《疯狂Java:突破程序员基本功的16课》读书笔记-第二章 对象与内存控制
Java内存管理分为两个方面:内存分配和内存回收。这里的内存分配特指创建Java对象时JVM为该对象在堆内存中所分配的内存空间。内存回收指的是当该Java对象失去引用,变成垃圾时,JVM的垃圾回收机制自动清理该对象,并回收该对象所占用的内存。由于JVM内置了垃圾回收机制回收失去引用的Java对象所占用的内存,所以很多Java开发者认为Java不存在内存泄漏,资源泄漏的问题。实际上这是一种错觉,Java程序依然会有内存泄漏。
由于JVM的垃圾回收机制由一条后台线程完成,本身也是非常消耗性能的,因此如果肆无忌惮地创建对象,让系统分配内存,那这些分配的内存都将由垃圾回收机制进行回收。这样做有两个坏处:
(1) 不断分配内存使得系统中可用内存减少,从而降低程序运行性能;
(2) 大量已分配内存的回收使得垃圾回收的负担加重,降低程序的运行性能。
2.1实例变量和类变量
Java程序的变量大体可分为成员变量和局部变量。其中局部变量可分为如下3类:
(1) 形参:在方法签名中定义的局部变量,由方法调用者为其赋值,随方法的结束而消亡。
(2) 方法内的局部变量:在方法内定义的局部变量,必须在方法内对其进行显式初始化。这种类型的局部变量从初始化完成后开始生效,随方法的结束而消亡。
(3) 代码块内的局部变量:在代码块内定义的局部变量,必须在代码块内对其进行显式初始化。这种类型的局部变量从初始化完成后开始生效,随代码块的结束而消亡。
局部变量的作用时间很短暂,他们都被存储在方法的栈内存中。
类体内定义的变量被成为成员变量(Field)。如果定义该成员变量时没有使用static修饰,该成员变量又被称为非静态变量或实例变量;如果使用了static修饰,则该成员变量又被成为静态变量或类变量。
(对于static关键字而言,从词义上看来,它是“静态”的意思。但从Java程序的角度来看,static的作用就是将实例成员变成类成员,static只能修饰在类里定义的成员部分,包括成员变量,方法,内部类,初始化块,内部枚举类。如果没有使用static修饰这些类里的成员,这些成员属于该类的实例;如果使用了static修饰,这些成员就属于类本身。从这个意义上看,static只能修饰类里的成员,不能修饰外部类,不能修饰局部变量,局部内部类)。
表面上看,Java类里定义成员变量时没有先后顺序,但实际上Java要求定义成员变量时必须采用合法的前向引用。示例如下:
public class ErrorDef
{
//下面代码将提示:非法向前引用
int num1 = num2 + 2;
int num2 = 20;
} public class ErrorDef2
{
//下面代码将提示:非法向前引用
static int num1 = num2 + 2;
static int num2 = 20;
}
但如果一个是实例变量,一个是类变量,则实例变量总是可以引用类变量,因为类变量的初始化时机总是处于实例变量的初始化时机之前。示例如下:
public class RightDef
{
//下面代码完全正确
int num1 = num2 + 2;
static int num2 = 20;
}
2.1.1 实例变量和类变量的属性
使用static修饰的成员变量是类变量,属于该类本身;没有使用static修饰的成员变量是实例变量,属于该类的实例。在同一个JVM内,每个类只对应一个Class对象,但每个类可以创建多个Java对象。
由于同一个JVM内每个类只对应一个Class对象,因此同一个JVM内的一个类的类变量只需一块内存空间;但对于实例变量而言,该类每创建一次实例,就需要为实例变量分配一块内存空间。也就是说,程序中有几个实例,实例变量就需要几块内存空间。
下面程序可以很好地表现出实例变量属于对象,而类变量属于类的特性
class Person
{
String name;
int age;
static int eyeNum;
public void info()
{
System.out.println("我的名字是:" + name
+ ", 我的年龄是:" + age);
}
}
public class FieldTest
{
public static void main(String[] args)
{
//类变量属于该类本身,只要该类初始化完成,程序即可使用类变量。
Person.eyeNum = 2;
//通过Person类访问eyeNum类变量
System.out.println("Person的eyeNum属性:" + Person.eyeNum);
//创建第一个Person对象
Person p = new Person();
p.name = "猪八戒";
p.age = 300;
//通过p访问Person类的eyeNum类变量
System.out.println("通过p变量访问eyeNum类变量:" + p.eyeNum);
p.info();
//创建第二个Person对象
Person p2 = new Person();
p2.name = "孙悟空";
p2.age = 500;
p2.info();
//通过p2修改Person类的eyeNum类变量
p2.eyeNum = 3;
//分别通过p、p2和Person访问Person类的eyeNum类变量
System.out.println("通过p变量访问eyeNum类变量:" + p.eyeNum);
System.out.println("通过p2变量访问eyeNum类变量:" + p2.eyeNum);
System.out.println("通过Person类访问eyeNum类变量:" + Person.eyeNum);
}
}
执行完这段程序,内存情况如图:
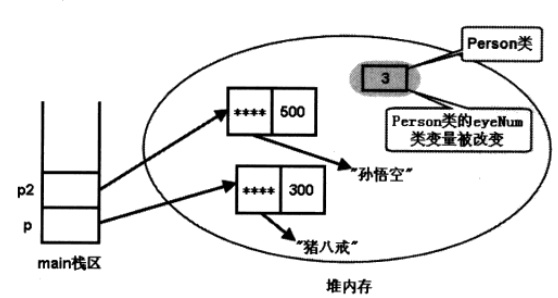
当Person类初始化完成后,eyeNum类变量也随之初始化完成。
2.1.2 实例变量的初始化时机
从程序运行的角度来看,每次创建Java对象都会为实例变量分配内存空间,并对实例变量执行初始化。
从语法角度来看,程序可以在3个地方对实例变量执行初始化:
(1) 定义实例变量时指定初始值;
(2) 非静态初始化块中对实例变量指定初始值;
(3) 构造器中对实例变量指定初始值。
