python笔记 - day3
python笔记 - day3
参考:http://www.cnblogs.com/wupeiqi/articles/5453708.html
set特性:
函数:
函数的作用:函数就是封装某一个功能的;
函数语法:
参数类型:
变量:
函数应用示例:
例一:
【形式参数:*args,把传入的参数都会以元组的形式打印出来;也会把列表当成一个元素传入到元组里】
def f1(*args):
print(args,type(args))
f1(,,,'alex')
li = [,,'alex','hhh']
f1(li,)
【实际参数:*,把列表里面的元素传入到元组里面】
f1(*li) 【实际参数:*,把字符串的每一个元素传入到元组里面】
li = "name"
f1(*li)
例二:
【**args,两个*输出的数据类型为字典,所以传入的参数也必须为两个值】
def f1(**args):
print(args,type(args))
f1(n1="alex",n2= )
【kk为字典的key,定义的dic为字典kk的value】
dic = {'k1':'v1','k2':'v2'}
f1(kk=dic)
【**,把dic字典,以字典形式赋值给args并打印出来】
f1(**dic)
【万能参数,前面是数组,后面是列表】
def f1(*args,**kwargs):
print(args)
print(kwargs) f1(,,,,k1='v1',k2='v2') 【python传参数传的是引用当前变量,不是重新赋值一份】
def f1(a1):
a1.append()
li = [,,,]
f1(li)
print(li) 【全局变量,变量名用大写】
name = 'alex'
def f1():
global name
#全局变量,变量名用大写
name = 'freddy'
age =
print(age,name)
def f2():
age =
print(age,name)
f1()
f2()
函数:发送邮件,并判断是否成功:
例一,没有传参:
def sendmail ():
try:
import smtplib
from email.mime.text import MIMEText
from email.utils import formataddr msg = MIMEText('test mail', 'plain', 'utf-8')
msg['From'] = formataddr(["武沛齐",'wptawy@126.com'])
msg['To'] = formataddr(["走人",'1011464647@qq.com'])
msg['Subject'] = "主题" server = smtplib.SMTP("smtp.126.com", 25)
server.login("wptawy@126.com", "WW.3945.59")
server.sendmail('wptawy@126.com', ['1011464647@qq.com',], msg.as_string())
server.quit()
except:
return False
else:
return True
res = sendmail()
if res == False:
print("Send mail Fail.")
else:
print("Send mail Seucess.")
例二,带传参:1.收件人 2.邮件内容 3.默认参数:
def sendmail (xxoo,content,xx="OK"):
print(xxoo,content,xx)
try:
import smtplib
from email.mime.text import MIMEText
from email.utils import formataddr msg = MIMEText(content, 'plain', 'utf-8')
msg['From'] = formataddr(["武沛齐",'wptawy@126.com'])
msg['To'] = formataddr(["走人",'1011464647@qq.com'])
msg['Subject'] = "主题" server = smtplib.SMTP("smtp.126.com", 25)
server.login("wptawy@126.com", "WW.3945.59")
server.sendmail('wptawy@126.com', [xxoo,], msg.as_string())
server.quit()
except:
return False
else:
return True
res = sendmail('1011464647@qq.com',"sb")
if res == False:
print("Send mail Fail.")
else:
print("Send mail Seucess.") 例3:进阶,手动输入收件人邮件地址;
def sendmail (xxoo,content,xx="OK"):
print(xxoo,content,xx)
try:
import smtplib
from email.mime.text import MIMEText
from email.utils import formataddr msg = MIMEText(content, 'plain', 'utf-8')
msg['From'] = formataddr(["武沛齐",'wptawy@126.com'])
msg['To'] = formataddr(["走人",'1011464647@qq.com'])
msg['Subject'] = "主题" server = smtplib.SMTP("smtp.126.com", 25)
server.login("wptawy@126.com", "WW.3945.59")
server.sendmail('wptawy@126.com', [xxoo,], msg.as_string())
server.quit()
except:
return False
else:
return True
while True:
em = input("mail addr:")
result = sendmail(em,"SB")
#传入时间参数,em:收件人地址;SB,是邮件内容;
# result = sendmail(xxoo=em,content="SB")
#指定参数,
if result == 'False':
print('send mail fail.')
