JDK1.7 HashMap 源码分析
概述
HashMap是Java里基本的存储Key、Value的一个数据类型,了解它的内部实现,可以帮我们编写出更高效的Java代码。
本文主要分析JDK1.7中HashMap实现,JDK1.8中的HashMap已经和这个不一样了,后面会再总结。
正文
HashMap概述
HashMap根据键的hashCode值获取存储位置,大多数情况下可以直接定位到它的值,因而具有很快的访问速度,但遍历顺序却是不确定的。 HashMap最多只允许一条记录的键为null,允许多条记录的值为null。HashMap非线程安全,即任一时刻可以有多个线程同时写HashMap,可能会导致数据的不一致。如果需要满足线程安全,可以用 Collections的synchronizedMap方法使HashMap具有线程安全的能力,或者使用ConcurrentHashMap。
HashMap的存储结构如下图所示:
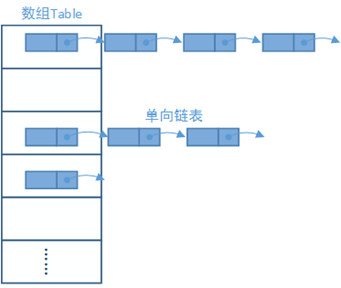
HashMap根据键的hashCode值和HashMap里数组的大小取余,余数即为该Key存储的数组位置。
如:一个Key的hashCode为15,HashMap的Size为6,15 % 6 = 3,所以该Key存储在数组的第三个位置。
考虑另一种情况,如果一个Key的hashCode为21,那21 % 6 = 3,所以该Key也存储在数组的第三个位置,这样岂不是重复了?
所以对于在同一个位置的Key,HashMap把他们存储在一个单向链表里,新的Key永远在最前面。
如果这个数组里存储的太满,HashMap还有扩容机制。
下面我们分析HashMap的源代码,来看看数据是怎么存储的。
PUT
public V put(K key, V value) {
//判断如果table为空,则初始化table
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
//计算key的hash值
int hash = hash(key);
//根据key的hash值和table.length计算KEY的位置
int i = indexFor(hash, table.length);
//判断是否有重复的值,若有,则用新值替换旧值,并返回旧值
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
//修改的次数加一,用于迭代HashMap时,判断HashMap元素有没有修改
modCount++;
//添加key
addEntry(hash, key, value, i);
return null;
}
inflateTable — 初始化HashMap内部数组
private void inflateTable(int toSize) {
//根据toSize计算容量,即大于toSize的最小的2的n次方
int capacity = roundUpToPowerOf2(toSize);
………
}
private static int roundUpToPowerOf2(int number) {
// assert number >= 0 : "number must be non-negative";
return number >= MAXIMUM_CAPACITY
? MAXIMUM_CAPACITY
: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;
}
public static int highestOneBit(int i) {
// HD, Figure 3-1
i |= (i >> 1);
i |= (i >> 2);
i |= (i >> 4);
i |= (i >> 8);
i |= (i >> 16);
return i - (i >>> 1);
}
关键方法Integer.highestOneBit((number - 1) << 1),这个方法的结果就是求出大于给定数值的,最小的2的N次方。
解释之前先说明几个概念:
<< : 按二进制形式把所有的数字向左移动对应的位数,高位移出(舍弃),低位的空位补零。在数字没有溢出的前提下,对于正数和负数,左移一位都相当于乘以2的1次方,左移n位就相当于乘以2的n次方;
>>: 按二进制形式把所有的数字向右移动对应位移位数,低位移出(舍弃),高位的空位补符号位,即正数补零,负数补1。右移一位相当于除2,右移n位相当于除以2的n次方。
>>>: 无符号右移,忽略符号位,空位都以0补齐
我们拿数字10做示例,经过(number - 1) << 1 = 18,二进制表示为:10010
i |= (i >> 1) 即:10010 | 01001 = 11011
i |= (i >> 2) 即:11011 | 00110 = 11111
i |= (i >> 4) 即:11111 | 00001 = 11111
……
其实这几步就是把i的最高位1之后的所有位都变成1
然后 i – (i >>> 1) 即:11111-01111=10000(16)
这步是把最高位,之后的都变成0,这样就求出了最接近10的2的N次方(16)
至于为什么要把数组的Size设置为2的N次方,我们后面说。
hash — 计算Key的hash值