其中第1,2种方式比第3种方式更早执行,但他们的执行顺序与排列顺序相同。
下面程序示范了实例变量的初始化时机
class Cat
{
//定义name、age两个实例变量
String name;
int age;
//使用构造器初始化name、age两个实例变量
public Cat(String name , int age)
{
System.out.println("执行构造器");
this.name = name;
this.age = age;
}
{
System.out.println("执行非静态初始化块");
weight = 2.0;
}
//定义时指定初始值
double weight = 2.3;
public String toString()
{
return "Cat[name=" + name
+ ",age=" + age + ",weigth=" + weight + "]";
}
}
public class InitTest
{
public static void main(String[] args)
{
Cat cat = new Cat("kitty" , 2);
System.out.println(cat);
Cat c2 = new Cat("Jerfield" , 3);
System.out.println(c2);
}
}
当程序执行Cat cat = new Cat("kitty" , 2);时,创建第一个Cat对象,程序就会先执行Cat类的非静态初始化块,再调用该Cat类的构造器来初始化该Cat实例,内存分配如图:
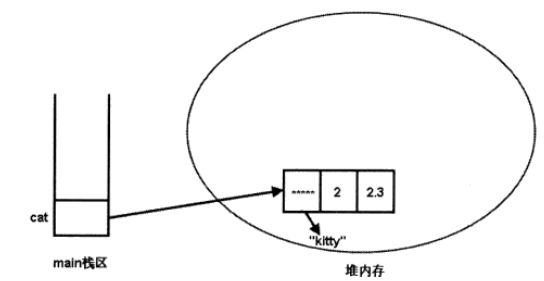
从上图可以看出,该Cat对象的weight实例变量的值为2.3,而不是初始化块中指定的。这是因为,初始化块中指定初始值,定义weight时指定初始值,都属于对该实例变量执行的初始化操作,它们的执行顺序与它们在源程序中的排列顺序相同。在本程序中,初始化块中对weight的赋值位于定义weight语句之前,因此程序将先执行初始化块中的操作,执行完成后weight的值为2.0;然后再执行定义weight时指定的初始值,完成后weight为2.3,从这里看,初始化块中对weight所指定的初始化值每次都将被2.3所覆盖
2.1.3 类变量的初始化时机
从程序运行的角度来看,每JVM对一个Java类只初始化一次,因此Java程序每运行一次,系统只为类变量分配一次内存空间,执行一次初始化。
从语法角度来看,程序可以在2个地方对类变量执行初始化:
(1) 定义类变量时指定初始值;
(2) 静态初始化块中对类变量指定初始值
这两种方式的执行顺序与它们在源程序中排列顺序相同。下列程序示范了类变量的初始化时机。
public class StaticInitTest
{
//定义count类变量,定义时指定初始值。
static int count = 2;
//通过静态初始化块为name类变量指定初始值
static {
System.out.println("StaticInitTest的静态初始化块");
name = "Java编程";
}
//定义name类变量时指定初始值
static String name = "疯狂Java讲义";
public static void main(String[] args)
{
//访问该类的两个类变量
System.out.println("count类变量的值:" + StaticInitTest.count);
System.out.println("name类变量的值:" + StaticInitTest.name);
}
}
2.2 父类构造器
当创建任何Java对象时,程序总会先依次调用每个父类非静态初始化块,父类构造器执行初始化,最后才调用本类的非静态初始化块,构造器执行初始化。
2.2.1 隐式调用和显式调用
当调用某个类的构造器来创建Java对象时,系统总会先调用父类的非静态初始化块进行初始化。这个调用是隐式执行的,而且父类的静态初始化块总是会被执行。接着调用父类一个或多个构造器执行初始化,这个调用既可以是通过super进行显式调用,也可以是隐式调用。
当所有父类的非静态初始化块,构造器依次调用完成后,系统调用本类的非静态初始化块,构造器执行初始化,最后返回本类实例。
如果有本图的继承关系:

程序会按如下步骤进行初始化:
(1) 执行Object类非静态初始化块(如果有的话)。
(2) 隐式或显式调用Object类的一个或多个构造器执行初始化。
(3) 执行Parent类非静态初始化块(如果有的话)。
(4) 隐式或显式调用Parent类的一个或多个构造器执行初始化。
(5) 执行Mid类非静态初始化块(如果有的话)。
(6) 隐式或显式调用Mid类的一个或多个构造器执行初始化。
(7) 执行Sub类非静态初始化块(如果有的话)。
(8) 隐式或显式调用Sub类的一个或多个构造器执行初始化。
只要在程序创建Java对象,系统总是先调用最顶层父类的初始化操作,包括初始化块和构造器,然后依次向下调用所有父类的初始化操作,最终执行本类的初始化操作返回本类的实例。至于调用父类的哪个构造器执行初始化,则分为如下几种情况:
(1) 子类构造器执行体的第一行代码使用super显式调用父类构造器,系统将根据super调用里传入的实参列表来确定调用父类的哪个构造器;
(2) 子类构造器执行的第一行代码使用this显式调用本类中重载的构造器,系统将根据this调用里传入的实参列表来确定本类的另一个构造器(执行本类中另一个构造器时即进入第一种情况);
(3) 子类构造器执行提中既没有super调用,也没有this调用,系统将会在执行子类构造器之前,隐式调用父类无参数的构造器。
(super调用用于显式调用父类的构造器,this调用用于显式调用本类中另一个重载的构造器。Super调用和this调用都只能在构造器中使用,而且super调用和this调用都必须作为构造器的第一行代码,因此构造器中的super调用和this调用最多只能使用其中之一,而且最多只能调用一次)。
2.2.2 访问子类对象的实例变量
子类的方法可以访问父类的实例变量,这是因为子类继承父类就会获得父类的成员变量和方法;但父类的方法不能访问子类的实例变量,因为父类根本无从知道它将被哪个子类继承,它的子类将会增加怎样的成员变量。