else:
print('send mail secuess')
函数:以函数的形式写代码示例:
readme:
1.这个程序包含一个主程序文件,一个存放账号密码的文件;
2.存放密码的文件,账号和密码的分隔符为“|”
主程序:
#!/usr/bin/python env
#_*_coding:utf-8 _*_ def login(username,password):
"""
用于用户登陆
:param username: 用户输入的用户名
:param password: 用户输入的密码
:return: Ture,登陆成功;False,登陆失败;
"""
f = open('db','r+')
for line in f.readlines():
line = line.split("|")
if line[0] == username and line[1] == password:
return True
return False def register(username,password):
"""
用于用户注册
:param username: 注册用户名
:param password: 注册用户密码
:return: 默认None
"""
f = open('db','a')
temp = "\n" + username + "|" + password
f.write(temp)
f.close() def main():
t = input("1,login 2.register:")
if t == '':
user = input("user:")
pwd = input("passwd:")
r = login(user,pwd)
if r == True:
print("login secuess")
else:
print("login fail")
elif t == '':
user = input("user:")
pwd = input("passwd:")
register(user,pwd)
main()
语法糖:
【三元运算,三目运算】
1.正常写法:
if 1 == 1:
name = "freddy"
else:
name = "SB"
思路:
1.先判断条件,如果1=1,name就等于freddy,
2.否则,name就等于SB; 2.三目写法:
name = "freddy" if 1 == 1 else "SB"
print(name)
思路:
1.我想要name等于freddy,想要达到什么条件,
2.否则,就是SB; 【lambda,】
1.正常写法:
def t1(a1):
return a1 +100
res = t1(10)
print(res) 2.lambda写法:
f2 = lambda a1: a1 +110
ret = f2(10)
print(ret)
语法解析:
1.f2 = lambda #函数名+lambda
2.a1 #形式参数
3. a1 + 100 #函数内执行主体内容 2.1.之lambda + 2个函数:
f2 = lambda a1,a2: a1 + a2 +110
ret1 = f2(10,1)
print(ret1) 2.2.之lambda + 2个函数 + 默认参数:
f2 = lambda a1,a2=2: a1 + a2 +110
ret2 = f2(10)
print(ret2)
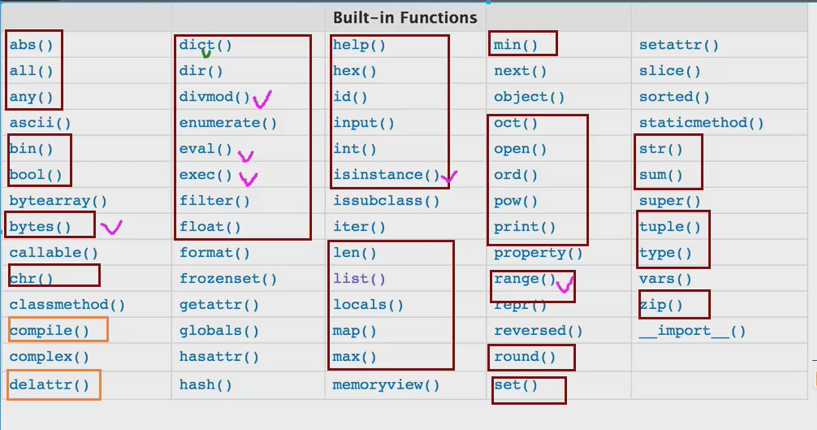
内置函数:
【abs,绝对值】
n = abs(-1)
print(n) 【bool,】
print(bool(1))
结果:True
print(bool(" "))
结果:True
print(bool())
结果:False
print(bool(0))
结果:False
print(bool(None))
结果:False
print(bool([]))
结果:False 【all(),所有为Ture,才为真;】
【可以被迭代,循环的对象】
n = all([1,2,3,4])
print(n) 【any(),只要有一个为真就是真】
n = any([1,[],0,"",None])
print(n) 【bin(),把5转换成2进制】
print(bin(5))
结果:0b101 #0b表示转成的是2进制
【oct(),把9转换成8进制】
print(oct(9))
结果:0o11 #0o表示是8进制
【hen(),把15转换成16进制】
print(hex(15))
结果:0xf #0x表示是16进制
【bytes(),字符串转换成字节】
s = '胜伟'
n = bytes(s,encoding="utf-8")
print(n) n = bytes(s,encoding="gbk")
print(n) 【str(),把字节转换成字符串用str】
nn = str(bytes("胜伟",encoding="utf-8"),encoding="utf-8")
print(nn) 【函数默认没有返回值,返回None】
li = [11,22,33,44]
def f1(arg):
arg.append(55)
li = f1(li) #让li重新等于了函数的返回值None
print(li)
结果:None li = [11,22,33,44]
def f1(arg):
arg.append(55)
return arg #增加了return
li = f1(li)