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
根据上面的注释,我们可以看出,HashMap中使用的hash值,不是Key直接的hashCode,而是经过一系列计算的。
计算hash值的作用就是,让hash的高位也参与indexFor运算,避免hash碰撞,尽量减少单向链表的产生,因为链表中查找一个元素时间复杂度为O(n)。
具体怎么避免的,我们放到下面这个indexFor里说。
indexFor — 计算Key所对应的数组位置
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
}
第一次看到这个方法很是不理解,不是应该用 h % length吗?其实这里用了一个非常巧妙的方法来取这个余数。
在计算机中CPU做除法运算、取余运算耗费的CPU周期都比较长,一般几十个CPU周期,而位移运算、位运算只用一个CPU周期。
这样对于性能要求高的地方,就可以用位运算代替普通的除法、取余等运算,JDK源码中有很多这样的例子。
为了能够使用位运算求出这个余数,length必须是2的N次方,这也是我们上面初始化数组大小时要求的,然后使用 h & (length-1),就可以求出余数。具体的算法推导,请自行搜索。
我们用个例子来说明下,如一个Key经过运算的hash为21,length为16:
直接取余运算:21 % 16 = 5
位运算:10101(21) & 01111(16-1) = 00101(5)
哇,这就是计算机运算的魅力,这就是算法的作用。
另外就是上一步的hash算法,因为我们求Key所在数组位置的算法是h & (length-1)
假设下面两个hash值,:
00000000000000110001001001100010(201314)
00000000000000000000000000100010(34)
如果length=32,则:length-1:
00000000000000000000000000011111(31)
这两个hash值计算数组位置时,都为2,其实只有二进制的后六位参与了运算,高位根本没有任何作用,这样就加大了产生hash碰撞的概率。
所以上一步的hash算法就是为了解决这个问题,将hash值的高位进行一系列左移和异或,使高位也参与到与运算里,上面两个hash值就可以分配到不同的位置。
addEntry — 添加数据
void addEntry(int hash, K key, V value, int bucketIndex) {
//如果size大于等于threshold,且数组的这个位置不为null,则扩容数组
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
threshold:HashMap实际可以存储的Key的个数,如果size大于threshold,说明HashMap已经太饱和了,非常容易发生hash碰撞,导致单向链表的产生。
在inflateTable方法中,我们可以看到
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
所以这个值是由HashMap的capacity 和负载因子(loadFactor默认:0.75)计算出来的。
loadFactor越小,相同的capacity就更频繁地扩容,这样的好处是HashMap会很大,产生hash碰撞的几率就更小,但需要的内存也更多,这就是所谓的空间换时间。
在这里也注意,扩容时会直接将原来容量乘以2,满足了length为2的N次方的条件。
createEntry就不多说了,就是将key、value保存到数组相应的位置。
GET
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
//用和添加时相同的算法求出hash值
int hash = (key == null) ? 0 : hash(key);
//直接从数组的响应位置拿到数据,判断hash相同、key相同,则返回
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
获取时非常简单,也非常迅速,添加时做的所有工作都是为快速获取做的工作。
总结
HashMap是一个非常高效的Key、Value数据结构,GET的时间复杂度为:O(1) ~ O(n),我们在使用HashMap时需要注意以下几点:
1. 声明HashMap时最好使用带initialCapacity的构造函数,传入数据的最大size,可以避免内部数组resize;
2. 性能要求高的地方,可以将loadFactor设置的小于默认值0.75,使hash值更分散,用空间换取时间;
JDK1.7 HashMap 源码分析的更多相关文章
- JDK1.8 HashMap源码分析
一.HashMap概述 在JDK1.8之前,HashMap采用数组+链表实现,即使用链表处理冲突,同一hash值的节点都存储在一个链表里.但是当位于一个桶中的元素较多,即hash值相等的元素较多时 ...
- JDK1.8 HashMap 源码分析
一.概述 以键值对的形式存储,是基于Map接口的实现,可以接收null的键值,不保证有序(比如插入顺序),存储着Entry(hash, key, value, next)对象. 二.示例 public ...