但是,在极端的情况下,可能出现父类访问子类变量的情况,例子如下:
class Base
{
//定义了一个名为i的实例变量
private int i = 2;
public Base()
{
this.display();
}
public void display()
{
System.out.println(i);
}
}
//继承Base的Derived子类
class Derived extends Base
{
//定义了一个名为i的实例变量
private int i = 22;
//构造器,将实例变量i初始化为222
public Derived()
{
i = 222;
}
public void display()
{
System.out.println(i);
}
}
public class Test
{
public static void main(String[] args)
{
//创建Derived的构造器创建实例
new Derived();
}
}
程序main里只有new Derived();。它会调用Derived的构造器,因为Derived继承了Dase,而且Derived构造器里没有显式使用super来调用父类的构造器,因此系统将会自动调用Base中无参数的构造器来初始化。
最后程序输出是0。不是22,也不是222,这是怎么回事呢?
为了解释这个程序,首先需要澄清一个概念:Java对象是由构造器创建的吗?很多书籍,资料中会说,是的。
但实际情况是:构造器只负责对Java对象实例变量执行初始化(也就是赋初始值),在执行构造器代码之前,该对象所占的内存已经被分配下来,这些内存里值都是默认是空值。
当程序执行new Derived();时,系统会先为Derived对象分配内存空间。此时系统内存需要为这个Derived对象分配两块内存,它们分别用于存放Derived对象的两个i实例变量,其中一个属于Base类定义的i,一个属于Derived类定义的i,此时这2个i的值都是0。
接下来程序在执行Derived的构造器之前,首先会执行Base类的构造器。表面上看,Base的构造器内只有一行代码this.display();,但由于Base类定义了i时指定了初始值是2,因此经过编译处理后,该构造器应该包含如下两行代码。
i = 2;
this.display();
现在的问题就是此处的this代表谁?
Java的定义是,当this在构造器中时,this代表正在初始化的Java对象。此时的情况是:从源代码来看,此时的this位于Base构造器内,但这些代码实际放在Derived构造器内执行,是Derived构造器隐式调用了Base构造器的代码。由此可见,此时的this应该是Derived对象,而不是Base对象。但是这个this虽然代表Derived对象,但它却位于Base构造器中,它的编译时类型是Base,而它实际引用了一个Derived对象。
为了验证这一点,为Derived类增加一个简单的sub()方法,然后改造Base构造器
public Base()
{
System.out.println(this.i);
this.display();
System.out.println(this.getClass());
//因为this的编译类型是Base,所以依然不能调用sub()方法
this.sub();
}
上面程序调用this.getClass()来获取this代表对象的类,将看到输出Derived类,这表明此时this引用代表是Derived对象,但程序调用sub()时,则无法通过编译,这是因为this的编译时类型是Base的缘故。
当变量的编译时类型和运行时类型不同时,通过该变量访问它引用的对象的实例变量时,该实例变量的值由声明该变量的类型决定。但通过该变量调用它引用的对象的实例方法时,该方法行为将由它实际所引用的对象来决定。因此,当程序访问this.i时,将会访问Base类中定义的i实例变量,也就是输出2;但执行this.display()时,则实际表现出Derived对象的行为,也就是输出Derived对象的i实例变量,即0。
2.2.3 调用被子类重写的方法
在访问权限允许的情况下,子类可以调用父类方法,这是因为子类继承父类会获得父类定义的成员变量和方法;但父类不能调用子类的方法,因此父类根本无从知道它将被哪个子类继承,它的子类将会增加怎样的方法。
但有一种特殊情况,当子类方法重写了父类方法之后,父类表面上只有调用属于自己的,被子类重写的方法,但随着执行context的改变,将会变成父类实际调用子类的方法。
实例如下:
class Animal
{
//desc实例变量保存对象toString方法的返回值
private String desc;
public Animal()
{
//调用getDesc()方法初始化desc实例变量
this.desc = getDesc();
}
public String getDesc()
{
return "Animal";
}
public String toString()
{
return desc;
}
}
public class Wolf extends Animal
{
//定义name、weight两个实例变量
private String name;
private double weight;
public Wolf(String name , double weight)
{
//为name、weight两个实例变量赋值
this.name = name;
this.weight = weight;
}
//重写父类的getDesc()方法
@Override
public String getDesc()
{
return "Wolf[name=" + name + " , weight="
+ weight + "]";
}
public static void main(String[] args)
{
System.out.println(new Wolf("灰太郎" , 32.3));
}
}
这段代码会输出Wolf[name=null , weight=0.0],而不是Wolf[name=灰太狼 , weight=32.3],那我们赋的值哪去了?