print(li)
结果:[11, 22, 33, 44, 55]
li = [11,22,33,44]
def f1(arg):
arg.append(55)
f1(li) #直接打印li的值
print(li)
结果:[11, 22, 33, 44, 55]
【bytes:把“唐胜伟”转换成utf-8的格式】
s = "唐胜伟"
ss = bytes(s,encoding='utf-8')
print(ss)
前言:在ASSCII码表中,第65位是大写字母A;
【chr:把ASCII数字转换成字母】
r = chr(65)
print(r)
结果:A 【ord:把大写字母A,转换成ASCII对应的数字】
a = ord("A")
print(a)
结果:65
【compile:就是把字符串编译成python代码】
【exec:执行python代码】
s = "print(123)"
r = compile(s,"<string>","exec")
exec(r)
【eval:把字符串通过evel转成python代码来执行】
s = "8*8"
ret = eval(s)
print(ret)
总结:
exec():能执行python所有的东西; |
eval():只能执行python表达式,并且evel有返回值; |
exec():执行python代码,或者字符串; |
eval():执行表达式,并返回结果; |
【dir():dir():获取python内置方法的功能】
print(dir(list))
help(list)
【divmod:取商和余数,在做分页的时候使用】
r = divmod(100,10)
print(r) print(r[0])
print(r[1]) r1,r2 = divmod(100,5)
print(r1,r2)
【isinstance:判断对象是否是某个类的实例】
【例:判断对象s是否是str类的实例】
s = "alex"
r = isinstance(s,str)
print(r)
【filter:取出列表中大于22的值】
原理:内部实现机制:li的每个参数都会执行f2方法,如果条件成立,返回Ture,并把结果赋值给result,返回False不做处理; 例一,不使用filter:
def f1(args):
result = []
for item in args:
if item > 22:
result.append(item)
return result
li = [11,22,33,44,55]
ret = f1(li)
print(ret) 例二,使用filter:
def f2(a):
if a>22:
return True
li = [11,22,33,44,55]
result = filter(f2,li)
#filter(函数,可迭代的对象)
print(list(ret)) 【lambda:lambda会内部做返回值,结果是什么就会返回什么】
f1 = lambda a: a > 30
ret = f1(90)
print(ret)
结果:True 【filter+lambda:如果返回True,则把结果赋值给result】
li = [11,22,33,44,55]
result = filter(lambda a: a >33,li)
print(list(result))
结果:[44, 55] 【map:需求,每个元素加100】
[map语法:map(函数,可迭代的对象(可以for循环的东西))]
方法一,原始方法:
li = [11,22,33,44,55]
def f1(args):
result = []
for i in args:
result.append(100+i)
return result
r = f1(li)
print(r) 方法二,进阶:
li = [11,22,33,44,55]
def f2(a):
return a + 100
result = map(f2,li)
print(list(result))
方法三,map+lambda:
li = [11,22,33,44,55]
result = map(lambda a: a+ 100,li)
print(list(result))
总结:
filter: 函数返回Ture,将元素添加到结果中;
map: 将函数返回值添加到结果中; 【globals():全局变量,locals(),局部变量】 NAME='Freddy'
def show():
a = 123
c = 123
print(locals())
print(globals())
show()
【hash:给传入的对象,转换成hash值,不管你传入的值是多长,hash出来值得长度永远是固定的】
【应用场景:一般都用于成字典的key】
s = 'feawfefeafefafwseesfesfsefwa'
print(hash(s))
【len:】
f = "唐胜伟"
b = len(bytes(f,encoding='utf-8'))
print(len(f))
print(b) 总结:
len:在python3里面,len的结果就是3,python3中用字符来计算的;
在python2中,len的结果就是9,python2中是用字节来计算的;
【max:取出来最大的值】
r = max([11,22,88,55])
print(r) 【min:取出来最小的值】
r = min([11,22,88,55])