- JDK1.7 hashMap源码分析
了解HashMap原理之前先了解一下几种数据结构: 1.数组:采用一段连续的内存空间来存储数据.对于指定下标的查找,时间复杂度为O(1),对于给定元素的查找,需要遍历整个数据,时间复杂度为O(n).但 ...
- jdk1.8 HashMap源码分析(resize函数)
// 扩容兼初始化 final Node<K, V>[] resize() { Node<K, V>[] oldTab = table; int oldCap = (oldTa ...
- HashMap源码分析(一)
基于JDK1.7 HashMap源码分析 概述 HashMap是存放键值对的集合,数据结构如下: table被称为桶,大小(capacity)始终为2的幂,当发生扩容时,map容量扩大为两倍 Hash ...
- HashMap 源码分析 基于jdk1.8分析
HashMap 源码分析 基于jdk1.8分析 1:数据结构: transient Node<K,V>[] table; //这里维护了一个 Node的数组结构: 下面看看Node的数 ...
- HashMap实现原理(jdk1.7),源码分析
HashMap实现原理(jdk1.7),源码分析 HashMap是一个用来存储Key-Value键值对的集合,每一个键值对都是一个Entry对象,这些Entry被以某种方式分散在一个数组中,这个数 ...
- 源码分析系列1:HashMap源码分析(基于JDK1.8)
1.HashMap的底层实现图示 如上图所示: HashMap底层是由 数组+(链表)+(红黑树) 组成,每个存储在HashMap中的键值对都存放在一个Node节点之中,其中包含了Key-Value ...
- 【JAVA集合】HashMap源码分析(转载)
原文出处:http://www.cnblogs.com/chenpi/p/5280304.html 以下内容基于jdk1.7.0_79源码: 什么是HashMap 基于哈希表的一个Map接口实现,存储 ...
随机推荐
- Intrusion Analysis Learning
目录 . 入侵分析简介 . 基于日志的入侵分析技术 . 入侵分析CASE . 入侵分析CASE . 入侵分析CASE . 入侵分析CASE 1. 入侵分析简介 Windows 清除日志的方法 wmic ...
- 如何起草你的第一篇科研论文——应该做&避免做
如何起草你的第一篇科研论文——应该做&避免做 导语:1.本文是由Angel Borja博士所写.本文的原文链接在这里.感谢励德爱思唯尔科技的转载,和刘成林老师的转发.2.由于我第二次翻译,囿于 ...
- 理解模板引擎Razor 的原理(转载)
Razor是ASP.NET MVC 3中新加入的技术,以作为ASPX引擎的一个新的替代项.简洁的语法与.NET Framework 结合,广泛应用于ASP.NET MVC 项目.Razor Pad是一 ...
- word表格断行的问题
word一个表格如果某一行的 内容 太多,就会自动跑到下一页去了 解决方法是: 在表格上点右键-> 属性 -> "行" -> 去掉"设置行高" ...
- jQuery1.11源码分析(5)-----Sizzle编译和过滤阶段[原创]
在上一章中,我们说到在之前的查找阶段我们已经获得了待选集seed,那么这一章我们就来讲如何将seed待选集过滤,以获得我们最终要用的元素. 其实思路本质上还是不停地根据token过滤,但compile ...
- C#集合实现接口一览表
- More is better(MST)(求无向图中最大集合元素个数)
More is better Time Limit:1000MS Memory Limit:102400KB 64bit IO Format:%I64d & %I64u Sub ...
- document.documentElement和document.body的区别
网页中获取滚动条卷去部分的高度,可以通过 document.body.scrollTop 来获取,比如使div跟着滚动条滚动: <div id="div" style=&qu ...
- 工具推荐:2016年最佳的15款Android黑客工具
黑客技术,曾被认为是专家的专有领域,但随着技术的崛起和移动安全领域的进步,黑客技术已经变得越来越普遍.随着人们越来越依赖于智能手机和其它的便携式设备来完成他们的日常活动,我们有必要了解一些Androi ...
- HDOJ 2546饭卡(01背包问题)
http://acm.hdu.edu.cn/showproblem.php?pid=2546 Problem Description 电子科大本部食堂的饭卡有一种很诡异的设计,即在购买之前判断余额.如 ...