理解这个程序的关键在于this.desc = getDesc();。表面上此处是调用父类中定义的getDesc()方法,但实际运行过程中,此处会变成调用被子类重写的getDesc()方法。
程序在执行new Wolf("灰太郎" , 32.3) 之前,系统会隐式执行父类无参数的构造器,也就是先执行this.desc = getDesc();但不再调用父类中定义的getDesc()方法,而是调用子类的getDesc()方法。此时还没有为name,weight赋值,所以会输出Wolf[name=null , weight=0.0]
通过上面分析可以看到,该程序产生这种输出的原因在于this.desc = getDesc();处调用的getDesc()方法是被子类重写过的方法。这样使得对Wolf对象的实例变量赋值的语句this.name = name;this.weight = weight;在getDesc()方法之后被执行,因此getDesc()方法不能得到Wolf对象的name,weight实例变量的值。
为了避免这种不希望看到的结果,应该避免在Animal类的构造器中调用被子类重写过的方法,因此将Animal类改成如下形式即可:
class Animal2
{
public String getDesc()
{
return "Animal";
}
public String toString()
{
return getDesc();
}
}
经过改写的Animal2类不再提供构造器(系统会为止提供一个无参数的构造器),程序改由toString()方法来调用被重写的getDesc()方法。这就保证了对Wolf对象的实例变量赋值的语句his.name = name;this.weight = weight;在getDesc()方法之前被执行,从而使得getDesc()方法得到Wolf对象的name,weight实例变量的值。
如果父类构造器调用了被子类重写的方法,且通过子类构造器来创建子类对象,调用(不管是显式还是隐式)了这个父类构造器,就会导致子类的重写方法在子类构造器的所有代码之前被执行,从而导致子类的重写方法访问不到子类的实际变量值的情形。
2.3 父子实例的内存控制
继承是面向对象的3大特征之一,也是Java语言的重要特征,而父,子继承关系则是Java编程中需要重点注意的地方。下面将继续深入分析父子实例的内存控制。
2.3.1 继承成员变量和继承方法的区别
很多java书籍,资料都会介绍,当子类继承父类时,子类会获得父类中定义的成员变量和方法。当访问权限允许的情况下,子类可以直接访问父类中定义的成员变量和方法。这种介绍其实稍嫌笼统,因为Java继承中对成员变量和方法的处理是不同的,示例如下:
class Base
{
int count = 2;
public void display()
{
System.out.println(this.count);
}
}
class Derived extends Base
{
int count = 20;
@Override
public void display()
{
System.out.println(this.count);
}
}
public class FieldAndMethodTest
{
public static void main(String[] args)
{
// //声明、创建一个Base对象
Base b = new Base();
// //直接访问count实例变量和通过display访问count实例变量
System.out.println(b.count);
b.display();
//声明、并创建一个Derived对象
Derived d = new Derived();
//直接访问count实例变量和通过display访问count实例变量
System.out.println(d.count);
d.display();
// //声明一个Base变量,并将Derived对象赋给该变量
Base bd = new Derived(); //(3)
// //直接访问count实例变量和通过display访问count实例变量
System.out.println(bd.count);
bd.display();
// //让d2b变量指向原d变量所指向的Dervied对象
Base d2b = d; //(4)
//访问d2b所指对象的count实例变量
System.out.println(d2b.count);
}
}
在(3)这块代码中,直接通过db访问count实例变量,输出的将是Base(声明时的类型)对象的count实例变量的值;如果通过db来调用display()方法,该方法将表现出Derived(运行时类型)对象的行为方式。
程序(4)代码直接将d变量赋值给d2b变量,只是d2b变量的类型是Base。这意味着d2b和d两个变量指向同一个Java对象,因此如果在程序中判断d2b==d,将返回true。但是访问d.count时输出20,访问d2b.count时却输出2。这一点看上去很诡异:两个指向同一个对象的变量,分别访问它们的实例变量时却输出不同的值。这表明在d2b,d变量所指向的Java对象中包含了两块内存,分别存放值为2的count实例变量和值为20的count实例变量。
但不管是d变量,还是bd变量,d2b变量,只要它们实际指向一个Dervied对象,不管声明它们时用什么类型,当通过这些变量调用方法时,方法的行为总是表现出它们实际类型的行为;但如果通过这些变量来访问它们所指对象的实例变量,这些实例变量的值总是表现出声明这些变量所用类型的行为。由此可见,Java继承在处理成员变量和方法时是有区别的。
如果在子类重写了父类方法,就意味着子类里定义了方法彻底覆盖了父类里的同名方法,系统将不可能把父类里的方法转移到子类中。对于实例变量则不存在这样的现象,即使子类中定义了与父类完全同名的实例变量,这个实例变量依然不可能覆盖父类中定义的实例变量。
因为继承成员变量和继承方法之间存在这样的差别,所以对于一个引用类型的变量而言,当通过该变量访问它所引用的对象的实例变量时,该实例变量的值取决于声明该变量时类型;当通过该变量来调用它所引用的对象的方法时,该方法行为取决于它所实际引用的对象的类型。
2.3.2 内存中子类实例
看下面一段程序:
class Base
{
int count = 2;
}
class Mid extends Base
{
int count = 20;
}
public class Sub extends Mid
{
int count = 200;