print(r)
【sum:求和】
r = sum([11,22,88,55])
print(r)
【reversed:反转显示结果】
li = [11,22,44,33]
r = reversed(li)
print(list(r))
【round:四舍五入】
r = (1.8)
print(r)
结果:2 r = round(1.4)
print(r)
结果:1 【zip:取值方法】
l1 = ['freddy',11,22,33]
l2 = ['is',11,22,33]
l3 = ['sb',11,22,33] tem = zip(l1,l2,l3)
print(list(tem)) 结果:[('freddy', 'is', 'sb'), (11, 11, 11), (22, 22, 22), (33, 33, 33)] 例二:
l1 = ['freddy',11,22,33]
l2 = ['is',11,22,33]
l3 = ['sb',11,22,33] tem = zip(l1,l2,l3)
* 使用zip进行格式化输出; tmp = list(tem)[0]
print(tmp)
('freddy', 'is', 'sb')
* 取出序列化的第一列 ret = ' '.join(tmp)
print(ret)
结果:
freddy is sb
文件操作:
【r,只读】
f =open('db','r') 【w,清空原来db文件,然后再写入新内容】
f =open('db','w') 【x,文件存在报错,不存在,创建并写内容】
f =open('db','x') 【a,追加内容】
f =open('db','a') 【ab,追加写入;bytes,字节编码写入至文件内】
f = open("db",'ab')
f.write(bytes("胜伟",encoding="utf-8"))
f.close()
【读文件方法:1.utf-8。2.GBK。】
f = open('db','r',encoding='utf-8') #如果文件是以'utf-8'方式保存的,这里就要写一个'utf-8';
f = open('db','r',encoding='GBK') #如果文件是以gbk方式保存的,这里就要写一个GBK;
res = f.read()
print(res)
f.close()
【直接以二进制方式打开文件,优点:1.跨平台。2.快。】
f = open('db','rb')
data = f.read()
print(data,type(data))
【如果想以二进制的形式写入文件,写入的内容也必须转成二进制格式】
f = open('db','xb')
f.write(bytes('唐胜伟',encoding='utf-8'))
f.close()
【加b,以二进制,字节方式读】
f = open('db','rb')
res = f.read()
f.close()
print(res,type(res))
结果:b'\xe5\x94\x90\xe8\x83\x9c\xe4\xbc\x9f' <class 'bytes'> 【以字符串的方式读】
f = open('db','r',encoding='utf-8')
res = f.read()
f.close()
print(res,type(res))
结果:唐胜伟 <class 'str'>
【seek(),永远找的是字节指针位置,一个字母一个字节,一个汉字,如果是utf-8的格式,是三个字节】
f = open('db','r+',encoding="utf-8")
data=f.read(1) #f.read(1):如果以r的方式打开,读取就是一个字符指针位置;如果以rb的方式打开,读取就是一个字节指针位置
print(data)
f.seek(1) #seek(),调整指针的位置,seek的时候,seek的永远是字节的指针位置
f.write("777")
f.close()
【tell:获取当前指针的位置,单位永远是字节】
f = open('db','r+',encoding="utf-8")
data=f.read(1)
print(f.tell()) #f.tell():获取当前指针的位置,结果是:3,因为一个汉字(字符)占3位;
f.seek(f.tell()) #在tell获取的位置开始写内容,向后覆盖;
f.write("777")
f.close()
【读出来的文件类型是,字符串】
f=open('db','r',)
data = f.read()
print(data,type(data))
结果:<class 'str'>
f=open('db','r',encoding='utf-8')
data = f.read()
print(data,type(data))
结果:<class 'str'>
【rb,以字节方式读,读取类型是 字节】
f=open('db','rb',)
data = f.read()
print(data,type(data))
结果:<class 'bytes'>
【有b,按照字节读取;无b,按照字符读取】
f = open('db','r+',encoding='utf-8')
【tell(),获取当前指针位置;
seek(1) 跳转到指定指针位置】
data = f.read(1) #tell当前指针所在的位置(字节)
print(f.tell()) #调整当前指针的位置(字节)
