绘制界面,绘制界面或多或少有点延迟,这段时间中你看到的就是白屏,显然影响用户体验,怎么消除呢? 在 Activity theme 设置sty ...