public static void main(String[] args)
{
//创建一个Sub对象
Sub s = new Sub();
//将Sub对象向上转型后赋为Mid、Base类型的变量
Mid s2m = s;
Base s2b = s;
//分别通过3个变量来访问count实例变量
System.out.println(s.count);
System.out.println(s2m.count);
System.out.println(s2b.count);
}
}
打印的结果是:
200
20
2
s,s2m,s2b,这3个变量所引用Java对象拥有3个count实例变量,需要3块内存存储它们。如图:
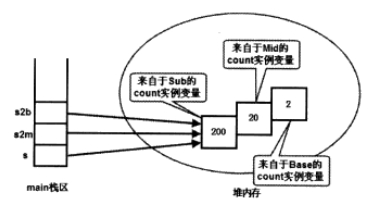
从上图可以看出,Sub对象不仅存储了它自身的count实例变量,还存储从Mid,Base两个父类那里继承到的count实例变量。但这3个count实例变量在底层是有区别的,程序通过Base型变量来访问该对象的count实例变量时,输出2;通过Mid新的变量来访问该对象的count实例变量时,输出20;当直接在Sub类中访问实例变量i时,输出200。
为了在Sub类中访问Mid类定义的count实例变量,可以在count之前加入super关键字为限定。例:super.count;。这样就可以访问到父类中定义的count实例变量。
系统内存中并不存在Mid和Base两个对象,程序内存中只有一个Sub对象,只是这个Sub对象中不仅保存了在Sub类中定义的所有实例变量,还保存了它的所有父类所定义的全部实例变量。
那super关键字的作用到底是什么?看下个程序:
class Fruit
{
String color = "未确定颜色";
//定义一个方法,该方法返回调用该方法的实例
public Fruit getThis()
{
return this;
}
public void info()
{
System.out.println("Fruit方法");
}
}
public class Apple extends Fruit
{
//重写父类的方法
@Override
public void info()
{
System.out.println("Apple方法");
}
//通过super调用父类的Info()方法
public void AccessSuperInfo()
{
super.info();
}
//尝试返回super关键字代表的内容
public Fruit getSuper()
{
return super.getThis();
}
String color = "红色";
public static void main(String[] args)
{
//创建一个Apple对象
Apple a = new Apple();
//调用getSuper()方法获取Apple对象关联的super引用
Fruit f = a.getSuper();
//判断a和f的关系
System.out.println("a和f所引用的对象是否相同:" + (a == f));
System.out.println("访问a所引用对象的color实例变量:" + a.color);
System.out.println("访问f所引用对象的color实例变量:" + f.color);
//分别通过a、f两个变量来调用info方法
a.info();
f.info();
//调用AccessSuperInfo来调用父类的info()方法
a.AccessSuperInfo();
}
}
输出结果为:
a和f所引用的对象是否相同:true
访问a所引用对象的color实例变量:红色
访问f所引用对象的color实例变量:未确定颜色
Apple方法
Apple方法
Fruit方法
Java程序允许某个方法通过return this;返回调用该方法的Java对象,但不允许直接return super;甚至不允许直接将super当成一个引用变量使用。
通过上面程序可以看出:super关键字本身并没有引用任何对象,它甚至不能被当成一个真正的引用变量使用。主要有如下两个原因:
(1) 子类方法不能直接使用return super;但使用return this;返回调用该方法的对象是允许的。
(2) 程序不允许直接把super当成变量使用,例如,试图判断super和a变量是否引用同一个Java对象—super==a;但这条语句将引起编译错误。
至此,对父,子对象在内存中存储有了准确的结论:当程序创建一个子类对象时,系统不仅会为该类中定义的实例变量分配内存,也会为其父类中定义的所有实例变量分配内存,即使子类定义了与父类中同名实例变量。
如果在子类里定义了与父类中已有变量同名的变量,那么子类中定义的变量会隐藏父类中定义的变量。之一不是完全覆盖,因此系统为创建子类对象时,依然会为父类中定义的,被隐藏的变量分配内存空间。
为了在子类方法中访问父类中定义的,被隐藏的实例变量,或者为了在子类方法中调用父类中定义的,被覆盖的方法,可以通过super作为限定来修饰这些实例变量和实例方法。
2.3.3 父,子类的类变量
理解了上面介绍的父,子实例在内存中分配之后,接下来的父,子类的类变量基本与此类似。不同的是,类变量属于类本身,而实例变量则属于Java对象;类变量在类初始化阶段完成初始化,而实例变量则在对象初始化阶段完成初始化。
由于类变量本质上属于类本身,因此通常不会涉及父,子实例变量那样复杂的情形,但由于Java允许通过对象来访问类变量,因此也可以使用super作为限定来访问父类中定义的类变量。下面程序示范了这种用法:
class StaticBase
{
//定义一个count类变量
static int count = 20;
}
public class StaticSub extends StaticBase
{
//子类再定义一个count类变量
static int count = 200;
public void info()
{
System.out.println("访问本类的count类变量:" + count);
System.out.println("访问父类的count类变量:" + StaticBase.count);
System.out.println("访问父类的count类变量:" + super.count);
}
public static void main(String[] args)
{
StaticSub sb = new StaticSub();