f.seek(f.tell()) #当前指针位置开始向后覆盖
f.write('777') # write() 写数据,有b,写字节,没b,写字符;
write()
【flush,把缓冲区内容写入硬盘】
文件1:
f = open('db','a')
f.write("123")
f.flush()
input("str:") 文件2:
f =open('db','r+')
ret = f.read()
print(ret) 【readable,判断是否可写】
f = open('db','w')
ret = f.readable()
print(ret) 【readline,一行一行读,避免读取数据过大】
f = open('db','r')
f.readline()
f.readline() 【truncate,截断数据,把指针位置后的数据清空】
f = open('db','r+',encoding='utf-8')
f.seek(3)
f.truncate()
f.close() 【一行,一行的读这个文件】
f = open('db','r+',encoding="utf-8")
for line in f:
print(line) 【with,优点:不用手动去关闭文件,代码块的代码执行完后会自动关闭文件(f.close)】
思路一:
把f1文件里面的内容全部写入到f2:
with open('db1','r',encoding='utf-8') as f1,open('db2','w',encoding='utf-8') as f2:
for line in f1:
f2.write(line)
【把db1的前10行内容写入到db2文件中】
with open('db','r',encoding='utf-8') as f1,open('db1','w',encoding='utf-8') as f2:
count = 0
for line in f1:
count +=1
if count <= 10:
f2.write(line)
else:
break
思路二:
【把db1文件中的freddy,替换成st】
with open('db1','r',encoding='utf-8') as f1,open('db2','w',encoding="utf-8") as f2:
for line in f1:
new_str = line.replace("freddy",'st')
f2.write(new_str)
验证码小程序:
【例1:生成6位字母验证码】
import random
li = []
for i in range(6):
temp = random.randrange(65,91)
c = chr(temp)
li.append(c)
例二验证码,程序带入:
【join的时候元素必须都是字符串】
result = "".join(li)
print(result)
【例二:生成6位,包含两个数字的验证码】
import random
li = []
for i in range(6):
r = random.randrange(0,5)
print(r)
if r == 2 or r == 4:
num = random.randrange(0,10)
li.append(str(num)) ##转换成字符串类型,否则不能join
else:
temp = random.randrange(65,91)
c = chr(temp)
li.append(c)
result = "".join(li)
print(result)
从作业中学到的知识:
【语法技巧】
if True:
print('aa')
tt = True
if tt:
print('aa') 【列表格式的字符串】
s = "[11,22,33,44,55]"
print(s,type(s))
结果:<class 'str'> 【json:数据序列化,跨平台传输数据】
import json
s = "[11,22,33,44,55]" n = json.loads(s)
print(n,type(n))
结果:<class 'list'>
#json:将指定格式的字符串,转换成python的基本数据类型,
#注意:字符串形式的字典{"k1":"v1"}的内部字符串必须是双引号; 【json:格式化输出】
import json
r = input("input dic:")
dic = json.loads(r)
bk = dic['backend']
rd = "server %s %s weight %d maxconn %d"%(dic['record']['server'],
dic['record']['server'],
dic['record']['weight'],
dic['record']['maxconn'])
print(bk)
print(rd) 输入内容:{"backend": "test.oldboy.org","record":{"server": "100.1.7.9","weight": 20,"maxconn": 30}}
函数重要性:
python笔记 - day3的更多相关文章
- Python笔记之不可不练
如果您已经有了一定的Python编程基础,那么本文就是为您的编程能力锦上添花,如果您刚刚开始对Python有一点点兴趣,不怕,Python的重点基础知识已经总结在博文<Python笔记之不可不知 ...