sb.info();
}
}
要访问父类中定义的count类变量,有2中方式
(1) 直接使用父类的类名作为主调来访问count类变量。
(2) 使用super作为限定来访问count类变量。
2.4 final修饰符
final修饰符是Java语言中比较简单的一个修饰符,定义如下:
(1) final可以修饰变量,被final修饰的变量被赋初始值之后,不能对它重新赋值。
(2) final可以修饰方法,被final修饰的方法不能被重写。
(3) final可以修饰类,被final修饰的类不能派生子类。
只掌握定义是不够的,下面将从几个方面来分析final修饰符功能。
2.4.1 final修饰的变量
被final修饰的实例变量必须显式指定初始值,而且只能在如下3个位置指定初始值。
(1) 定义final实例变量时指定初始值。
(2) 在非静态初始化块中为final实例变量指定初始值。
(3) 在构造器中为final实例变量指定初始值。
对于普通实例变量,Java程序可以对它执行默认的初始化,也就是将实例变量的值指定为默认的初始值0或null,但对于final实例变量,则必须由程序员显式指定初始值。
下面程序示范了在3个地方对final实例变量进行初始化。
public class FinalInstanceVaribaleTest
{
//定义final实例变量时赋初始值
final int var1 = "疯狂Java讲义".length();
final int var2;
final int var3;
//在初始化块中为var2赋初始值
{
var2 = "轻量级Java EE企业应用实战".length();
}
//在构造器中为var3赋初始值
public FinalInstanceVaribaleTest()
{
this.var3 = "疯狂XML讲义".length();
}
public static void main(String[] args)
{
FinalInstanceVaribaleTest fiv = new FinalInstanceVaribaleTest();
System.out.println(fiv.var1);
System.out.println(fiv.var2);
System.out.println(fiv.var3);
}
}
上面程序用了3种给final变量初始化的方式,但是经过编译器的处理,这3种方式都会被抽取到构造器中赋初始值。
对于final类变量而言,同样必须显式指定初始值,而且final类变量只能在2个地方初始值:
(1) 定义final类变量时指定初始值;
(2) 在静态初始化块中为final类变量指定初始值。
下面程序示范了2个地方对final类变量进行初始化
public class FinalClassVaribaleTest
{
//定义final类变量时赋初始值
final static int var1 = "疯狂Java讲义".length();
final static int var2;
//在静态初始化块中为var2赋初始值
static {
var2 = "轻量级Java EE企业应用实战".length();
}
public static void main(String[] args)
{
System.out.println(FinalClassVaribaleTest.var1);
System.out.println(FinalClassVaribaleTest.var2);
}
}
上面程序用了2种方法初始化,但是经过编译器的处理,这2种方式都会被抽取到静态初始化块中赋初始值。
当使用final修饰类变量时,如果定义该final类变量时指定了初始值,而且该初始值可以在编译时就被确定下来,系统将不会在静态初始化块中对该类变量赋初始值,而将是在类定义中直接使用该初始值代替该final变量。
对于一个使用final修饰的变量而言,如果定义该final变量时就指定初始值,而且这个初始值可以在编译时就确定下来,那么这个final变量将不再是一个变量,系统会将其当成“宏变量”处理。也就是说,所有出现该变量的地方,系统将直接把它当成对应的值处理。
2.4.2 执行“宏替换”的变量
对一个final变量,不管它是类变量,实例变量,还是局部变量,只要定义该变量时使用了final修饰符修饰,并在定义该final类变量时指定了初始值,而且该初始值可以在编译时就被确定下来,那么这个final变量本质上已经不再是变量,而是相当于一个直接量。
Final修饰符的一个重要用途就是定义“宏变量”。当定义final变量时就为该变量指定了初始值,而且该初始值可以在编译时就确定下来,那这个final变量本质上就是一个“宏变量”,编译器会把程序中所有用到该变量的地方直接替换成该变量的值。
Java会缓存所有曾经用过的字符串直接量。例如执行String a = “java”;语句之后,系统的字符串池中就会缓存一个字符串”java”;如果程序再次执行String b = “java”;系统将会让b直接指向字符串池中的”java”字符串,因此a==b将会返回true。
为了加深对final修饰符的印象,看如下程序
public class StringJoinTest
{
public static void main(String[] args)
{
String s1 = "疯狂Java";
String s2 = "疯狂" + "Java";
System.out.println(s1 == s2);
//定义2个字符串直接量
String str1 = "疯狂";
String str2 = "Java";
//将str1和str2进行连接运算
String s3 = str1 + str2;
System.out.println(s1 == s3);
}
}
S1是一个普通的字符串直接赋值“疯狂Java”,s2的值是两个字符串直接进行连接运算,由于编译器可以在编译阶段就确定s2的值为“疯狂Java”,所以系统会让s2直接指向字符串池中缓存中的“疯狂Java”字符串,所以s1==s2输出true。
对于S3而言,它的值有str1和str2进行连接运算后得到。由于str1和str2只是两个普通变量,编译器不会执行“宏替换”,因此编译器无法在编译时确定s3的值,不会让s3指向字符串池中缓存中的“疯狂Java”。由此可见,s1==s3输出false。
为了让s1==s3输出true很简单,只要编译器可以对str1,str2两个变量执行“宏替换”。及在str1和str2之前加上fianl,这样编译器即可在编译阶段就确定s3的值,就会让s3指向字符串池中缓存中的“疯狂Java”。
对于实例变量而言,除了可以在定义该变量时赋初始值之外,还可以在非静态初始化块,构造器中对它赋初始值,而且在这3个地方指定初始值的效果基本一样。但对于fianl实例变量而言,只有在定义该变量时指定初始值才会有“宏变量”的效果,在非静态初始化块,构造器中为final实例变量指定初始值则不会有这种效果,示例如下:
public class FinalInitTest
{
//定义3个final实例变量
final String str1;
final String str2;
final String str3 = "Java";
//str1、str2分别放在非静态初始化块、构造器中初始化
{
str1 = "Java";
}
public FinalInitTest()
{
str2 = "Java";
}
//判断str1、str2、str3是否执行"宏替换"
public void display()
{
System.out.println(str1 + str1 == "JavaJava");
System.out.println(str2 + str2 == "JavaJava");
System.out.println(str3 + str3 == "JavaJava");
}
public static void main(String[] args)
{
FinalInitTest fit = new FinalInitTest();
fit.display();
}
}
上面程序str3是true,前两个都是false,就说明了这个问题。
2.4.3 final方法不能被重写
如果父类中某个方法使用了final修饰符进行修饰,那么这个方法将不可能被它的子类访问到,因此这个方法也不可能被它的子类重写。例子如下:
class Base
{
private final void info()
{
System.out.println("Base的info方法");
}
}
public class FinalMethodTest extends Base
{
//这个info方法并不是覆盖父类方法。
// @Override
public void info()
{
System.out.println("FinalMethodTest的Info方法");
}
}
子类FinalMethodTest的info方法只是一个普通方法,并不是重写父类的方法,如果打开@Override的话会提示错误。
2.4.4 内部类中的局部变量
如果程序需要在匿名内部类中使用局部变量,那么这个局部变量必须使用final修饰符修饰。示例如下:
import java.util.*; interface IntArrayProductor
{
//接口里定义的product方法用于封装“处理行为”
int product();
}
public class CommandTest
{
//定义一个方法,该生成指定长度的数组,但每个数组元素由于cmd负责产生
public int[] process(IntArrayProductor cmd , int length)
{
int[] result = new int[length];
for (int i = 0; i < length ; i++ )
{
result[i] = cmd.product();
}
return result;
}
public static void main(String[] args)
{
CommandTest ct = new CommandTest();
final int seed = 5;
//生成数组,具体生成方式取决于IntArrayProductor接口的匿名实现类
int[] result = ct.process(new IntArrayProductor()
{
public int product()
{
return (int)Math.round(Math.random() * seed);
}
} , 6);
System.out.println(Arrays.toString(result));
}
}
不仅匿名内部类,即使是普通内部类,在任何内部类中访问的局部变量都应该使用final修饰。
那为什么Java要求内部类访问的局部变量必须使用final修饰呢?
Java要求所有被内部类访问的局部变量都使用final修饰也是有其原因的:对于普通局部变量而言,它的作用域就是停留在该方法内,当方法执行结束,该局部变量也随之消失;但内部类则可能产生隐式的“闭包”,闭包将使得局部变量脱离它所在的方法继续存在。
下面程序是局部变量脱离它所在方法继续存在的例子:
public class ClosureTest
{
public static void main(String[] args)
{
//定义一个局部变量
final String str = "Java";
//在内部类里访问局部变量str
new Thread(new Runnable()
{
public void run()
{
for (int i = 0; i < 100 ; i++ )
{
//此处将一直可以访问到str局部变量
System.out.println(str + " " + i);
//暂停0.1秒
try
{
Thread.sleep(100);
}
catch (Exception ex)
{
ex.printStackTrace();
}
}
}
}).start();
//执行到此处,main方法结束
}
}
上面程序定义了一个局部变量str。正常情况下,当程序执行完main后,他的声明周期就结束了,局部变量str的作用域也会随之结束。但只要新线程里的run方法没有执行完,匿名内部类的实例的生命周期就没有结束,将一直可以访问str局部变量的值,这就是内部类会扩大局部变量作用域的实例。
由于内部类可能扩大局部变量的作用域,如果再加上这个被内部类访问的局部变量没有使用final修饰,也就是说该变量的值可以随意改变,那将引起极大的混乱,因此Java编译器要求所有被内部类访问的局部变量必须使用final修饰符修饰。
《疯狂Java:突破程序员基本功的16课》读书笔记-第二章 对象与内存控制的更多相关文章
- 《疯狂java-突破程序员基本功的16课 》笔记总结
本人最近读完<疯狂java-突破程序员基本功的16课 >读完后,感觉对java基础又有了新的认识,在这里总结一下:一.数组与内存控制 1.1 数组初始化 java语言的数组是静态的 ...