- boost.python笔记
boost.python笔记 标签: boost.python,python, C++ 简介 Boost.python是什么? 它是boost库的一部分,随boost一起安装,用来实现C++和Pyth ...
- 20.Python笔记之SqlAlchemy使用
Date:2016-03-27 Title:20.Python笔记之SqlAlchemy使用 Tags:python Category:Python 作者:刘耀 博客:www.liuyao.me 一. ...
- Python笔记——类定义
Python笔记——类定义 一.类定义: class <类名>: <语句> 类实例化后,可以使用其属性,实际上,创建一个类之后,可以通过类名访问其属性 如果直接使用类名修改其属 ...
- 13.python笔记之pyyaml模块
Date:2016-03-25 Title:13.Python笔记之Pyymal模块使用 Tags:Python Category:Python 博客地址:www.liuyao.me 作者:刘耀 YA ...
- 8.python笔记之面向对象基础
title: 8.Python笔记之面向对象基础 date: 2016-02-21 15:10:35 tags: Python categories: Python --- 面向对象思维导图 (来自1 ...
- python笔记 - day8
python笔记 - day8 参考: http://www.cnblogs.com/wupeiqi/p/4766801.html http://www.cnblogs.com/wupeiqi/art ...
- python笔记 - day7-1 之面向对象编程
python笔记 - day7-1 之面向对象编程 什么时候用面向对象: 多个函数的参数相同: 当某一些函数具有相同参数时,可以使用面向对象的方式,将参数值一次性的封装到对象,以后去对象中取值即可: ...
- python笔记 - day7
python笔记 - day7 参考: http://www.cnblogs.com/wupeiqi/articles/5501365.html 面向对象,初级篇: http://www.cnblog ...
随机推荐
- 新浪微博iOS客户端架构与优化之路
新浪微博iOS客户端架构与优化之路 随着Facebook.Twitter.微博的崛起,向UGC.PGC.OGC,自媒体提供平台的内 容消费型App逐渐形成了独特的客户端架构模式.与电商和通讯工具类 ...
- <html:option获取文本值
<p class="w120">变更后IP:</p> <div class="comBobox w200 f_l"> < ...
- hdu Pie
这道题是一道二分搜索的题,首先计算出最大的平均体积:mx=V总/f:然后去left=0,right=mx,mid=(left+right)/2进行二分搜索,当所有pi分割出的mid的个数是大于等于f时 ...
- .NET中资料库的设计与SQL
.NET中资料库的设计与SQL ADO.NET设计 先来说说资料库的设计 主要涉及 关联式资料库 资料库系统管理(DBMS) 结构化查询(SQL) 预储程序 一个资料库包含一个以上的资料表,每个资料表 ...
- nova.conf部分参数解析
#----------networking options---------------# #nova的dhcpbridge配置的文件位置 --dhcpbridge_flagfile=/etc/nov ...
- 使用安捷伦波形编辑软件产生GK101 任意波数据文件的方法(支持手绘)
软件安装包下载地址: 链接: http://pan.baidu.com/s/1bn8Lmhx 密码: v5xz 一.安捷伦IO套件安装 1.将压缩包解压,首先双击IOLibSuite_16_3_179 ...
- FZU 2032 高精度小数加法
题目描写很没意思..就是说给出n个小数 求它们的总和 因为给出的小数点后最多16位而要求保存至12位 而能直接使用的最精确的double只能到12位 于是13的进位可能被忽略 于是不可以用double ...
- [听点音乐]American Music Awards 2015 Winners
“see you again” - wiz khalifa feat. charlie puth Lyrics It's been a long day without you my friend ...
- Ubuntu安装Flash
第一步:打开视频网站,随意点击一个视频,会提示需要先安装Flash,点击它所提供的链接. 第二步:根据系统选择合适的版本进行下载,有红帽的yum版本,我选择的是tar.gz for other Lin ...
- 学习VS生活
很多时候,失败的原因归结为一点:我没有时间...代码敲不完,我真的是没有时间么?很多时候是没意识的浪费时间 我每次进教室,总能看到吴刚和赵东亮在敲代码,为啥他们有时间呢?很多时候,时间就像那啥,挤一挤 ...