- 疯狂Java:突破程序员基本功的16课-李刚编著 学习笔记(未完待续)
突破程序员基本功(16课) 数组 静态语言: 在编译的时候就能确定数据类型的语言,大多静态语言要求在使用变量之前必须声明数据类型(少数具有强推导能力的现代语言不用) 动态语言: 在程序运行时确定数据类 ...
- 《疯狂Java:突破程序员基本功的16课》读书笔记-第一章 数组与内存控制
很早以前就听过李刚老师的疯狂java系列很不错,所以最近找一本拿来拜读,再此做下读书笔记,促进更好的消化. 使用Java数组之前必须先对数组对象进行初始化.当数组的所有元素都被分配了合适的内存空间,并 ...
- 类变量的初始化时机(摘录自java突破程序员基本功德16课)
先看书本的一个例子,代码如下: public class Price { final static Price INSTANCE=new Price(2.8); static double initP ...
- 《程序员的自我修养》读书笔记——系统调用、API
系统调用 程序运行的时候,本身是没有权限访问多少系统资源的.系统资源有限,如果操作系统不进行控制,那么各个程序难免会产生冲突.线程操作系统都将可能产生冲突的系统资源保护起来,阻止程序直接访问. ...
- pwn学习日记Day21 《程序员的自我修养》读书笔记
Linux内核装载ELF过程 (1)bash进程调用fork()系统调用创建一个新的进程 (2)新的进程调用execve()系统调用执行指定的ELF文件,原先的bash进程继续返回等待刚才启动的新进程 ...
- pwn学习日记Day20 《程序员的自我修养》读书笔记
可执行文件的装载与进程 覆盖装入和页映射是两种典型的动态装载方法 进程建立的三步 1.创建一个独立的虚拟地址空间 2.读取可执行文件头,并且建立虚拟空间与可执行文件的映射关系. 3.将CPU的指令寄存 ...
- pwn学习日记Day19 《程序员的自我修养》读书笔记
windows PE/COFF章总结 本章学习了windows下的可执行文件和目标文件格式PE/COFF.PE/COFF文件与ELF文件非常相似,它们都是基于段的结构的二进制文件格式.Windows下 ...
- pwn学习日记Day18 《程序员的自我修养》读书笔记
知识杂项 obj文件:当前源代码编译成二进制目标文件 exe文件:将.obj文件与库文件.lib等文件链接生成的可执行文件 一个现代编译器的主要工作流程如下: 源程序(source code)→ 预处 ...
随机推荐
- 伪多项式时间算法Pseudo-polynomial Algorithms-----geeksforGeek 翻译
原创翻译加学习笔记,方便国人学习算法知识! 原文链接http://www.geeksforgeeks.org/pseudo-polynomial-in-algorithms/ 什么是伪多项式? 当一个 ...
- codeforces 711A A. Bus to Udayland(水题)
题目链接: A. Bus to Udayland 题意: 找一对空位坐下来,水; 思路: AC代码: #include <iostream> #include <cstdio> ...
- UVALive 6168 Fat Ninjas --二分小数+搜索
题意:一个NxN的网格地板,有一些激光束从天花板垂直射向地面的某个网格,一个圆要安全地从左走到右,不碰到上边界,下边界以及激光束,问这个圆的直径最大能达到多大. 分析:可以二分直径,关键在check函 ...
- 线性代数与MATALB1
1图论的一个基本应用 下图描述了4个城市之间的航空航线图, 为了描述着4个城市之间航线的邻接关系,定义邻接矩阵 第i行描述从城市i出发,可以达到各个城市的情况, 可以证明,矩阵A^N表示一个人连续坐N ...
- Highlighting System
Highlighting System 法线贴图漫反射着色器 Unity论坛:http://forum.unity3d.com/threads/143043-Highlighting-System-R ...
- 001医疗项目-项目框架的搭建(四个maven工程)
这个项目资料来源于传智播客.用的是ssm框架, 我们首先建立一个working sets里面存放,我们的maven工程. 如下:
- [转]SRTM、ASTER GDEM等全球数字高程数据(DEM)下载方式简介
之前写过一篇短文对比过几种数字高程数据的区别:5种全球高程数据对比,这篇文章简要介绍下如何下载这些数据. 1.DLR的数字高程数据.该数据也是SRTM(shuttle radar topo ...
- iBatis.net入门指南
iBatis.net入门指南 - 1 - 什么是iBatis.net ? - 3 - iBatis.net的原理 - 3 - 新人指路 - 3 - iBatis.net的优缺点 ...
- IBatis.Net学习笔记六--再谈查询
在IBatis.Net学习笔记五--常用的查询方式 中我提到了一些IBatis.Net中的查询,特别是配置文件的写法. 后来通过大家的讨论,特别是Anders Cui 的提醒,又发现了其他的多表查询的 ...
- 极简反传(BP)神经网络
一.两层神经网络(感知机) import numpy as np '''极简两层反传(BP)神经网络''' # 样本 X = np.array([[0,0,1],[0,1,1],[1,0,1],[1, ...